




 本文是关于MySQL的学习记录,涵盖了SQL基本概念、导入示例数据库、查询语句(SELECT FROM)、筛选(WHERE)、分组(GROUP BY)、排序(ORDER BY)以及常用函数的介绍。还提供了SQL代码规范及小练习,帮助读者巩固所学。
本文是关于MySQL的学习记录,涵盖了SQL基本概念、导入示例数据库、查询语句(SELECT FROM)、筛选(WHERE)、分组(GROUP BY)、排序(ORDER BY)以及常用函数的介绍。还提供了SQL代码规范及小练习,帮助读者巩固所学。
导入示例数据库
在workbench中导入.sql文件!(导入数据库文件)—DeepRunning—优快云
按照上面的教程在 MySQL Workbench 中导入示例数据库,示例数据库 yiibaidb 来自于
MySQL导入示例数据库—初生不惑—易百教程,成功导入示例数据库后,简单测试下导入结果,如下图:

SQL是什么?MySQL是什么?
-
SQL: 全称是 Structured Query Language,结构化查询语言。SQL 是用于访问和处理数据库的标准的计算机语言。
虽然 SQL 是一门 ANSI(American National Standards Institute美国国家标准化组织)标准的计算机语言,但是仍然存在着多种不同版本的 SQL 语言。
然而,为了与 ANSI 标准相兼容,它们必须以相似的方式共同地来支持一些主要的命令(比如 SELECT、UPDATE、DELETE、INSERT、WHERE 等等)。
除了 SQL 标准之外,大部分 SQL 数据库程序都拥有它们自己的专有扩展! -
MySQL: MySQL 是一个关系型数据库管理系统,由瑞典 MySQL AB 公司开发,目前属于 Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件。
MySQL是一种关系数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。- MySQL 是开源的,所以你不需要支付额外的费用。
- MySQL 支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
- MySQL 使用标准的 SQL 数据语言形式。
- MySQL 可以运行于多个系统上,并且支持多种语言。
- MySQL 对PHP有很好的支持,PHP 是目前最流行的 Web 开发语言。
- MySQL 是可以定制的,采用了 GPL 协议,你可以修改源码来开发自己的 MySQL 系统。
查询语句 SELECT FROM
- 语句解释
SELECT语句的用途是从一个或多个表中检索信息。
SELECT 语句中你可以使用一个或者多个表,表之间使用逗号(,)分割,查询多个列也用逗号(,)分隔:
SELECT column_name1, column_name2, column_name3
FROM table_name1, table_name2;
当查询所有列时,不必逐个列出列名,使用星号(*)来代替列名,SELECT 语句会返回表的所有字段数据:
SELECT *
FROM table_name;
- 去重语句
使用 DISTINCT 关键字进行去重,它指示数据库只返回不同的值:
SELECT DISTINCT column_name
FROM table_name;
- 前N个语句
使用 LIMIT 属性可以设定返回的记录数,通过 OFFSET 指定 SELECT 语句开始查询的数据偏移量。默认情况下偏移量为0。
使用 LIMIT 字句输出前 N 个记录:
SELECT column_name
FROM table_name
LIMIT N;
输出第 5 行后面的 5 行记录:
SELECT column_name
FROM table_name
LIMIT 5 OFFSET 5;
- CASE…END判断语句
参考CASE WHEN THEN END多条件判断—Writing_the_future—优快云这篇博文
筛选语句 WHERE
- 语句解释
上面已经介绍了从 MySQL 表中使用 SELECT 语句来读取数据。
如需有条件地从表中选取数据,可将 WHERE 子句添加到 SELECT 语句中。
SELECT column_name1, column_name2, ..., column_nameN
FROM table_name1, table_name2, ..., table_nameN
WHERE condition1 [AND [OR]] condition2;
- 运算符/通配符/操作符
| 操作符 | 描述 |
|---|---|
| = | 等号,检测两个值是否相等,如果相等返回 true |
| <>, != | 不等于,检测两个值是否相等,如果不相等返回 true |
| > | 大于号,检测左边的值是否大于右边的值, 如果大于返回 true |
| < | 小于号,检测左边的值是否小于右边的值, 如果小于返回 true |
| >= | 大于等于号,检测左边的值是否大于或等于右边的值, 如果大于或等于返回 true |
| <= | 小于等于号,检测左边的值是否小于或等于右边的值, 如果小于或等于返回 true |
分组语句 GROUP BY
- 语句解释
GROUP BY 语句根据一个或多个列对结果集进行分组。在分组的列上我们可以使用 COUNT, SUM, AVG等函数。
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
- 聚集函数
| 函 数 | 说 明 |
|---|---|
| AVG() | 返回某列的平均值 |
| COUNT() | 返回某列的记录数 |
| MAX() | 返回某列的最大值 |
| MIN() | 返回某列的最小值 |
| SUM() | 返回某列值之和 |
- HAVING子句
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用。
分组后的条件使用 HAVING 来限定,WHERE 是对原始数据进行条件限制。
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name
HAVING aggregate_function(column_name) operator value;
排序语句 ORDER BY
ORDER BY 语句用于根据指定的列对结果集进行排序。
ORDER BY 语句可以使用 ASC 或 DESC 关键字来设置查询结果是按升序或降序排列。 默认情况下,它是按升序排列。
SELECT column_name1, column_name2, ..., column_nameN
FROM table_name1, table_name2, ..., table_nameN
ORDER BY column_name1, [column_name2, ...] ASC;
SELECT column_name1, column_name2, ..., column_nameN
FROM table_name1, table_name2, ..., table_nameN
ORDER BY column_name1, [column_name2, ...] DESC;
常用函数
详细的函数介绍请参考 菜鸟教程-MySQL函数 ,下面只介绍部分常用函数:
- 时间函数
ADDDATE(d,n) : 计算起始日期 d 加上 n 天的日期
SELECT ADDDATE("2019-04-02", INTERVAL 100 DAY);
CURDATE() 或 CURRENT_DATE() : 返回当前日期
SELECT CURDATE();
SELECT CURRENT_DATE();
CURTIME() 或 CURRENT_TIME : 返回当前时间
SELECT CURTIME();
SELECT CURRENT_TIME();
- 数值函数
ABS(x) : 返回 x 的绝对值
SELECT ABS(-1);
SQRT(x) : 返回x的平方根
SELECT SQRT(25);
RAND() : 返回 0 到 1 的随机数
SELECT RAND();
ROUND(x) : 返回离 x 最近的整数
SELECT ROUND(1.23456);
- 字符串函数
POSITION(s1 IN s) : 从字符串 s 中获取 s1 的开始位置
SELECT POSITION('b' in 'abc'); -- 2
REPEAT(s,n) : 将字符串 s 重复 n 次
SELECT REPEAT('runoob',3); -- runoobrunoobrunoob
REPLACE(s,s1,s2) : 将字符串 s2 替代字符串 s 中的字符串 s1
SELECT REPLACE('abc','a','x'); --xbc
SQL注释
- 单行注释: SQL语句中的单行注释使用 –
CREATE DATABASE database_x; --创建数据库database_x
- 多行注释 : SQL语句中的多行注释采用 /* … */
CREATE DATABASE database_x;
/*
创建一个数据库
名字叫做database_x
*/
SQL代码规范
参考知乎回答 SQL编程格式的优化建议
小练习
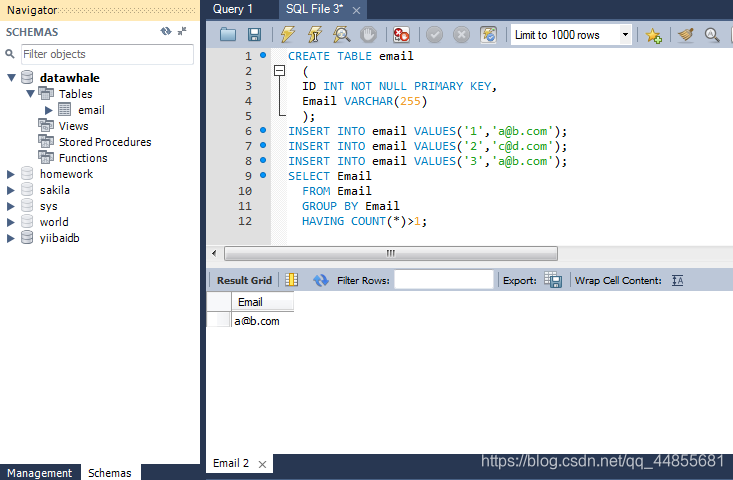
项目一:查找重复的电子邮箱(难度:简单)
创建 email表,并插入如下三行数据
±—±--------+
| Id | c |
±—±--------+
| 1 | a@b.com |
| 2 | c@d.com |
| 3 | a@b.com |
±—±--------+
编写一个 SQL 查询,查找 Email 表中所有重复的电子邮箱。
根据以上输入,你的查询应返回以下结果:
±--------+
| Email |
±--------+
| a@b.com |
±--------+
说明:所有电子邮箱都是小写字母。
-- 创建表
CREATE TABLE email
(
ID INT NOT NULL PRIMARY KEY,
Email VARCHAR(255)
);
-- 插入数据
INSERT INTO email VALUES('1','a@b.com');
INSERT INTO email VALUES('2','c@d.com');
INSERT INTO email VALUES('3','a@b.com');
-- 查找重复邮箱
SELECT Email
FROM Email
GROUP BY Email
HAVING COUNT(*)>1;
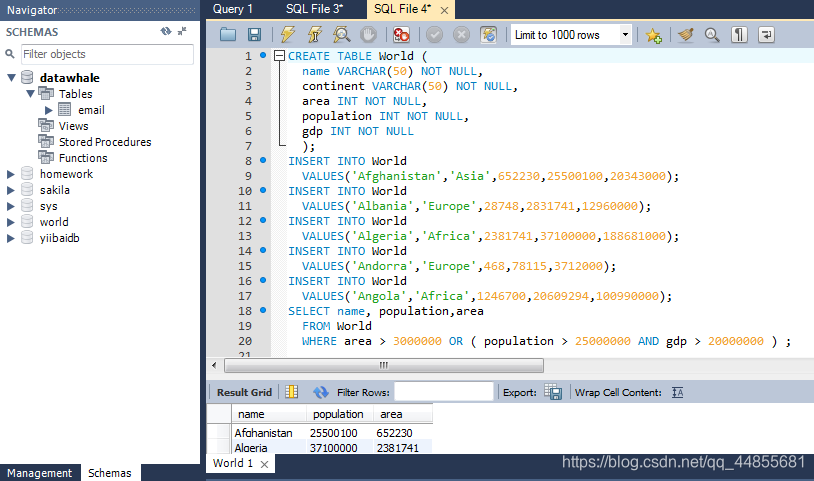
项目二:查找大国(难度:简单)
创建如下 World 表
±----------------±-----------±-----------±-------------±--------------+
| name | continent | area | population | gdp |
±----------------±-----------±-----------±-------------±--------------+
| Afghanistan | Asia | 652230 | 25500100 | 20343000 |
| Albania | Europe | 28748 | 2831741 | 12960000 |
| Algeria | Africa | 2381741 | 37100000 | 188681000 |
| Andorra | Europe | 468 | 78115 | 3712000 |
| Angola | Africa | 1246700 | 20609294 | 100990000 |
±----------------±-----------±-----------±-------------±--------------+
如果一个国家的面积超过300万平方公里,或者(人口超过2500万并且gdp超过2000万),那么这个国家就是大国。
编写一个SQL查询,输出表中所有大国家的名称、人口和面积。
例如,根据上表,我们应该输出:
±-------------±------------±-------------+
| name | population | area |
±-------------±------------±-------------+
| Afghanistan | 25500100 | 652230 |
| Algeria | 37100000 | 2381741 |
±-------------±------------±-------------+
-- 创建表
CREATE TABLE World
(
name VARCHAR(50) NOT NULL,
continent VARCHAR(50) NOT NULL,
area INT NOT NULL,
population INT NOT NULL,
gdp INT NOT NULL
);
-- 插入数据
INSERT INTO World
VALUES('Afghanistan','Asia',652230,25500100,20343000);
INSERT INTO World
VALUES('Albania','Europe',28748,2831741,12960000);
INSERT INTO World
VALUES('Algeria','Africa',2381741,37100000,188681000);
INSERT INTO World
VALUES('Andorra','Europe',468,78115,3712000);
INSERT INTO World
VALUES('Angola','Africa',1246700,20609294,100990000);
-- 查找大国
SELECT name, population,area
FROM World
WHERE area > 3000000 OR ( population > 25000000 AND gdp > 20000000 ) ;

















 269
269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









