






需求:
-
一场演讲比赛,共12名选手参加,每名选手都有对应的编号,如 10001 ~ 10012。
-
比赛共两轮:第一轮:随机分成两组,6人一组,按照选手编号进行抽签后顺序演讲。
-
十个评委打分,去除最高分和最低分,前三名晋级,进入下一轮的比赛。
-
第二轮6人决赛,前三名胜出,为冠亚季军。
-
每轮比赛过后需要显示晋级选手的信息。
-
可以查看往届冠亚军记录,文件用.csv后缀名保存。
一键加速:
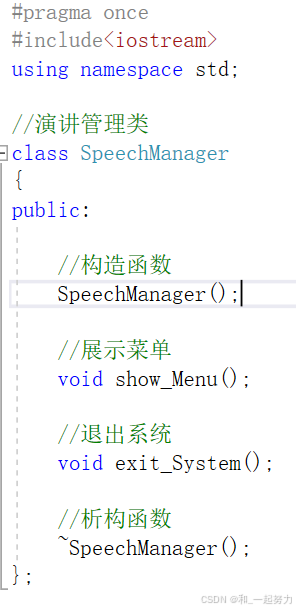
speechManager.h:
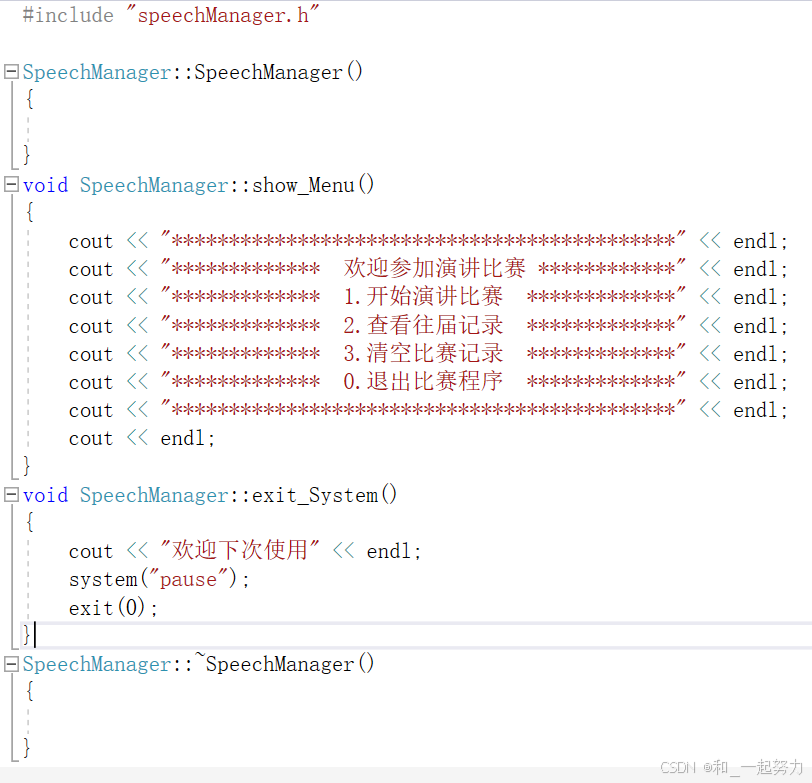
speechManager.cpp:
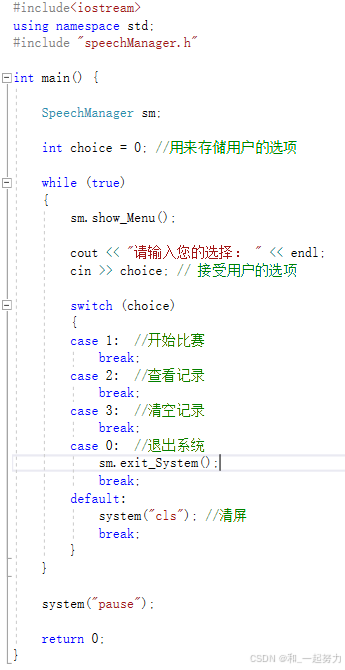
演讲比赛流程管理系统.cpp:
1、演讲比赛功能
1.1比赛流程分析:
抽签 → 开始演讲比赛 → 显示第一轮比赛结果 →抽签 → 开始演讲比赛 → 显示前三名结果 → 保存分数
1.2创建选手类:
-
选手类中的属性包含:选手姓名、分数
-
头文件中创建 speaker.h文件,并添加代码:

1.3比赛:
1.3.1在speechManager.h中添加属性
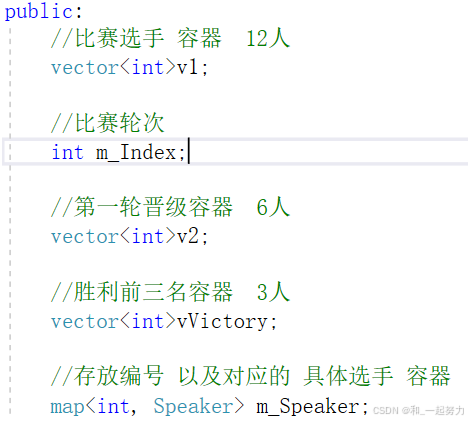
为什么Speaker属性包含姓名和分数、vector容器中存放编号、创建了map容器存储编号和选手的映射关系?
这是一种典型的面向对象设计和数据分离的思想。它的核心目的是为了提高代码的可维护性、灵活性和性能。
1. 数据分离:编号与选手信息分离
-
编号是唯一标识符:编号是选手的唯一标识,适合作为外部管理的键值。
-
选手信息是属性:姓名和分数是选手的属性,适合放在
Speaker类中。 -
分离的好处:
-
编号和选手信息是独立的,修改编号不会影响选手信息,反之亦然。
-
通过编号可以快速定位选手信息,而不需要在每个
Speaker对象中存储编号。
-
2. 高效的数据访问
-
vector<int>存放编号:-
vector是一个动态数组,适合存储一组编号。 -
编号是整数,占用内存小,操作(如排序、随机打乱)效率高。
-
-
map<int, Speaker>存放编号和选手的映射:-
map是一个关联容器,可以通过编号(键)快速查找对应的Speaker对象(值)。 -
查找时间复杂度为O(log n),效率较高。
-
3. 避免数据冗余
-
如果直接在
vector中存放Speaker对象,会导致以下问题:-
每个
Speaker对象都包含姓名和分数,占用更多内存。 -
如果需要修改选手信息,需要在多个地方同步更新,增加了维护成本。
-
-
通过
map集中管理选手信息,避免了数据冗余。
4. 灵活的比赛流程管理
-
比赛流程需要频繁操作编号:
-
第一轮:从
v1中随机打乱编号,分组比赛。 -
第二轮:从
v2中取出晋级选手的编号,继续比赛。 -
决赛:从
vVictory中取出前三名的编号。
-
-
通过编号操作,逻辑清晰:
-
编号是轻量级的数据,适合用于分组、排序、晋级等操作。
-
如果需要选手的详细信息,可以通过编号从
map中快速获取。
-
1.3.2初始化比赛流程的属性

1.3.3创建选手
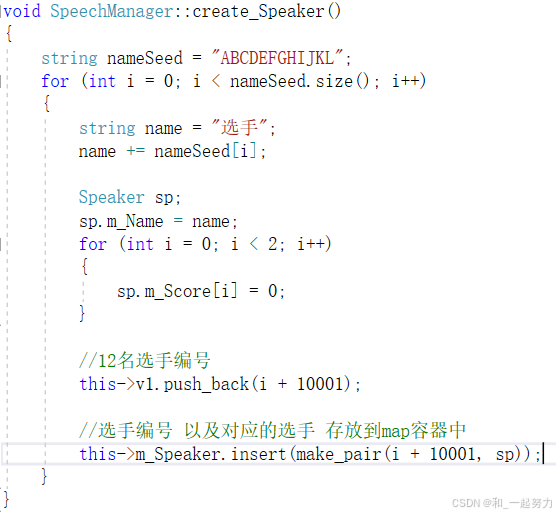
为什么不将m_Speaker的初始化放在init_Speech()中?
-
职责分离:
init_Speech()的职责是重置比赛流程,而create_Speaker()的职责是初始化选手信息。将两者分开,使代码更清晰、更易于维护。 -
性能优化:
m_Speaker存储的是所有选手的固定信息,只需要在程序启动时初始化一次,不需要在每次比赛结束后重新初始化。 -
逻辑清晰:选手信息是固定的,而比赛流程是动态的。将固定信息和动态信息分开管理,符合逻辑。
SpeechManager类的构造函数中调用:

1.3.4比赛流程成员函数添加

1.3.5抽签(洗牌算法)
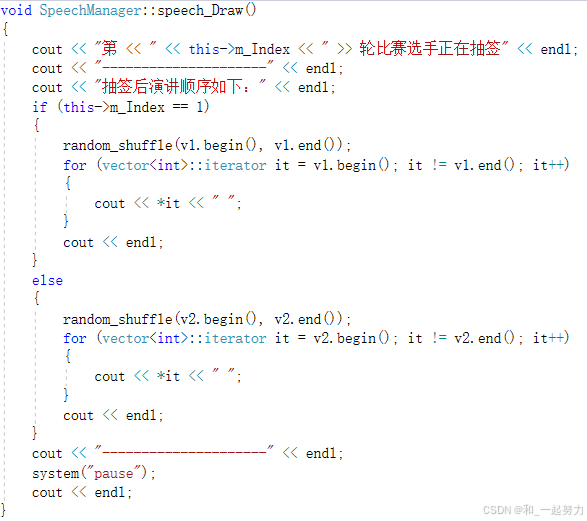
抽签即打乱顺序,random_shuffle配合随机数种子使用。
1.3.6比赛
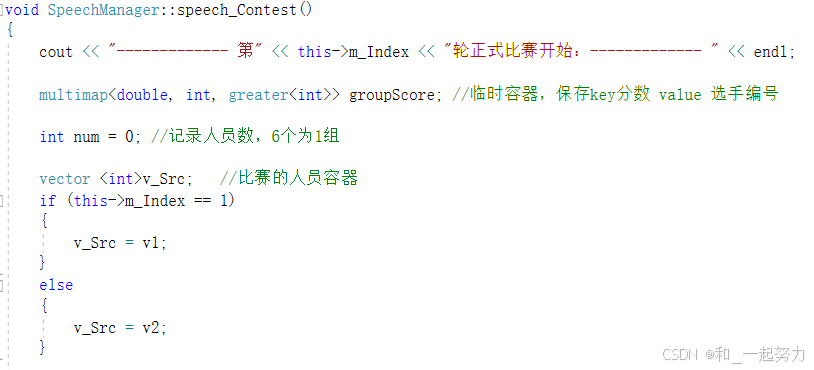
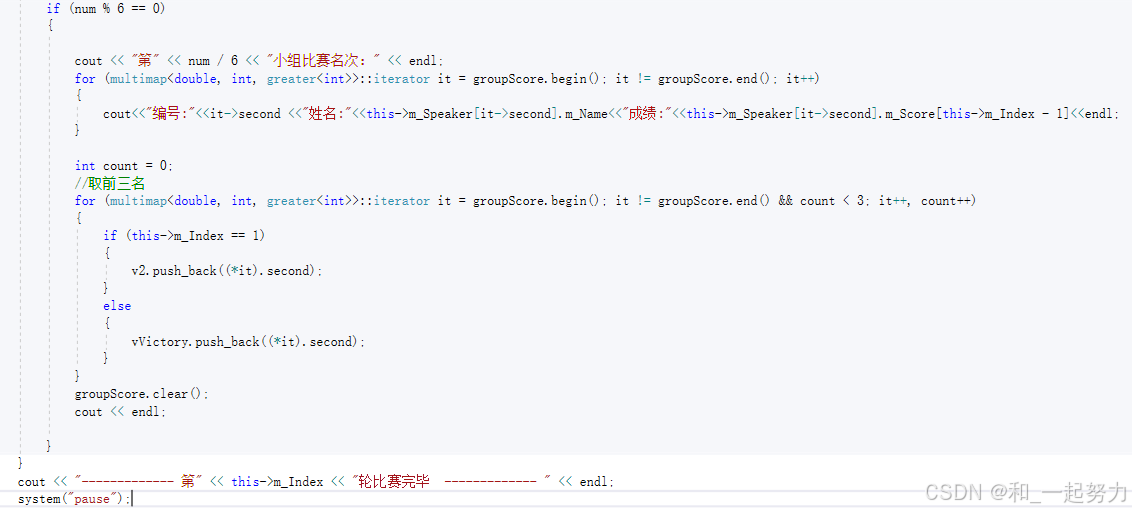
1、为什么选择 multimap?
-
自动排序:
multimap会根据键(key)自动排序,适合需要对得分进行排序的场景。 -
允许重复键:
multimap允许存储多个具有相同得分的选手,而map不允许。 -
高效查找:
multimap支持快速查找和遍历,适合需要频繁排序和取出的场景。
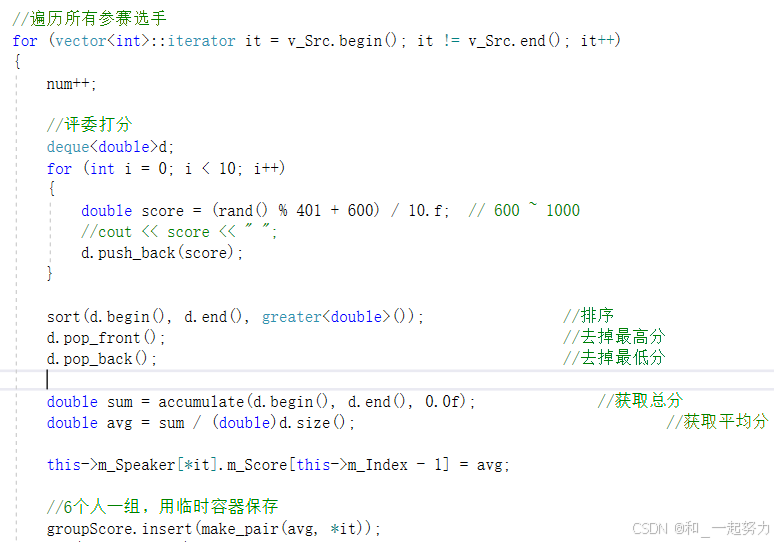
2、deque使用sort算法和大于仿函数,便于去除最低分和最高分;
3、/10.f:将分数表示为 浮点数,并保留一位小数;
4、create_Speaker()函数中://选手编号 以及对应的选手 存放到map容器中,此时也不要忘记更新分数;
5、通过键值访问value:m_Speaker[it->second].m_Name;
6、使用 random_shuffle 打乱顺序,再通过 num 控制分组,是一种非常巧妙的设计;
7、注意groupScore容器什么时候清理。
1.3.6显示比赛分数

1.3.7第二轮比赛
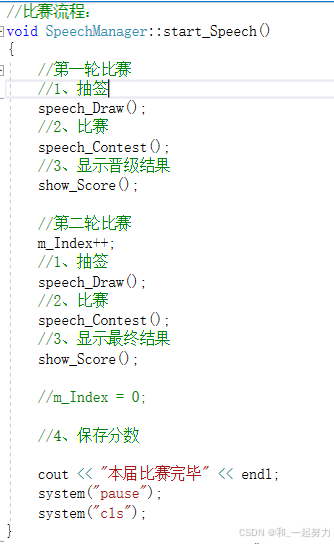
隐藏一个小bug。
测试:
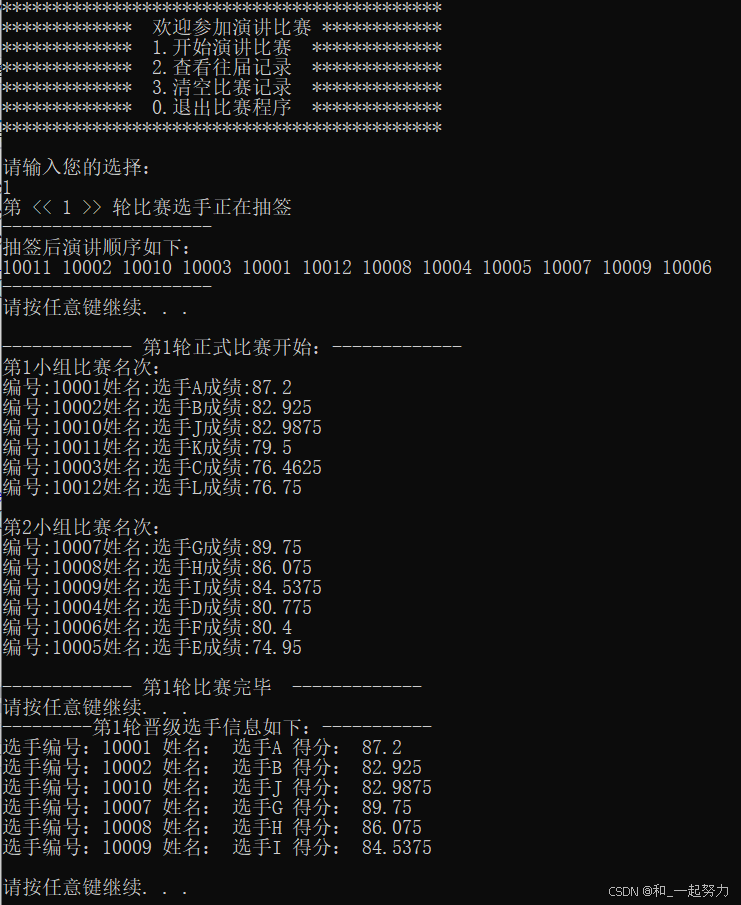
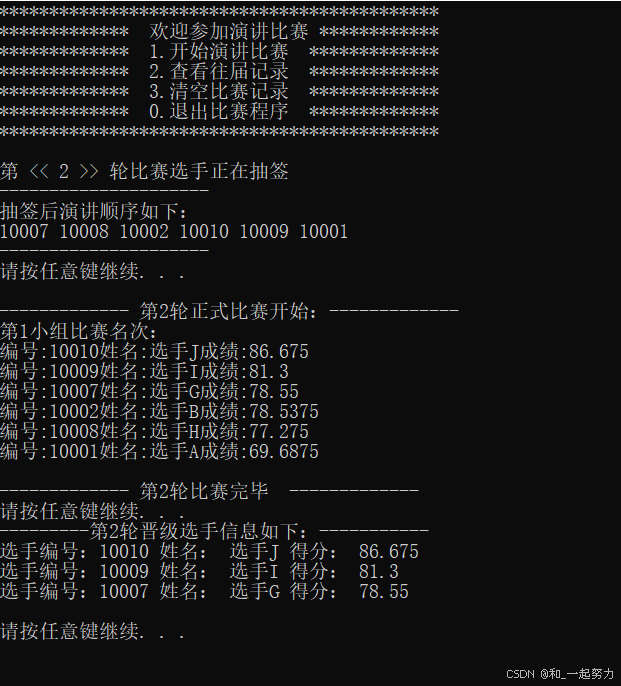
1.4保存分数

测试:

1、.csv 文件是 逗号分隔值(Comma-Separated Values)文件的缩写,但实际上可以使用任何字符作为分隔符,只要在读取或写入时与数据的格式一致。注意:CSV 文件格式并没有严格规定如何处理特殊字符(如逗号、换行符),因此在有特殊字符的情况下(如数据字段中包含逗号),通常会使用引号(")来包围数据字段,以确保格式正确。如:
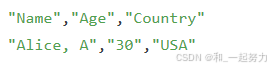
2、!写入文件时的格式设计会直接影响读取文件的难易程度。在设计文件格式时,需要充分考虑如何方便后续的读取和解析。
2、查看往届记录
2.1在speechManager.h中添加属性

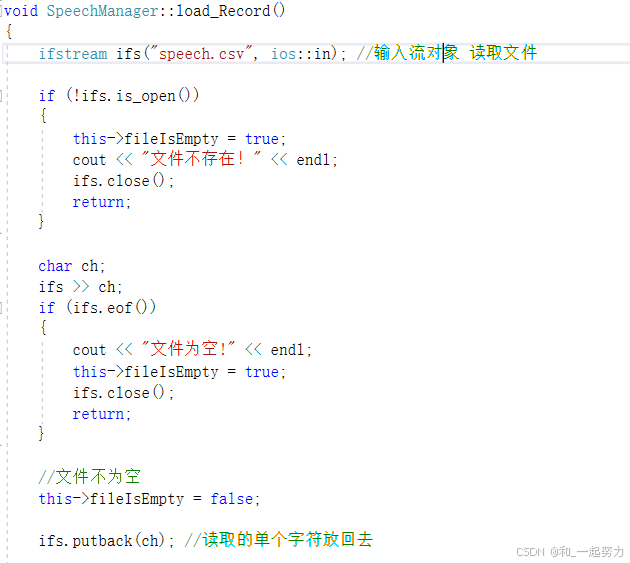
1、为什么选择 map<int, vector<string>>?
①需求分析
-
存储多届记录:需要存储多届比赛的冠、亚、季军信息。
-
每届记录包含多个字段:每届比赛的记录包含多个选手的编号和得分。
-
快速检索:需要能够快速检索某一届比赛的记录。
②优势
-
map的优势:-
键值对映射:
map是一种关联容器,可以通过键(key)快速查找值(value)。 -
自动排序:
map会根据键自动排序,方便按届数顺序存储和检索记录。
-
-
vector<string>的优势:-
动态数组:
vector可以动态存储多个字符串,适合存储每届比赛的多个字段(如选手编号和得分)。 -
灵活性:
vector可以存储任意数量的字段,适合不确定字段数量的场景。
-
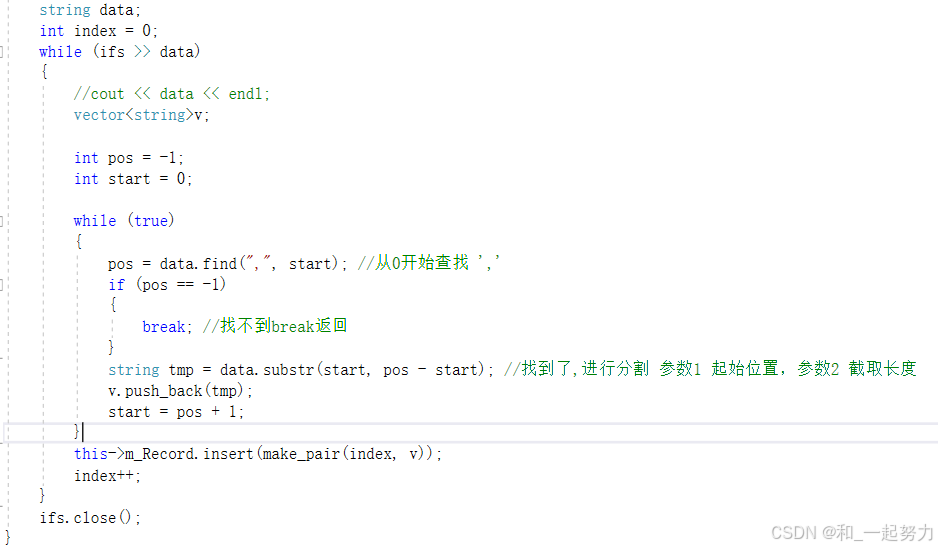
2、ifs.putback(ch); //读取的单个字符放回去。
3、loadRecord() 函数在读取 CSV 文件时,充分利用了逗号作为分隔符的特性,通过 find() 和 substr() 函数,动态提取每个字段,巧妙地解析了文件内容。
4、在 data = "10001,85.5,10002,92.3,10003,78.9," 这个例子中,start = 38 指向的是字符串的末尾,也就是最后一个逗号后面的位置。这个位置 没有实际字符,因此可以认为它是一个 空字符 或者说是 字符串的结束位置。不过,并没有任何空字符串被插入到vector中。
!不要忘记在SpeechManager构造函数中调用获取往届记录函数。
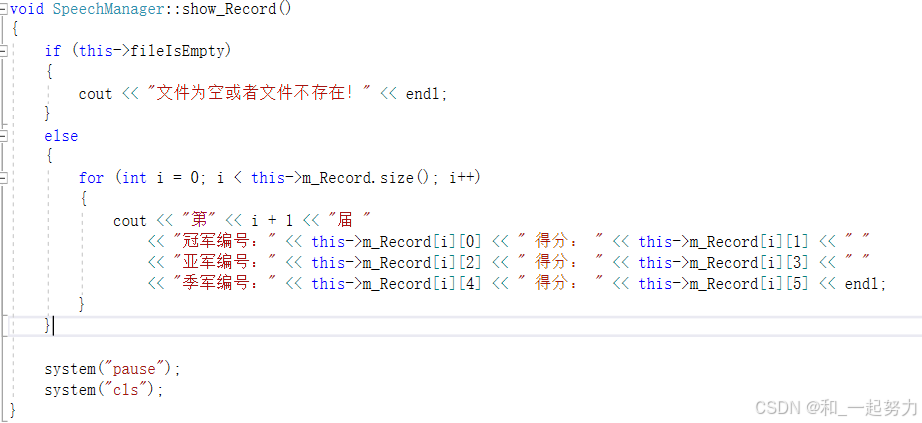
1、save_Record中更新文件为空的标志:防止记录为空或不存在,比完赛后依然提示记录为空。
2、比赛完毕后,所有数据重置:

3、init_Speech中添加初始化记录容器:this->m_Record.clear();
4、在main函数一开始,添加随机数种子:srand((unsigned int)time(NULL));
3、清空记录
确保程序在清空比赛记录后能够恢复到初始状态。

















 154
154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









