






正则表达式
正则表达式是一种描述一组字符串的模式,为处理大量文本、字符串而定义的一套规则和方法,以行为单位进行处理。正则表达式分为两类:基本正则表达式(BRE)和扩展正则表达式(ERE)。在linux中使用正则表达式较多的有三个工具,分别为grep,sed和awk,这三个工具被称为linux文本处理的三剑客。
正则表达式元字符集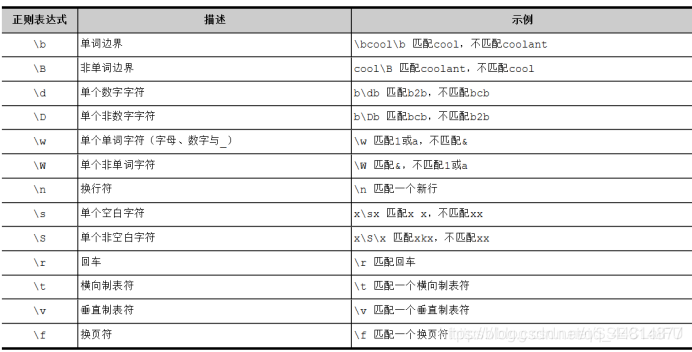
基本组成部分
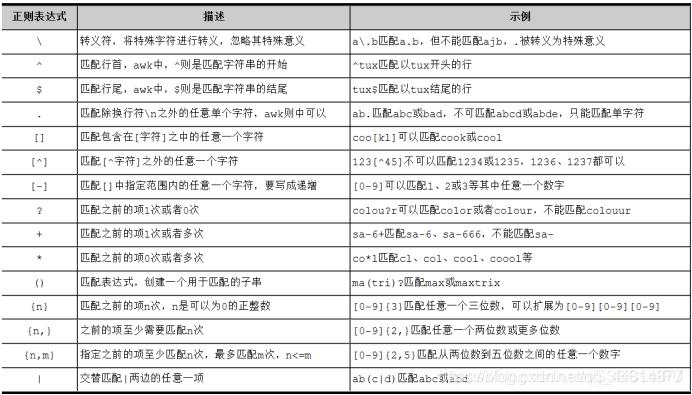
grep
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
、grep主要参数
[options]主要参数:
-a或–text 不要忽略二进制的数据。
-A<显示列数>或–after-context=<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之后的内容。
-b或–byte-offset 在显示符合范本样式的那一列之前,标示出该列第一个字符的位编号。
-B<显示列数>或–before-context=<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前的内容。
-c或–count 计算符合范本样式的列数。
-C<显示列数>或–context=<显示列数>或-<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作>或–directories=<进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-e<范本样式>或–regexp=<范本样式> 指定字符串做为查找文件内容的范本样式。
-E或–extended-regexp 将范本样式为延伸的普通表示法来使用。
-f<范本文件>或–file=<范本文件> 指定范本文件,其内容含有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每列一个范本样式。
-F或–fixed-regexp 将范本样式视为固定字符串的列表。
-G或–basic-regexp 将范本样式视为普通的表示法来使用。
-h或–no-filename 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H或–with-filename 在显示符合范本样式的那一列之前,表示该列所属的文件名称。
-i或–ignore-case 忽略字符大小写的差别。
-l或–file-with-matches 列出文件内容符合指定的范本样式的文件名称。
-L或–files-without-match 列出文件内容不符合指定的范本样式的文件名称。
-n或–line-number 在显示符合范本样式的那一列之前,标示出该列的列数编号。
-q或–quiet或–silent 不显示任何信息。
-r或–recursive 此参数的效果和指定“-d recurse”参数相同。
-s或–no-messages 不显示错误信息。
-v或–revert-match 反转查找。
-V或–version 显示版本信息。
-w或–word-regexp 只显示全字符合的列。
-x或–line-regexp 只显示全列符合的列。
-y 此参数的效果和指定“-i”参数相同。
–help 在线帮助。
sed简介

sed 是一种新型的,非交互式的编辑器。它能执行与编辑器 vi 和 ex 相同的编辑任务。sed 编辑器没有提供交互式使用方式,使用者只能在命令行输入编辑命令、指定文件名,然后在屏幕上查看输出。sed 编辑器没有破坏性,它不会修改文件,除非使用 shell 重定向来保存输出结果。默认情况下,所有的输出行都被打印到屏幕上。
sed 工作过程
sed 编辑器逐行处理文件(或输入),并将输出结果发送到屏幕。sed 的命令就是在 vi和 ed/ex 编辑器中见到的那些。sed 把当前正在处理的行保存在一个临时缓存区中,这个缓存区称为模式空间或临时缓冲。sed 处理完模式空间中的行后(即在该行上执行 sed 命令后),就把该行发送到屏幕上(除非之前有命令删除这一行或取消打印操作)。sed 每处理完输入文件的最后一行后,sed 便结束运行。sed 把每一行都存在临时缓存区中,对这个副本进行编辑,所以不会修改或破坏源文件。如图 1:sed 处理过程。
sed命令使用
常用选项:
-n 使用安静模式,在一般情况所有的 STDIN 都会输出到屏幕上,加入-n 后只打印被 sed 特殊处理的行
-e 多重编辑,且命令顺序会影响结果
-f 指定一个 sed 脚本文件到命令行执行,
-r Sed 使用扩展正则
-i 直接修改文档读取的内容,不在屏幕上输出
Sed操作命令
sed 操作命令告诉 sed 如何处理由地址指定的各输入行。如果没有指定地址,sed 就会处理输入的所有的行
x:指定行号。
x,y:指定从x到y的行号范围
/ pattern/:查询包含模式的行 # # % %
/ pattern/ pattern/:查询包含两个模式的行
/ pattern/,x:从与 pattern的匹配行到x号行之间的行
x,/ pattern/:从x号行到与 pattern的匹配行之间的行
x,y!:查询不包括x和y行号的行
r:从另一个文件中读文件
w:将文本写入到一个文件
y:变换字符
q:第一个模式匹配完成后退出
l:显示与八进制ASCⅡ码等价的控制字符
{}:在定位行执行的命令组
p:打印匹配行
=:打印文件行号。
a:在定位行号之后追加文本信息
i:在定位行号之前插入文本信息。
d:删除定位行
c:用新文本替换定位文本
s:使用替换模式替换相应模式
n:读取下一个输入行,用下一个命令处理新的行
N:将当前读入行的下一行读取到当前的模式空间。
h:将模式缓冲区的文本复制到保持缓冲区
H:将模式缓冲区的文本追加到保持缓冲区
x:互换模式缓冲区和保持缓冲区的内容
g:将保持缓冲区的内容复制到模式缓冲区
G:将保持缓冲区的内容追加到模式缓冲区。
awk
awk 是一种很棒的语言,它适合文本处理和报表生成,其语法较为常见,借鉴了某些语言的一些精华,如 C 语言等。在 linux 系统日常处理工作中,发挥很重要的作用,掌握了 awk将会使你的工作变的高大上。awk 是三剑客的老大,利剑出鞘,必会不同凡响。
1、awk 的原理
通过一个简短的命令,我们来了解其工作原理。
awk ‘{print $0}’ /etc/passwd
echo hhh|awk ‘{print “hello,world”}’
awk ‘{ print “hiya” }’ /etc/passwd
通过第一个指令你将会见到/etc/passwd 文件的内容出现在眼前。现在,解释 awk 做了些什么。调用 awk时,我们指定/etc/passwd 作为输入文件。执行 awk 时,它依次对/etc/passwd 中的每一行执行 print 命令。所有输出都发送到 stdout,所得到的结果与执行 cat /etc/passwd 完全相同。现在,解释{ print }代码块。在 awk 中,花括号用于将几块代码组合到一起,这一点类似于 C 语言。在代码块中只有一条 print 命令。在 awk 中,如果只出现 print 命令,那么将打印当前行的全部内容

















 3127
3127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









