







 这篇博客介绍了大数据课程中离线项目第二天的内容,重点关注Flume的Sinks,如HDFS、Hive、HBase、Avro等,并探讨了如何收集Java请求数据和ETL准备,包括过滤脏数据、IP到地域解析、设计rowkey等。
这篇博客介绍了大数据课程中离线项目第二天的内容,重点关注Flume的Sinks,如HDFS、Hive、HBase、Avro等,并探讨了如何收集Java请求数据和ETL准备,包括过滤脏数据、IP到地域解析、设计rowkey等。

@R星校长
离线项目第二天
flume sinks
HDFS Sink (使用较多)
| 属性名称 | 默认值 | 说明 |
|---|---|---|
| channel | - | |
| type | - | 组件类型名称,必须是hdfs |
| hdfs.path | - | HDFS路径,如hdfs://mycluster/flume/mydata |
| hdfs.filePrefix | FlumeData | flume在hdfs目录中创建文件的前缀 |
| hdfs.fileSuffix | - | flume在hdfs目录中创建文件的后缀。 |
| hdfs.inUsePrefix | - | flume正在写入的临时文件的前缀 |
| hdfs.inUseSuffix | .tmp | flume正在写入的临时文件的后缀 |
| hdfs.rollInterval | 30 | 多长时间写一个新的文件 (0 = 不写新的文件),单位秒 |
| hdfs.rollSize | 1024 | 文件多大写新文件单位字节(0: 不基于文件大小写新文件) |
| hdfs.rollCount | 10 | 当写一个新的文件之前要求当前文件写入多少事件(0 = 不基于事件数写新文件) |
| hdfs.idleTimeout | 0 | 多长时间没有新增事件则关闭文件(0 = 不自动关闭文件) |
| hdfs.batchSize | 100 | 写多少个事件开始向HDFS刷数据 |
| hdfs.codeC | - | 压缩格式:gzip, bzip2, lzo, lzop, snappy |
| hdfs.fileType | SequenceFile | 当前支持三个值:SequenceFile,DataStream,CompressedStream。(1)DataStream不压缩输出文件,不要设置codeC (2)CompressedStream 必须设置codeC |
| hdfs.maxOpenFiles | 5000 | 最大打开多少个文件。如果数量超了则关闭最旧的文件 |
| hdfs.minBlockReplicas | - | 对每个hdfs的block设置最小副本数。如果不指定,则使用hadoop的配置的值。1 |
| hdfs.writeFormat | - | 对于sequence file记录的类型。Text或者Writable(默认值) |
| hdfs.callTimeout | 10000 | 为HDFS操作如open、write、flush、close准备的时间。如果HDFS操作很慢,则可以设置这个值大一点儿。单位毫秒 |
| hdfs.threadsPoolSize | 10 | 每个HDFS sink的用于HDFS io操作的线程数 (open, write, etc.) |
| hdfs.rollTimerPoolSize | 1 | 每个HDFS sink使用几个线程用于调度计时文件滚动。 |
| hdfs.round | false | 支持文件夹滚动的属性。是否需要新建文件夹。如果设置为true,则会影响所有的基于时间的逃逸字符,除了%t。 |
| hdfs.roundValue | 1 | 该值与roundUnit一起指定文件夹滚动的时长,会四舍五入 |
| hdfs.roundUnit | second | 控制文件夹个数。多长时间生成新文件夹。可以设置为- second, minute 或者 hour. |
| hdfs.timeZone | Local Time | Name of the timezone that should be used for resolving the directory path, e.g. America/Los_Angeles. |
| hdfs.useLocalTimeStamp | false | 一般设置为true,使用本地时间。如果不使用本地时间,要求flume发送的事件header中带有时间戳。该时间用于替换逃逸字符 |
支持的逃逸字符:
| 别名 | 描述 |
|---|---|
| %t | Unix时间戳,毫秒 |
| %{host} | 替换名为"host"的事件header的值。支持任意标题名称。 |
| %a | 星期几的短名,即Mon, Tue, … |
| %A | 星期几的全名,即Monday, Tuesday, … |
| %b | 月份短名,即Jan, Feb, … |
| %B | 月份全名,即January, February, … |
| %c | 时间和日期,即Thu Mar 3 23:05:25 2005 |
| %d | day of month (01) |
| %e | day of month without padding (1) |
| %D | date; same as %m/%d/%y |
| %H | hour (00…23) |
| %I | hour (01…12) |
| %j | day of year (001…366) |
| %k | 小时 ( 0…23) |
| %m | 月份 (01…12) |
| %n | 不加前缀的月份 (1…12) |
| %M | 分钟(00…59) |
| %p | locale’s equivalent of am or pm |
| %s | seconds since 1970-01-01 00:00:00 UTC |
| %S | second (00…59) |
| %y | 年份最后两位 (00…99) |
| %Y | year (2010) |
| %z | +hhmm数字时区 (for example, -0400) |
案例1
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/data/access.log
# Describe the sink
a1.sinks.k1.type = hdfs
# 时间会四舍五入
#a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/%S
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.useLocalTimeStamp=true
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
案例2:
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/data/access.log
# Describe the sink
a1.sinks.k1.type = hdfs
# 时间会四舍五入
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.rollInterval=0
a1.sinks.k1.hdfs.rollSize=0
# 10个记录写到一个文件中,然后滚动输出
a1.sinks.k1.hdfs.rollCount=10
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 2
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.useLocalTimeStamp=true
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
案例 3:滚动文件夹
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/data/myfile.log
# Describe the sink
a1.sinks.k1.type = hdfs
# 时间会四舍五入
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.rollInterval=5
a1.sinks.k1.hdfs.rollSize=0
a1.sinks.k1.hdfs.rollCount=0
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = second
a1.sinks.k1.hdfs.useLocalTimeStamp=true
a1.sinks.k1.hdfs.callTimeout=60000
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
思考:
1、flume如何收集java请求数据
2、项目当中如何来做? 日志存放/log/目录下 以 yyyyMMdd 为子目录 分别存放每天的数据
Hive Sink(使用较多)
| 属性名 | 默认值 | 说明 |
|---|---|---|
| channel | - | |
| type | - | 组件类型名称,必须是 hive |
| hive.metastore | - | 元数据仓库地址,如 thrift://node2:9083 |
| hive.database | - | 数据库名称 |
| hive.table | - | 表名 |
| hive.partition | - | 逗号分割的分区值,标识写到哪个分区 可以包含逃逸字符 如果表分区字段为:(continent: string, country :string, time : string) 则"Asia,India,2014-02-26-01-21"表示continent为Asia country为India,time是2014-02-26-01-21 |
| callTimeout | 10000 | Hive和HDFS的IO操作超时时间,比如openTxn,write,commit,abort等操作。单位毫秒 |
| batchSize | 15000 | 一个hive的事务允许写的事件最大数量。 |
| roundUnit | minute | 控制多长时间生成一个文件夹的单位:second,minute,hour |
HBase Sink(使用较多)
| 属性名称 | 默认值 | 描述 |
|---|---|---|
| channel | - | |
| type | - | 组件类型名称,必须是hbase |
| table | - | hbase的表名 |
| columnFamily | - | 列族的名称 |
| zookeeperQuorum | - | 对应于hbase-site.xml中hbase.zookeeper.quorum的值,指定zookeeper 集群地址列表。 |
Logger Sink
Avro Sink(使用较多)
Thrift Sink(使用较多)
a1.sinks.k1.type=thrift
a1.sinks.k1.hostname=node3 连谁?
a1.sinks.k1.port=8888 对方端口
File Roll Sink
ElasticSearchSink(使用较多)
Kafka Sink(使用较多)
flume channel
Memory Channel
a1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
JDBC Channel
a1.channels = c1
a1.channels.c1.type = jdbc
File Channel
Kafka Channel
flume 的项目设置配置
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/data/access.log
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /log/%Y%m%d
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.rollSize = 10240000
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.callTimeout = 60000
#防止sequence file的前缀字符,修改为DataStream
a1.sinks.k1.hdfs.fileType = DataStream
# 10s关闭hdfs连接。
a1.sinks.k1.hdfs.idleTimeout = 10
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
ETL 准备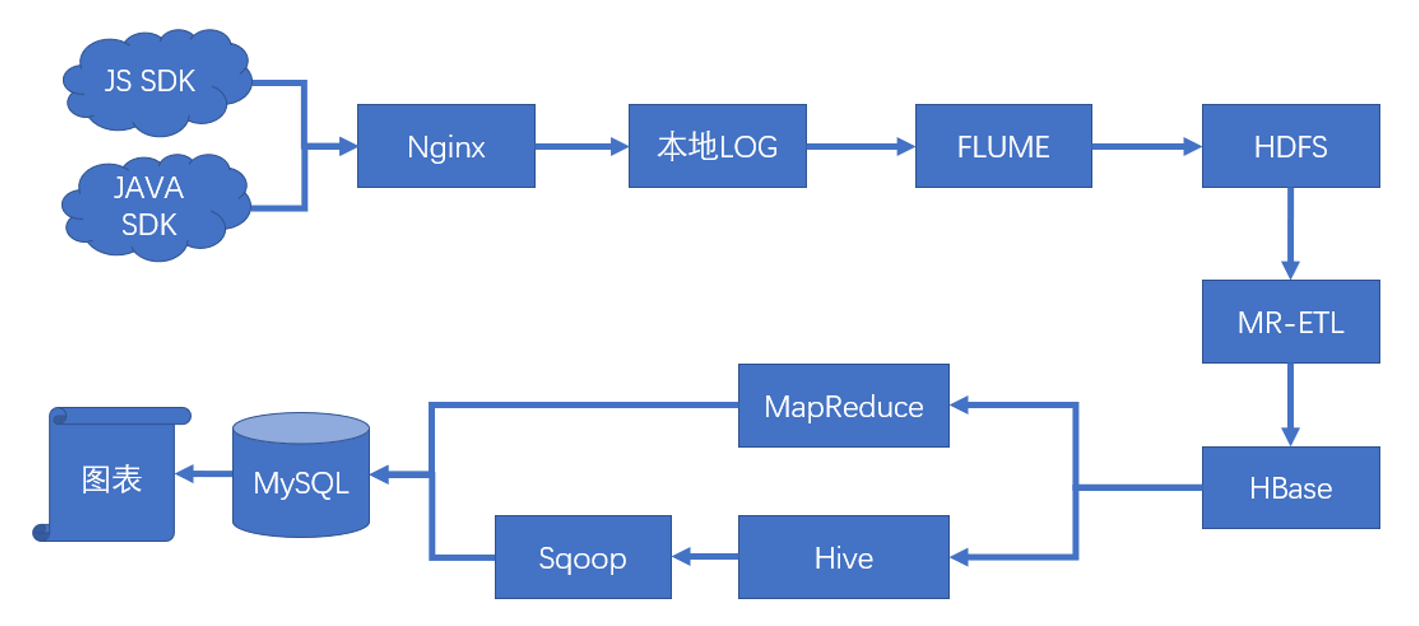
过滤脏数据
解析 IP 地址到地域
用于解析 IP 地址到地域。
http://ip.taobao.com/index.html
qqwry.dat 保存了 ip 地址到地域的对应关系。
第三方的工具类直接用。
IPSeekerExt
浏览器相关信息
解析UserAgent
uasparser-0.6.1.jar
设计 rowkey
解析思路:
192.168.100.1^A1574736498.958^Anode1^A/log.gif?en=e_e&ca=event%E7%9A%84category%E5%90%8D%E7 %A7%B0&ac=event%E7%9A%84action%E5%90%8D%E7%A7%B0&kv_key1=value1&kv_key2=value2&du=1245&ver= 1&pl=website&sdk=js&u_ud=8D4F0D4B-7623-4DB2-A17B-83AD72C2CCB3&u_mid=zhangsan&u_sd=9C7C0951- DCD3-47F9-AD8F-B937F023611B&c_time=1574736499827&l=zh-CN&b_iev=Mozilla%2F5.0%20(Windows%20N T%2010.0%3B%20Win64%3B%20x64)%20AppleWebKit%2F537.36%20(KHTML%2C%20like%20Gecko)%20Chrome%2 F78.0.3904.108%20Safari%2F537.36&b_rst=1360*768
============================
192.168.100.1
换算成地域
1574736498.958
时间
node1
/log.gif?en=e_e&ca=event%E7%9A%84category%E5%90%8D%E7 %A7%B0&ac=event%E7%9A%84action%E5%90%8D%E7%A7%B0&kv_key1=value1&kv_key2=value2&du=1245&ver= 1&pl=website&sdk=js&u_ud=8D4F0D4B-7623-4DB2-A17B-83AD72C2CCB3&u_mid=zhangsan&u_sd=9C7C0951- DCD3-47F9-AD8F-B937F023611B&c_time=1574736499827&l=zh-CN&b_iev=Mozilla%2F5.0%20(Windows%20N T%2010.0%3B%20Win64%3B%20x64)%20AppleWebKit%2F537.36%20(KHTML%2C%20like%20Gecko)%20Chrome%2 F78.0.3904.108%20Safari%2F537.36&b_rst=1360*768
int index = request.indexOf("?");
String sub0 = request.substring(index + 1);
en=e_e&ca=event%E7%9A%84category%E5%90%8D%E7 %A7%B0&ac=event%E7%9A%84action%E5%90%8D%E7%A7%B0&kv_key1=value1&kv_key2=value2&du=1245&ver= 1&pl=website&sdk=js&u_ud=8D4F0D4B-7623-4DB2-A17B-83AD72C2CCB3&u_mid=zhangsan&u_sd=9C7C0951- DCD3-47F9-AD8F-B937F023611B&c_time=1574736499827&l=zh-CN&b_iev=Mozilla%2F5.0%20(Windows%20N T%2010.0%3B%20Win64%3B%20x64)%20AppleWebKit%2F537.36%20(KHTML%2C%20like%20Gecko)%20Chrome%2 F78.0.3904.108%20Safari%2F537.36&b_rst=1360*768
String[] sub0s = sub0.split("&");
Map map =
for (String substr : sub0s) {
parts = substr.split("=");
map.put(parts[0], parts[1])
}
rowkey设计
rowkey带时间_ crc32()
put("rowkey".getBytes);
for (Entry<String, STRING> ENTRY : MAP.ENTRYSET()) {
put.add("CF".GETBYTES(), ENTRY.GETkEY().GETBYTES(), NETRY.GETVALUE.GETBYTES)
}
ETL 代码讲解
1、创建表:
hbase 表名:eventlog 列族:log


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









