




 本文详细介绍了numpy的ndarray对象,包括其四个关键属性:维度(ndim)、形状(shape)、长度(size)和数据类型(dtype)。探讨了基本操作,如索引、切片、反转、reshape变形、级联和切分,并强调了创建副本以防止数据意外修改的重要性。
本文详细介绍了numpy的ndarray对象,包括其四个关键属性:维度(ndim)、形状(shape)、长度(size)和数据类型(dtype)。探讨了基本操作,如索引、切片、反转、reshape变形、级联和切分,并强调了创建副本以防止数据意外修改的重要性。
属性
4个必记参数:
ndim:维度
shape:形状(各维度的长度)
size:总长度
dtype:元素类型
基本操作
1.索引
一维时和列表一样,基本索引和切片得到的结果都是原始数组的视图,修改视图也会修改原始数组,想得到副本,用.copy()
注意: 索引是一层一层的往里面进的

根据索引修改数据

2. 切片
一维与列表完全一致, 多维时同理

注意:切片也是左闭右开
3.将数反转
1.上下反转
可以看出,只是第一个和第三个的位置交换了,里面的数据还是没有变的

2.里面的行业也反转一下
发现,15这一行跑到下面去了,行的顺序也变了

3.只反转里面的行
和最开始的相比,里面的行数反转了,但是总体的大的没有变
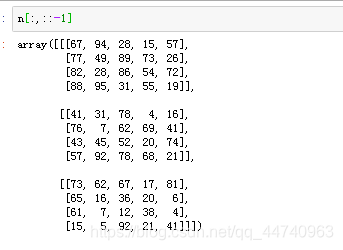
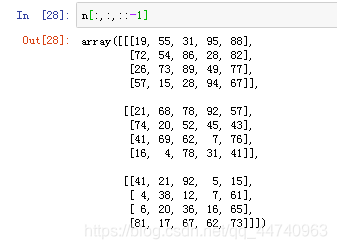
4.只反转里面的列
3.变形 reshape()
参数是一个元祖
变形后,总元素个数不能发生变化
例如:
如果原来的n.shape为(3,4,5)
你可以 n.reshape(5,12)或者(3,20)
n.reshape(3,20)与(3,-1)效果一样
4.级联
- np.concatenate()
级联需要注意的点:
- 级联的参数是列表:一定要加中括号或小括号
- 维度必须相同
- 形状相符
- 【重点】级联的方向默认是shape这个tuple的第一个值所代表的维度方向
- 可通过axis参数改变级联的方向
水平级联, axis=1,水平级联要求行数一致
np.concatenate((n1,n2), axis=1)
垂直级联,axis=0, 要求列数一致
np.concatenate((n1,n2), axis=0)
- np.hstacky()与np.vstack()
h = horizontal 水平
v = vertical 垂直
5.切分
与级联类似,三个函数完成切分工作:
np.split
np.vsplit
np.hsplit
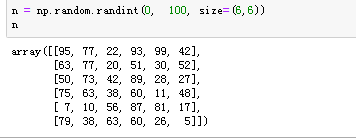
现在有一个ndararry
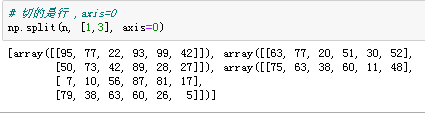
np.split(n, [1,3], axis=0) # 对行进行切分
np.split(n, [1,3], axis=1) # 对列进行切分
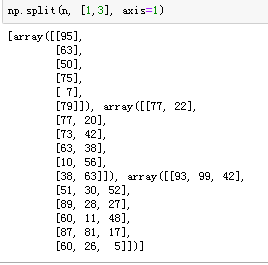
np.vsplit(n, [1,3]) 与 np.split(n, [1,3], axis=0) 一样
np.hsplit(n, [1,3]) 与 np.split(n, [1,3], axis=1) 一样
6. 副本
所有赋值运算不会为ndarray的任何元素创建副本。对赋值后的对象的操作也对原来的对象生效。
就是说你通过某些函数改变了原始数组的数据,就算你从新让一个对象等于它,原始数组也还是会被改变
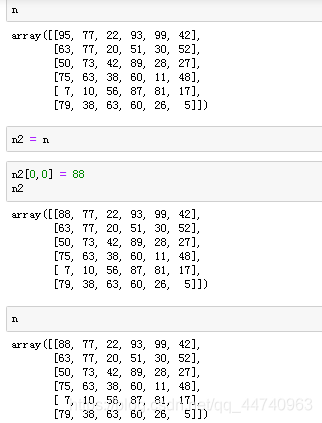
要是不想发生这种情况,应该使用副本,就是n2 = n.copy()
这样对n2的操作,与n没有关系

















 1153
1153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









