






因为一个一个的查看各个省份的招聘信息比较麻烦,且有的时候公告发布后一周内要报名,时常出现错过报名的情况o(╥﹏╥)o,故写个脚本每天查询一下各个官网有没有更新招聘公告,然后发送到我的邮箱内!
步骤:
1:拉取对应官网的招聘信息
2:对获得的信息进行抽取和处理成自己想要的格式
3:发送到自己的个人邮箱
4:放到服务器上持续运行(记得打开端口号)
效果如图:
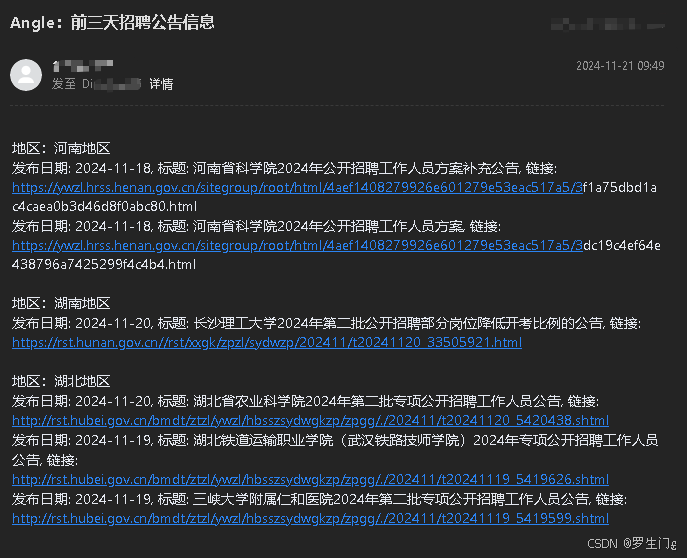
具体代码如下,你只需更改一下发送和接受的邮箱地址,以及有个自己的服务器就可以了。
import requests
import schedule
from bs4 import BeautifulSoup
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from datetime import datetime, timedelta
AllDataDict = {}
def getHuBeiData():
url = "http://rst.hubei.gov.cn/bmdt/ztzl/ywzl/hbsszsydwgkzp/zpgg/"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
now = datetime.now().date()
three_days_ago = now - timedelta(days=3)
announcements = soup.find('div', class_='col-xs-12 col-md-12').find('ul', class_='list-t border6').find_all('li')
recruitment_info_list = []
for announcement in announcements:
date_str = announcement.find('span', class_='date hidden-xs').text
date = datetime.strptime(date_str, '%Y-%m-%d').date()
title = announcement.find('a')['title']
link = announcement.find('a')['href']
if date >= three_days_ago:
recruitment_info_list.append({"date": date, "title": title, "link": link})
huBeiList = []
printed_titles = set()
for info in recruitment_info_list:
if info["title"] not in printed_titles:
huBeiList.append(f"发布日期: {info['date']}, 标题: {info['title']}, 链接: http://rst.hubei.gov.cn/bmdt/ztzl/ywzl/hbsszsydwgkzp/zpgg/{info['link']}")
printed_titles.add(info["title"])
AllDataDict["湖北地区"] = huBeiList
def getHunanData():
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
HuNanUrl = "https://rst.hunan.gov.cn/rst/xxgk/zpzl/sydwzp/index.html"
response = requests.get(HuNanUrl, verify=False)
soup = BeautifulSoup(response.content, 'html.parser')
now = datetime.now()
three_days_ago = now - timedelta(days=5)
tbody = soup.find('tbody', class_='table_list_st')
rows = tbody.find_all('tr')
hunanlist = []
for row in rows:
cells = row.find_all('td')
date_str = cells[2].text.strip()
date = datetime.strptime(date_str, '%Y-%m-%d')
if date >= three_days_ago:
href = cells[1].find('a')['href']
title = cells[1].find('a')['title']
hunanlist.append(f"发布日期: {date_str}, 标题: {title}, 链接: https://rst.hunan.gov.cn/{href}")
AllDataDict["湖南地区"] = hunanlist
def getHeNanData():
url = "https://ywzl.hrss.henan.gov.cn/viewCmsCac.do?cacId=4aef1408279926e601279e53eac517a5"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
now = datetime.now().date()
three_days_ago = now - timedelta(days=3)
rows = soup.find_all('tr')
recruitment_info_list = []
henanlist = []
for row in rows:
cells = row.find_all('td')
if len(cells) > 2:
date_str = cells[2].text.strip().replace('[', '').replace(']', '')
try:
date = datetime.strptime(date_str, '%Y-%m-%d').date()
except ValueError:
continue
title = cells[1].find('a')['title']
link = cells[1].find('a')['href']
if date >= three_days_ago:
recruitment_info_list.append({"date": date, "title": title, "link": link})
printed_titles = set()
for info in recruitment_info_list:
if info["title"] not in printed_titles:
henanlist.append(f"发布日期: {info['date']}, 标题: {info['title']}, 链接: https://ywzl.hrss.henan.gov.cn/{info['link']}")
printed_titles.add(info["title"])
AllDataDict["河南地区"] = henanlist
def getAllData():
getHeNanData()
getHunanData()
getHuBeiData()
def sendAngle():
sender_email = 'XXX@qq.com'
receiver_email = 'XXX@163.com'
password = '这里是邮箱授权码'
message = MIMEMultipart()
message['From'] = sender_email
message['To'] = receiver_email
message['Subject'] = 'Angle:前三天招聘公告信息'
body = ""
for region, announcements in AllDataDict.items():
body += f"地区:{region}\n"
for announcement in announcements:
body += announcement + "\n"
body += "\n"
message.attach(MIMEText(body, 'plain'))
try:
server = smtplib.SMTP('smtp.qq.com', 587)
server.starttls()
server.login(sender_email, password)
server.sendmail(sender_email, receiver_email, message.as_string())
print("邮件发送成功!")
except Exception as e:
print(f"邮件发送失败:{e}")
finally:
server.quit()
def job_task():
getAllData()
sendAngle()
schedule.every().day.at("09:30").do(job_task)
while True:
schedule.run_pending()
time.sleep(60)
希望大家都有一个光明的未来!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









