






1 简介
略
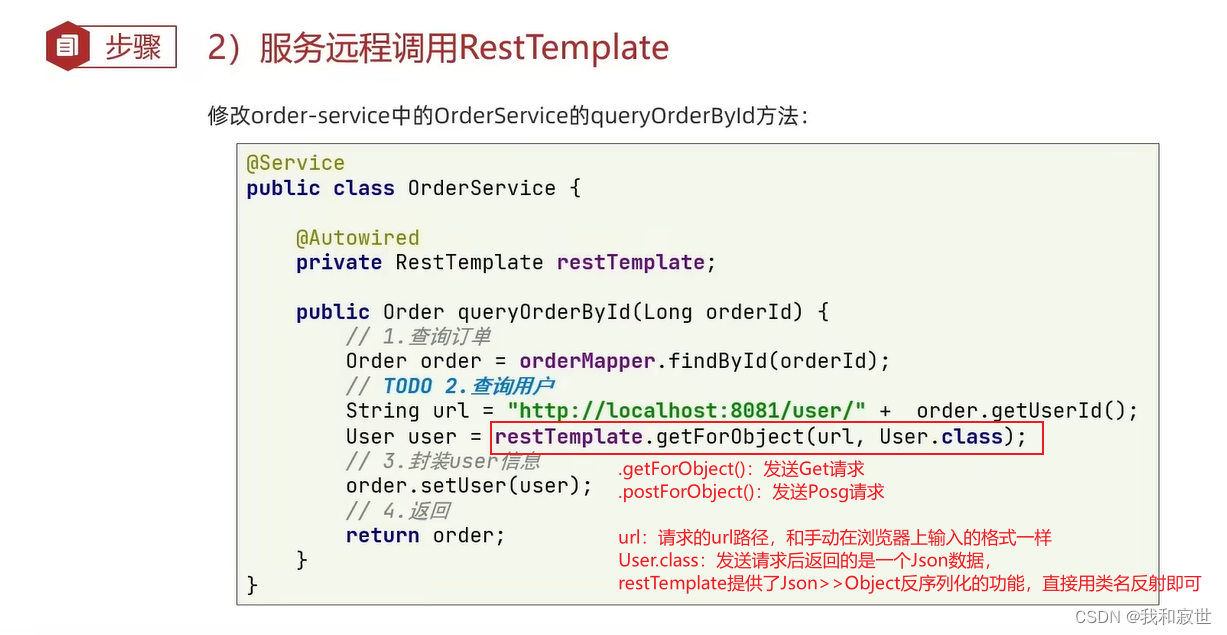
1.1 服务远程调用(RestTemplate)
RestTemplate用于模拟发送http的url请求,实现微服务多个组件之间的通信。
当一个组件想要请求另一个组件返回的数据时,就可以使用RestTemmpate。

2 Eureka
提供者与消费者:
- 服务提供者:暴露接口给其他微服务调用。
- 服务消费者:调用其他微服务暴露的接口。
- 提供者与消费者的角色是相对的,比如提供者可能也要调用其他微服务接口。
仅仅使用RestTemplate的问题:
- url采用硬编码的形式,如果从开发环境移植到了生产环境,那么ip地址就得手动改变,太麻烦。
- 部署多个相同的微服务组件进行负载均衡,这时怎么去选择使用哪个组件?只能由机器去寻找选择。
Eureka则解决了以上的问题,作用如下:
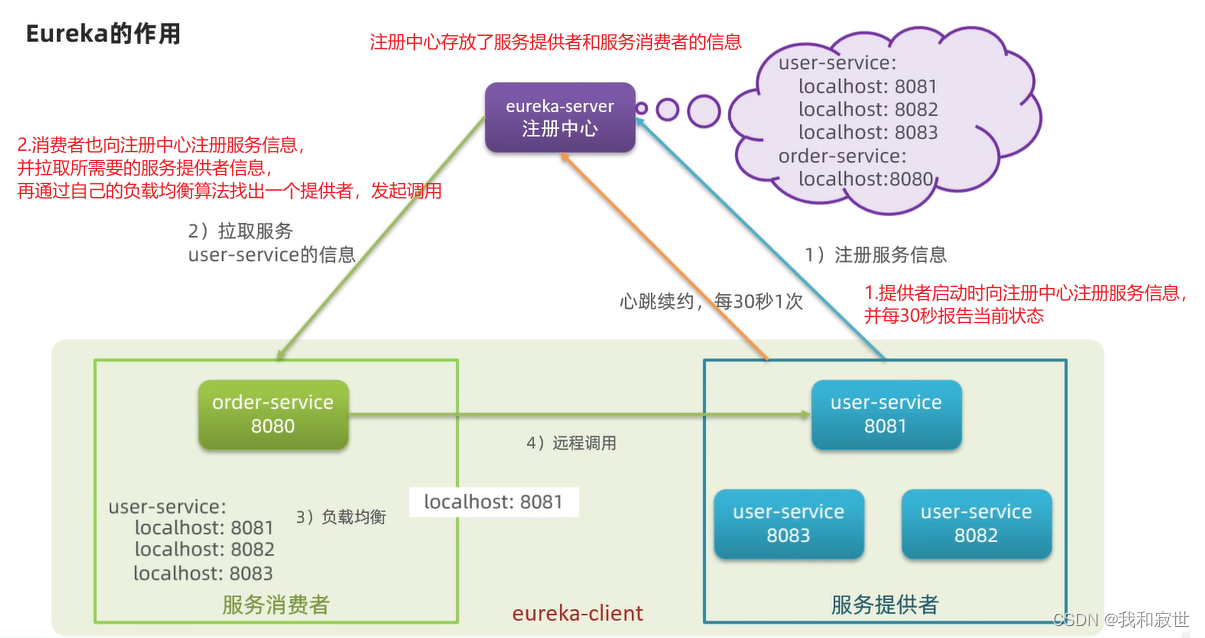
Eureka解决的问题:

总结:

2.1 Eureka使用
2.1.1 搭建Eureka
Eureka在注册时会将自己也注册到服务上,用于Eureka搭建集群时进行选择。
-
在项目中创建一个eureka模块(使用maven创建,spirng boot也行)
-
引入eureka依赖
<dependencies>
<!-- eureka服务端 -->
<!-- 父工程的spring cloud依赖中有指定版本 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
</dependencies>
- 如果使用maven创建,自行添加一个spring boot启动类,并且在启动类上使用注解@EnableEurekaServer开启Eureka
@SpringBootApplication
@EnableEurekaServer
public class eurekaApplication {
public static void main(String[] args) {
SpringApplication.run(eurekaApplication.class, args);
}
}
- 添加application.yml配置文件
server:
# 端口号自行定义一个
port: 10001
spring:
application:
# 定义该模块的名称
name: eureka-server
eureka:
client:
service-url:
# eureka的地址,如果是eureka集群,用逗号分隔,如:http://127.XXXX,http://192.XXXX
defaultZone: http://127.0.0.1:10001/eureka/
- 启动类启动,网页访问
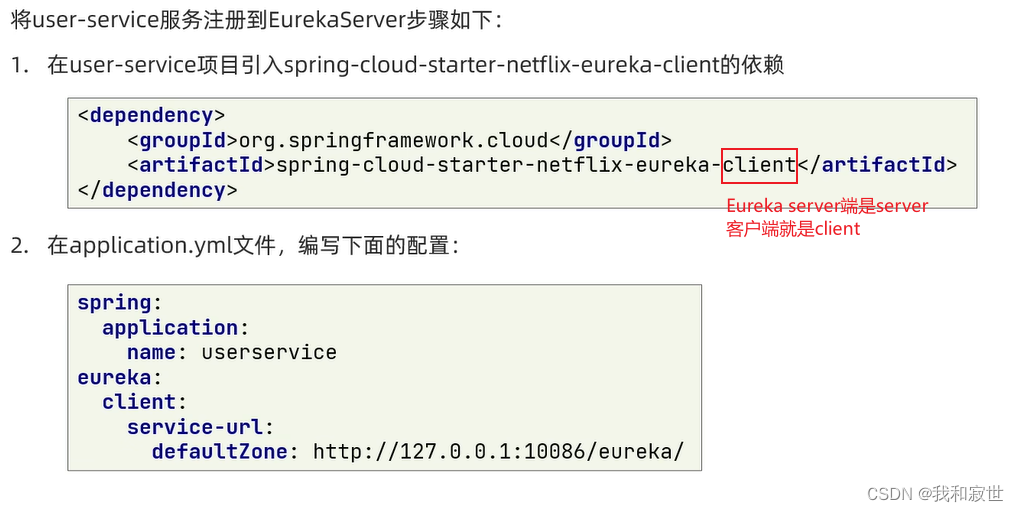
2.1.2 服务注册
- 服务提供者和服务消费者都要进行如下步骤
- 如果要进行模拟集群操作,进行如下配置:
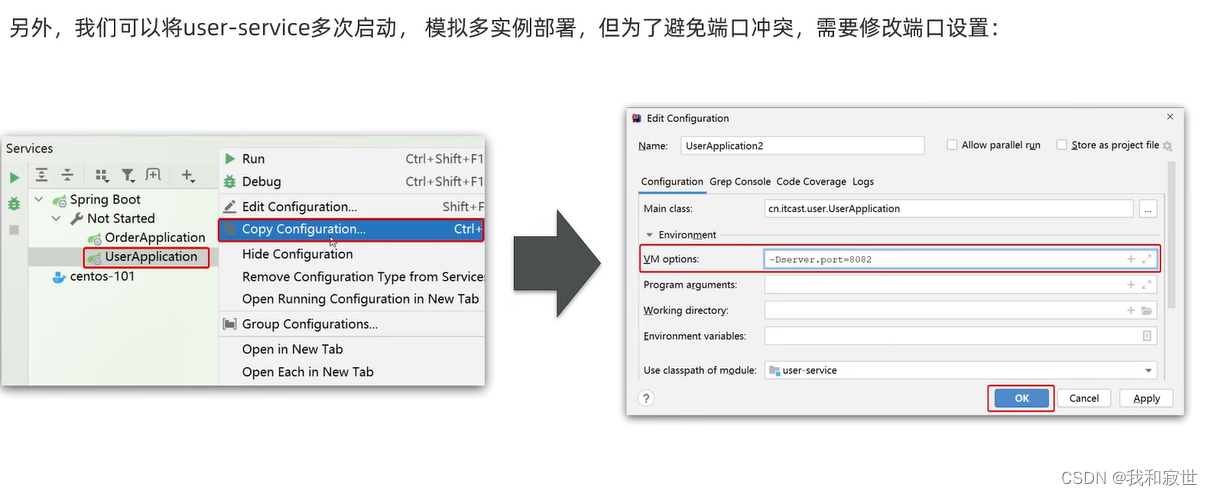
2.1.3 服务发现
之前是使用RestTemplate来和其他微服务组件通信,使用Eureka后,替换方案如下:
- 之前的URL是硬编码,现在将IP地址替换为服务名(服务名就是注册时的application.name)
//原URL
String url = "http://localhost:8081/user/" + order.getUserId();
//新URL
String url = "http://user-service:8081/user/" + order.getUserId();
- 在RestTemplate的Bean前加上@LoadBalanced注解,表示开启负载均衡(Spring Cloud提供的Ribbon实现)
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
2.1.4 Eureka使用总结
- 创建一个Eureka模块,导入Eureka server依赖,启动类上添加@EnableEurekaServer依赖,创建application.yml配置文件,启动网页即可访问。
- 服务提供者和消费者导入Eureka client依赖,添加application.yml配置向Eureka注册
- 服务消费者使用URL时,IP换为服务名,restTemplate上加上@LoadBalanced注解
3 Ribbon
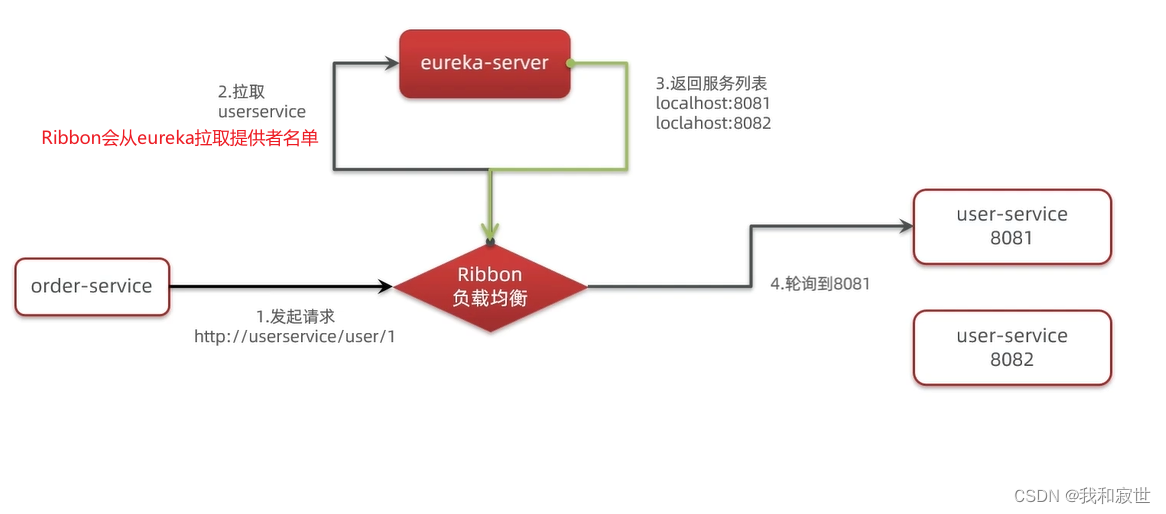
Ribbon是Spring Cloud的一个负载均衡组件,是基于客户端的负载均衡(表示在客户端里选择出访问哪个地址)。
Ribbon的工作流程如下:
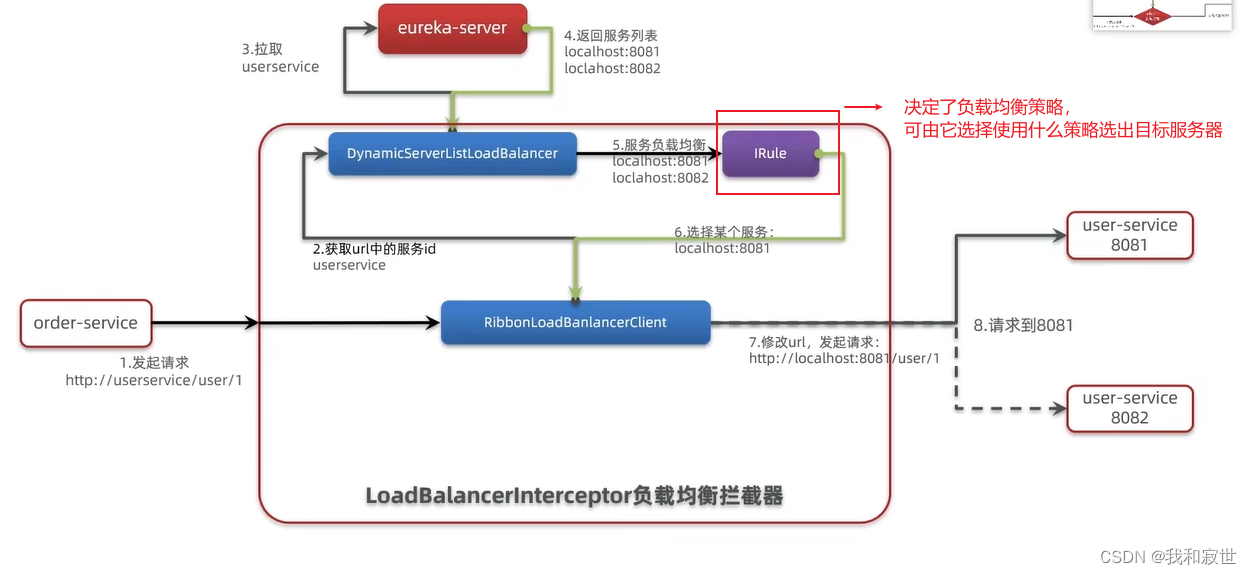
Ribbon实现负载均衡源码讲解
3.1 负载均衡策略
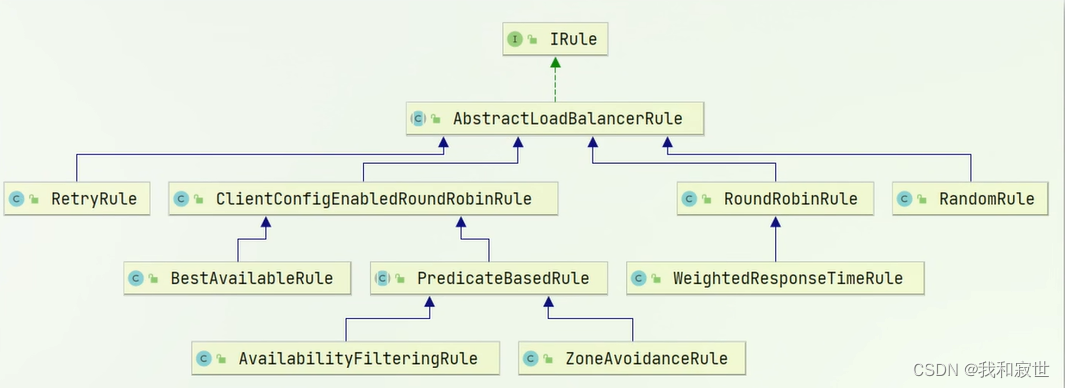
默认负载均衡策略是ZoneAvoidanceRule

如何选择使用哪个负载均衡:

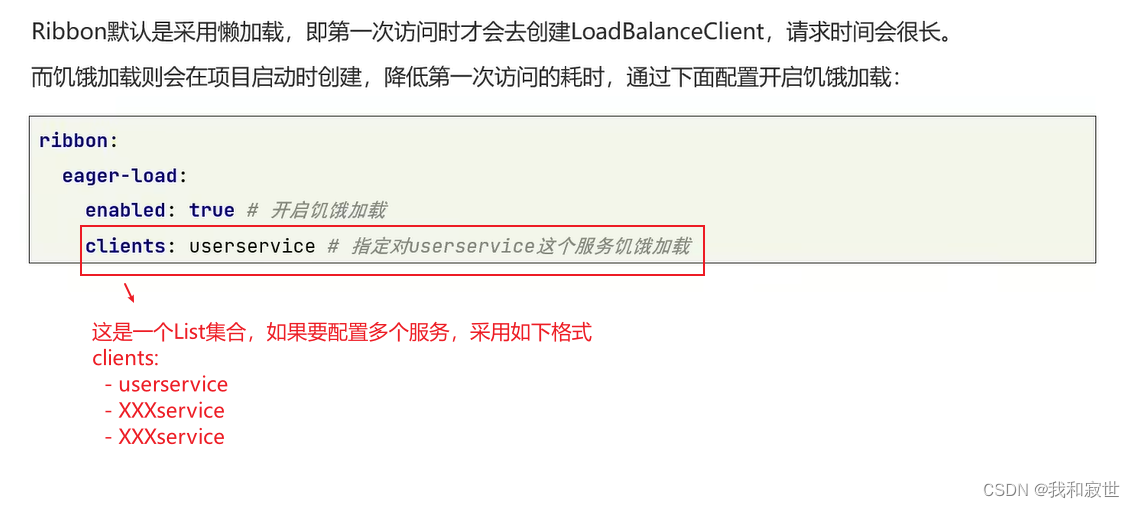
3.2 饥饿加载
4 Nacos
4.1 Nacos注册中心
4.1.1 快速入门
Nacos和Eureka都遵循着相同的规范,服务提供者和消费者的代码部分不需要改动,需要改动的是配置文件中Nacos的地址配置和Maven依赖。

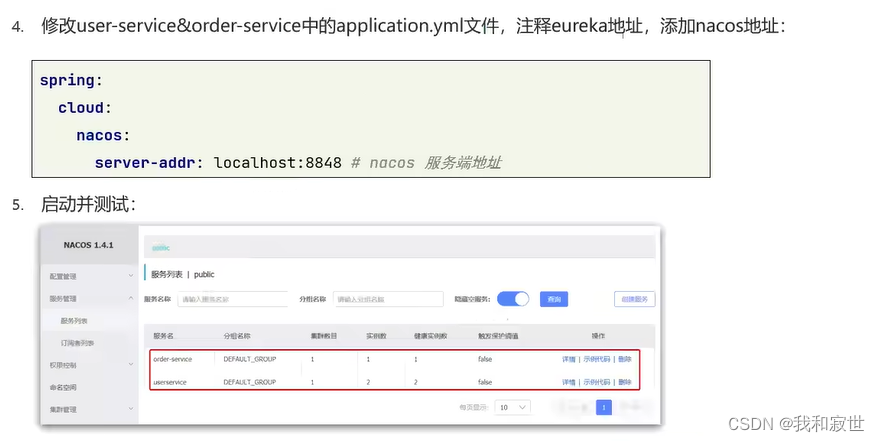
总结:
- 父工程中导spring-cloud-alibaba的依赖,子工程中导nacos的依赖(如果子工程有eureka依赖记得注释掉)。
- 子工程中在yml添加nacos配置(代码部分无需修改,因为和eureka遵守同样标准)。
4.1.2 服务分级存储模型
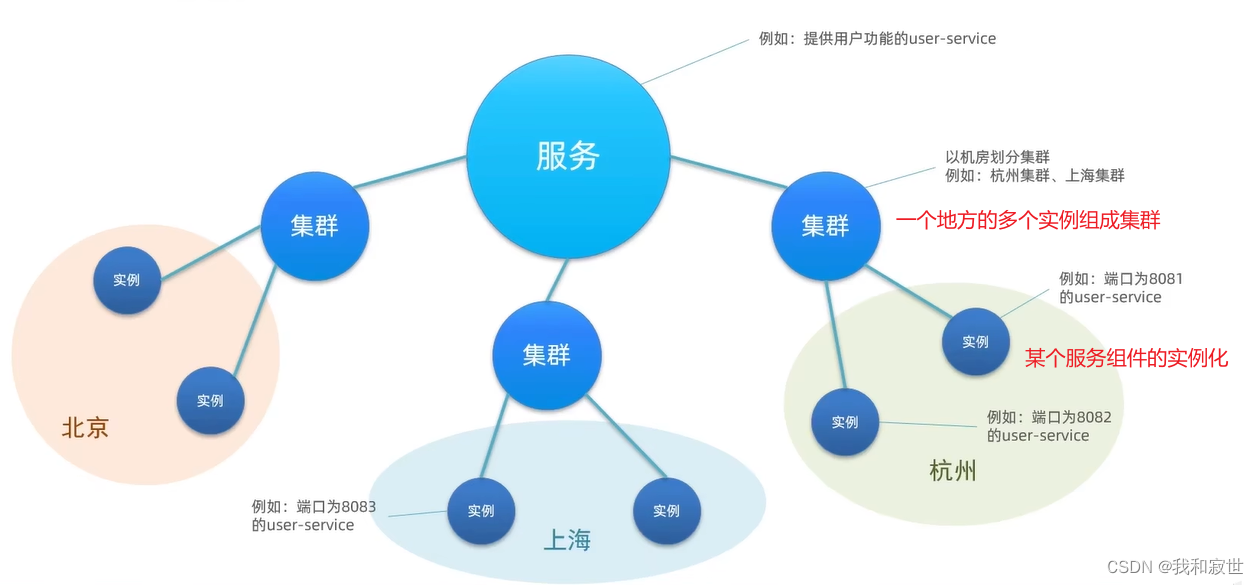
服务跨集群调用问题:
- 服务调用尽可能选择本地集群的服务,跨集群调用的延迟高(因为地理距离远)。
- 本地集群不可用时再去调其它集群。
那么如何配置集群?
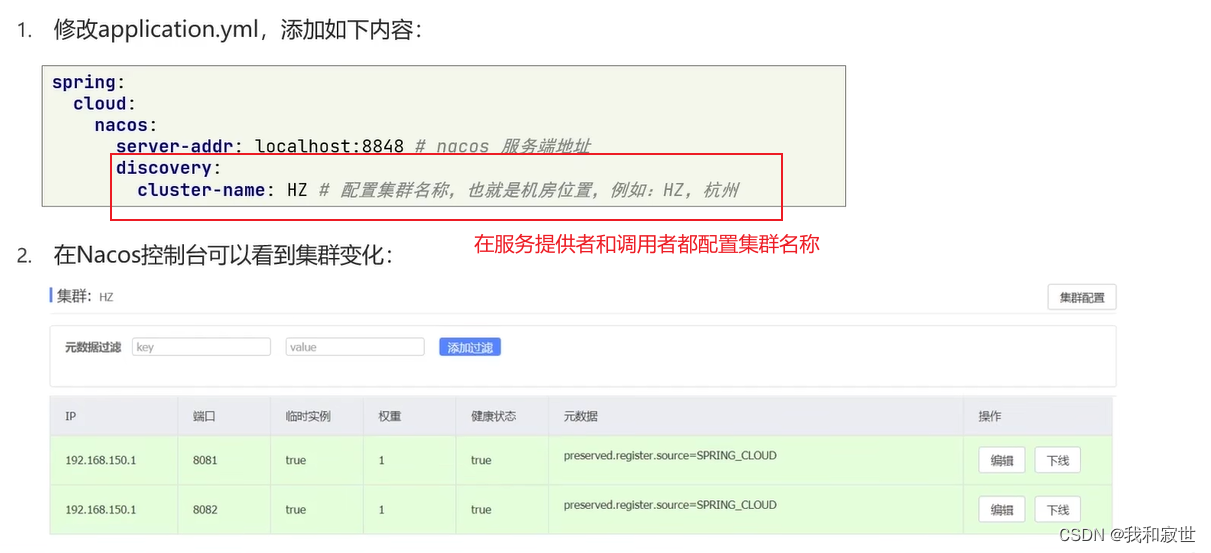
注意: 此时仅仅添加集群名,服务消费者在消费时默认还是会跨集群调用(因为有负载均衡规则存在)
解决办法: 修改Ribbon负载均衡的规则,方法如下

服务分级总结:
- 在yml中使用
cluster-name配置集群名称(提供者和消费者都要配)。 - 修改负载均衡规则为
NacosRule(默认的规则是在全集群下轮询,我们需要的是单个集群下的规则)。 - 可以在Nacos控制台设置权重(权重越大,被访问频率越高;权重为0不会被访问)。
4.1.3 环境隔离(NameSpace)

- Nacos中可以创建NameSpace,每个NameSpace之间是隔离的,不可互相访问(默认public)。
- NameSpace里也可以创建多个Group(默认DEFAULT_GROUP)。
- 默认NameSpace为public,一般就用这个。
创建使用NameSpace步骤如下:
- Nacos控制台>>命名空间>>新建命名空间>>创建后得到命名空间ID。
- 修改代码的yml,使用
namespace:将服务纳入指定空间中。
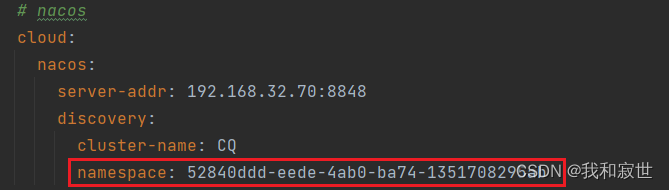
- 在Nacos控制台>>服务管理>>服务列表,可以看见多个NameSpace。
4.1.4 Nacos和Eureka对比
视频讲解
服务提供者健康检测:
-
nacos分为临时实例和非临时实例
A. 临时实例采用心跳检测(频率比eureka略快一点),主动向注册中心报告自己状态,如果实例挂掉了,会从注册中心剔除。
B. 非临时实例采用nacos主动询问服务提供者,如果实例挂掉了不会从注册中心剔除,而是nacos间隔询问实例是否live。

-
eureka只采用心跳检测的方式。
服务消费者请求注册中心:
- nacos采用pull和push的方式
A. PULL:消费者间隔时间向注册中心询问消费者信息。
B. PUSH:如果注册中心发现提供者挂了,会立即向消费者push提供者的状态信息。 - eureka只采用pull方式。
4.2 Nacos配置中心
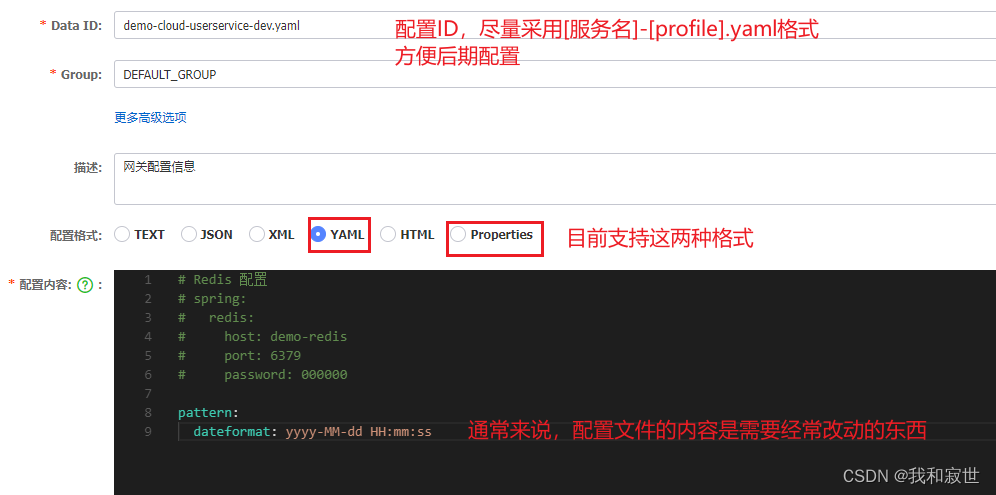
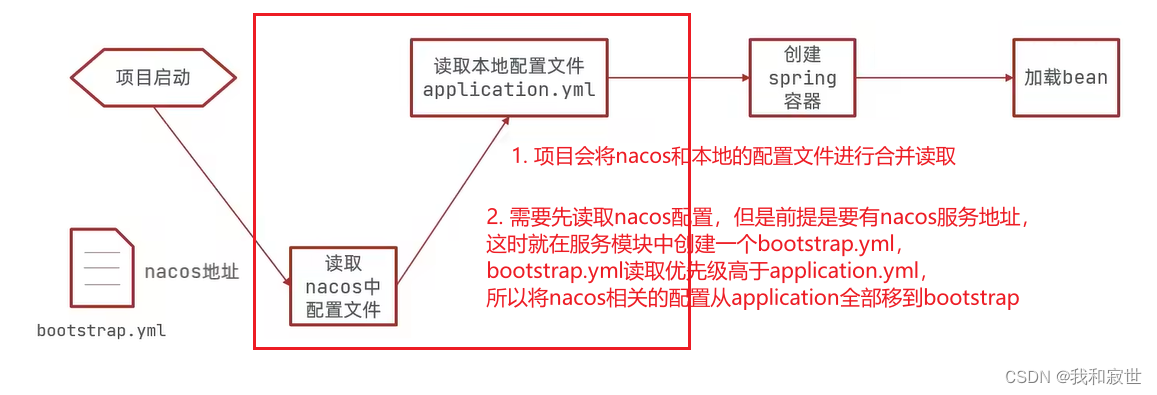
4.2.1 快速入门:统一配置管理
-
Nacos创建配置文件
-
服务获取配置文件步骤
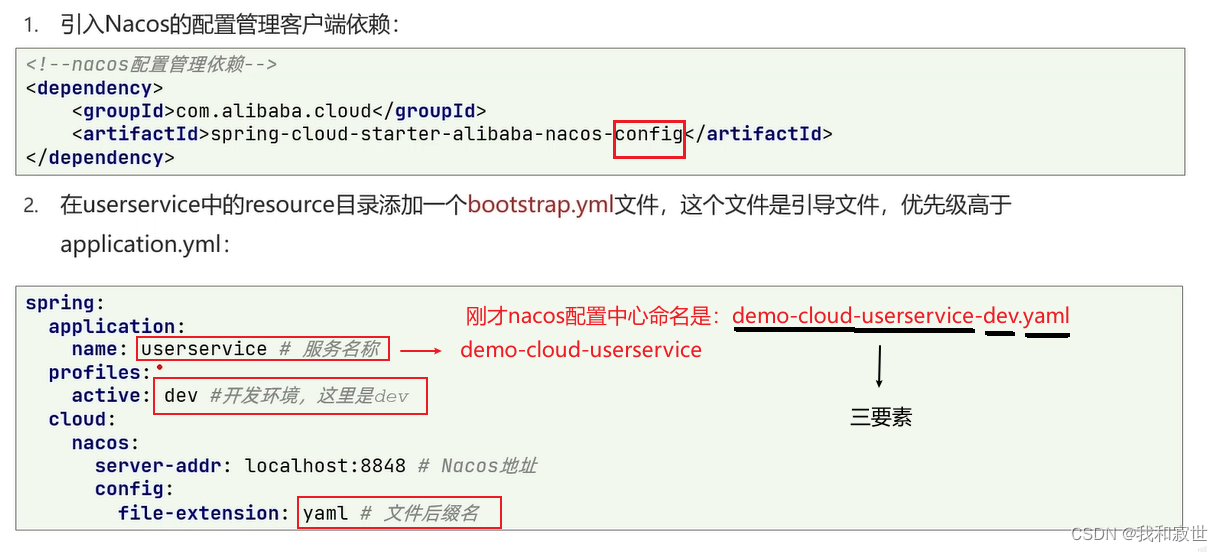
-
消费者/生产者导入配置中心所需依赖>>添加bootstrap.yml配置文件
-
读取配置文件测试,随便找个Controller尝试读取配置文件
@Value("${pattern.dateformat}")
private String now;
@GetMapping("/now")
public String now() {
return LocalDateTime.now().format(DateTimeFormatter.ofPattern(now));
}
统一配置总结:
- Nacos控制台创建配置文件。
- 在需要该配置文件的地方,导入config依赖。
- 在该微服务组件下,创建
bootstrap.yml文件,读取nacos配置。
4.2.2 配置热更新
视频讲解
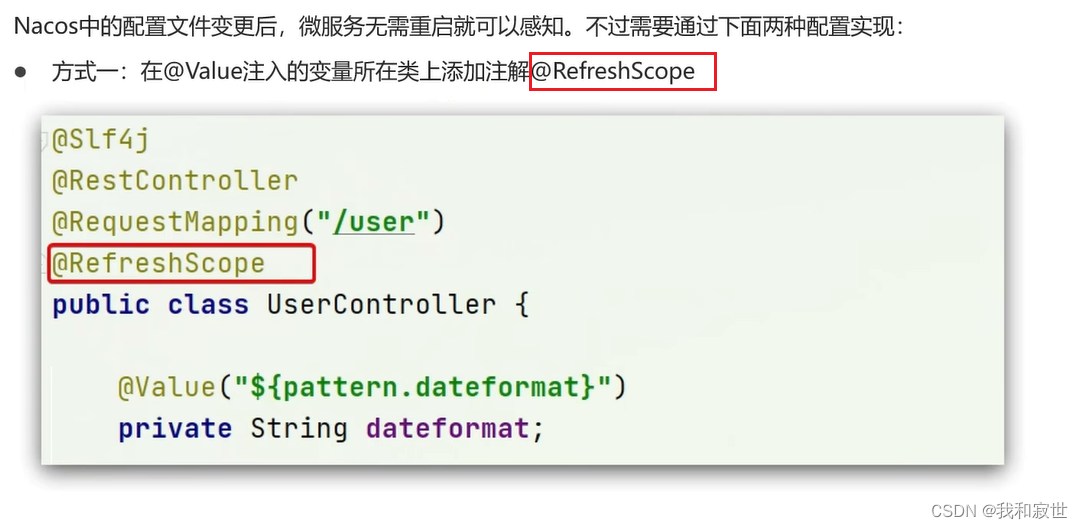

推荐使用方式二来配置热更新。
4.2.3 多环境配置共享
多环境指的是开发、测试、运行等环境。
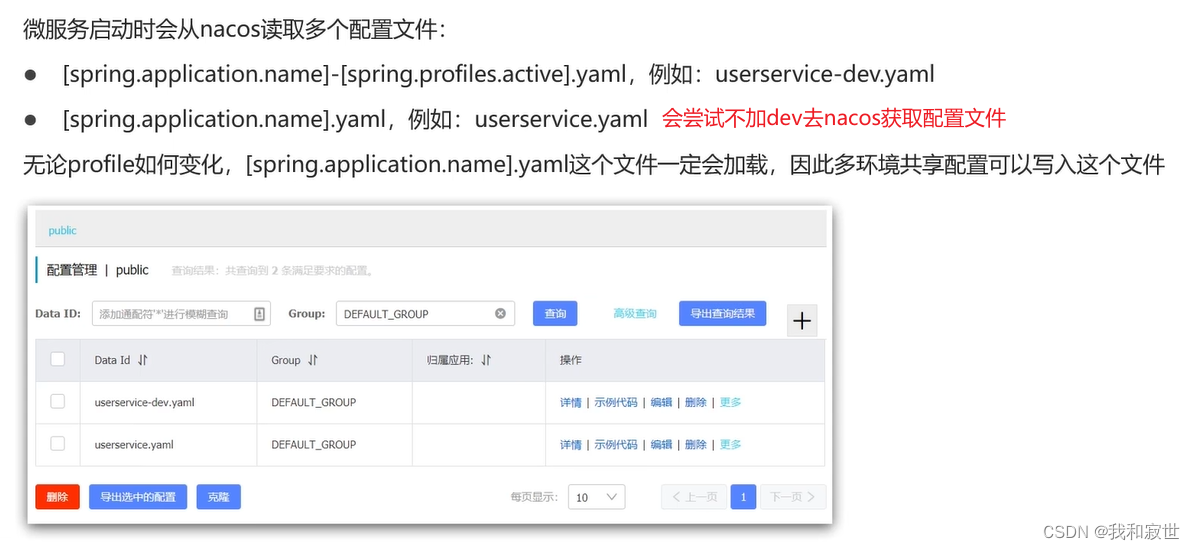
多环境下配置文件的优先级:带环境的yaml > 不带环境的yaml > 本地配置文件
eg:userservice-dev.yaml > userservice.yaml > 本地的userservice.yml
4.2.4 搭建Nacos集群
5 Feign
/feɪn/
前言:
使用RestTemplate代码可读性差、URL参数难以维护。
Feign是一个声明式的http客户端,用于帮助发送Http请求。
5.1 Feign替代RestTemplate
- 引入依赖
<!-- Feign -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
- 在组件的启动类打上
@EnableFeignClients注解 - 新建一个
UserClient接口(如clients包.UserClient,打上@FeignClient("生产者服务名")注解,声明远程调用信息
@FeignClient("demo-cloud-userservice")
public interface UserClient {
@GetMapping("/user/{id}")
User queryById(@PathVariable("id") Long id);
}
- 服务名称:demo-cloud-userservice(也就是提供者的spring.application.name)
- 请求方式:GET(这四项参考提供者Controller的请求方法)
- 请求路径:/user/{id}
- 请求参数:Long id
- 返回值类型:User
- 在代码中代替RestTemplate
// 记得自动注入
@Autowired
private UserClient userClient;
// 2.RestTemplate请求user模块数据
// String url = "http://demo-cloud-userservice:8081/user/" + order.getUserId();
// User user = restTemplate.getForObject(url, User.class);
//Feign替代RestTemplate
User user = userClient.queryById(order.getUserId());
5.2 自定义配置

修改方式:

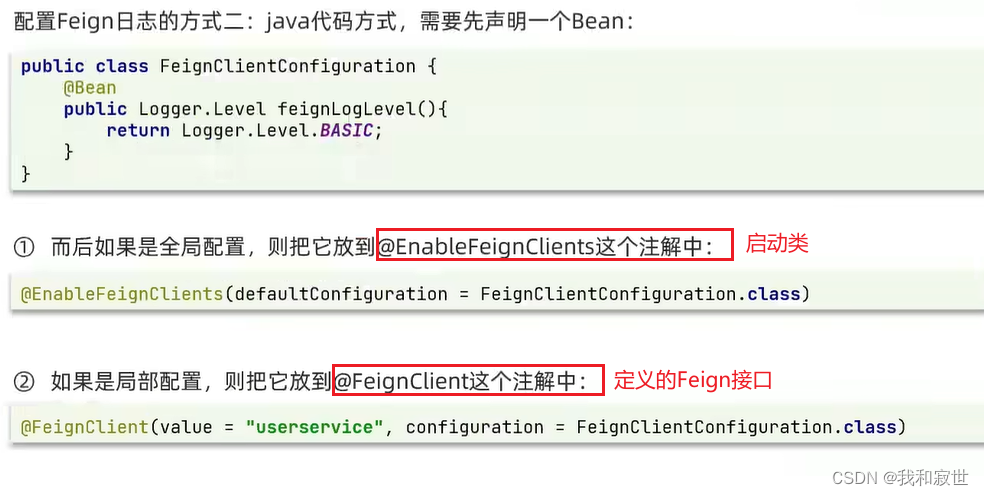
5.3 Feign使用优化

实现方式如下:
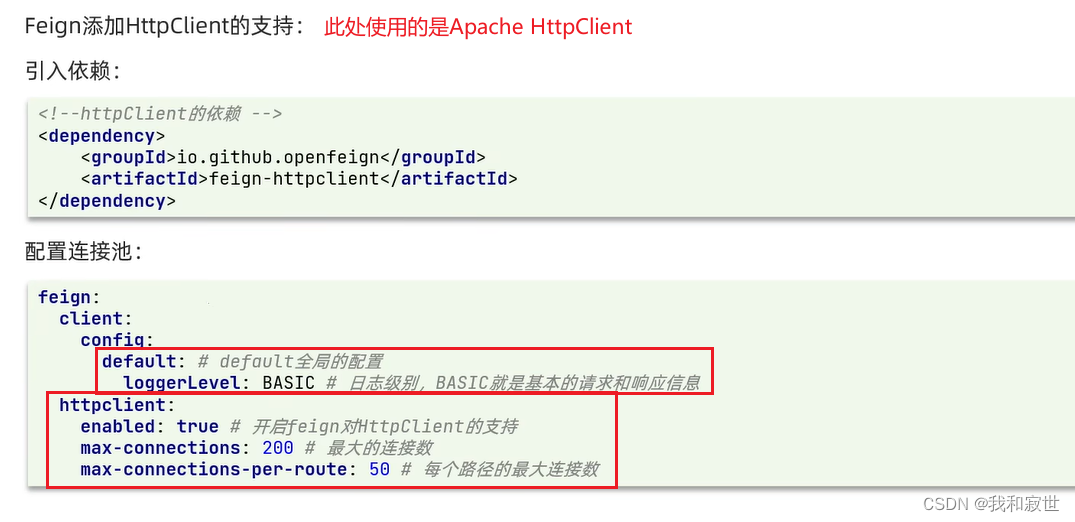
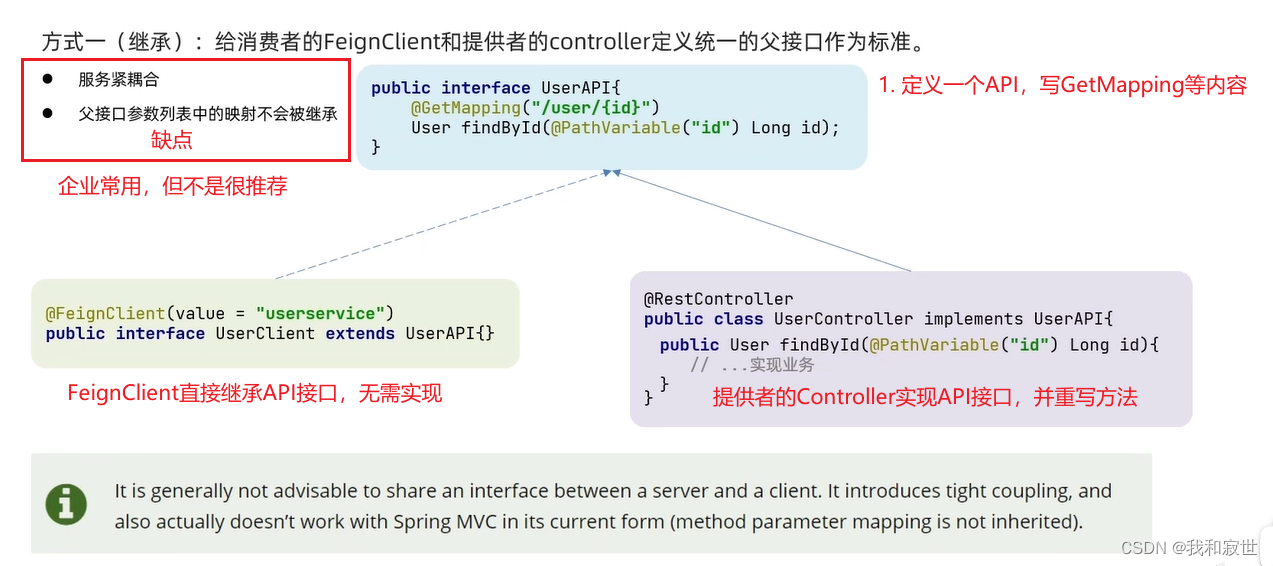
5.4 最佳实践
最佳实践:指的是Feign最佳使用方式。
两种方式各有各的优点,根据情况选择使用。
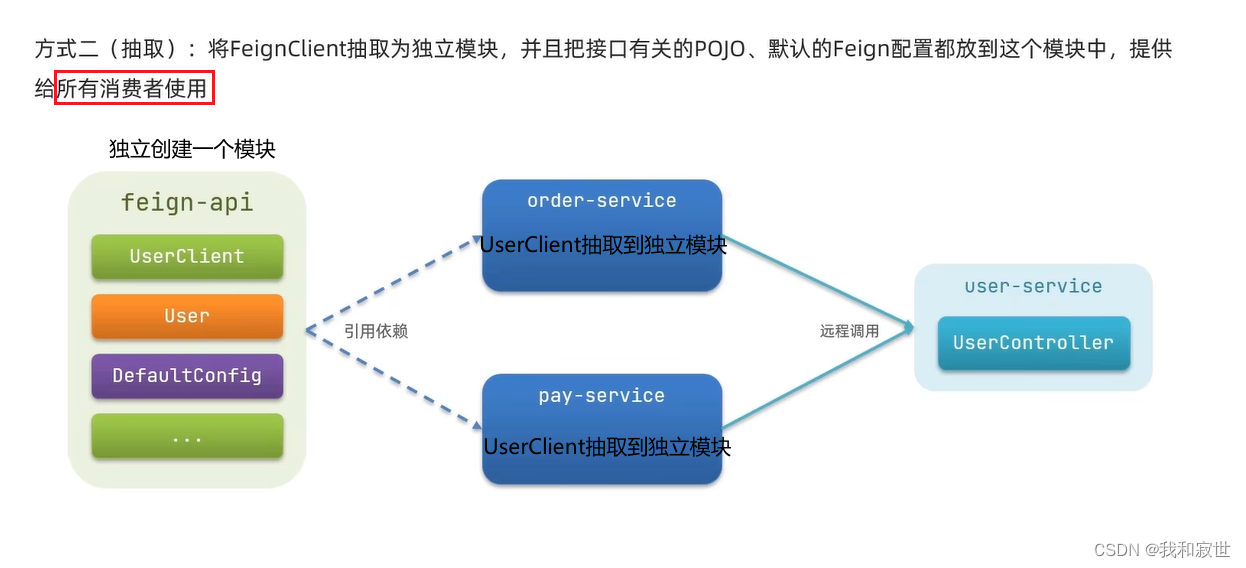
对于方式二的实现思路如下:
- 新建一个模块
feign-api,并导入Feign的依赖
<!-- Feign -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
- 将
UserClient和实体类User及Feign相关的配置yml(比如Feign日志配置)移动到feign-api中。
对于
Feign日志配置,建议使用配置类的形式,不用yml形式(目前不知道为什么在api模块yml格式用不了)
- 消费者里,导入该模块的
<denpendency>。
特别注意: 消费者的启动类打上
@EnableFeignClients(basePackages = "cn.itcast.api")注解时,必须使用bashPackages指定UserClient所在的包名。(因为启动类和UserClient不在同一个包下,启动类就无法自动扫描到)
或者@EnableFeignClients(clients = {UserClient.class})精确指定Client类。
参考文章:Feign-实现抽取
参考视频
6 Gateway
6.1 为什么需要网关
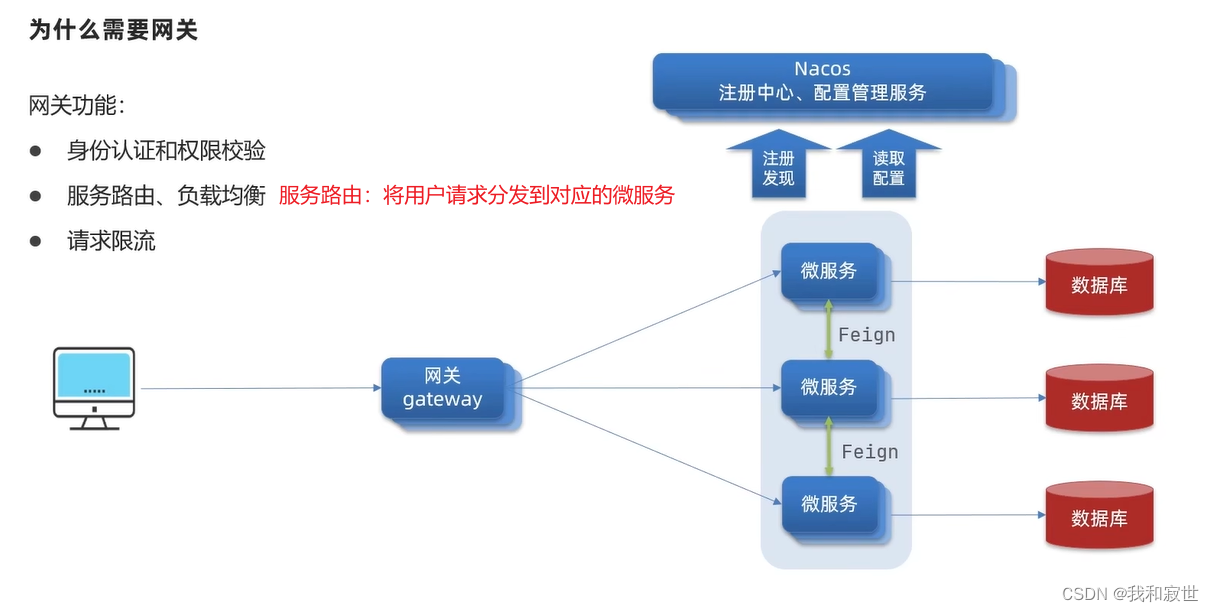
6.2 Gateway快速入门
- 创模块、导依赖(starter-gateway和nacos-discovery)
<!--spring cloud gateway-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!--nacos服务发现-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
- 配置yml文件,编写路由配置及端口、nacos、服务名
server:
port: 10001
spring:
application:
name: gateway
cloud:
nacos:
server-addr: 192.168.32.70:8848
gateway:
# 网关路由配置
routes:
- id: order-service # 路由ID,自定义,唯一即可
# uri: http://127.0.0.1:8081 #另一种写法,但是这种写法写死了,不常用
uri: lb://order-service # 路由目标地址,lb就是LoadBalance负载均衡的意思,后面跟对应的application.name
predicates: # 路由断言,断言:判断true和false;也就是判断请求是否符合路由规则的条件
- Path=/order/** # 按照路径匹配,只要以/order/开头就转发到这里
- id: user-service
uri: lb://demo-cloud-userservice
predicates:
- Path=/user/**
- 使用网关地址就可以访问转发到各个服务。
6.3 断言工厂(predicates详解)


6.4 过滤器工厂(GatewayFileter)
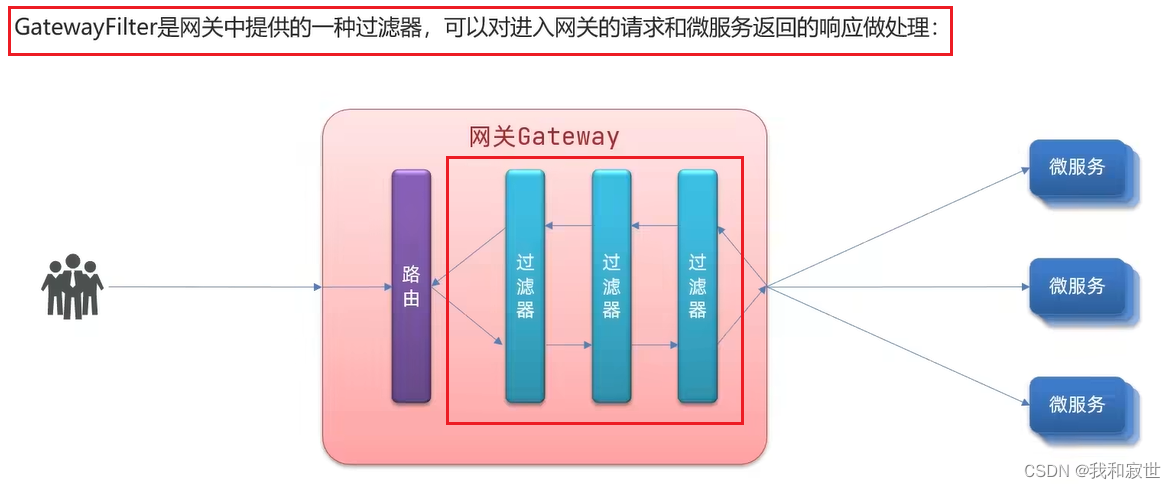
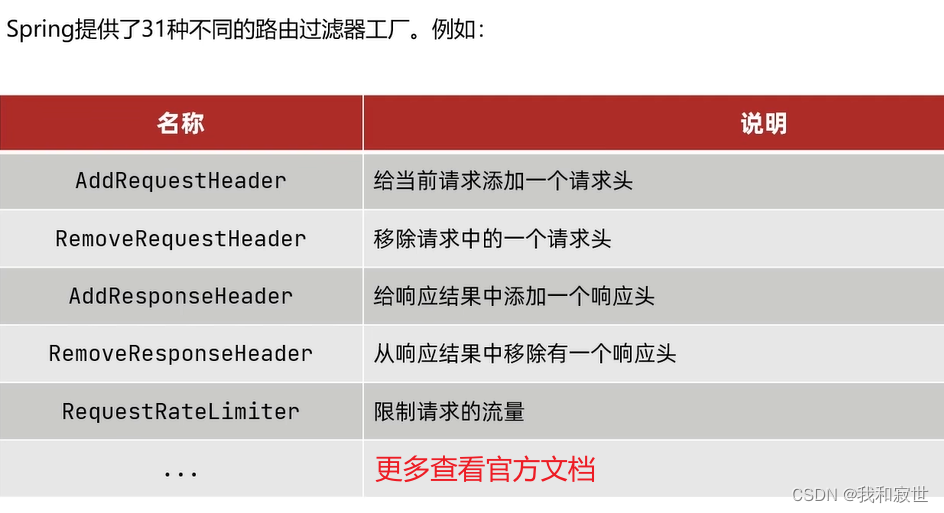
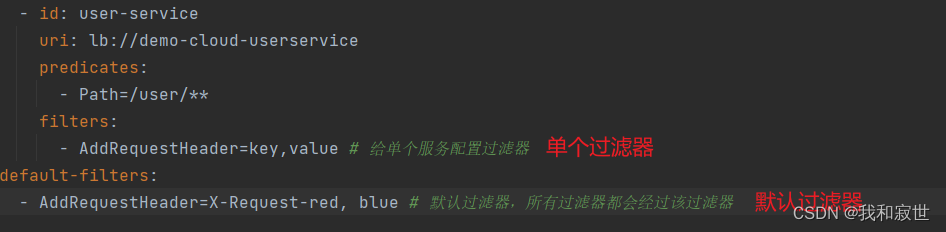
6.5 全局过滤器(GlobalFilter)
GlobalFilter和上面讲的GatewayFilter作用一样。
不同点在于:
- GatewayFilter通过yml定义,处理逻辑有限(从官方提供的来选择)。
- GlobalFilter是自定义过滤器,处理逻辑由自己实现,自由度高。

实现如下:
@Component //交给Spring管理
@Order(-1) //表示该过滤器的优先级,越小优先级越高;或者实现Ordered接口
public class AuthorizeFilter implements GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//1. 获取请求参数
ServerHttpRequest request = exchange.getRequest();
MultiValueMap<String, String> params = request.getQueryParams();
//2. 获取参数中authorization参数
String authorization = params.getFirst("authorization");
//3. 判断该参数是否为admin
if ("admin".equals(authorization)) {
//4. 是,放行
return chain.filter(exchange);
}
//5. 否,拦截
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED) //代表返回401,未登录的意思
return exchange.getResponse().setComplete();
}
}
浏览器带参访问http://localhost:10001/order/106?authorization=admin
6.6 过滤器链执行顺序
6.7 跨域问题
7 MQ
7.1 概述
MQ,消息队列,事件驱动架构中的Broker。
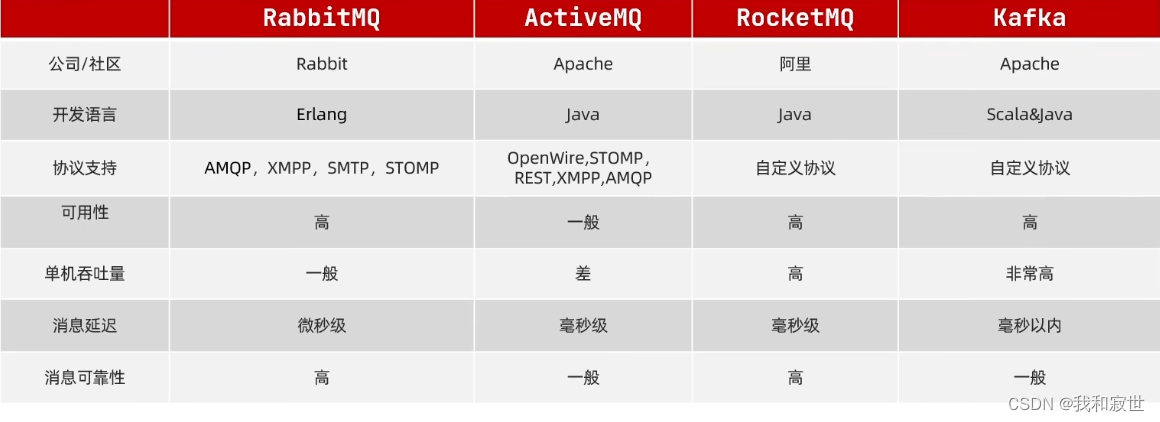
- RabbitMQ:实时性和可靠性高。
- Kafka:吞吐量高,适合海量数据的处理。
同步调用:同一时刻一个服务只能和另一个服务进行一对一通信(比如双方进行微信通话,同一时刻只能一对一)。
异步调用:同一时刻一个服务可以和多个服务进行通信(比如发微信消息,同一时刻可以一对多)。
kafka参考链接
nack(int index, long sleep)中index的含义
Ack Model模式
手动、自动确认消息
kafka架构介绍
7.1.1 同步调用
同步调用的优点:
实时性较强,可以立即得到结果。
同步调用存在的问题:
耦合度高:每次加入新的需求,都需要修改原有代码。性能下降:消费者需要等待提供者响应(如果调用链过长,则响应时间=每次调用的时间之和)。资源浪费:调用链中每个消费者在等待响应过程中,不能释放自身请求所占用的资源,高并发场景下会非常浪费系统资源。级联失败:如果提供者出现问题,那么所有消费者都会跟着出问题(因为消费者等待不到结果)。
同步调用视频讲解
比如Feign就是同步调用。
7.1.2 异步调用
异步调用常见实现就是事件驱动模式()。
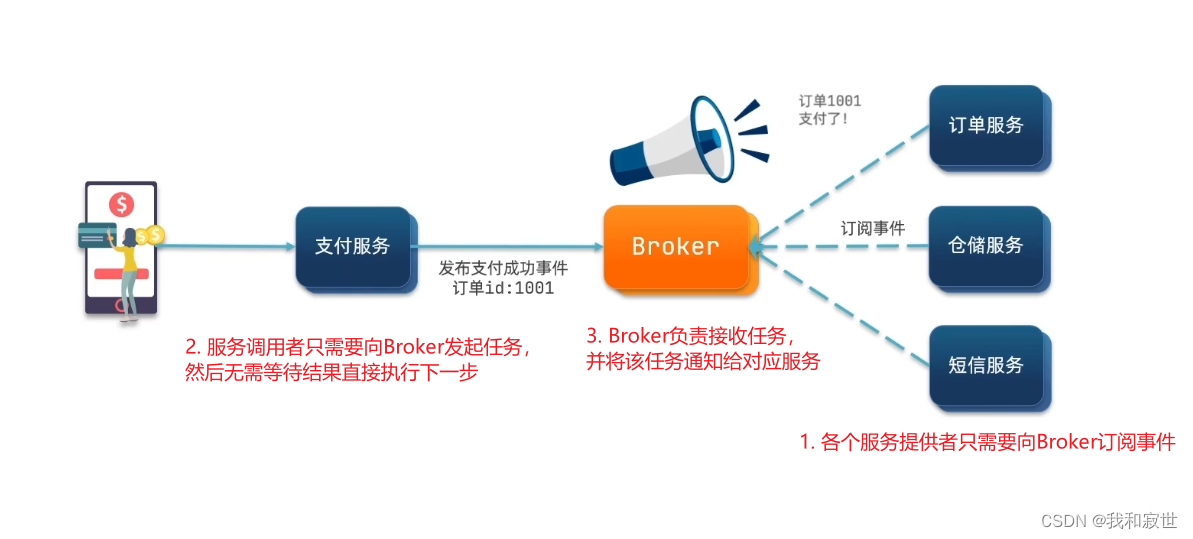
异步调用优点(以上图为例):
服务解耦:支付服务只需要将任务发布到Broker,而不用了解这个任务会被多少服务执行。性能提升,吞吐量提高:用户在完成支付服务后,支付服务将该事件发布到Broker即可返回支付成功的结果,而不用等待其他服务返回结果。服务没有强依赖 ,不担心级联失败问题:订单、仓储等服务的失败并不会影响到支付服务。流量消峰:当支付服务发布大量任务时,订单、仓储等服务可能处理不过来,这时可以先将任务堆积到Broker中,达到流量消峰的目的。
异步调用缺点:
- 依赖于Broker的可靠性、安全性、吞吐能力;如果Broker挂了,那么消费者和生产者都无法继续工作。
- 架构复杂了,业务没有明显的流程线,不好追踪管理。
7.1.3 同步异步如何选择
一般情况下用到的都是同步,平时没有那么多高并发的场景,能够实时返回结果。
如果是高并发的场景,就用到异步。
最终还是根据业务场景来进行选择。
7.2 RabbitMQ
7.2.1 架构概述
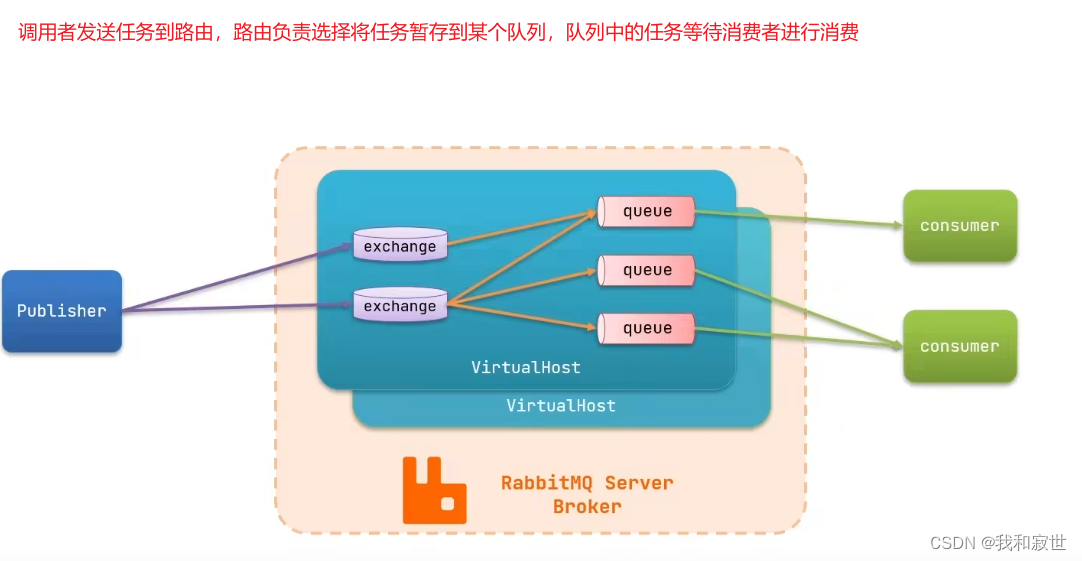
7.2.2 快速部署
以下为Docker单机部署方式
docker pull rabbitmq:3-management- 安装
docker run \
-e RABBITMQ_DEFAULT_USER=admin \
-e RABBITMQ_DEFAULT_PASS=123456 \
--name mq \
--hostname mq1 \
-p 15672:15672 \
-p 5672:5672 \
-d \
rabbitmq:3-management
–name:该容器的名称
–hostname:主机名,在MQ集群配置的时候用到
15672:RabbitMQ的管理页面端口
5672:RabbitMQ的服务提供端口
RabbitMQ的界面管理信息:
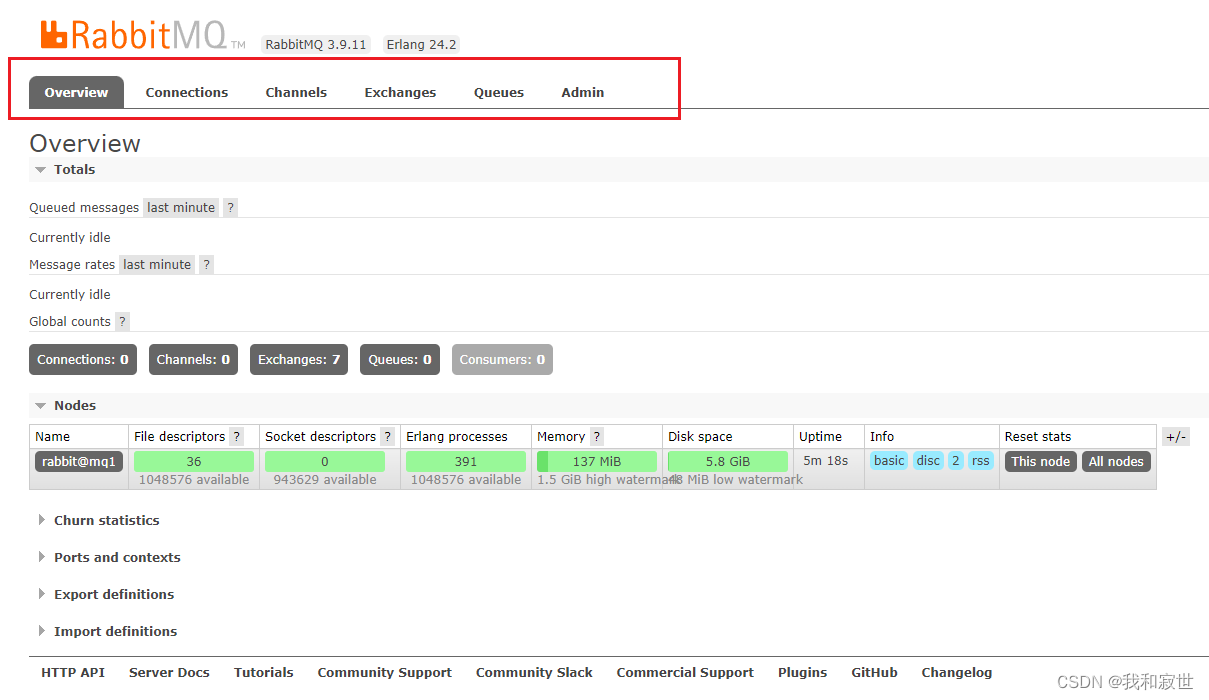
Overview:信息总览。Connections:连接信息,消费者和生产者与MQ建立连接后,在这里可以查看相关信息。Channels:消息通道,操作MQ的工具,创建该通道,消费者和生产者才能在这里发送和接收消息。Exchanges:将接收到的任务路由到消息队列中。Queues:消息队列,缓存消息。Admin:账号管理,可以在此实现多租户隔离。Virtual Host:虚拟主机,对queue、exchange等资源进行逻辑分组(起到隔离的作用)。
各选项的视频讲解
7.2.3 RabbitMQ常见消息模型
官网消息模型Demo
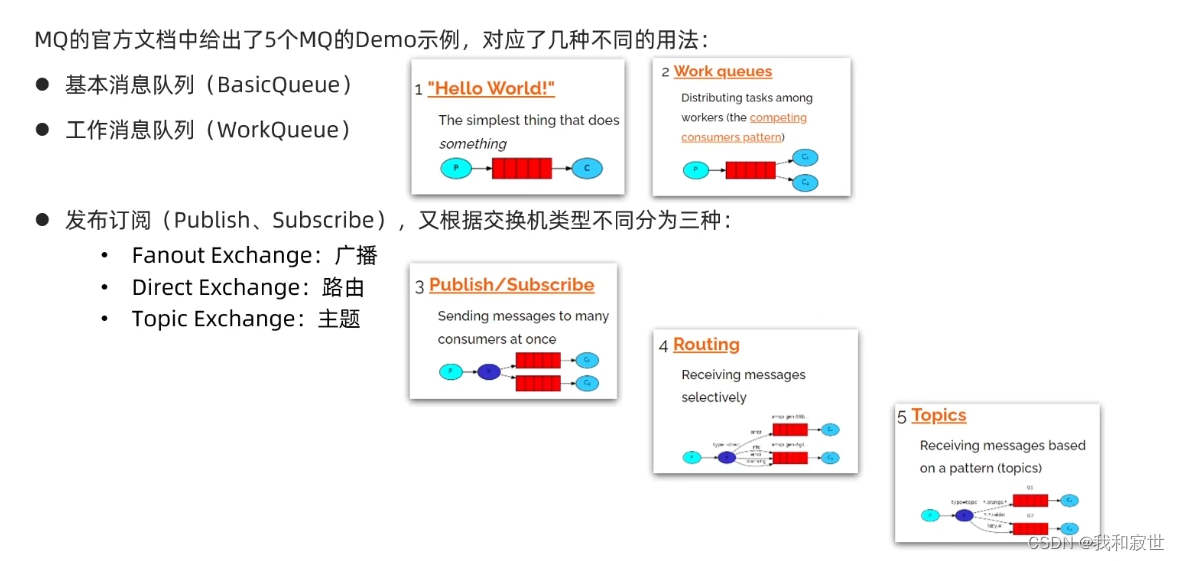
RabbitMQ官方的API使用起来很繁琐(要得到连接工厂–>建立connection–>创建channel–>创建队列queue–>订阅消息),所以有了下面的SpringAMQP来简化该过程。
对于以上5种常见的消息模型,具体的案例在下面的AMQP中展示。
7.3 SpringAMQP
7.3.1 概述
AMQP:Advanced Message Queuing Protocol高级消息队列协议,用于在应用程序之间传递业务消息的开放标准。该协议与语言和平台无关,所以有更高的独立性。Spring AMQP:基于AMQP定义的一套API规范,提供模板来简便发送和接收消息(和RedisTemplate类似)。包含两部分:
spring-amqp:基础抽象层
spring-rabbit:底层的默认实现- Demo示例源码:GitHub
7.3.2 BasicQueue
基本队列
- 父工程中导入spring-amqp起步依赖
<!--AMQP依赖,包含RabbitMQ-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
- 添加配置到生产者和消费者的yml
spring:
rabbitmq:
host: 192.168.32.50
port: 5672
virtual-host: /zhangsan
username: zhangsan
password: 123456
- 消息发送者的代码
@SpringBootTest(classes = PublisherApplication.class)
@RunWith(SpringRunner.class)
public class RabbitTest {
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
public void testRabbit() {
String queueName = "simple.queue";
String message = "Hello World";
rabbitTemplate.convertAndSend(queueName, message);
}
}
- 消息接收者的代码
//1. 将该类交给Spring管理
@Component
public class SpringRabbitListener {
//2. 监听哪一个队列
@RabbitListener(queues = "simple.queue")
//3. 形参的类型:消息发送者发送的消息是什么类型,这里就用什么类型接收(如发送的User user,这里就用User u接收)
public void listenSimpleQueueMessage(String msg) {
System.out.println("接收到消息:" + msg);
}
}
7.3.3 WorkQueue
工作队列
作用:提供多个同类型消费者处理同一个消息队列,提高消息处理速度,避免队列消息堆积。
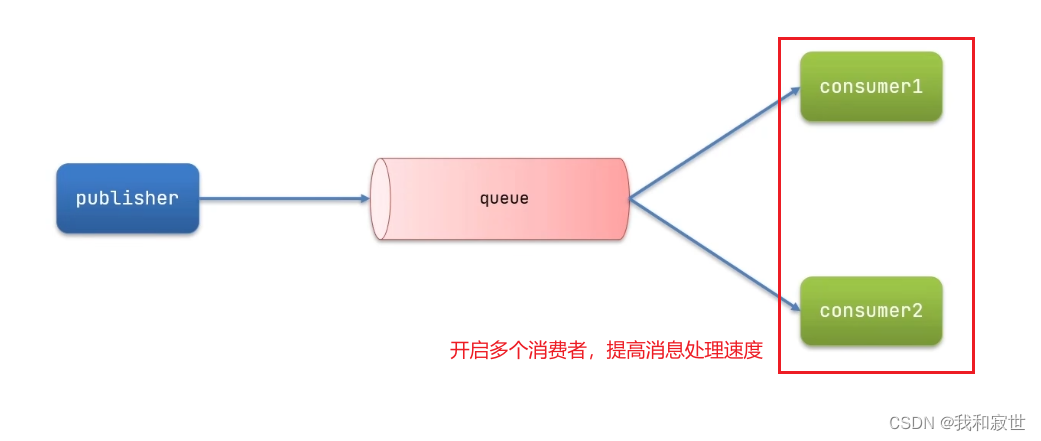
代码实现:
- 消息发送者
@Test
public void testWorkQueue() {
String queueName = "simple.queue";
String message = "Hello World__";
//模拟发送50条消息,要求消费者要在1秒内消费完
for (int i = 1; i <= 50; i++) {
rabbitTemplate.convertAndSend(queueName, message + i);
}
System.out.println("消息发送完毕");
}
- 消息接收者(注意:此处的消息接收者功能一模一样,比如它们都是订单服务,只是同时有两个消费者去消费任务队列)
/**
* 工作消息队列消费者01
* 每20ms消费一条
*
* @param msg
*/
@RabbitListener(queues = "simple.queue")
public void listenWorkQueue01(String msg) throws InterruptedException {
System.out.println("Consumer01接收到消息:" + msg + "=======" + LocalDateTime.now());
//模拟消费者01的处理能力更高一些
Thread.sleep(20);
}
/**
* 工作消息队列消费者02
* 每200ms消费一条
*
* @param msg
*/
@RabbitListener(queues = "simple.queue")
public void listenWorkQueue02(String msg) throws InterruptedException {
System.err.println("Consumer02接收到消息:" + msg + "=======" + LocalDateTime.now());
Thread.sleep(200);
}
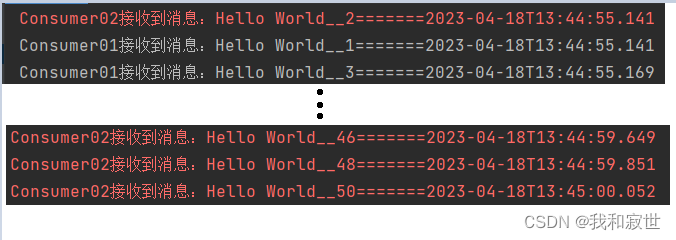
- 结果:可以看到两个消费者并没有如预想的一样在1s内处理完消息队列中的消息,而是5s才处理完
原因:两个消费者的处理能力不一样,但它们却平分了这50条任务;因为消费者02的处理能力较慢,所以5s才完成50条任务。
导致它们平分50条任务的根本原因是,消息队列采用预取机制,不管自身处理能力怎么样,先把任务领过来再说。
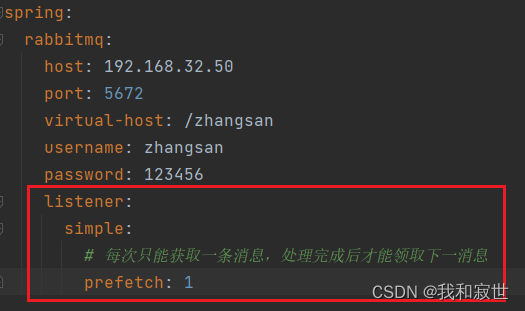
4. 对于3的解决办法
在消费者配置文件中进行预取上限配置
7.3.4 FanoutExchange
Fanout(fænaʊt)发布订阅模型-广播
发布订阅模型与前面两种案例的区别就是,发布订阅允许将同一消息发送给多个消费者。实现方式是加入了exchange(交换机)。
比如现在有订单服务和仓储服务,前两种模型只支持一条消息被单个服务获取(单个服务可以多开),一旦消息被取出即被销毁,其他服务就拿不到该消息,即一个消息队列对应一个服务。
发布订阅模型则是,通过exchange可以将一条消息同时发给多个消息队列,对应的服务再消费,这样就实现了一条消息被多个服务消费。
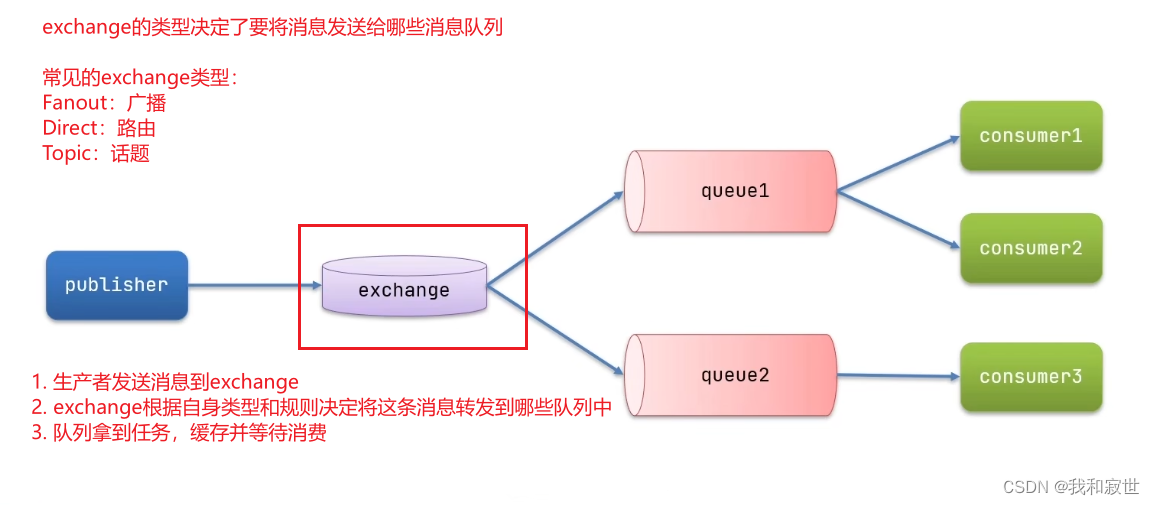
注意:exchange只负责消息转发,不负责存储,转发失败则该消息丢失。
实现方式:使用Spring AMQP声明一个交换机和两个消息队列,并进行两者的绑定。
实现思路:
- consumer中,利用代码声明交换机和队列并进行绑定。
- consumer中,编写两个消费者,分别监听两个队列。
- publisher中,向交换机发送消息。
Spring AMQP提供的exchange API如下:
提供的队列API叫Queue,绑定关系API叫Binding。
代码实现:
consumer中定义一个FanoutConfig类,使用Bean声明Exchange、Queue、Binding(也可以直接在@RabbitListener注解中声明这三者,下面Direct有示例)
//0. 该类作为一个配置类被扫描
@Configuration
public class FanoutConfig {
//1. 声明一个Fanout交换机,名称为 fanout.exchange
@Bean
public FanoutExchange fanoutExchange() {
return new FanoutExchange("fanout.exchange");
}
//2. 声明第一个队列,名称为 fanout.queue01
@Bean
public Queue fanoutQueue01() {
return new Queue("fanout.queue01");
}
//2. 声明第二个队列,名称为 fanout.queue02
@Bean
public Queue fanoutQueue02() {
return new Queue("fanout.queue02");
}
//3. 使用Binding,将队列01和交换机进行绑定
@Bean
public Binding fanoutBinding01(FanoutExchange fanoutExchange, Queue fanoutQueue01, Queue fanoutQueue02) {
return BindingBuilder
.bind(fanoutQueue01)
.to(fanoutExchange);
}
//3. 使用Binding,将队列02和交换机进行绑定
@Bean
public Binding fanoutBinding02(FanoutExchange fanoutExchange, Queue fanoutQueue02) {
return BindingBuilder
.bind(fanoutQueue02)
.to(fanoutExchange);
}
}
consumer中定义两个消费者
/**
* 发布订阅模型-Fanout 消费者
*
* @param msg
* @throws InterruptedException
*/
//接收队列fanout.queue01的消息
@RabbitListener(queues = "fanout.queue01")
public void listenFanoutQueue01(String msg) {
System.out.println("fanout.queue01接收到消息:" + msg);
}
//接收队列fanout.queue02的消息
@RabbitListener(queues = "fanout.queue02")
public void listenFanoutQueue02(String msg) {
System.out.println("fanout.queue02接收到消息:" + msg);
}
publisher中定义消息发送者
@Test
public void testSendFanoutExchange() {
String exchangeName = "fanout.exchange";
String message = "Hello World";
//参数:路由名,routingKey,message
rabbitTemplate.convertAndSend(exchangeName, "", message);
System.out.println("消息发送完毕");
}
总结:FanoutExchange会将自己收到的消息转发给所有绑定的Queue。
7.3.5 DirectExchange
发布订阅模型-路由
DirectExchange会将接收到的消息根据规则路由到指定的Queue,因此称为路由模式。
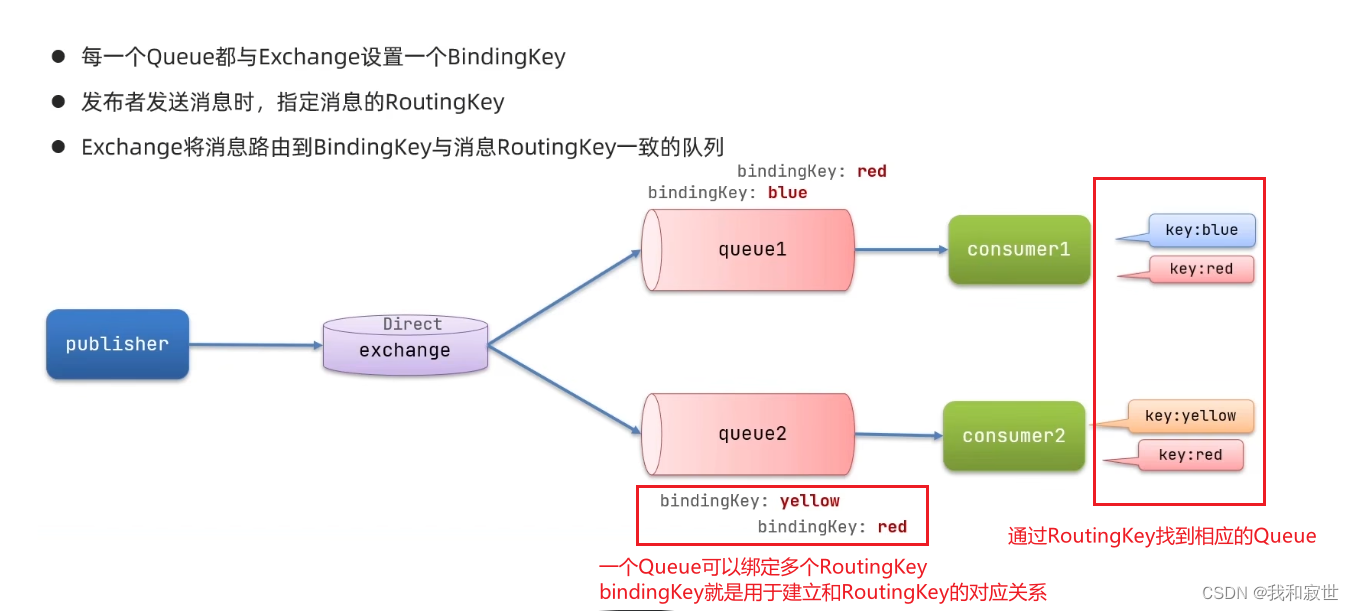
consumer中定义消费者,直接在@RabbitListener声明Exchange、Queue、Binding和RoutingKey
/**
* 发布订阅模型-Direct 消费者
*/
//消费者01
//QueueBinding内说明了Queue和Exchange以及RoutingKey的关系
@RabbitListener(bindings = @QueueBinding(
//Queue名称
value = @Queue("direct.queue01"),
//Exchange名称,以及该Exchange是哪种类型
exchange = @Exchange(name = "direct.exchange", type = ExchangeTypes.DIRECT),
//RoutingKey名称
key = {"red"}
))
public void listenDirectQueue01(String msg) {
System.out.println("direct.queue01接收到消息:" + msg);
}
//消费者02
@RabbitListener(bindings = @QueueBinding(
value = @Queue("direct.queue02"),
exchange = @Exchange(name = "direct.exchange", type = ExchangeTypes.DIRECT),
//一个Queue可以绑定多个routingKey
key = {"yellow", "red"}
))
public void listenDirectQueue02(String msg) {
System.out.println("direct.queue02接收到消息:" + msg);
}
publisher中定义消息发送者
@Test
public void testSendDirectExchange() {
String exchangeName = "direct.exchange";
String message = "Hello Direct Exchange";
//转发到该Exchange的哪一个RoutingKey中
rabbitTemplate.convertAndSend(exchangeName, "yellow", message);
}
总结:DirectExchange会将自己收到的消息转发给符合routingKey的Queue。
7.3.6 TopicExchange
发布订阅模型-主题
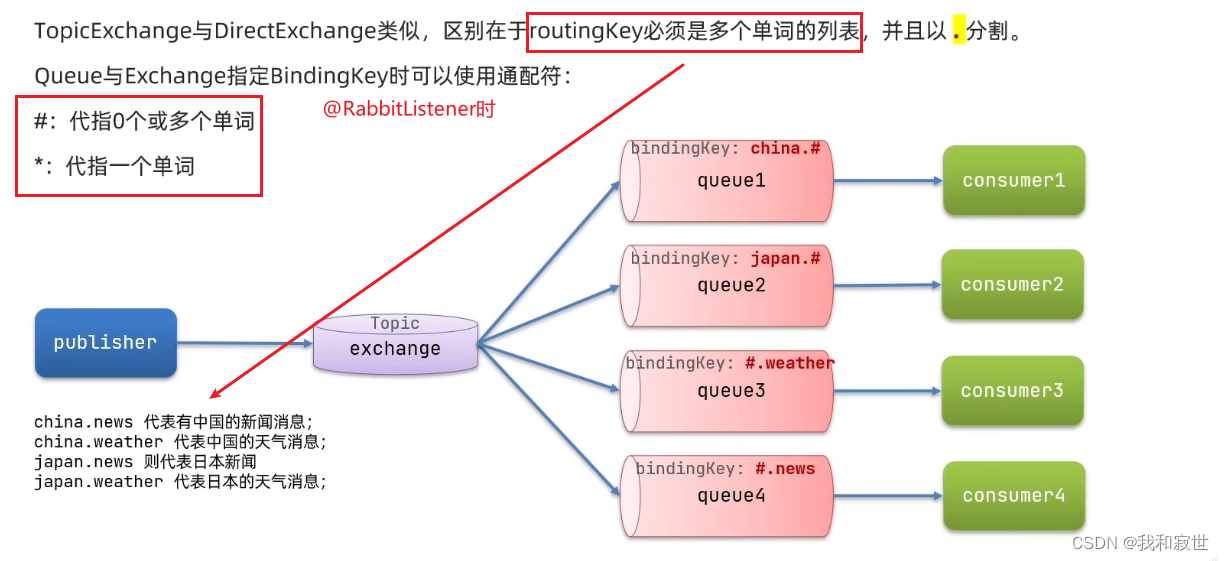
consumer中定义消费者,注意此时key = "通配符表达式"就不使用数组格式了。
/**
* 发布订阅模型-Topic 消费者
*/
//消费者01
@RabbitListener(bindings = @QueueBinding(
value = @Queue("topic.queue01"),
exchange = @Exchange(name = "topic.exchange", type = ExchangeTypes.TOPIC),
//因为使用通配符,所以就不用数组格式的了
key = "china.#"
))
public void listenTopicQueue01(String msg) {
System.out.println("topic.queue01接收到消息:" + msg);
}
//消费者02
@RabbitListener(bindings = @QueueBinding(
value = @Queue("topic.queue02"),
exchange = @Exchange(name = "topic.exchange", type = ExchangeTypes.TOPIC),
key = "#.news"
))
public void listenTopicQueue02(String msg) {
System.out.println("topic.queue02接收到消息:" + msg);
}
publisher中定义消息发送者
@Test
public void testSendTopicExchange() {
String exchangeName = "topic.exchange";
String message = "Hello Topic Exchange";
rabbitTemplate.convertAndSend(exchangeName, "china.weather", message);
}
总结:TopicExchange会将自己收到的消息根据routingKey的通配符规则转发给对应的Queue。
7.3.7 消息转换器
问题: 发送消息时,如果发送的内容是Object(对象),那么在传输时会采用Java默认的序列化方式,如下图所示:
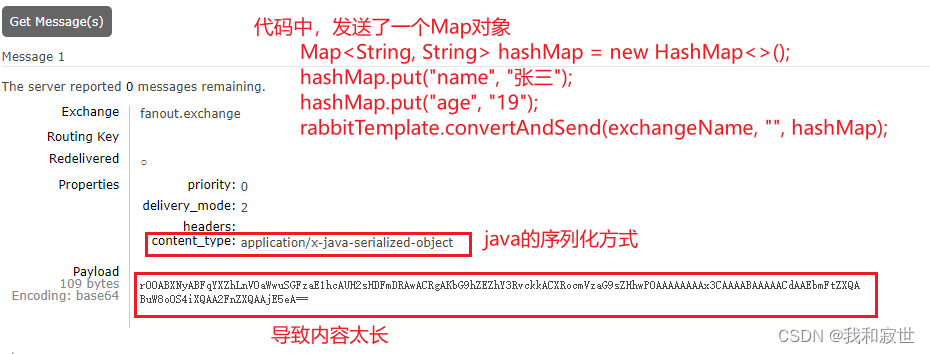
采用默认的序列化方式,会导致传输的内容过长,从而导致传输性能下降。
产生原因:Spring的消息对象是由org.springframework.amqp.support.converter.MessageConverter来处理的,该接口的默认实现是SimpleMessageConverter,其本质是基于JDK的ObjectOutputStream完成序列化。
解决方式一:
定义一个MessageConverter类型的Bean,在发送时会自动使用JSON方式进行序列化,步骤如下:
- 首先在父工程中引入jackson依赖
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
consumer和publisher中都声明MessageConverterBean(可以自定义一个配置类、或者写在启动类中)
@Configuration
public class RabbitMQConfig {
@Bean
public MessageConverter jsonMessageConverter() {
//使用Jackson的序列化,FastJson的MessageConverter目前还没有,使用不了
return new Jackson2JsonMessageConverter();
}
}
publisher消息发送者中
@Test
public void testSendFanoutExchange() {
String exchangeName = "fanout.exchange";
Map<String, String> hashMap = new HashMap<>();
hashMap.put("name", "张三");
hashMap.put("age", "19");
//直接发送参数,MessageConverter会自动序列化该参数
rabbitTemplate.convertAndSend(exchangeName, "", hashMap);
}
consumer的消费者中
@RabbitListener(queues = "fanout.queue01")
//发送者的参数是什么类型,这里就直接写什么类型,MessageConverter会自动反序列化
public void listenFanoutQueue01(Map<String, String> msg) {
System.out.println("fanout.queue01接收到消息:" + msg);
}
解决方式二:
不使用MessageConverter,直接将Object使用FastJson或者Jackson转为String发送,简单粗暴。
publisher发送时
@Test
public void testSendFanoutExchange() {
String exchangeName = "fanout.exchange";
Map<String, String> hashMap = new HashMap<>();
hashMap.put("name", "张三");
hashMap.put("age", "19");
//此处使用FastJson转为字符串
rabbitTemplate.convertAndSend(exchangeName, "", JSONObject.toJSONString(hashMap));
}
consumer接收时
@RabbitListener(queues = "fanout.queue01")
//字符串接收
public void listenFanoutQueue01(String msg) {
//转回Map
Map mapTyep = JSONObject.parseObject(msg);
for (Object o : mapTyep.keySet()) {
System.out.println(mapTyep.get(o));
}
System.out.println("fanout.queue01接收到消息:" + mapTyep);
}
8 ElasticSearch
9 Seata
9.1 Docker部署Seata
建表
- 自行创建
seata数据库,新建以下四张表。官方SQL脚本
-- -------------------------------- The script used when storeMode is 'db' --------------------------------
-- the table to store GlobalSession data
CREATE TABLE IF NOT EXISTS `global_table`
(
`xid` VARCHAR(128) NOT NULL,
`transaction_id` BIGINT,
`status` TINYINT NOT NULL,
`application_id` VARCHAR(32),
`transaction_service_group` VARCHAR(32),
`transaction_name` VARCHAR(128),
`timeout` INT,
`begin_time` BIGINT,
`application_data` VARCHAR(2000),
`gmt_create` DATETIME,
`gmt_modified` DATETIME,
PRIMARY KEY (`xid`),
KEY `idx_status_gmt_modified` (`status` , `gmt_modified`),
KEY `idx_transaction_id` (`transaction_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
-- the table to store BranchSession data
CREATE TABLE IF NOT EXISTS `branch_table`
(
`branch_id` BIGINT NOT NULL,
`xid` VARCHAR(128) NOT NULL,
`transaction_id` BIGINT,
`resource_group_id` VARCHAR(32),
`resource_id` VARCHAR(256),
`branch_type` VARCHAR(8),
`status` TINYINT,
`client_id` VARCHAR(64),
`application_data` VARCHAR(2000),
`gmt_create` DATETIME(6),
`gmt_modified` DATETIME(6),
PRIMARY KEY (`branch_id`),
KEY `idx_xid` (`xid`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
-- the table to store lock data
CREATE TABLE IF NOT EXISTS `lock_table`
(
`row_key` VARCHAR(128) NOT NULL,
`xid` VARCHAR(128),
`transaction_id` BIGINT,
`branch_id` BIGINT NOT NULL,
`resource_id` VARCHAR(256),
`table_name` VARCHAR(32),
`pk` VARCHAR(36),
`status` TINYINT NOT NULL DEFAULT '0' COMMENT '0:locked ,1:rollbacking',
`gmt_create` DATETIME,
`gmt_modified` DATETIME,
PRIMARY KEY (`row_key`),
KEY `idx_status` (`status`),
KEY `idx_branch_id` (`branch_id`),
KEY `idx_xid` (`xid`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
CREATE TABLE IF NOT EXISTS `distributed_lock`
(
`lock_key` CHAR(20) NOT NULL,
`lock_value` VARCHAR(20) NOT NULL,
`expire` BIGINT,
primary key (`lock_key`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('AsyncCommitting', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('RetryCommitting', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('RetryRollbacking', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('TxTimeoutCheck', ' ', 0);
- 在需要使用分布式事务的数据库里,新建
undo_log表,用于记录更新前后的快照,以实现分布式事务。
如果多个数据库都要使用分布式事务,那每个数据库里都要加undo_log表。
DROP TABLE IF EXISTS `undo_log`;
CREATE TABLE `undo_log` (
`branch_id` bigint(0) NOT NULL COMMENT '分支事务ID',
`xid` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '全局事务ID',
`context` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '上下文',
`rollback_info` longblob NOT NULL COMMENT '回滚信息',
`log_status` int(0) NOT NULL COMMENT '状态,0正常,1全局已完成',
`log_created` datetime(6) NOT NULL COMMENT '创建时间',
`log_modified` datetime(6) NOT NULL COMMENT '修改时间',
UNIQUE INDEX `ux_undo_log`(`xid`, `branch_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = 'AT transaction mode undo table' ROW_FORMAT = Compact;
SET FOREIGN_KEY_CHECKS = 1;
拉镜像
docker pull seataio/seata-server:1.6.1
注意:seata的版本和spring cloud版本尽量保持一致。版本对应表
自定义seata配置文件需要通过挂载文件的方式实现;
先run一个临时容器,把配置文件拷贝出来,再重新创建容器。
- 创建配置文件存放的目录,后面创建容器映射这个目录下的配置文件。
mkdir -p /opt/seata/resources - 启动临时容器
docker run -d -p 8091:8091 -p 7091:7091 --name seata-server seataio/seata-server:1.6.1 - copy临时容器配置到宿主机
docker cp seata-server:/seata-server/resources/. /opt/seata/resources - 删除临时容器
docker rm -f seata-server
配置文件
- 修改
resources目录下的application.yml文件。
seata:
config:
# support: nacos, consul, apollo, zk, etcd3
type: nacos
nacos:
server-addr: hisi.nacos:8848 # nacos地址
namespace: # nacos的命名空间名称,默认public,不填就是默认
group: SEATA_GROUP # 配置文件所在组,默认DEFAULT_GROUP;如果自定义了,在spring集成seata时服务的yml需要修改
username: # nacos账号,没有就不填
password: # nacos密码
context-path:
data-id: seataServer.properties
registry:
# support: nacos, eureka, redis, zk, consul, etcd3, sofa
type: nacos
nacos:
application: seata-server
server-addr: hisi.nacos:8848
group: SEATA_GROUP
namespace:
cluster: default # TC 集群名称,下文 Seata 客户端中配置事务分组名和集群名映射使用;就是nacos服务列表里的集群名称
username:
password:
- seata使用nacos作为配置中心,上传seata需要的配置文件到nacos。文件地址
nacos新建seataServer.properties配置文件,复制内容,并修改以下内容。
#Transaction storage configuration, only for the server. The file, db, and redis configuration values are optional.
# 存储方式改为db
store.mode=db
store.lock.mode=db
store.session.mode=db
# 数据库链接
store.db.datasource=druid
store.db.dbType=mysql
store.db.driverClassName=com.mysql.jdbc.Driver
store.db.url=jdbc:mysql://hisi-mysql:3306/seata?useUnicode=true&rewriteBatchedStatements=true
store.db.user=root
store.db.password=yfsl64799678
启动容器
- run命令的方式,注意
-v挂载配置文件的路径。
docker run -d \
--name seata-server \
--restart=always \
-p 8091:8091 \
-p 7091:7091 \
-e SEATA_IP=192.168.10.23 \
-v /opt/seata/resources:/seata-server/resources \
seataio/seata-server:1.7.1
- docker compose的方式,新建
compose.yaml文件。以及手动新建一个network
version: "3"
services:
seata-server:
image: seataio/seata-server:1.6.1
container_name: seata.server
restart: always
ports:
- "8091:8091"
- "7091:7091"
environment:
- SEATA_IP=192.168.32.50
volumes:
- /home/hisicloud/dockerfile/seata/resources:/seata-server/resources
networks:
- "hisi-network"
networks:
hisi-network:
external: true
新建start.sh文件。
docker-compose -f compose.yaml down
docker-compose -f compose.yaml up -d
sh start.sh启动容器。
- 访问nacos控制台查看seata是否注册成功。
9.2 Spring Boot集成Seata
- 每个需要seata的服务加上maven依赖,注意版本和seata版本保持一致。
<!--seata-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
<exclusions>
<exclusion>
<artifactId>seata-spring-boot-starter</artifactId>
<groupId>io.seata</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>1.6.1</version>
</dependency>
- 在每个需要使用seata的微服务里配置
application.yml
seata:
registry:
type: nacos # nacos作为注册中心
nacos:
server-addr: 192.168.32.50:8848 # nacos地址
namespace: "" # seata所在命名空间,和seata配置文件相同,默认就不填
group: SEATA_GROUP # seata所在nacos组,和seata配置文件相同
application: seata-server # seata注册到nacos的服务名
tx-service-group: seata-demo # seata分组管理,这个服务在哪个组;随便填,seata会根据vgroup-mapping来定位具体服务
service:
vgroup-mapping:
seata-demo: default # seata的nacos配置文件里的service.vgroupMapping.default_tx_group=default,的值
- 启动服务,看日志检查微服务注册到seata是否成功。
2024-06-14 14:05:33.848 INFO 20120 --- [ main] i.s.c.r.netty.NettyClientChannelManager : will connect to 192.168.32.50:8091
2024-06-14 14:05:34.340 INFO 20120 --- [ main] i.s.core.rpc.netty.NettyPoolableFactory : NettyPool create channel to transactionRole:TMROLE,address:192.168.32.50:8091,msg:< RegisterTMRequest{applicationId='hisi-cngt-warehouse', transactionServiceGroup='seata-demo'} >
2024-06-14 14:05:35.154 INFO 20120 --- [ main] i.s.c.rpc.netty.TmNettyRemotingClient : register TM success. client version:1.6.1, server version:1.6.1,channel:[id: 0x81a4deb4, L:/192.168.32.2:8195 - R:/192.168.32.50:8091]
2024-06-14 14:05:35.162 INFO 20120 --- [ main] i.s.core.rpc.netty.NettyPoolableFactory : register success, cost 118 ms, version:1.6.1,role:TMROLE,channel:[id: 0x81a4deb4, L:/192.168.32.2:8195 - R:/192.168.32.50:8091]
2024-06-14 14:05:35.164 INFO 20120 --- [ main] i.s.s.a.GlobalTransactionScanner : Transaction Manager Client is initialized. applicationId[hisi-cngt-warehouse] txServiceGroup[seata-demo]
2024-06-14 14:05:35.178 INFO 20120 --- [ main] io.seata.rm.datasource.AsyncWorker : Async Commit Buffer Limit: 10000
2024-06-14 14:05:35.179 INFO 20120 --- [ main] i.s.rm.datasource.xa.ResourceManagerXA : ResourceManagerXA init ...
2024-06-14 14:05:35.191 INFO 20120 --- [ main] i.s.core.rpc.netty.NettyClientBootstrap : NettyClientBootstrap has started
2024-06-14 14:05:35.191 INFO 20120 --- [ main] i.s.s.a.GlobalTransactionScanner : Resource Manager is initialized. applicationId[hisi-cngt-warehouse] txServiceGroup[seata-demo]
2024-06-14 14:05:35.191 INFO 20120 --- [ main] i.s.s.a.GlobalTransactionScanner : Global Transaction Clients are initialized.
- 在需要使用事务的方法上,注解
@GlobalTransactional(和@Transactional的使用方法类似,注意方法所在类要交给spring代理)。
@Override
@GlobalTransactional
public Result<String> testSeata(Integer isException) {
// RPC
Result result = warehouseFeign.updatePreemption(38L, "SUB");
if (result.getCode() != 200) {
return Result.fail("RPC失败");
}
// 本地数据
StatisticsProduced statisticsProduced = new StatisticsProduced();
setProduced(statisticsProduced);
this.save(statisticsProduced);
// 异常
if (isException == 1) {
throw new CheckedException("自定义异常");
}
return Result.success();
}
9.3 参考链接
10 Logback
10.1 快速开始
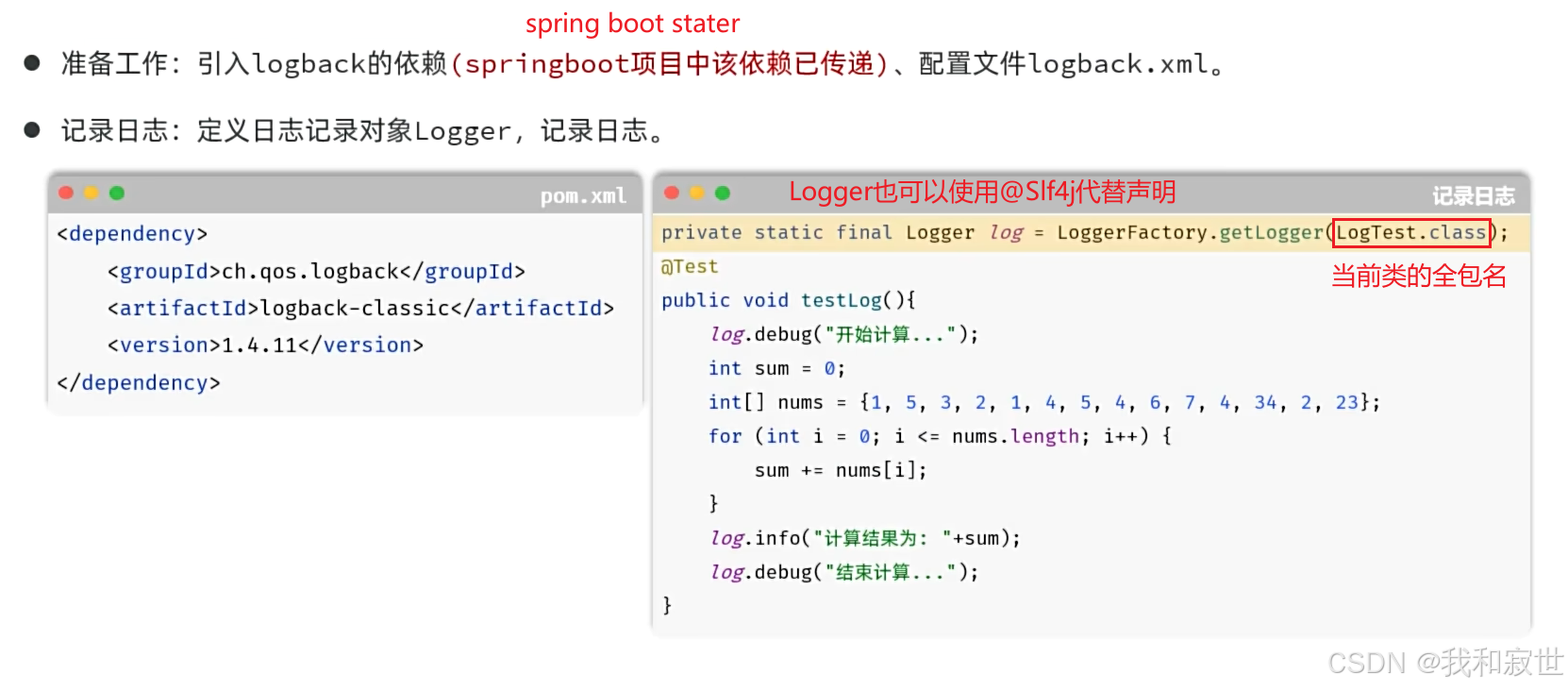
10.2 logback.xml
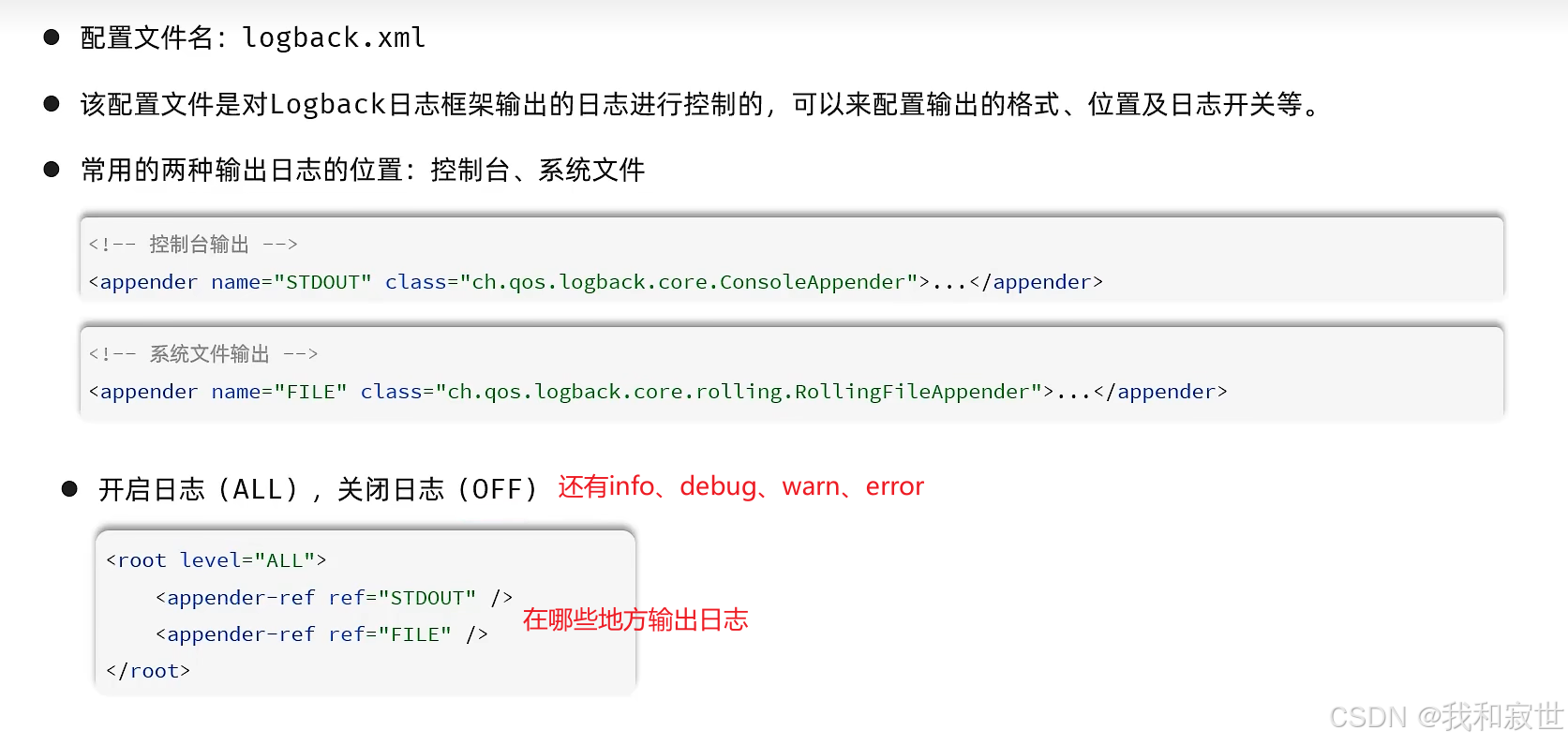
模板:
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="60 seconds" debug="false">
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<!-- 应用名称-->
<springProperty scope="context" name="appName" source="spring.application.name" defaultValue="iam.log"/>
<property name="MAX_HISTORY" value="30"/>
<!-- 普通日志信息:看看SQL、LOG之类的 -->
<property name="ORDINARY_LOG_FILE_NAME_PATTERN" value="logs/${appName}/ordinary.%d{yyyy-MM-dd}.log.gz"/>
<!-- 关键信息:用于排查问题 -->
<property name="CRUX_LOG_FILE_NAME_PATTERN" value="logs/${appName}/crux.%d{yyyy-MM-dd}.log.gz"/>
<!-- 日志格式 -->
<property name="CONSOLE_LOG_PATTERN"
value="%clr(%d{${LOG_DATEFORMAT_PATTERN:-yyyy-MM-dd HH:mm:ss.SSS}}){faint} - [%X{n-d-trace-id}] -%clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%c){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
<property name="FILE_LOG_PATTERN"
value="%d{${LOG_DATEFORMAT_PATTERN:-yyyy-MM-dd HH:mm:ss.SSS}} - [%X{n-d-trace-id}] - ${LOG_LEVEL_PATTERN:-%5p} ${PID:- } --- [%t] %c : %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
<!--输出到控制台-->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
</encoder>
</appender>
<!--输出到普通信息文件-->
<appender name="ordinaryFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${ORDINARY_LOG_FILE_NAME_PATTERN}</fileNamePattern>
<!-- 日志保留天数 -->
<maxHistory>${MAX_HISTORY}</maxHistory>
<!-- 日志文件上限大小,达到指定大小后删除旧的日志文件 -->
<totalSizeCap>3GB</totalSizeCap>
<!-- 每个日志文件的最大值 -->
<!--<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>-->
</rollingPolicy>
<encoder>
<pattern>${FILE_LOG_PATTERN}</pattern>
</encoder>
</appender>
<appender name="cruxFileWarn" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${CRUX_LOG_FILE_NAME_PATTERN}</fileNamePattern>
<!-- 日志保留天数 -->
<maxHistory>${MAX_HISTORY}</maxHistory>
<!-- 日志文件上限大小,达到指定大小后删除旧的日志文件 -->
<totalSizeCap>5GB</totalSizeCap>
<!-- 每个日志文件的最大值 -->
<!--<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>30MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>-->
</rollingPolicy>
<encoder>
<pattern>${FILE_LOG_PATTERN}</pattern>
</encoder>
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>warn</level>
</filter>
</appender>
<!-- region 根据不同的环境设置不同的日志输出级别 -->
<springProfile name="default,local,dev,demo">
<root level="info">
<appender-ref ref="console"/>
<appender-ref ref="ordinaryFile"/>
<appender-ref ref="cruxFileWarn"/>
</root>
<logger name="com.wemirr" level="debug"/>
</springProfile>
<springProfile name="prod,pre,test">
<root level="info">
<appender-ref ref="console"/>
<appender-ref ref="ordinaryFile"/>
<appender-ref ref="cruxFileWarn"/>
</root>
<logger name="com.wemirr" level="debug"/>
</springProfile>
<logger name="com.alibaba.nacos" level="warn"/>
<logger name="org.springframework.amqp.rabbit" level="warn"/>
</configuration>

















 2616
2616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









