







21年9月6日———有关深度学习的Tips
**在训练的结果中,训练集和测试集都可能不会达到预期的结果,对于训练集结果不好的原因有:
1.模型的架构有问题
2.学习率的问题
而对于测试集可能的原因是:
1.早停
2.正则化
3.Dropout
**
首先针对训练集中模型的架构有问题进行解析:
那么首先要知道一个现象叫做Vanishing Gradient Problem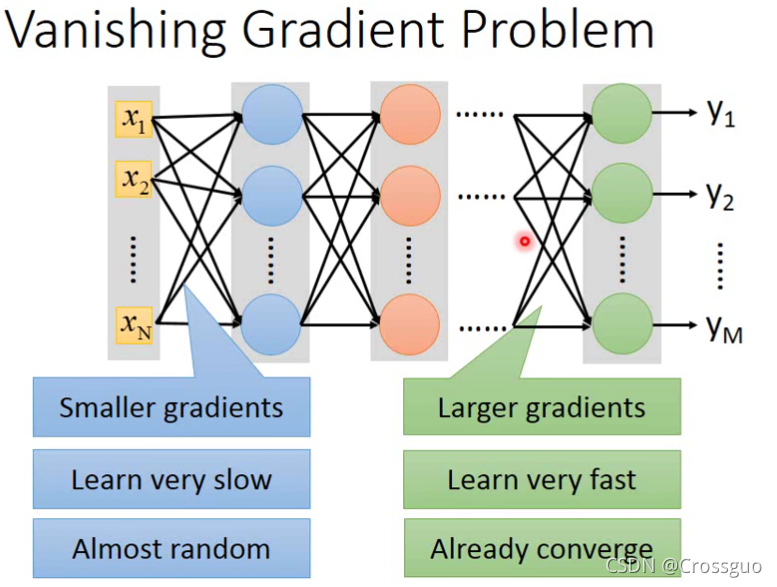
意思是说,因为sigmoid函数的存在,导致输入的变化并不会产生线性的输出变化(输出的变化率低于输入的变化率),如图所示:
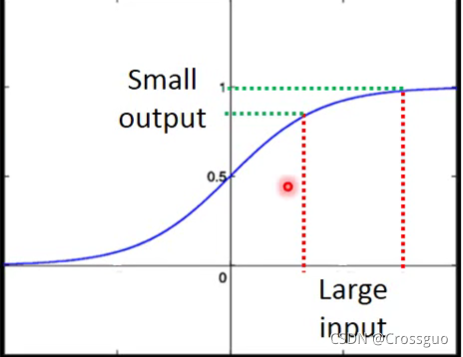
因此在多层的情况下,第一层很大变化的w对输出的影响是很小的,根据这个理念,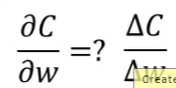
第一层的梯度是非常小的(因为经过了很多歌sigmoid),而最后一层的梯度会是最大的(因为只经过了一个sigmoid),那么因此可见,在多层的情况下,输入对输出的影响非常小!
为了改善这个情况,因为原因就出在sigmoid函数上,所以提出改良激活函数ReLU!
ReLU全称为Rectified Linear Unit,整流线性单元。
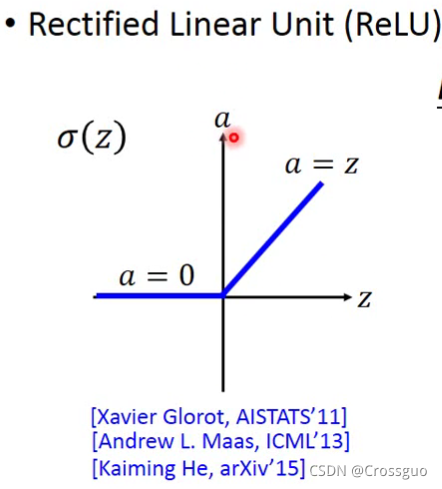
在p14视频里有讲解有关ReLU和Maxout之间的关系(ReLU是Maxout的特殊情况),那么Maxout这个算法就是说每层中间,
一对输出里只保留最大的那一个,较小的那个被舍弃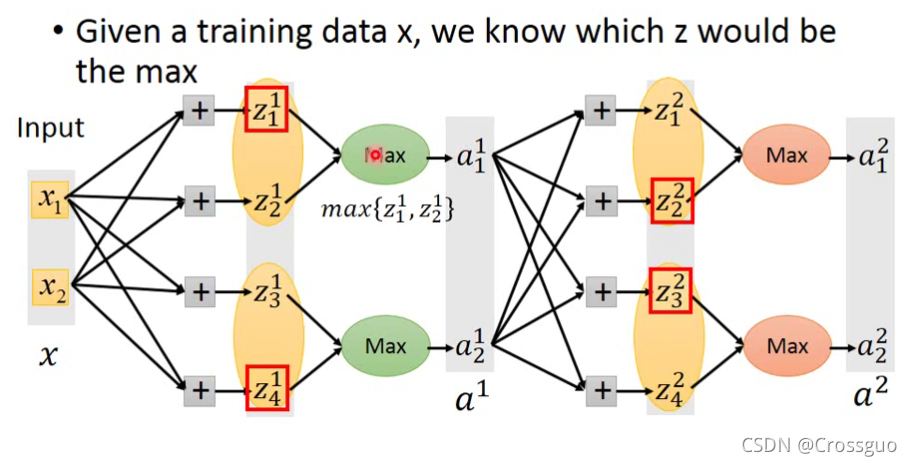
那么综上,解决Vanishing Gradient Problem的方法就是使用ReLU,有关改善深度学习模型架构的介绍就到此为止。
接下里介绍训练集中出现的学习率的问题,提出自适应学习率
略,主要讲解Adam算法
对于测试集出现未达到预期效果的解释
对于早停和正则化的概念于书本P107页有解释,略写
着重解释Dropout
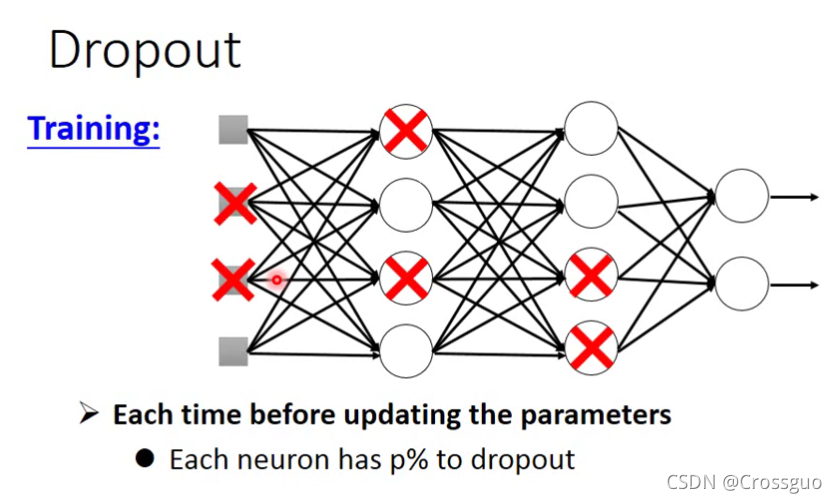
如上图,在训练的时候,按照p%的概率去舍弃一部分神经元,用这个新的神经网络去训练数据。因此用这个方法去训练的时候效果是会变差的,因为舍弃了一部分神经元,但是它能让测试结果变得更好,是一种非常之有效消除过拟合的方法。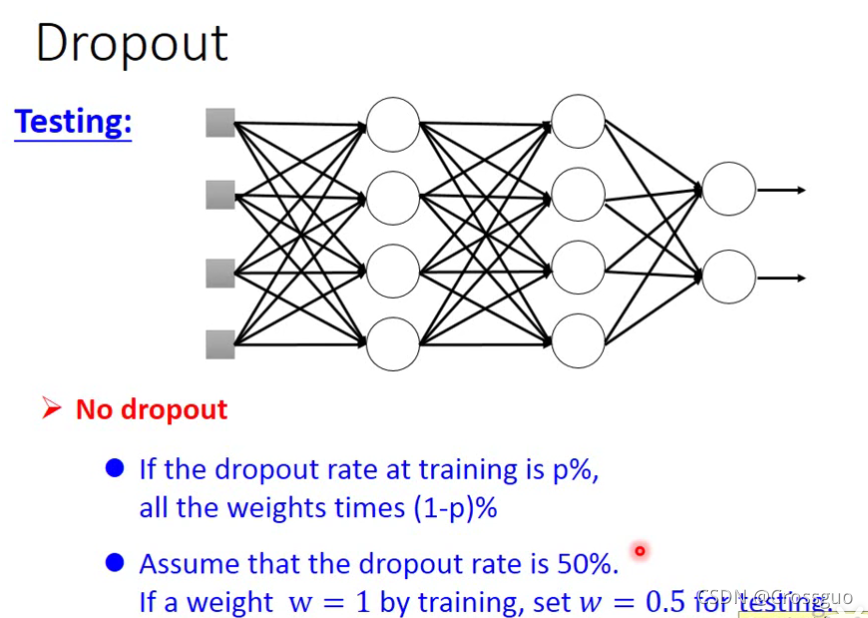
但是注意,在测试时,是不做Dropout的!
并且如果Dropout率是p%,那么要对所有的权重乘上(1-p)%
那么对这个测试结果会变得更好的解释是:
一群学生,只有个几个再好好做项目,而剩下的并没有好好做(神经元被Dropout了),因此在做项目的几个人就会carry,但是在真正测试的时候,大家都在好好做了,因此就能得到更好的数据结果。
而为什么
Dropout率是p%,那么要对所有的权重乘上(1-p)%
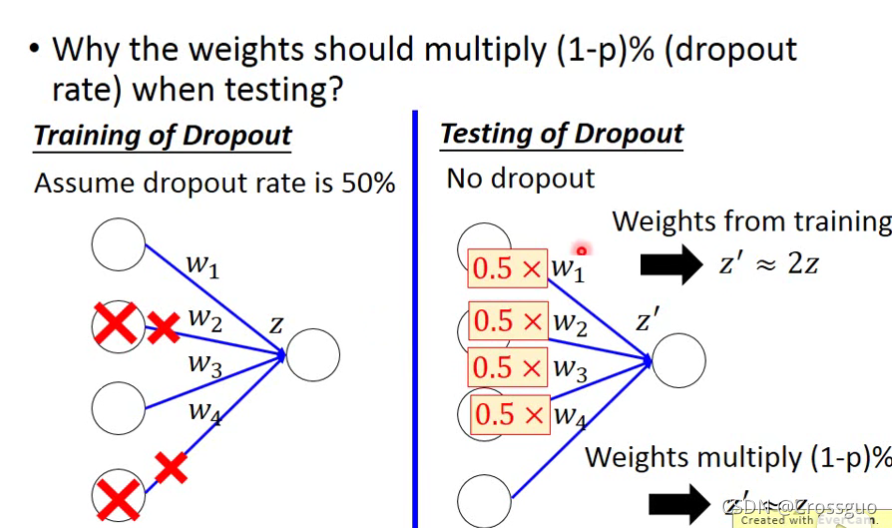
这是一种解释,会显得比较牵强,网上还有其他的说法,值得一看。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









