







 文章讨论了神经网络中激活函数的重要特性,如非线性、可微性和单调性,并对比了Sigmoid、Tanh和ReLU函数的优缺点。同时,介绍了损失函数的概念,包括均方误差MSE和交叉熵损失函数CE,以及它们在优化过程中的作用。
文章讨论了神经网络中激活函数的重要特性,如非线性、可微性和单调性,并对比了Sigmoid、Tanh和ReLU函数的优缺点。同时,介绍了损失函数的概念,包括均方误差MSE和交叉熵损失函数CE,以及它们在优化过程中的作用。
1.激活函数
1.优秀的激活函数具有的特点:
非线性:使得多层神经网络可逼近所有函数
可微性:优化器大多用梯度下降更新参数
单调性:能保证单层网络的损失函数是凸函数
近似恒等性:当参数初始化为随机小值时,神经网络更稳定
2.激活函数输出值的范围
(1)为有限值时,权重对特征的影响会更加显著,用梯度下降法更新参数会更加稳定
(2)为无限值时,参数的初始值对模型的影响会非常大,要使用更小的学习率
3.Sigmoid函数 tf.nn.sigmoid(x)
输出值在0到1之间
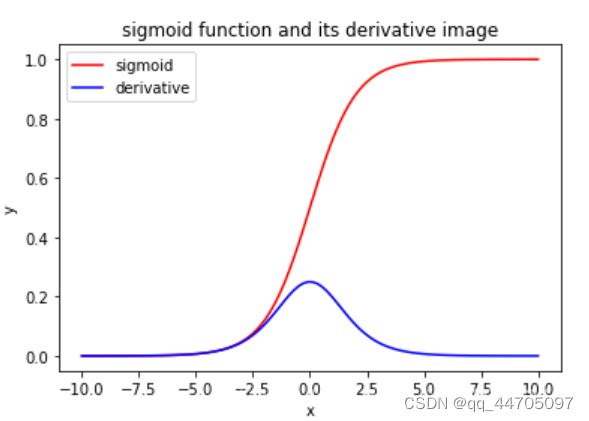
易造成梯度消失(深层网络更新时,需要从输出层到输入层逐层进行链式求导,而sigmoid函数的导数输出是0到0.25间的小数,链式求导需要多层导数连续相乘,会出现多个0到0.25之间的连续相乘,结果将趋于0,产生梯度消失,使得参数无法继续更新。) 输出非0均值,收敛慢(我们希望输入每次神经网络的特征是以0为均值的小数,但是过sigmoid激活函数后的数据都是正数,会使收敛变慢)幂运算复杂,训练时间长。
4.Tanh函数 tf.math.tanh(x)
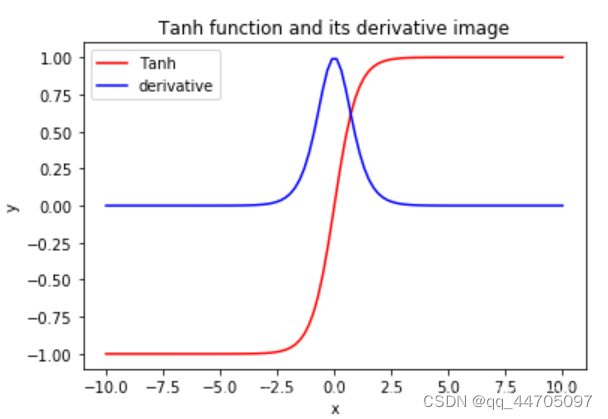
它解决了Sigmoid函数的不以0为中心输出问题,然而,梯度消失的问题和幂运算的问题仍然存在,且幂运算复杂,训练时间长。
5.Relu函数 tf.nn.relu(x)
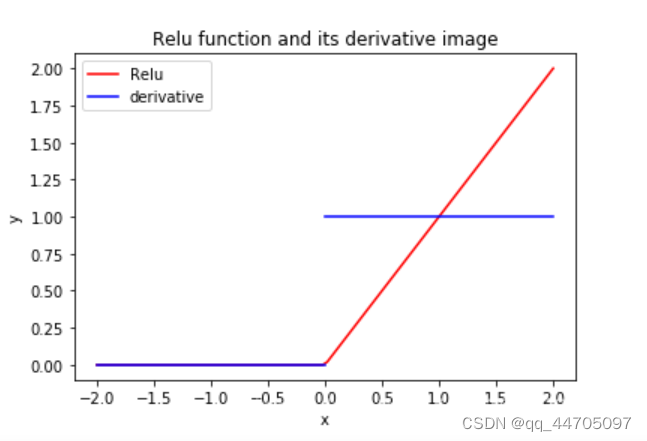
优点: 解决了梯度消失的问题(在正区间),只需要判断输入是否大于0,计算速度快,收敛速度远快于sigmoid和tanh
缺点:输出非0均值,收敛慢,Dead Relu问题:送入激活函数的输入特征是负数时,激活函数输出是0,反向传播得到的梯度是0,导致参数无法更新,造成神经元死亡。(可以通过设置更小的学习率,减少参数分布的巨大变化,来避免训练中产生过多负数特征进入relu函数)
6.激活函数选取建议:
首先relu函数,学习率设置较小值,输入特征标准化(以0为均值,1为标准差的正态分布),初始参数中心化(以0为均值,为标准差的正态分布,n为当前层输入特征个数)。
2.损失函数
即预测值y与标签值y1的差距,神经网络优化的目标:loss最小
loss(MSE,自定义,ce(cross entropy))
1.均方误差MSE:
loss_mse=tf.reduce_mean(tf.square(y-y1))
2.自定义
import tensorflow as tf
import numpy as np
SEED = 23455
rdm = np.random.RandomState(seed=SEED) # 生成[0,1)之间的随机数
x = rdm.rand(32, 2)
y_ = [[x1 + x2 + (rdm.rand() / 10.0 - 0.05)] for (x1, x2) in x] # 生成噪声[0,1)/10=[0,0.1); [0,0.1)-0.05=[-0.05,0.05)
x = tf.cast(x, dtype=tf.float32)
w1 = tf.Variable(tf.random.normal([2, 1], stddev=1, seed=1))
epoch = 15000
lr = 0.002
for epoch in range(epoch):
with tf.GradientTape() as tape:
y = tf.matmul(x, w1)
loss_mse = tf.reduce_mean(tf.square(y_ - y))
# loss = tf.reduce_sum(tf.where(tf.greater(y, y_), (y - y_) * COST, (y_ - y) * PROFIT)) # 自定义损失函数
grads = tape.gradient(loss_mse, w1)
w1.assign_sub(lr * grads)
if epoch % 500 == 0:
print("After %d training steps,w1 is " % (epoch))
print(w1.numpy(), "\n")
print("Final w1 is: ", w1.numpy())3.交叉熵损失函数CE(cross entropy):
表征两个概率分布之间的距离
tf.losses.categorical_crossentropy(y,y1)
loss_ce1=tf.losses.categorical_crossentropy([1,0],[0.6,0.4])
loss_ce2=tf.losses.categorical_crossentropy([1,0],[0.8,0.2])
print("loss_ce1:",loss_ce1)
print("loss_ce2:",loss_ce2)4.softmax与交叉熵的结合
输出先过softmax函数,在计算y与y1的交叉损失函数
tf.nn.softmax_cross_entropy_with_logits(y,y1)
y_= np.array([[1,0,0],[0,1,0],[0,0,1],[1,0,0],[0,1,0]])
y = np.arry([[12,3,2],[3,10,1],[1,2,5],[4,6.5,1.2],[3,6,1]])
y_pro=tf.nn.softmax(y)
loss_ce3 = tf.losses.categorical_crossentropy(y_,y_pro)
loss_ce4 = tf.nn.softmax_cross_entropy_with_logits(y_,y)
print("分步计算的结果:\n",loss_ce3)
print("结合计算的结果:\n",loss_ce4)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









