






 本文通过四种优化算法:最速下降法、牛顿法、共轭梯度法和BFGS法,结合精确线搜索求解二次函数问题,详细比较了它们的收敛速度和效率。
本文通过四种优化算法:最速下降法、牛顿法、共轭梯度法和BFGS法,结合精确线搜索求解二次函数问题,详细比较了它们的收敛速度和效率。
啊第一次在csdn上写东西,在前些时候优化方法的计算实习老师留了一些上机作业,第一道题目是用不同的优化算法结合最速下降法求解二次函数。
二次函数及梯度的生成
先贴代码/matlab:
function Function_value = Quadratic_function(x)
%Quadratic_function(x)函数用来对给定的x返回二次函数值
n = 146;
a = unidrnd(10,n,1);
G = a*a'+unidrnd(2)*eye(n);
b = 0.5*G*ones(n,1);
Function_value = 1/2*(x')*G*x-(b')*x;
我们使用unidrnd函数生成随机整数的列向量,我们的基础二次函数的形式是:
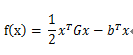
以及写出的梯度函数为之后做准备,不过这个函数的梯度特别好求,写不写都可。
function Gradient_value = Function_gradient(x)
%我们将要计算函数Quadratic_function对146个变量的导数
Gradient_value = G*x - b;
最速下降法加精确线搜索
function xk = Steepest_plus_Exact_line_search()
%我们采用精确线搜索加最速下降法
x0 = zeros(146,1);
eps = 0.001;
n = 146;
a = unidrnd(10,n,1);
G = a*a'+unidrnd(2)*eye(n);
b = 0.5*G*ones(n,1);
%做循环的准备条件
k = 0;xk = x0;
res = norm(Function_gradient(xk));
while res > eps && k<=10000
%dk
gk = G*xk-b;
dk = -gk;
%alphak
alphak = (gk'*gk)/(gk'*G*gk);
xk = xk + alphak*dk;
%更新k
k = k+1;
res = norm(gk);
%打印循环情况
fprintf('在%d-th轮,梯度的值为——%f\n',k,res);
end
啊最速下降法的收敛速度是最慢的。
牛顿法加精确线搜索
function [xk,k] = Newtown_plus_Exact_line_search()
%我们采用精确线搜索加最速下降法
x0 = zeros(146,1);
eps = 0.001;
n = 146;
a = unidrnd(10,n,1);
G = a*a'+unidrnd(2)*eye(n);
b = 0.5*G*ones(n,1);
%做循环的准备条件
gk = Function_gradient(x0);
res = norm(gk);
k = 0;
xk = x0;
G_inverse = inv(G);
alphak = 1;
while res > eps && k<=10000
%dk
dk = -G_inverse*gk;
gk = G*xk-b;
alphak = -(dk'*gk)/(dk'*G*dk);
%xk
xk = xk + alphak * dk;
%f = Quadratic_function(xk);
k = k + 1;
res = norm(gk);
%打印循环结果
fprintf('在%d-th轮,梯度的值为——%f\n',k,res);
end
然后牛顿法是最快的,因为实际上对于二次函数问题来说的话,牛顿法可以一步达到最小值点。
共轭梯度法
function [x_star]=Conjugate_gradient_method()
%在该脚本下我们使用共轭梯度法进行求解
%给定x0,eps
x0 = zeros(146,1);
eps = 0.001;
%为方便使用将条件列出:
n = 146;
a = unidrnd(10,n,1);
G = a*a'+unidrnd(2)*eye(n);
b = 0.5*G*ones(n,1);
gradk = G*x0 - b;
k=0;
%选择初始点,最大迭代次数
xk=x0;
maxit=10000;
while 1
%gradk的二范数
res=norm(gradk);
%第k次迭代
k=k+1;
%算法停止条件
if res<=eps||k>maxit
break;
end
%确定下降方向
dk=-gradk;
%计算步长
alphak=-gradk'*dk/(dk'*G*dk);
%迭代核心
xk=xk+alphak*dk;
%计算Beta
grad_temp=gradk;
gradk=G*xk-b;
Betak=gradk'*gradk/(grad_temp'*grad_temp);
dk=-gradk+Betak*dk;
fprintf('At the %d-th iteration,the residual is %f\n',k,res);
end
x_star=xk;
共轭梯度达到最小值不超过n步,但迭代一段时间之后,正交性会消失,实际步数可能会比n多。
BFGS加精确线搜索
function[x_star]= BFGS_plus_Exact_line_search()
%在该脚本下我们使用BFGS加精确线搜索求解问题
%给定x0,eps
x0 = zeros(146,1);
eps = 0.001;
xk=x0;
%为方便使用将条件列出:
n = 146;
a = unidrnd(10,n,1);
G = a*a'+unidrnd(2)*eye(n);
b = 0.5*G*ones(n,1);
%gk,hess阵
gradk = Function_gradient(xk);hess = G;
res=norm(gradk);k=0;Hk=eye(146);
%开始循环
while res>eps&&k<=10000
dk=-Hk*gradk;
%exact line search
alphak=-dk'*gradk/(dk'*hess*dk);
%保存xk
xkk=xk;
%计算下一点
xk=xk+alphak*dk;
%两点差
deltak=xk-xkk;
%保存xk的梯度
gradkk=gradk;
%unidrnd生成的数是随机的,要用第一次hess阵和b
gradk=hess*xk-b;
%两点梯度差
yk=gradk-gradkk;
%bfgs公式
Hk=(eye(146)-(deltak*yk')/(deltak'*yk))*Hk*(eye(146)-(yk*deltak')/(deltak'*yk))+(deltak*deltak')/(deltak'*yk);
k=k+1;
%下一点梯度范数
res=norm(gradk);
fprintf('At the %d-th iteration,the residual is:----%f\n',k,res)
end
x_star=xk;
end
最后通过这四种方法计算出来的结果应该均是收敛到0.5,所以到此就做完了这道题!
- 不过有一说一,在做完之后看代码确实有好多问题,其实我觉得首先梯度文件就不用写,每次要求梯度的时候直接用Gx-b就很方便,而且写的过程中,也要一直用初始的G和b,但是如果多次调用function_value函数的话就每次随机得到的也是不同的矩阵,所以就会出问题,也是自己遇到的问题之一。
- 第二个问题是写这种算法,很容易思路混乱,所以下次如果再有类似的情况,希望自己可以先将算法一步一步写出来,这样的话编程序的时候也思路比较清楚,而且修改代码也更容易。
啊到这第一篇就写完了!!完事 收工!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









