







PathGen-1.6M: 1.6 Million Pathology Image-text Pairs Generation through Multi-agent Collaboration

目录
1. 引言
本文提出了 PathGen-1.6M,这是目前规模最大、质量最高的病理图像-文本对数据集,包含 1.6M 图文对。通过使用来自 The Cancer Genome Atlas(TCGA)的全图(Whole Slide Images, WSI)病理图像并结合多个 agent 模型进行协同操作,自动生成并筛选了代表性图像 patch,并为其生成高质量文字描述,从而克服了传统图文数据来源稀缺、图像质量差和不可扩展的难题。
此外,本文还构建了 PathGen-CLIP 与 PathGen-LLaVA 模型,前者在九个病理任务中零样本表现大幅超越现有模型,后者则在多模态任务中优于 GPT-4V。PathGen 提供了一种可扩展的高质量病理数据生成路径,推动通用病理模型的发展。
1.1 关键词
病理图像(Pathology Image)、多模态模型(Multimodal Model)、图像文本对(Image-Text Pair)、图文检索(Cross-modal Retrieval)、多智能体协同(Multi-agent Collaboration)
2. 相关工作
在视觉-语言模型训练方面,开放领域已有 LAION-5B、WIT-400M 等数据集,病理领域则存在ARCH、PathCap、OpenPath 和 Quilt-1M 等,但大多图像来源于社交媒体或教材,质量参差不齐,文本与图像对齐度低,且规模有限。
CLIP 在病理图像分类、检索及多模态理解方面展现强大潜力,因此也催生了多个病理专用变种,如 PubMedCLIP、PMC-CLIP、PLIP、PathCLIP 等。
近年来,大型多模态模型(LMM)如 BLIP-2、Flamingo 的兴起也带动了医学领域的指令微调与描述生成模型的发展,如 PathAsst、LLaVA-Med 等。多智能体协同在软件开发、社会模拟等任务中也被广泛应用,为病理图文对自动生成提供了新思路。
3. PathGen 数据集构建
3.1 Agent 模型准备
PathGen-CLIP-L_{init}:清洗不对齐的图文对后,获得来自 PathCap(200K)、OpenPath(100K)和 Quilt-1M(400K)的 700K 图文对 PathGen_{init},对 OpenCLIP 训练得到 PathGen-CLIP-L_{init}。
描述大型多模态模型智能体(Description LMM Agent)PathGen-LLaVA_{desp}:采样来自 PathCap(10K)、OpenPath(10K)和 Quilt-1M(10K)的 30K 图文对,通过 GPT-4V 增强原始描述后,结合 LLaVA-v1.5- 13B 训练出病理特定描述模型 PathGen-LLaVA_{desp}。其中,LLaVA-v1.5- 13B 的 OpenAI-CLIP 视觉编码器被替换为 PathGen-CLIP-L_{init}。
Revise Agent,这是基于 LLaVA-v1.5-13B 构建的病理学 LMM,具有纠错功能。它利用由 PathGen-LLaVA_{desp} 和 GPT-4 生成的描述,并通过添加、删除、编辑引入可控的不精确性。通过基于(图像,描述,编辑操作)三元组的训练,使模型具备稳健的纠错能力。
Summarize Agent:使用 GPT-4 生成指令微调数据集,并微调 LLaMA-2 得到 Summarize Agent,用于将 PathGen-LLaVA_{desp} 生成的超长描述压缩到 CLIP 所需的 77 token 以内。
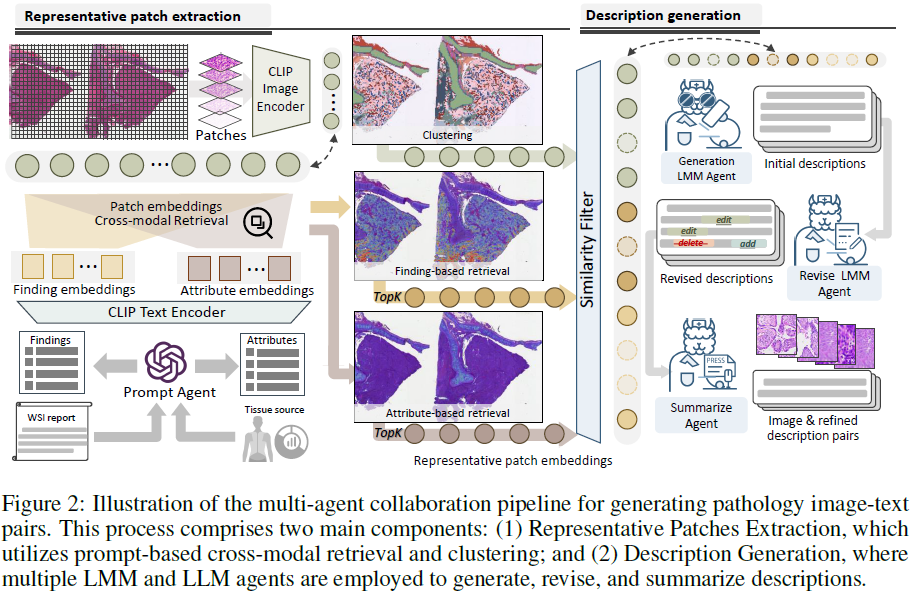
3.2 数据构建流程
从 TCGA 中选取 7500 个带有报告的 WSI 图像,采用五步流程构建数据集:
1)代表性图像 patch 提取(检索和聚类):
- 使用 PathGen-CLIP-L_{init},结合两类 prompt(报告文本和组织器官属性)进行图像-文本检索,每种方式各选 64 个 patch,总计 128 patch
- 由于基于提示的检索主要关注病理变化程度较高的 patch,因此可能会忽略具有其他形态变化的 patch。为了解决这个问题,使用 PathGen-CLIP-L_{init} 从 WSI 斑块中提取特征,并对这些特征应用 k-means 聚类,额外采样 256 个,合并后得到 384 个 patch。
2)相似 patch 过滤:使用 PathGen-CLIP-L_{init} 计算特征相似度并去除相似度大于 0.88 的 patch,保留信息多样性。
3)描述生成:用 PathGen-LLaVA_{desp} 为每个 patch 生成详细描述。
4)描述修订:通过 Revise Agent 检测并修复潜在错误。
5)描述总结:将冗长描述压缩为适配 CLIP 的简洁摘要,确保信息完整性。
最终生成 1.6M 图文对,涵盖 27 种不同组织类型。

3.3 专家评估

通过人工评估对比 PathGen 与 OpenPath 描述质量。结果显示 PathGen 的准确率达 90% 以上,平均每条描述含 5.3 条有效病理发现(Findings),明显优于 OpenPath 的 75%-77% 准确率与 2 条发现,验证其质量更高。
4. 实验
4.1 模型训练细节
PathGen-LLaVA_{desp} 分两阶段训练:先用 PathGen_{init} 对齐图像(PathGen-CLIP-L_{init})与文本(Vicuna LLM),连接器是一个全连接(FC)层。再用由 GPT-4V 生成的详细描述微调 FC 和 Vicuna 。
PathGen-CLIP 先以 PathGen-1.6M 训练获取形态学理解,再用 PathGen_{init} 增强诊断能力。实验证明分阶段训练优于混合训练。
4.2 零样本图像分类
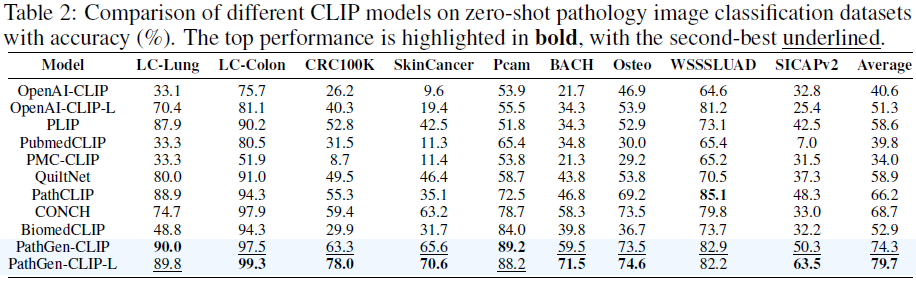
在 9 个病理分类数据集上评估模型性能,PathGen-CLIP-L平均准确率达 79.7%,显著高于 CONCH(68.7%)与其他 SOTA 模型。尤其在 Pcam、SkinCancer 等任务上提升超过 20%。结果表明,PathGen 数据在未标注场景中极具临床应用潜力。
4.3 少样本图像分类
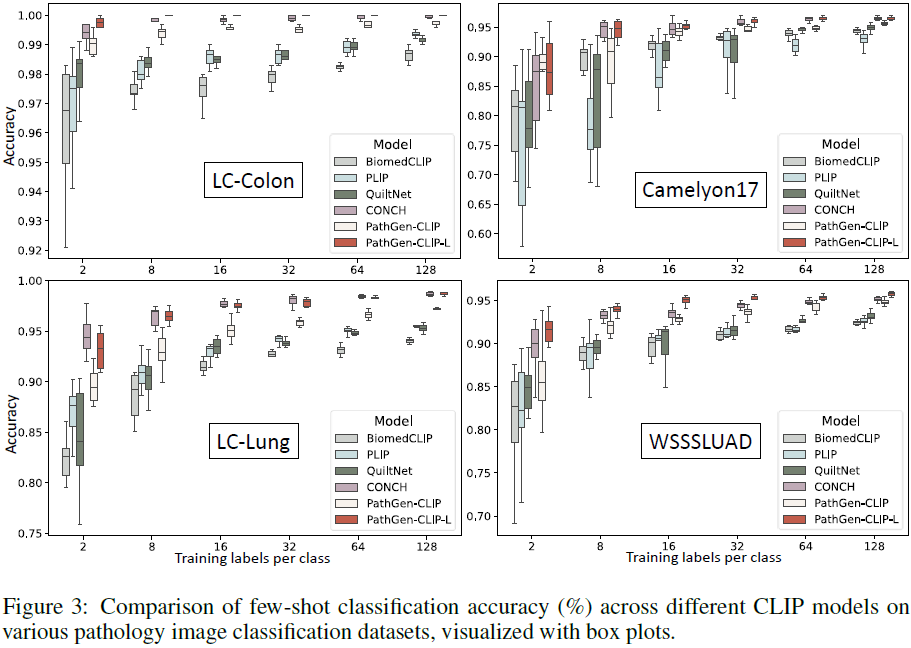
在 4 个数据集上通过线性探测评估 few-shot 能力。PathGen-CLIP-L 在仅 2-shot 下即达 92% 准确率,远超其他模型,表现更稳健,收敛更快,验证其在低资源环境下的优势。
4.4 全图像分类
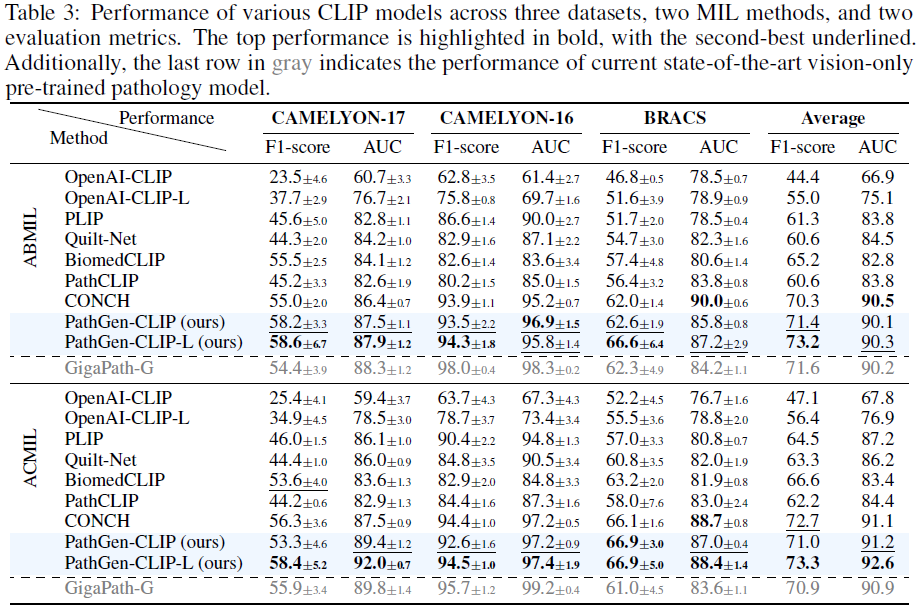
在 CAMELYON16/17 与 BRACS 数据集上进行 WSI 分类任务评估。结合 ABMIL 与 ACMIL 两种 MIL 方法,PathGen-CLIP-L 取得平均 AUC 92.6%,优于 QuiltNet、BiomedCLIP、CONCH 等,同时与体量更大、数据私有的 GigaPath-G 模型表现持平甚至超越。
4.5 与大型语言模型整合
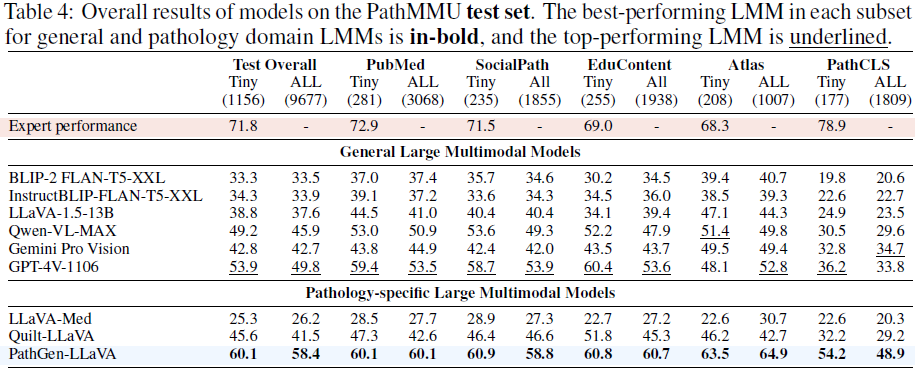
基于 PathGen 数据构建 200K 指令微调样本,结合 Vicuna 和 PathGen-CLIP-L 训练得到 PathGen-LLaVA。在 PathMMU 测试集上,PathGen-LLaVA 整体表现优于 GPT-4V 与其他医学多模态模型,验证其病理图像理解和推理能力。
4.6 可扩展性与通用性探索

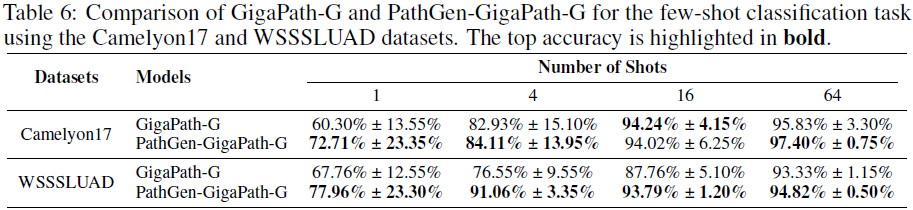
扩展方法包括加入无报告 WSI 数据(PathGen-CLIP-L*)、扩大模型规模(PathGen-CLIP-H)以及将图文能力迁移到视觉模型(PathGen-GigaPath-G)。
实验证明:
- 即使无报告数据也能提升性能;
- PathGen 数据适用于更大模型;
- 可用于视觉模型图文能力迁移且增强 few-shot 性能,显示其广泛适应性。
5. 结论
本文提出了 PathGen-1.6M,首个由多 agent 协作生成的超大规模高质量病理图文数据集,并基于此构建了 PathGen-CLIP 与 PathGen-LLaVA,分别在图像分类与多模态任务上大幅提升性能。系列实验验证了该方法在可扩展性、适应性、准确性等方面的优势,为通用病理 AI 模型提供了新的可能。
论文地址:https://openreview.net/forum?id=rFpZnn11gj
项目页面:https://github.com/PathFoundation/PathGen-1.6M
进 Q 学术交流群:922230617


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









