







MISS: A Generative Pretraining and Finetuning Approach for Med-VQA

目录
1. 引言
医疗视觉问答(Med-VQA)是一个基于视觉和语言的多模态任务,旨在回答关于医疗图像的问题。尽管当前的视觉语言预训练模型(VLP)在 Med-VQA 任务中表现出色,但面临以下挑战:
- 任务局限:通常被视为分类任务,难以适应真实应用场景。
- 数据稀缺:由于医疗隐私和标注成本,缺乏大规模的高质量医疗图像-文本数据集。
本文提出了一个名为 MISS 的框架(MultI-task Self-Supervised-learning-based framework),以生成式任务替代传统分类任务,并通过多任务自监督学习提升性能。此外,提出了 TransCap(Transfer and Caption)方法,借助大型语言模型(LLMs)为单模态图像数据生成描述,从而扩展多模态数据集。
1.1 关键词
医疗视觉问答(Med-VQA)、视觉-语言预训练(VLP)、多模态学习、生成式任务、转移与描述(TransCap)
2. 相关工作
2.1 医疗视觉问答(Med-VQA)
Med-VQA通过视觉和语言理解医疗图像内容。早期研究多采用 CNN 和 RNN 提取图像和文本特征,后续 Transformer 模型引入后提升了性能。
目前的主流方法仍将任务视为分类任务,难以应对开放式问题。
2.2 视觉-语言预训练数据集
现有数据集(如 ROCO 和 MediCaT)通常从医学论文中提取图像和描述,但包含大量噪声。
为此,TransCap 方法利用 LLM 为高质量单模态图像生成描述,以弥补数据不足。
3. 方法
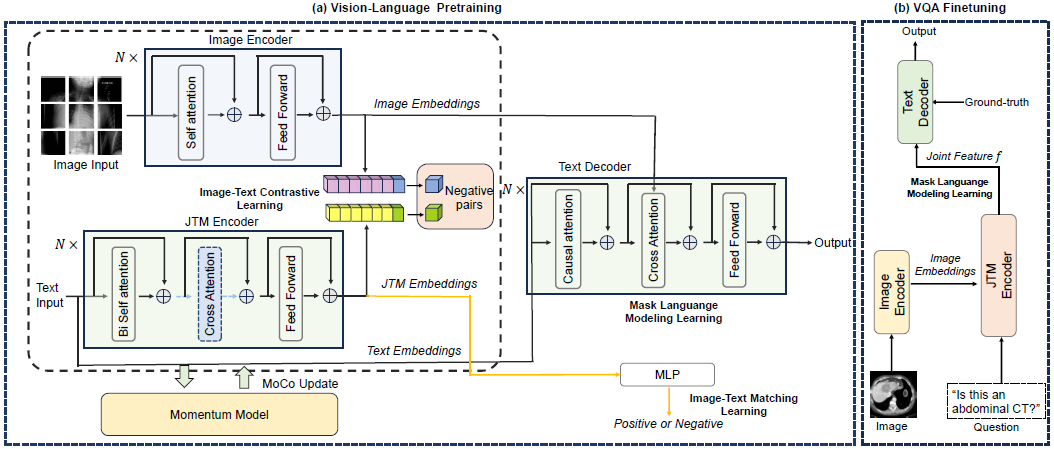
图 1:预训练(a)和微调(b)。
- 我们提出了一个用于 Med-VQA 任务的预训练和微调框架 Miss,它由图像编码器、JTM 编码器和文本解码器组成。
- ITC、ITM 和 MLM Learning 用于预训练
- 在微调阶段,多模态联合特征(joint feature)与标记化答案(tokenized answers)交互以进行 MLM Learning。
3.1 模型结构
MISS 框架包括以下三部分:
- 图像编码器:采用 ViT 将图像划分为 2D 补丁(patch)并编码为高维特征。
- 联合文本-多模态(JTM)编码器:融合文本和图像特征,采用多层 Transformer 结构,交叉注意力机制使两者充分交互。
- 文本解码器:将融合特征转为文本答案,支持生成式问答。
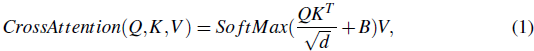
其中文本表示 {w_{<cls>}, w_1, ..., w_n} 生成查询向量 Q,图像表示 {v_{<cls>}, v_1, ..., v_n} 生成键向量 K 和值向量 V。
3.2 预训练任务
图文对比学习(Image-Text Contrastive Learning,ITC):学习单模态特征,利用动量编码器构建对比学习。
图文匹配(Image-Text Matching,ITM):二分类任务,判定图像与文本是否匹配。
掩码语言建模(Mask Language Modeling,MLM):随机掩码部分文本,通过多模态特征预测词语。
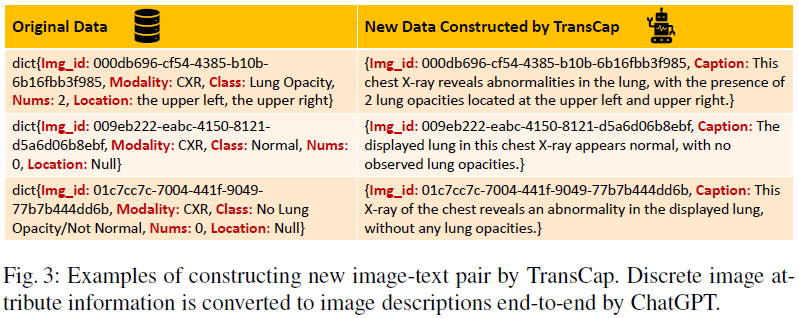
3.3 迁移和描述(TransCap)
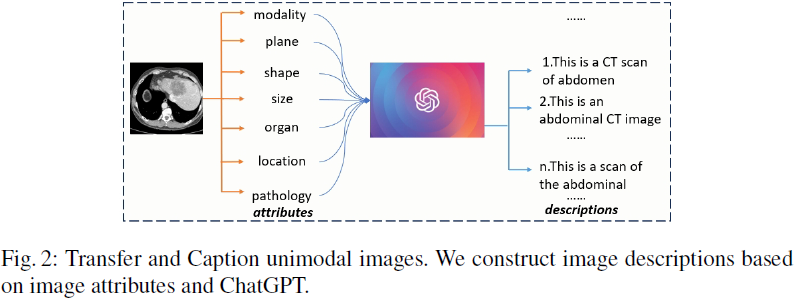
迁移和描述 (Transfer and Caption,TransCap) 是一种基于 LLM 扩展单模态图像数据特征空间的方法。
TransCap 利用 LLM 为无标签的医疗图像生成描述。具体流程如下:
- 定义图像属性(模态、平面、形状、大小、器官、位置、病理)。
- 使用 ChatGPT 生成各属性的描述文本。
- 随机组合不同属性,形成多样化的图像-文本对。
4. 实验
4.1 数据集与指标
数据集:
- VQA-RAD:315 张图像,3515 对问答。
- Slake:642 张图像,14028 对问答。
评价指标:准确率(ACC)。
4.2 实验结果
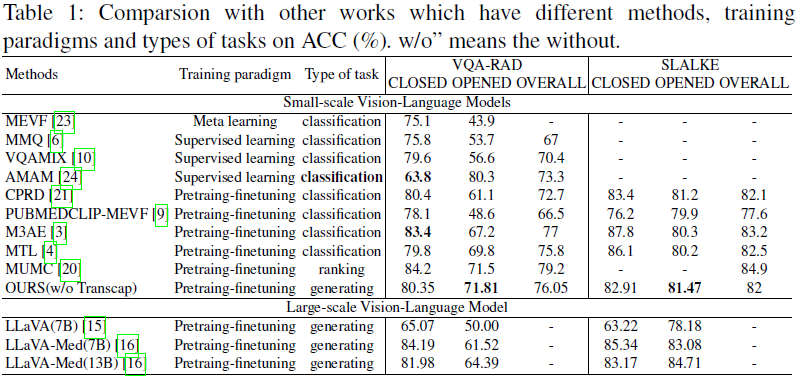
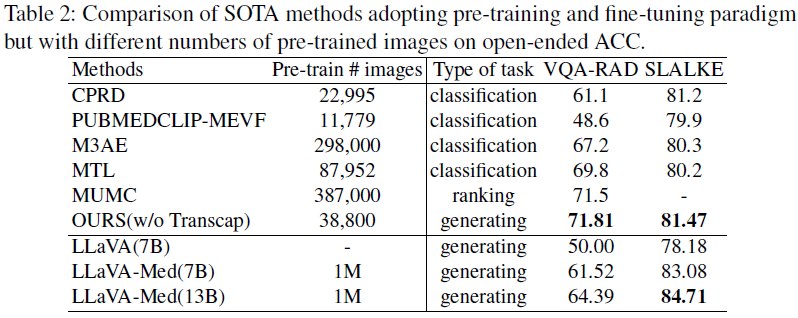
与现有方法对比:MISS 在开集和闭集问题上均表现优异,尤其在 Slake 数据集中超越了多项 SOTA 模型。
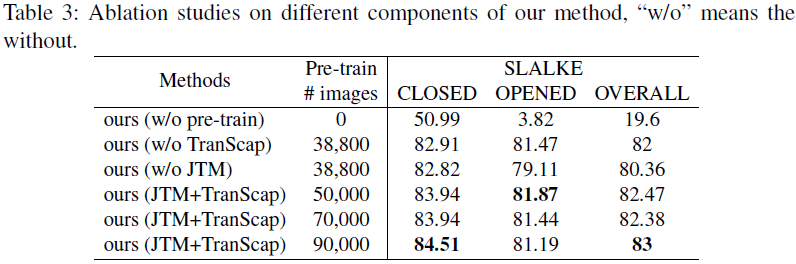
4.3 消融实验
JTM编码器:替换为传统编码器后,性能下降1.64%。
TransCap:在扩展数据集时,提升开放式和封闭式问答性能。
5. 结论
本文提出的 MISS 框架通过生成式任务改进了 Med-VQA 模型性能,并借助 TransCap 方法有效扩展了训练数据集。实验结果表明,该方法在少量数据的情况下,能够在多个基准数据集上达到 SOTA 水平,具有良好的应用前景。
论文地址:https://arxiv.org/abs/2401.05163
项目页面:https://github.com/TIMMY-CHAN/MISS.git
进 Q 学术交流群:922230617 或加 V:CV_EDPJ 进 V 交流群


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









