







DermaVQA: A Multilingual Visual Question Answering Dataset for Dermatology
目录
1. 引言
随着远程医疗的发展,患者可以通过在线平台与医生进行互动。然而,这也增加了医生的工作负担,因此自动化生成回复成为提高医生工作效率的一种可能解决方案。
本研究提出 DermaVQA 数据集,用于皮肤病学领域的 多语言视觉问答(VQA)任务。该数据集包含皮肤科相关的 用户生成的健康问题及配套图片,并提供了多个医生的回复,以支持多模态问答研究。
研究贡献:
- 数据集构建:收集了皮肤科用户生成的问答数据及相关图片,并提供多医生回复。
- 数据标注方法:整理和处理多线程健康对话,将其转换为 问答对(QA pairs)。
- 基准测试:使用 最先进的多模态模型 进行基准测试,评估多语言自动响应生成的性能。
1.1 关键词
多模态、视觉问答(VQA)、皮肤病学、自动响应生成(Response Generation)、人工智能、数据集、医疗问答、远程医疗
2. 相关研究
本研究涉及多个研究领域,包括 消费者健康问答、视觉问答(VQA)、皮肤病图像分类。
2.1 消费者健康问答
传统健康问答研究主要基于 文本数据,例如 TREC LiveQA(2017)提出的 消费者健康问题(CHQ)数据集。
在线 医生-患者对话 数据集(如 MedDialog、MedDG)包含数百万条医患对话,但大部分数据仍局限于文本,缺乏多模态信息(如图片)。
2.2 视觉问答(VQA)
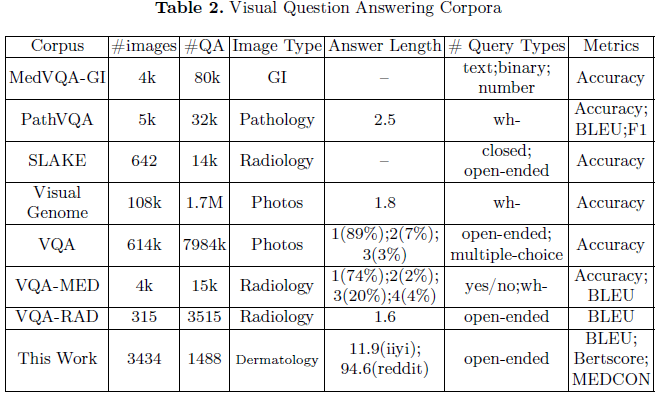
视觉问答(VQA)任务结合 图像 和 文本问题,但医学领域的 VQA 研究仍然有限,主要集中在 放射学(如 VQA-RAD、VQA-Med、PathVQA)。
医学 VQA 数据集通常 答案长度较短,问题范围有限,而 DermaVQA 数据集的回答更自然、自由,并具有较长的文本回复(>12 个词)。
2.3 皮肤病图像分类
皮肤病分类任务通常关注 疾病分类(如黑色素瘤检测) 或 属性分类(如皮损颜色、形态),例如:
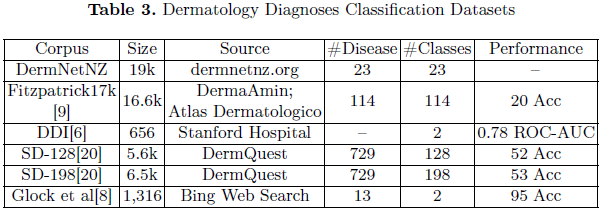
- HAM10000(包含 10,015 张影像)
- Fitzpatrick17k(包含 16.6k 张影像,涵盖 114 种疾病)
- ISIC 挑战数据集(常用于皮肤病分类竞赛)
DermaVQA 不同于传统分类任务,而是基于 开放式问答任务,需要理解问题语义并生成合理的诊断或建议。
3. 数据集构建(Corpus Creation)
本研究从 IIYI 和 Reddit 两个平台收集数据,最终构建 DermaVQA 数据集。
3.1 数据来源
IIYI 数据集(中国医疗健康论坛):
- 用户发布问题,并附带相关图片,多个医生可回复。
- 数据涵盖 患者及医生的互动,带有医生认证标识。
Reddit 数据集(r/DermatologyQuestions 子版块):
- 用户可上传皮肤相关图片,并提出问题。
- 由于回答可能来自非专业人士,因此 请专业皮肤科医生重新标注和补充回答。
3.2 数据清洗
移除 包含生殖器、面部完整识别特征(如纹身)、标注信息(如箭头) 的图片。
过滤 无意义回复(如“我也想知道答案”)。
对原始多轮对话进行转换,整理为 问答对(QA pairs)。
采用专业医学翻译将 IIYI 数据翻译成英文。
3.3 数据统计
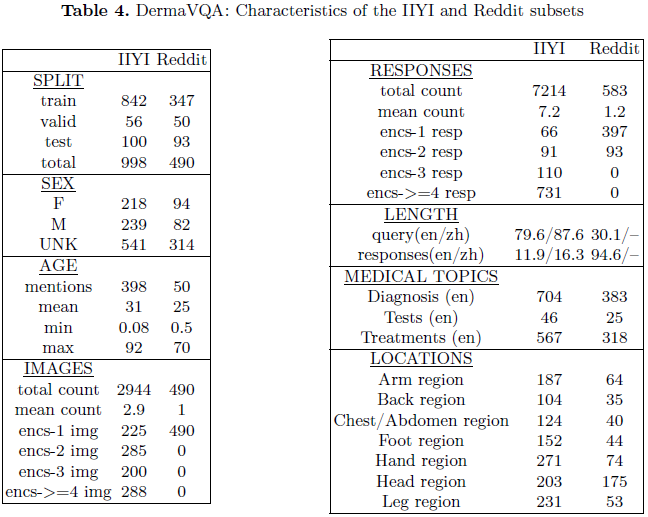
数据集总计 3,924 个案例,其中 IIYI 998 个,Reddit 490 个。统计如下:
平均年龄:
- IIYI:31 岁
- Reddit:25 岁
皮肤影像数:
- IIYI:2,944 张(平均 2.9 张/案例)
- Reddit:490 张(平均 1 张/案例)
回答数量:
- IIYI:7,214 条(平均 7.2 条/案例)
- Reddit:583 条(平均 1.2 条/案例)
4. 方法
4.1 基准测试模型
研究使用 三种最先进的多模态模型 进行测试:
- Gemini-Pro Vision(Google 多模态模型)
- GPT-4-vision-preview(OpenAI 最新视觉问答模型)
- LLaVA-FT+GPT4(自定义 VQA 系统)
- 图像到文本转换(LLaVA-Med 进行皮肤病分类)
- 文本到文本生成(GPT-4 生成最终答案)
4.2 评价指标
deltaBLEU(改进版 BLEU,考虑参考答案的质量权重)
BERTScore(基于 BERT 计算回答与标准答案的相似度)
MEDCON(医学概念匹配,评估答案的医学术语正确性)
5. 结果
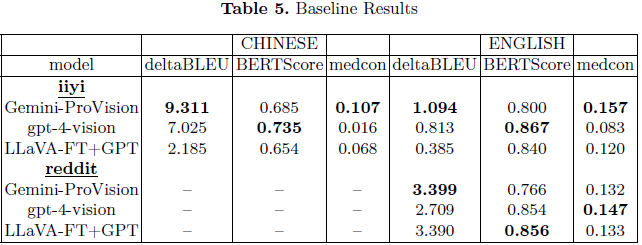
Gemini-Pro Vision 在 deltaBLEU 和 MEDCON 方面表现最佳,特别是在 中文数据集 上表现突出。
GPT-4-vision 在 BERTScore 指标上表现最优,表明它的生成文本更符合人类答案的语义。
LLaVA-FT+GPT 在 Reddit 数据集上表现较好,但整体略逊色于前两者。
6. 结论与未来工作
DermaVQA 数据集 旨在填补皮肤病多模态问答领域的空白,并为 多语言自动响应生成 提供基准测试。未来研究方向包括:
- 改进图像处理(如皮肤病区域分割、特征提取)
- 优化医学术语匹配(提高 MEDCON 评分)
- 探索更多多模态模型(如 BiomedCLIP)
- 进行真实场景测试(让医生评估 AI 生成的答案)
论文地址:https://papers.miccai.org/miccai-2024/paper/2444_paper.pdf
进 Q 学术交流群:922230617 或加 V:CV_EDPJ 进 V 交流群

















 2122
2122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









