







 本文介绍了一种使用Python的requests和BeautifulSoup库爬取2019年中国大学排名信息的方法,包括排名、学校名称、所在省份及总分等关键数据。
本文介绍了一种使用Python的requests和BeautifulSoup库爬取2019年中国大学排名信息的方法,包括排名、学校名称、所在省份及总分等关键数据。
"""
爬取中国大学2019的排名信息,爬取‘排名’,‘学校名’,‘省份’,‘总分’,这四个字段信息
爬取网址:http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html
"""
import requests
from bs4 import BeautifulSoup
import bs4
from lxml import etree
def get_html(URL):
res=requests.get(URL)
res.encoding=res.apparent_encoding
if res.status_code== 200:
html=res.text
return html
else:
pass
def soup_get_infos(html):
"""使用BeautifulSoup 提取"""
soup=BeautifulSoup(html,"lxml")
# for tr in soup.select(".hidden_zhpm tr"): #第一种定位方法
for tr in soup.find(class_="hidden_zhpm").children: #第二种定位方法
if isinstance(tr,bs4.element.Tag): # 判断子节点是否为Tag对象(因为子节点会包含如换行符之类的节点)
tds=tr("td") # tr("td")会生成一个bs4.element.ResultSet类型的数据对象,实际上就是Tag列表
data={
"排名":tds[0].string,
"学校名":tds[1].string,
"省份":tds[2].string,
"总分":tds[3].string
}
print(data)
def lxml_get_infos(html):
"""使用lxml 提取"""
soup=etree.HTML(html)
trs=soup.xpath('//tr[@class="alt"]')
for info in trs:
# 排名
rank = info.xpath('./td[1]/text()')[0]
# 学校名
name = info.xpath('./td[2]/div/text()')[0]
# 省份
province = info.xpath('./td[3]/text()')[0]
# 总分
score = info.xpath('./td[4]/text()')[0]
data = {
'排名' : rank,
'校名' : name,
'省份' : province,
'总分' : score,
}
print(data)
def main():
"""主接口"""
URL="http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html"
html=get_html(URL)
soup_get_infos(html)
# lxml_get_infos(html)
if __name__ == '__main__':
main()
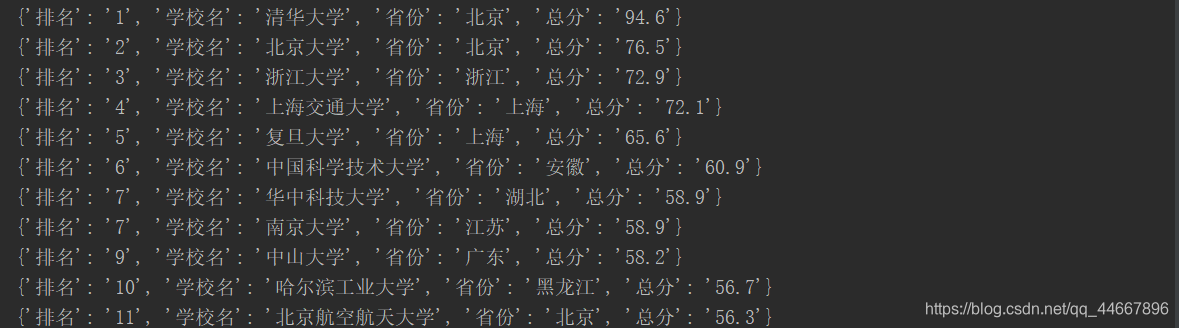
运行结果如下:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









