







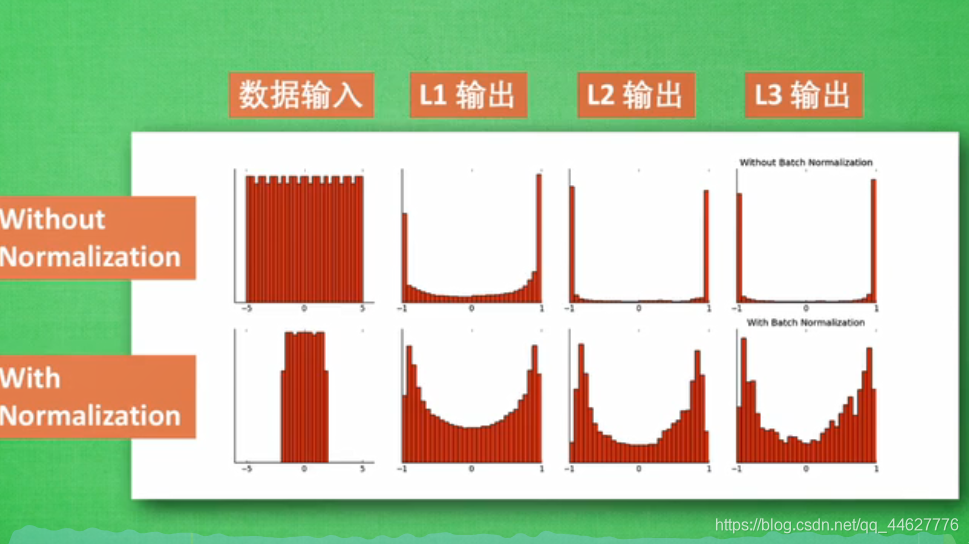
 本文介绍了批标准化在解决深度神经网络中梯度消失和饱和问题上的作用。通过批标准化处理,可以有效优化网络,使学习过程更加稳定。示例代码展示了批标准化的实现,结果显示,应用批标准化的网络能够继续学习并降低误差,而未使用批标准化的网络学习效果停滞。
本文介绍了批标准化在解决深度神经网络中梯度消失和饱和问题上的作用。通过批标准化处理,可以有效优化网络,使学习过程更加稳定。示例代码展示了批标准化的实现,结果显示,应用批标准化的网络能够继续学习并降低误差,而未使用批标准化的网络学习效果停滞。
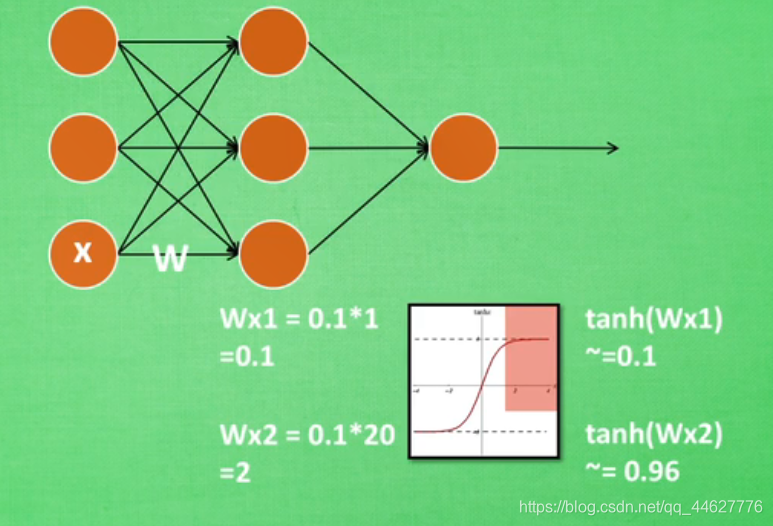
神经网络太深的话,传到后面,受到激励函数饱和区间、失效期间的影响,最后导致神经网络学不到了。
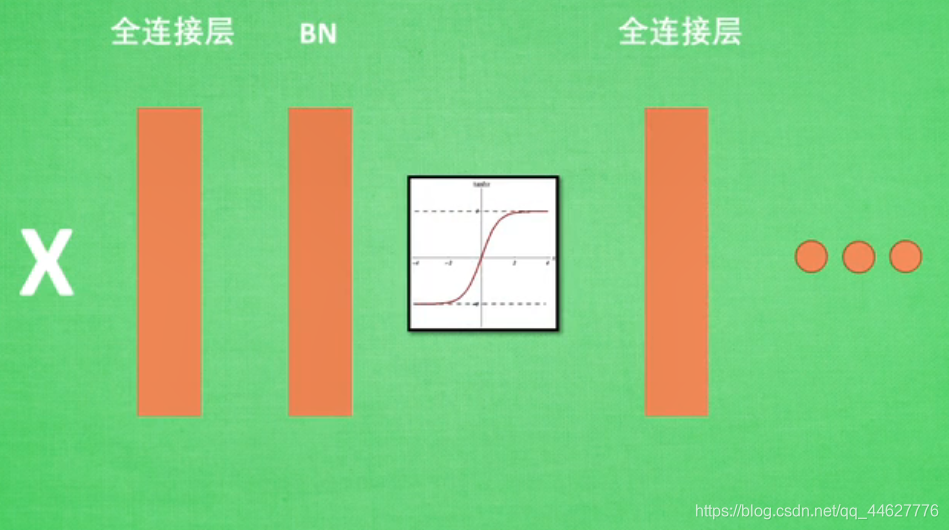
批标准化:将分散数据统一的一种方法,优化神经网络。处理方式大概为下图:
代码如下:
import torch
from torch import nn
from torch.nn import init
import torch.utils.data as Data
import matplotlib.pyplot as plt
import numpy as np
# torch.manual_seed(1) # reproducible
# np.random.seed(1)
#
N_SAMPLES = 2000
BATCH_SIZE = 64
EPOCH = 12
LR = 0.03
N_HIDDEN = 8 #8层
ACTIVATION = torch.tanh#采用的激活函数
B_INIT = -0.2 #
# 训练数据
x = np.linspace(-7, 10, N_SAMPLES)[:, np.newaxis]
noise = np.random.normal(0, 2, x.shape)
y = np.square(x) - 5 + noise
# 测试数据
test_x = np.linspace(-7, 10, 200)[:, np.newaxis]
noise = np.random.normal(0, 2, test_x.shape)
test_y = np.square(test_x) - 5 + noise
train_x, train_y = torch.from_numpy(x).float(), torch.from_numpy(y).float()
test_x = torch.from_numpy(test_x).float()
test_y = torch.from_numpy(test_y).float()
train_dataset = Data.TensorDataset(train_x, train_y)
train_loader = Data.DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2,)
# 看一下数据
plt.scatter(train_x.numpy(), train_y.numpy(), c='#FF9359', s=50, alpha=0.2, label='train')
plt.legend(loc='upper left')
#搭建网络
class Net(nn.Module) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









