







首先查看蘑菇街这个网站
网站地址 https://www.mogu.com/
比如爬取上衣这一栏
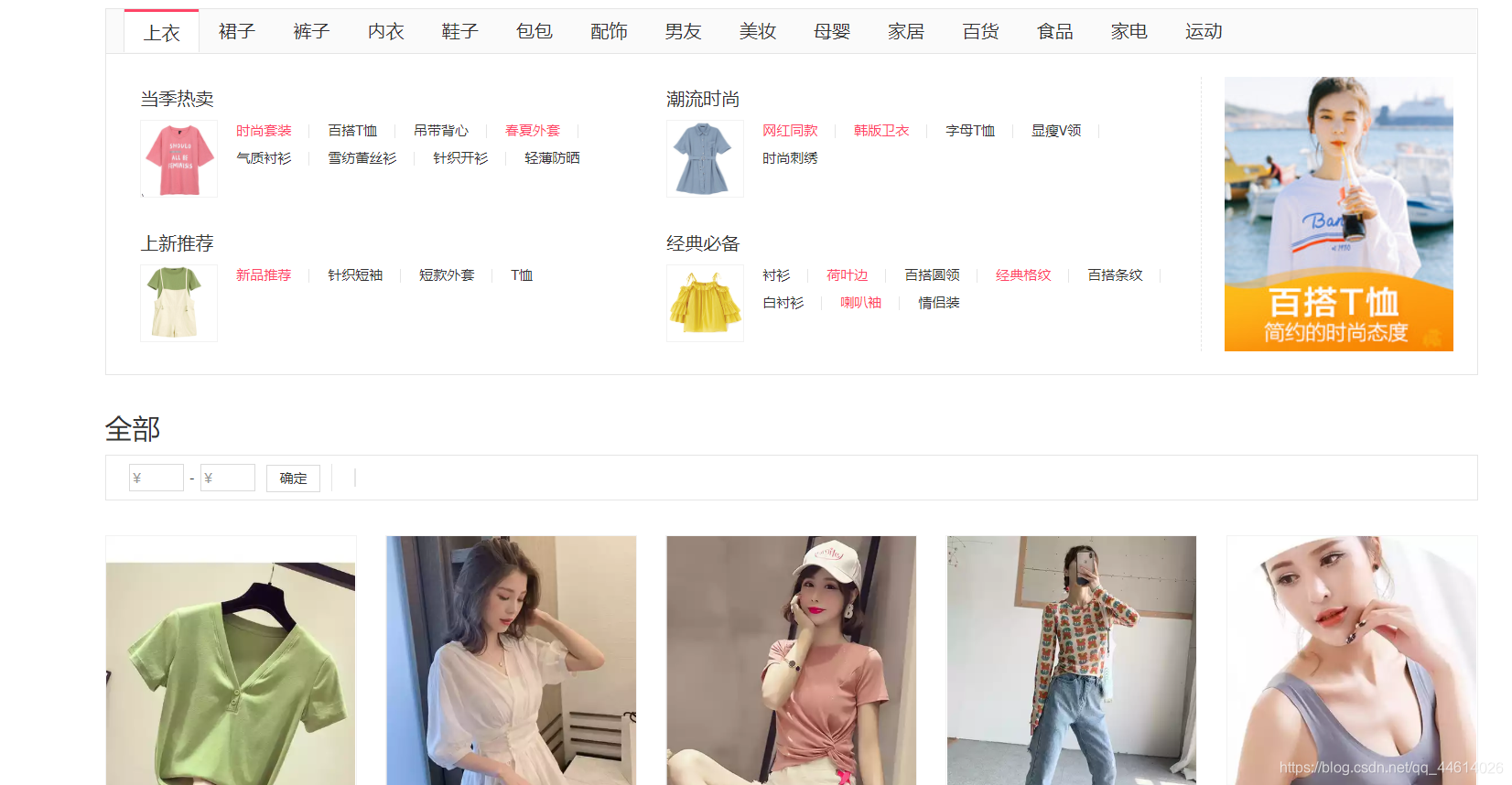
查看网页源代码

很明显,这些商品的数据是动态加载进来的,且在前端不能看到有关的json数据,以前没用框架之前是怎么处理这类事件的?用selenium方法,接下来,用scrapy框架又怎么处理呢?
1、创建爬虫项目
在黑屏终端输入命令
scrapy startproject Mogujie
然后用pycharm打开这个项目
在pycharm的Terminal终端输入命令
scrapy genspider mogu mogu.com
然后在setting .py文件中做一下配置的修改
# 首先是USER_AGENT 替换成浏览器的请求头
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
# robot协议改为不遵循
ROBOTSTXT_OBEY = False
# 时延开启
DOWNLOAD_DELAY = 1
这时setting .py文件就可以先放一边了,回到爬虫文件mogu .py
将起始url改为要爬取的上衣数据的url
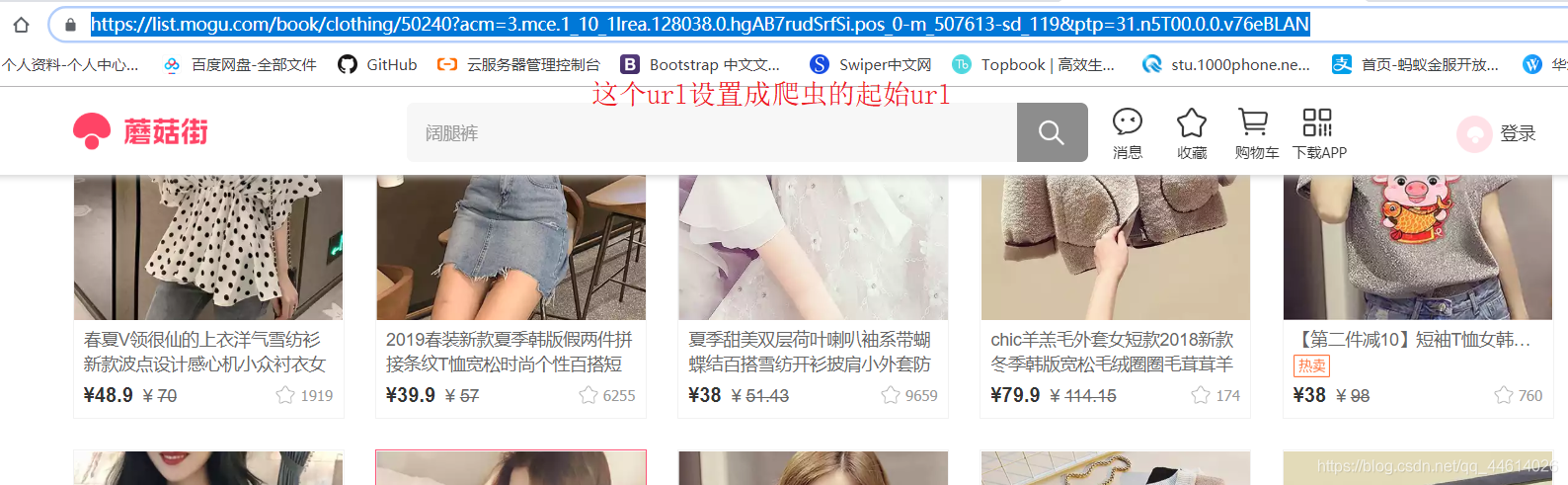
mogu .py
import scrapy
class MoguSpider(scrapy.Spider):
name = 'mogu'
allowed_domains = ['mogu.com']
start_urls = ['https://list.mogu.com/book/clothing/50240?acm=3.mce.1_10_1lrea.128038.0.hgAB7rudSrfSi.pos_0-m_507613-sd_119&ptp=31.n5T00.0.0.v76eBLAN']
def parse(self, response):
print(response.text)
如果像往常一样,我们能不能获取商品数据的信息?

当然不能了,这个页面的数据是通过js动态加载进来的,我们可以运行一下这个爬虫程序,使用命令
scrapy crawl mogu
它打印的都是js的代码
我们爬js代码有个锤子用啊,是吧
那怎么搞,能修改下载器的代码吗?不能,这是官方设定好的
2、中间件
这时候,就涉及到中间件的内容了
我们前面有接触过中间件的一些内容,scrapy框架中有很多官方的中间件
除了官方的中间件,还有一些自定义的中间件,而我们在这些自定义的中间件中,就可以去截获这些请求
查看该文件
这个是我们用来自定义的中间件
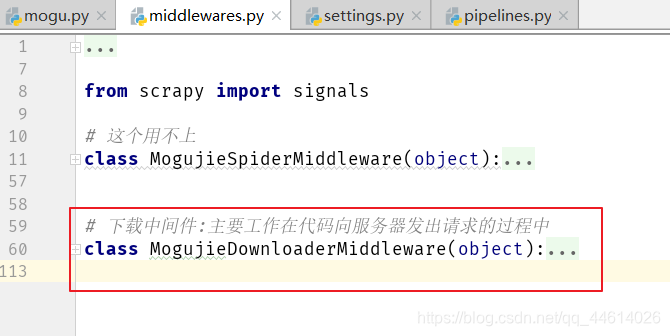
怎么去开启这个中间件呢?在setting .py文件中大概50~60行代码的位置

这个中间件的优先级为543,接下来也可以运行一下爬虫,看一下这个中间件在什么位置
使用命令 scrapy crawl mogu
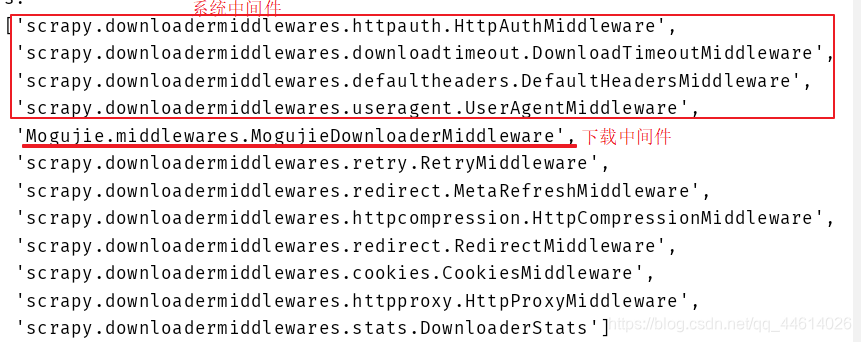
回到自定义中间件,看一下 class MogujieDownloaderMiddleware 这个类中的函数
这个文件中也有官方的一些解释,当然是英文的,如果英语好,直接能看懂这些解释,当然,可以选择百度翻译

解释一下
1#
class MogujieDownloaderMiddleware 这个类本来是普通类,然后把这个类加到了中间件组件中,这个类就变成了中间件了,这个类中的方法不是所有的方法都需要去被定义,如过这个类中的方法有一个没有被重写,那么scrapy框架就当作这个下载器中间件重来没有被更改过

2#
这个是什么意思呢?把爬虫文件mogu .py中的 **print(response.text)**改为 print(response),不打印那么网页的信息了,更方便查看,
使用命令 scrapy crawl mogu运行这个爬虫,打印的这句话在这里
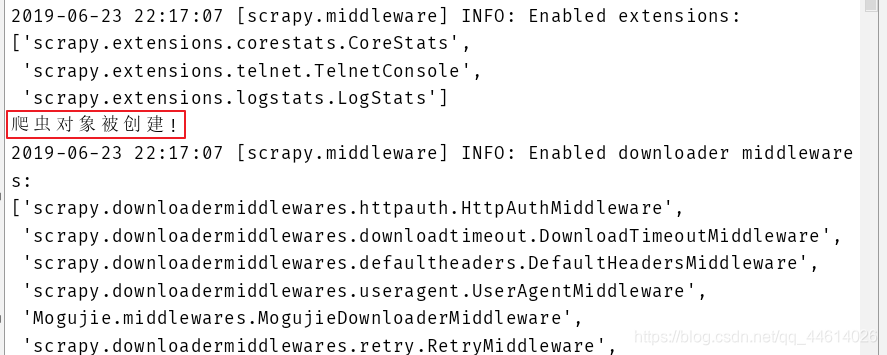
这个是什么意思呢,就是查看下爬虫对象什么时候被创建:在所有的扩展文件加载完成之后,在所有的中间键加载之前
我不是闲的,只是解释一下这个函数而已,解释一下这个类方法什么时候被调用
好了,接下来就不是类方法了,而是对象方法,也就是成员方法



3#
这个函数又是什么意思呢?
一旦有一个请求经过了下载中间件,这个方法就被调用,
return None的时候,直接忽略这个请求,不处理这个请求,像现在这个情况就是直接忽略
or return a Response object 或者返回一个响应对象
or return a Request object 或者返回一个请求对象
r raise IgnoreRequest 或者返回一个异常对象
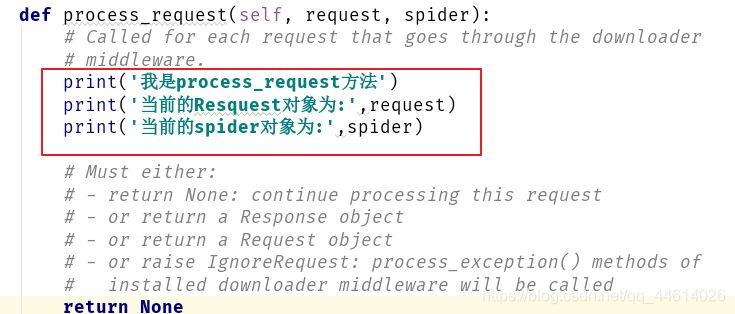
为了方便理解,依旧打印一些内容
4# 这个函数 当downloader返回一个响应体的时候被调用

5# 这个函数,当有异常的时候被调用

6 # 这个方法,当爬虫被开启的时候被调用

ok,全部都解释完了,运行一下爬虫文件,在pycharm的终端使用命令 scrapy crawl mogu运行这个爬虫,看一下打印的内容和顺序
首先是在所有的扩展文件加载完成之后,在所有的中间键加载之前,爬虫对象被创建
然后是爬虫开启,调用了spider_opened方法
发起请求,调用了process_request方法
请求完之后响应,调用了process_response方法
这个爬虫没有出异常,如果出了异常,会调用异常方法


3、截获请求
在 process_request里去截获请求
现在我们要把原来的请求方法截获,然后替换成selenium来请求
- 首先导入模块
from selenium import webdriver
from time import sleep
from scrapy.http import HtmlResponse
- 在process_request函数中进行操作
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
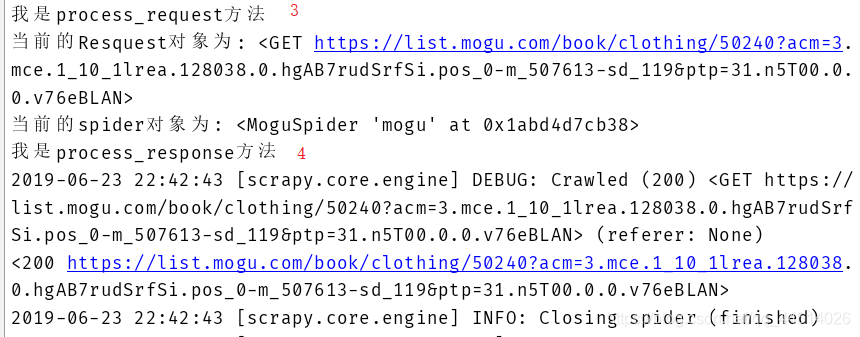
print('我是process_request方法')
print('当前的Resquest对象为:',request)
print('当前的spider对象为:',spider)
# 现在我们要把原来的请求方法截获,然后替换成selenium来请求
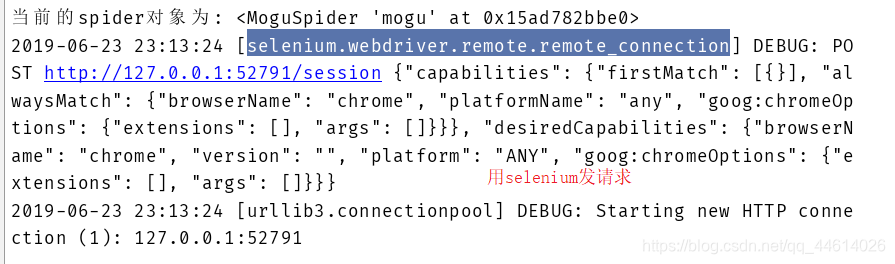
driver = webdriver.Chrome()
# 从request对象中取出当前正在请求的url
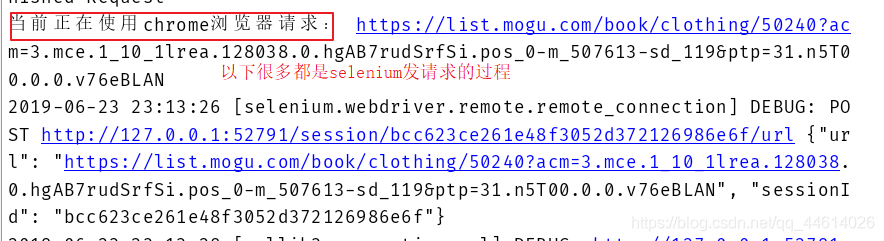
current_url = request.url
print("当前正在使用chrome浏览器请求:", current_url)
# 用driver来发起请求
driver.get(current_url)
sleep(1)
# 提取响应体
body = driver.page_source
# 将响应体封装到一个响应对象中
response = HtmlResponse(url=current_url, body=body, encoding="utf-8", request=request)
# 将响应体返回出去
return response # 这个响应体返回出去以后,会被放入下面process_response函数中
- 在pycharm的终端使用命令 scrapy crawl mogu运行这个爬虫,代码会操作浏览器打开网页,结束后看一下日志中打印的内容
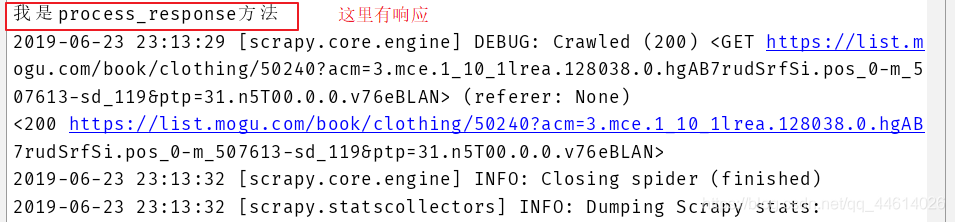
我们现在接收的响应体就是通过selenium返回来的响应体
响应体返回出去以后,会被放入process_response函数,并且返回给下载器
现在可以打印一下响应体,看一下画风是不是就变了
在mugo .py文件中的parse 函数中打印 print(response.text)
看一下效果,是不是数据就出来了


既然能获取响应体,那么就不用每次都打开浏览器了,浏览器界面耗费性能,
进行去头
在 process_request 函数下的driver前加入3行代码
opt = webdriver.ChromeOptions()
opt.add_argument("--headless")
opt.add_argument("--disable-gpu")
说到性能,这里加载了太多中间件,有一些中间件根本就没用上,可以禁掉,节省系统开销

当然,你要是不爬取很多内容,也可以无所谓,但是像要用到分布式爬虫的时候,爬取几乎整个网站所有页面中相关的数据,这个资源消耗量就很大了,禁掉就更好
4、解析响应体
4.1 首先确定需求,要爬取哪些内容,这里要用到items .py文件
items .py
import scrapy
# 根据需求分析,我们可以定义如下的item
class MogujieItem(scrapy.Item):
# 这类继承自scrapy中的Item,Item的本质是一个字典容器
# define the fields for your item here like:
# 标题
title = scrapy.Field()
# 原价
marketPrice = scrapy.Field()
# 原价
sellPrice = scrapy.Field()
# 图片
pic = scrapy.Field()
4.2 解析内容
普及一下知识点
# 基本选择器 :
# id选择器,#id值 根据id值来选择一个标签元素
# class选择, .class值 根据class值选择一批元素
# 标签选择器 标签名 根据标签名来选择一批元素
# 属性选择器 [某属性=某值] 根据属性和值对应来选择
# 派生 子 s1>s2>s3 先选s1再从s1的子标签中选s2在从选择的s2 的子标签中选s3 后代 s1 s2 s3先选s1再从s1的后代中选s2然后从选中s2的后代中选s3
# 组合 s1s2s3 其中s1、s2和s3中如果有标签选择器,则需要写在最前面 先选s1再从选中s2中根据s2来选然后从选中的元素中再根据s3来选
这里用css选择器中的类选择器来解析,这里有三个类,选一个就行, iwf
先获取每一条数据
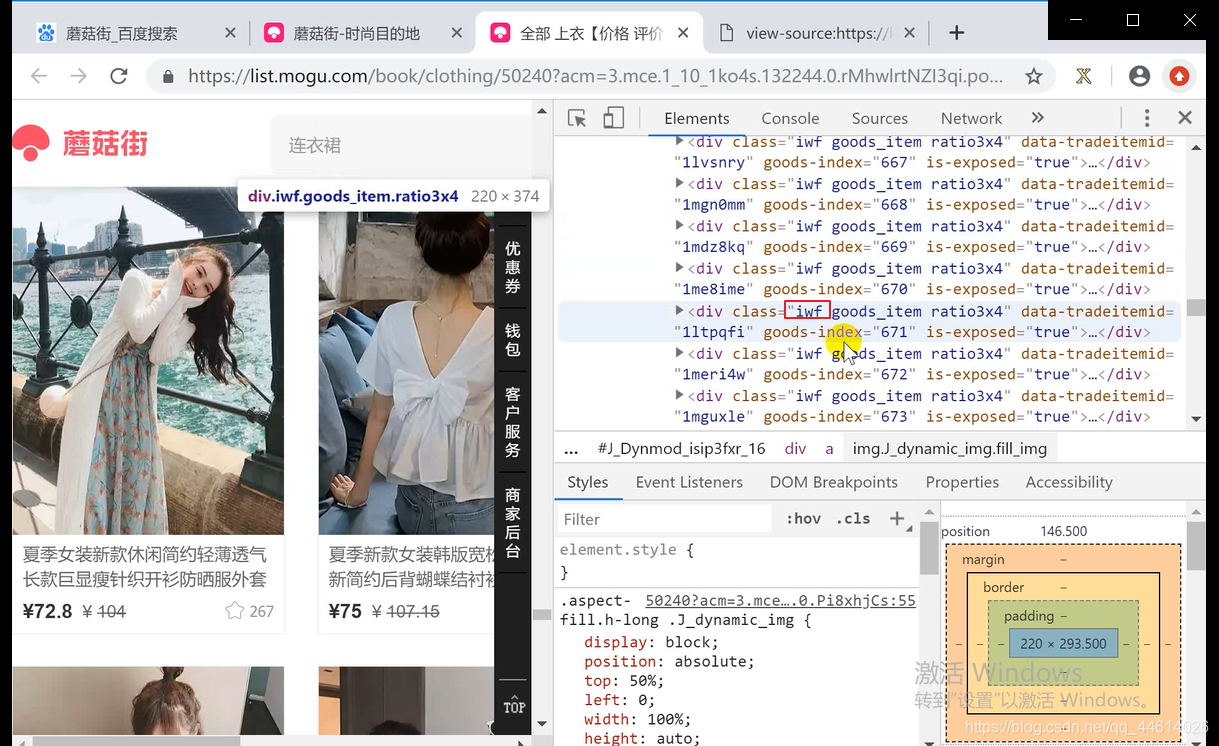
然后从每一条数据中再解析里面要获取的内容
标题
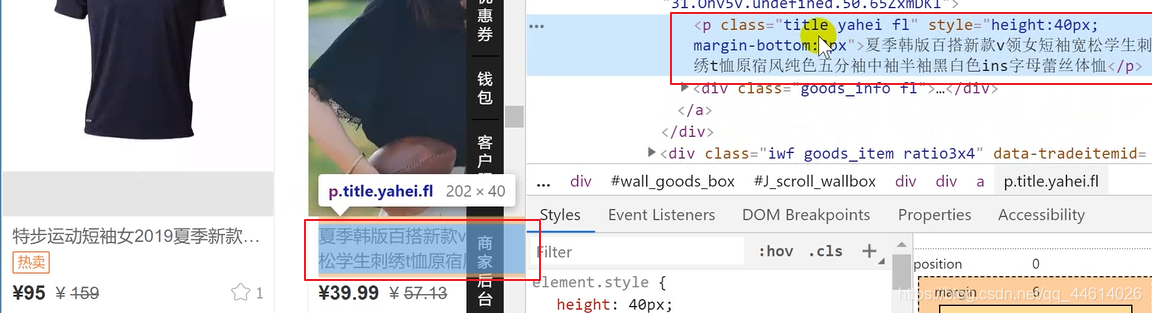
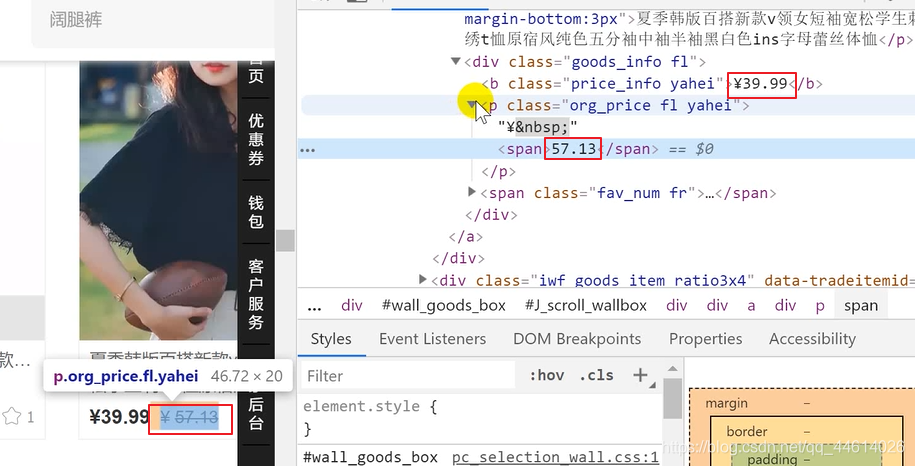
现价和原价
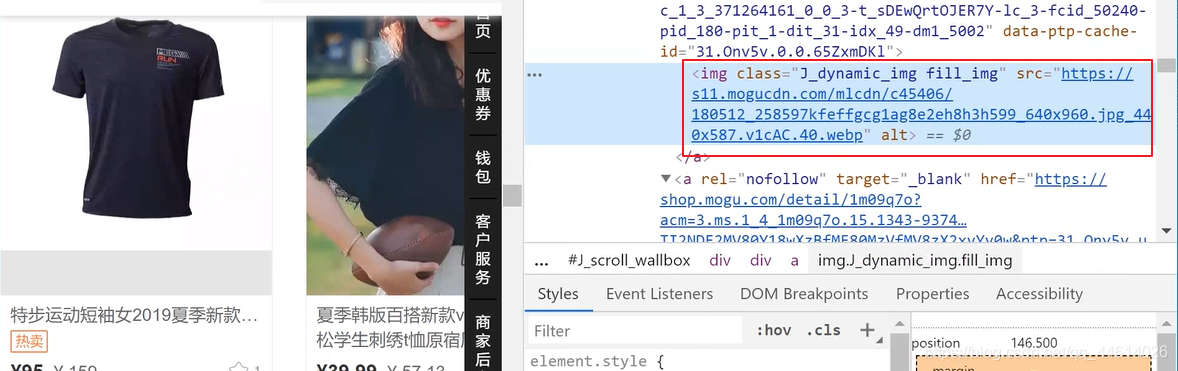
图片
这里我们以前获取内容的时候都是.extract()[0],去获取第一个,但是,如果还是这样的话,爬虫运行会报错,越界,为什么呢?因为有一些没有原价,只有一个价格
这里用 extract_first()方法,如果有则取出首元素,如果没有则取空
mogu .py
# -*- coding: utf-8 -*-
import scrapy
from Mogujie.items import MogujieItem
# 从items文件中导入需求类MogujieItem
class MoguSpider(scrapy.Spider):
name = 'mogu'
allowed_domains = ['mogu.com']
start_urls = ['https://list.mogu.com/book/clothing/50240?acm=3.mce.1_10_1lrea.128038.0.hgAB7rudSrfSi.pos_0-m_507613-sd_119&ptp=31.n5T00.0.0.v76eBLAN']
def parse(self, response):
# print(response.text)
goods_list = response.css(".iwf")
# print(goods_list)
for goods in goods_list:
item = MogujieItem()
item["title"] = goods.css(".title::text").extract_first()
item["marketPrice"] = goods.css(".org_price > span::text").extract_first()
item["sellPrice"] = goods.css(".price_info::text").extract_first()
item["pic"] = goods.css(".J_dynamic_img::attr('src')").extract_first()
# extract_first()方法,如果有则取出首元素,如果没有则取空
yield item
运行一下,获取数据,可以打印一下,看是否还有报错的地方
4.3 存储数据
往管道里存数据
在setting .py文件中,打开管道

然后在pipelines .py文件中操作
比如 写入到redis服务器中
pipelines .py
import redis
class MogujiePipeline(object):
def open_spider(self,spider):
# 创建一个redis链接
self.rds = redis.StrictRedis(host='www.fanjianbo.com',port=6379,db=7)
pass
def process_item(self, item, spider):
self.rds.lpush("mogu",item)
return item
def close_spider(self,spider):
pass
使用命令scrapy crawl mugo运行爬虫,数据就写入了数据库中

















 232
232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









