







 本文围绕Boss直聘网站的分布式爬虫项目展开。先介绍项目创建与配置,包括创建爬虫项目和配置setting.py文件;接着确定需求,如创建爬虫文件、查找url规律、匹配要爬取的信息;最后进行分布式爬虫部署,涉及爬虫文件和setting.py文件修改,以及连接远程redis数据库。
本文围绕Boss直聘网站的分布式爬虫项目展开。先介绍项目创建与配置,包括创建爬虫项目和配置setting.py文件;接着确定需求,如创建爬虫文件、查找url规律、匹配要爬取的信息;最后进行分布式爬虫部署,涉及爬虫文件和setting.py文件修改,以及连接远程redis数据库。
用分布式爬虫爬取boss直聘
1、项目的创建和相关配置
1.1 创建爬虫项目
在黑屏终端输入命令
scrapy startproject Zhipin
使用pycharm打开该项目
前面爬取的量仅供测试,不要爬太多,避免遇到反爬

1.2 配置setting .py文件
# 请求头改为浏览器请求头
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
#robot协议改为不遵守
ROBOTSTXT_OBEY = False
#下载时延开启,设置为3,前面测试的时候建议将时延调高一点,避免被反爬
DOWNLOAD_DELAY = 3
2、确定需求

从一级界面点击连接,查看二级页面
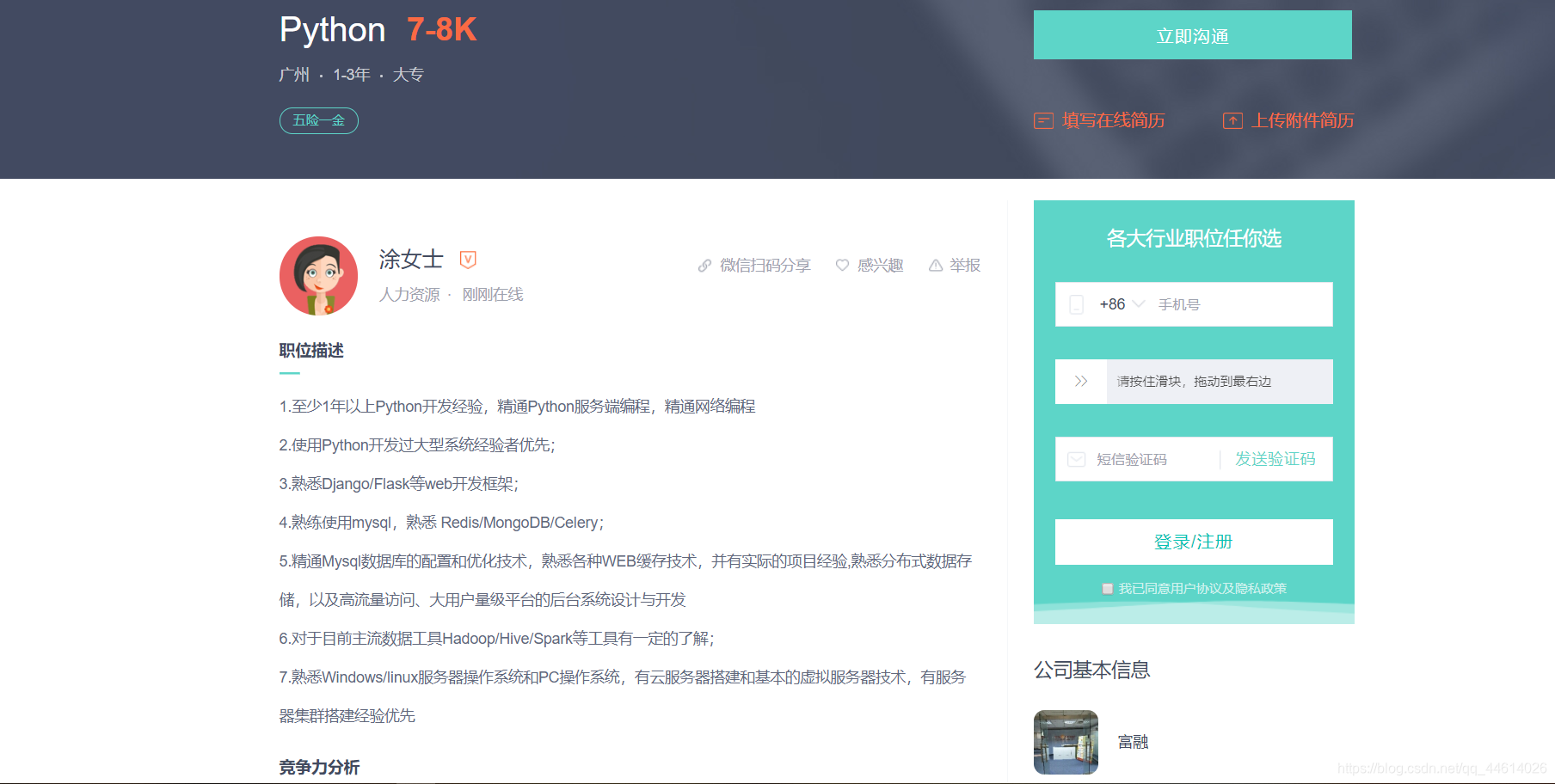
确定爬取的内容,在items .py文件内写入需求
items .py
import scrapy
class ZhipinItem(scrapy.Item):
# 职位
job = scrapy.Field()
# 薪资
salary = scrapy.Field()
# 要求
requirement = scrapy.Field()
# 公司名
companyName = scrapy.Field()
# 公司规模
companySize = scrapy.Field()
# 福利
welfare = scrapy.Field()
# 地址
address = scrapy.Field()
# 公司介绍
companyInfo = scrapy.Field()
# 岗位介绍
jobInfo = scrapy.Field()
2.1 创建爬虫文件
在pycharm的Terminal终端输入命令
scrapy genspider -t crawl zhipin zhipin.com
先使用增量爬虫的方式获取匹配的信息后再切换为分布式爬虫方式,便于爬取,且避免不必要的资源消耗
2.2 查找url规律
这里先以广州的为例,这是广州首页的url

检查导航栏的信息

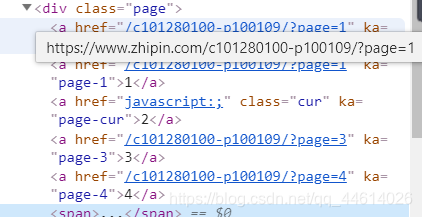
我们分布式爬虫最终的目的是爬取全国的信息,所以,url的确定不能写太死,将start_urls改为广州的首页
用正则匹配页数,先不要匹配太多,匹配1~3页,后面再修改
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from Zhipin.items import ZhipinItem #导入items中的类
class ZhipinSpider(CrawlSpider):
name = 'zhipin'
allowed_domains = ['zhipin.com']
start_urls = ['https://www.zhipin.com/c101280100-p100109/']
rules = (
Rule(LinkExtractor(allow=r'page=[1-3]'), callback='parse_item', follow=True),
)
def parse_item(self, response):
print(response)
使用命令,查看此爬虫文件能否获取信息,以确定url是否匹配正确
scrapy crawl zhipin
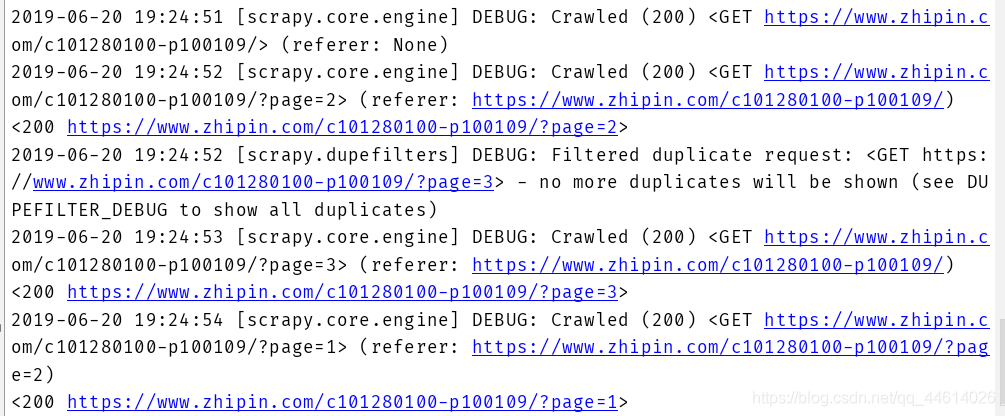
可以正确匹配url
2.3 匹配要爬取的信息
使用xpath解析信息
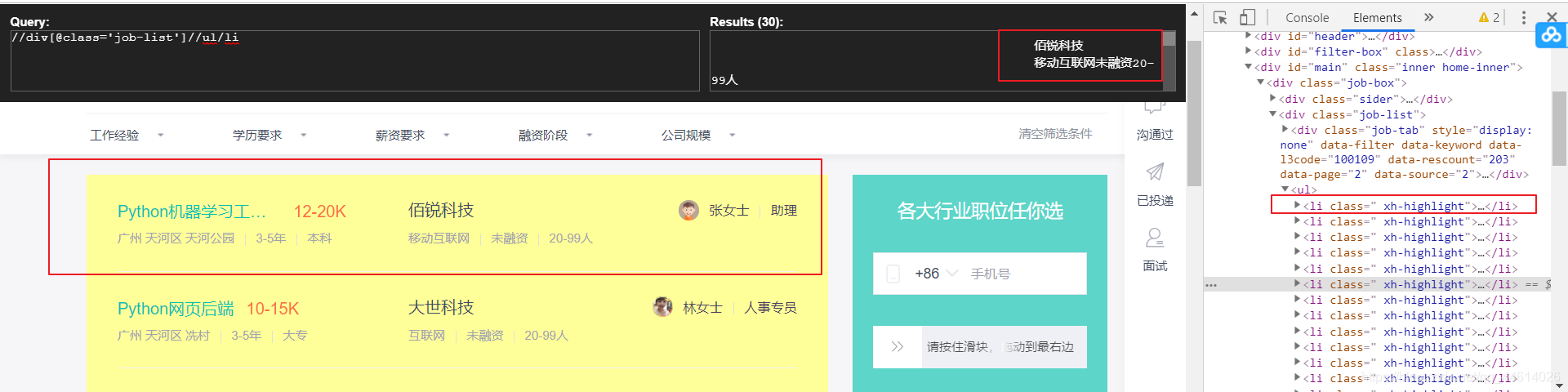
我们要爬取的信息都在二级页面可以获取,但是需要从一级页面获取到二级页面的链接

使用xpath匹配下级页面的url,浏览器给了提示,这个url需要拼接,因为匹配到的是一个相对路径
/job_detail/d953b9883c6369ca1HB839W6GVE~.html,且这里匹配到多个,只需要取到第一个
定义函数,获取二级页面的链接,使用生成器传给回调函数 parse_info
def parse_item(self, response):
# print(response)
# 解析
job_list =response.xpath("//div[@class='job-list']//ul/li")
for job in job_list:
# 获取下级页面的url
next_url = "https://www.zhipin.com" + job.xpath(".//div[@class='info-primary']/h3[@class='name']/a/@href").extract_first()
yield scrapy.Request(url=next_url,callback=self.parse_info)
#回调函数
def parse_info(self, response):
# item = ZhipinItem()
pass
解析要爬取的信息
在二级页面使用xpath匹配要爬取的所有内容
职位
这个匹配了两个,取第一个就行

# 职位
item["job"] = response.xpath("//div[@class='name']/h1/text()").extract_first()
薪资

# 薪资
item["salary"] = response.xpath("//div[@class='name']/span[@class='salary']/text()").extract_first()
福利
这个有点麻烦,将内容放到了多个span标签中,且匹配到两份
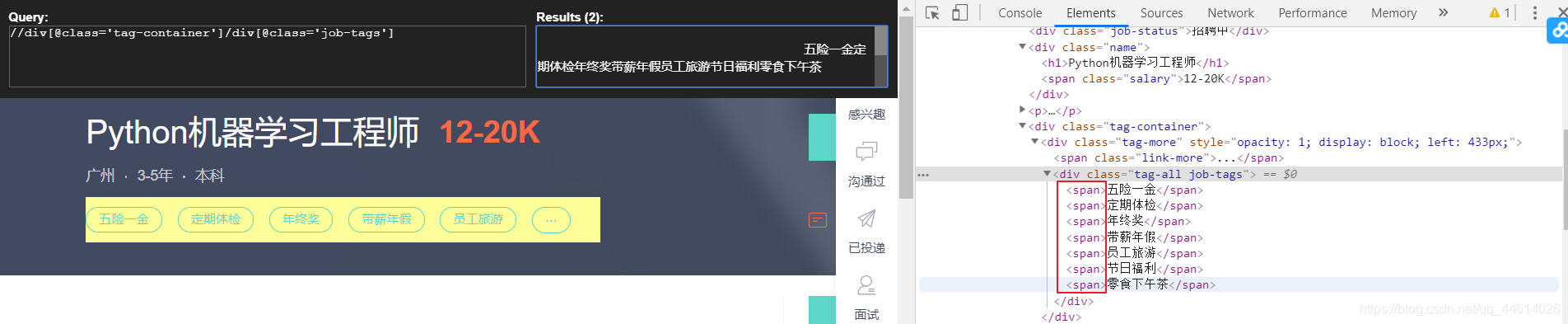
如果加上span标签匹配到一个一个

先取匹配到的第一份,然后再用一次xpath,取到span里的元素.用.join()方法将一个个元素添加进去
# 福利
item["welfare"] = " ".join(response.xpath("//div[@class='tag-container']/div[@class='job-tags']")[0].xpath("./span/text()").extract())
打印一些是否正确
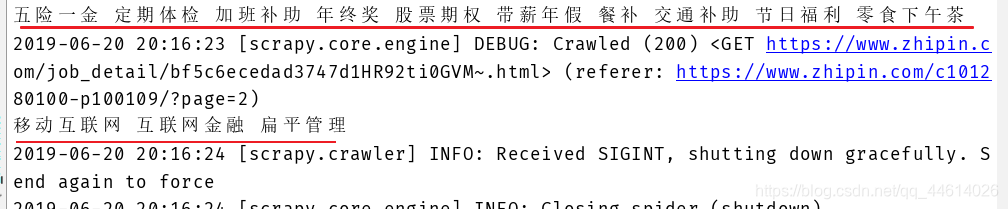
其他不一一介绍了
完成解析后,就可以往分布式爬虫来部署了
3、分布式爬虫的部署
3.1 爬虫文件的修改
页数的匹配,嘴后完全完成分布式爬虫的时候再匹配全部页数,还是先爬3页,防止遇到反爬
zhipin .py
# 导入分布式爬虫类
from scrapy_redis.spiders import RedisCrawlSpider
# 这里继承 RedisCrawlSpider
class ZhipinSpider(RedisCrawlSpider):
name = 'boss'
allowed_domains = ['zhipin.com']
# start_urls = ['https://www.zhipin.com/c101280100-p100109/']
# 由于分布式爬虫是从远程的redis数据库中获取起始url,所以这个属性就没用了,注释掉
# redis_key 属性
redis_key = 'boss::start_urls'
# 分布式爬虫是从远程的redis数据库中的这个key下获取起始url
rules = (
Rule(LinkExtractor(allow=r'page=\d+'), callback='parse_item', follow=True),
# Rule(LinkExtractor(allow=r'page=[1-3]'), callback='parse_item', follow=True),
)
3.2 setting .py文件的修改
包括管道的修改,
setting .py
ITEM_PIPELINES = {
# 分布式系统的数据不是存储在当前系统中,而是存储在分布式的master端,此时,我们的管道就要改成分布式的管道
'scrapy_redis.pipelines.RedisPipeline':300,
# 这个就是分布式系统的管道类,作用是将当前系统管道内的爬虫传到远程的redis服务器中
}
# 我们指定管道以后,,还需要指定管道将返回到哪个redis服务器中
# 远程redis服务程序的ip地址(域名)
REDIS_HOST = '10.3.134.13'
REDIS_PORT = '6379'
# 当前系统的调度器是scrapy的调度器,我们需要将其缓存scrapy_redis的分布式调度器
SCHEDULER = 'scrapy_redis.scheduler.Scheduler'
# 调度过程中是否允许暂停
SCHEDULER_PERSIST =True
# 去重组件 (同一个url只允许被一台主机访问)
DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
此时使用命令scrapy crawl zhipin运行爬虫,爬虫会停下来了,因为没有连接redis数据库,
分布式爬虫是从远程的redis数据库中的这个 redis_key下获取起始url,
3.3 连接远程的redis数据库
在windows黑屏终端使用命令
redis-cli -h 远程redis数据库ip
然后ping一下能不能通
将开始爬取的url导入redis数据库
使用命令
lpush dushu:start_urls https://www.zhipin.com/c101280100-p100109/
然后使用命令scrapy crawl zhipin开启爬虫,如果你匹配的页数使用的是正则d+,那么,恭喜你,爬取那么多页面还不禁止,可能就遇到IP禁止了

这时候IP代理就可以用上了,

而且分布式爬虫,基本上都是爬取的数据几乎涉及整个网站的所有页面,如果这样都没有IP禁止,那这网站配得上你取爬取?


















 1398
1398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









