




文章目录
- 第 1 章 Java8 概述:划时代的版本升级
- 第 2 章 函数式编程基石:Lambda 表达式
- 第 3 章 函数式编程核心:函数式接口
- 第 4 章 集合处理革命:Stream API
第 1 章 Java8 概述:划时代的版本升级
1.1 Java8 的发布背景与历史地位
2014 年 3 月 18 日,Oracle 正式发布 Java SE 8(简称 Java8),这一版本被业界誉为 Java 发展史上的里程碑。在 Java8 诞生前,Java 语言已近 20 年历史,虽凭借跨平台性和稳定性占据主流地位,但在函数式编程、大数据处理效率等方面逐渐落后于 Scala、Groovy 等新兴语言。
为应对多核心处理器普及带来的并发编程挑战,以及大数据时代对数据处理效率的需求,Java8 引入了函数式编程范式、Stream API 等颠覆性特性,不仅弥补了传统 Java 的短板,更奠定了后续 Java 版本进化的基础。截至今日,Java8 仍是企业级开发中使用率最高的版本,其稳定性、兼容性和功能性的平衡堪称典范。
1.2 Java8 核心新特性总览
Java8 的更新覆盖语法、API、虚拟机优化等多个层面,核心特性可归纳为五大类,具体如下表所示:
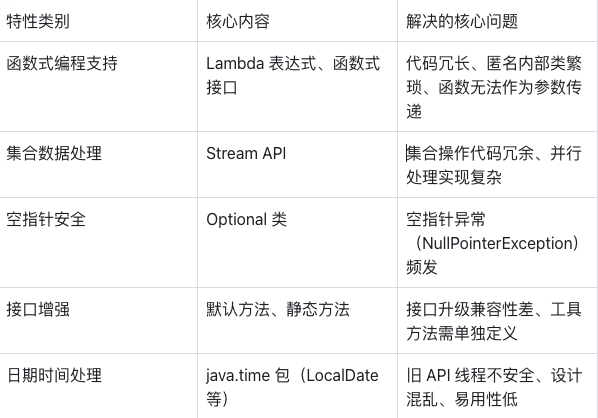
此外,Java8 还包含方法引用、重复注解、类型注解、Nashorn JavaScript 引擎等辅助特性,共同构建了其全面且高效的技术体系。
1.3 本指南的学习路径与阅读建议
1.3.1 学习路径
本指南遵循 “基础认知→核心深入→高级实战→原理剖析” 的递进式路径:
- 基础阶段:掌握 Lambda 表达式、函数式接口的基本语法与使用场景;
- 核心阶段:深入 Stream API、Optional 类、新日期时间 API 的全面用法;
- 高级阶段:探索特性组合应用、性能优化、并发编程实践;
- 原理阶段:理解 Lambda 实现机制、Stream 并行原理等底层逻辑。
1.3.2 阅读建议
- 初学者:从第 2 章开始逐章学习,重点掌握代码案例,配合图解理解概念;
- 有经验开发者:可直接跳转至核心或高级章节,侧重实战案例与原理部分;
- 面试备考者:重点关注 “高级应用” 与 “原理剖析” 章节,结合案例强化记忆。
第 2 章 函数式编程基石:Lambda 表达式
2.1 Lambda 表达式基础:语法与本质
2.1.1 为什么需要 Lambda 表达式?
在 Java8 之前,当需要传递一段代码块(如排序规则、线程任务)时,通常需借助匿名内部类实现。例如,使用Runnable创建线程的传统写法:
// Java8之前的匿名内部类写法
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("传统线程任务执行");
}
}).start();
这种写法存在明显缺陷:代码冗余,Runnable接口的run方法定义占据大量篇幅,核心逻辑(打印语句)反而不够突出;类型信息重复,new Runnable()与@Override public void run()均为冗余的结构代码。
Lambda 表达式的出现彻底解决了这一问题,它允许将函数作为参数传递,直接聚焦核心逻辑,上述代码可简化为:
// Lambda表达式简化写法
new Thread(() -> System.out.println("Lambda线程任务执行")).start();
2.1.2 Lambda 表达式的语法结构
Lambda 表达式的核心语法可概括为 “参数列表→方法体”,具体结构如下:
(参数列表) -> { 方法体 }
其中各部分的细节规则如下:
- 参数列表:
- 若参数个数为 0,需用空括号()表示;
- 若参数个数为 1,可省略括号(如x -> x*2);
- 若参数个数≥2,需用括号包裹,参数类型可省略(类型推断),多个参数用逗号分隔(如(x,y) -> x+y);
- 若显式指定参数类型,则必须用括号包裹(如(int x, String y) -> x + y.length())。
- 箭头符号:固定为->,用于连接参数列表与方法体,不可省略。
- 方法体:
- 若方法体仅包含一条语句,可省略大括号{},且无需指定return(若有返回值),语句结果自动作为返回值(如(x,y) -> x+y);
- 若方法体包含多条语句,必须用大括号包裹,且需显式指定return(若有返回值)(如(x,y) -> {int sum = x+y; return sum;});
- 若方法体为空,需用空大括号{}表示(如() -> {})。
2.1.3 Lambda 表达式的本质:函数式接口的实例
Lambda 表达式并非全新的语法元素,其本质是函数式接口的匿名实例。所谓函数式接口,是指仅包含一个抽象方法的接口(可包含默认方法、静态方法)。
例如,Runnable接口仅包含run()一个抽象方法,属于函数式接口,因此 Lambda 表达式() -> System.out.println(…)本质上就是Runnable接口的一个匿名实例。
Java8 中,可通过@FunctionalInterface注解标识函数式接口,该注解仅起校验作用:若接口不符合函数式接口定义(如包含多个抽象方法),编译器会报错。
2.1.4 图解:Lambda 表达式语法结构与本质
图2-1 Lambda表达式语法结构图解
+-------------------+ +---+ +-------------------+
| 参数列表区域 | | -> | | 方法体区域 |
+-------------------+ +---+ +-------------------+
| () | | | | System.out.println(...) | // 无参,单语句
| (x) | | | | return x*2; | // 单参,显式return
| (x, y) | | | | {int sum=x+y; return sum;} | // 多参,多语句
| (int x, String y) | | | | return x + y.length(); | // 显式类型
+-------------------+ +---+ +-------------------+
图2-2 Lambda表达式本质图解
+---------------------+ +---------------------+
| Lambda表达式 | ≡ | 函数式接口实例 |
| () -> System.out...| | new Runnable() { |
| | | @Override |
| | | public void run() |
| | | { ... } |
| | | } |
+---------------------+ +---------------------+
2.2 Lambda 表达式的类型推断与变量捕获
2.2.1 类型推断机制
Lambda 表达式的参数类型通常可以省略,这得益于 Java8 的类型推断机制。编译器会根据 Lambda 表达式所赋值的目标类型(函数式接口)自动推断参数类型。
例如,Comparator接口的compare方法定义为int compare(T o1, T o2),当使用 Lambda 表达式赋值时:
// 省略参数类型,编译器推断x、y为Integer类型
Comparator<Integer> comparator = (x, y) -> x - y;
编译器通过目标类型Comparator,自动推断出参数x和y的类型为Integer。
需注意,类型推断仅在 Lambda 表达式赋值给明确的目标类型时生效。若直接传递 Lambda 表达式作为方法参数,编译器会根据方法参数的类型进行推断:
// 方法参数为Comparator<Integer>,推断x、y为Integer
List<Integer> list = Arrays.asList(3,1,2);
list.sort((x, y) -> x - y);
2.2.2 变量捕获规则
Lambda 表达式可以访问外部作用域的变量,这种行为称为 “变量捕获”。变量捕获需遵循以下规则:
- 捕获局部变量:
示例:
public void testCapture() {
// effectively final变量(未显式声明final,但未修改)
String message = "Hello Lambda";
// 捕获message变量
Runnable runnable = () -> System.out.println(message);
runnable.run();
// 若此处修改message,编译器会报错
// message = "Modified";
}
-
局部变量必须是final或 “effectively final”(即变量声明后未被修改);
-
原因:Lambda 表达式可能在另一个线程中执行,局部变量所在的栈帧可能已销毁,捕获不可变变量可保证线程安全。
-
捕获成员变量与静态变量:
public class LambdaCaptureTest {
// 成员变量
private String memberVar = "Member";
// 静态变量
private static String staticVar = "Static";
public void test() {
// 捕获成员变量
Runnable r1 = () -> System.out.println(memberVar);
// 捕获静态变量
Runnable r2 = () -> System.out.println(staticVar);
// 修改成员变量和静态变量,编译通过
memberVar = "Modified Member";
staticVar = "Modified Static";
r1.run(); // 输出:Modified Member
r2.run(); // 输出:Modified Static
}
}
- 无需满足final或 “effectively final” 规则;
- 原因:成员变量存储在堆中,静态变量存储在方法区,生命周期与对象或类一致,不存在栈帧销毁问题。
2.3 Lambda 表达式的使用场景
Lambda 表达式的核心优势在于简化函数式接口的实例创建,因此其使用场景与函数式接口紧密相关。常见场景包括:
2.3.1 线程任务(Runnable)
如 2.1.1 节所示,使用 Lambda 表达式简化Runnable接口的实现,聚焦线程核心逻辑。
2.3.2 集合排序(Comparator)
Comparator接口是函数式接口,用于定义排序规则。传统写法需匿名内部类,Lambda 表达式可大幅简化:
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
// 传统匿名内部类写法:按字符串长度排序
names.sort(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.length() - o2.length();
}
});
// Lambda表达式写法
names.sort((o1, o2) -> o1.length() - o2.length());
2.3.3 数据过滤与转换(自定义函数式接口)
自定义函数式接口,结合 Lambda 表达式实现灵活的数据处理:
// 自定义函数式接口:数据处理器
@FunctionalInterface
interface DataProcessor<T, R> {
R process(T data);
}
public class LambdaDemo {
// 工具方法:处理数据
public static <T, R> R handleData(T data, DataProcessor<T, R> processor) {
return processor.process(data);
}
public static void main(String[] args) {
// 处理字符串:转为大写
String upperStr = handleData("lambda", (s) -> s.toUpperCase());
System.out.println(upperStr); // 输出:LAMBDA
// 处理整数:计算平方
Integer square = handleData(5, (n) -> n * n);
System.out.println(square); // 输出:25
}
}
2.4 Lambda 表达式高级特性与原理
2.4.1 闭包特性
Lambda 表达式具有闭包特性,即它会捕获外部作用域的变量,并将其与自身的逻辑绑定在一起,即使外部变量所在的作用域已结束,Lambda 表达式仍可访问该变量。
闭包的实现依赖于 Java 的内部类机制:编译器会将 Lambda 表达式转换为一个匿名内部类,该内部类会持有外部变量的副本(对于局部变量,由于是 effectively final,副本与原变量值一致)。
2.4.2 Lambda 表达式的实现原理:invokedynamic 指令
Java8 引入了invokedynamic指令(动态调用指令)来实现 Lambda 表达式,而非传统的匿名内部类编译方式(生成XXX$1.class文件)。
其实现流程如下:
- 编译器在包含 Lambda 表达式的类中生成一个私有静态方法,方法体为 Lambda 表达式的方法体;
- 编译器在 Lambda 表达式出现的位置插入invokedynamic指令,该指令会引导 JVM 创建一个函数式接口的实例;
- JVM 通过LambdaMetafactory类的metafactory方法,动态生成实现函数式接口的代理类,并将代理类的抽象方法实现委托给步骤 1 生成的静态方法;
- 最终返回代理类的实例,即 Lambda 表达式对应的函数式接口实例。
这种实现方式的优势在于:延迟生成类文件,减少编译后的 class 数量;通过动态链接优化性能,比传统匿名内部类更高效。
2.4.3 图解:Lambda 表达式实现原理流程
图2-3 Lambda表达式实现原理流程图
+----------------------+ 1. 生成静态方法 +----------------------+
| 包含Lambda的源文件 | ------------------> | 私有静态方法(方法体) |
+----------------------+ +----------------------+
|
| 2. 插入invokedynamic指令
v
+----------------------+ 3. 动态生成代理类 +----------------------+
| 编译后的class文件 | ------------------> | 实现函数式接口的代理类 |
+----------------------+ +----------------------+
| |
| 4. 返回代理类实例 | 委托调用静态方法
v v
+----------------------+ +----------------------+
| 函数式接口实例 | <------------------ | 静态方法执行 |
+----------------------+ +----------------------+
2.5 Lambda 表达式实战案例
2.5.1 案例 1:批量处理用户数据
需求:定义用户类User,包含name、age属性,实现对用户列表的批量过滤(筛选年龄≥18 的用户)和转换(提取用户名)。
实现代码:
// 用户类
class User {
private String name;
private int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
// getter方法
public String getName() { return name; }
public int getAge() { return age; }
}
public class LambdaUserDemo {
public static void main(String[] args) {
List<User> users = Arrays.asList(
new User("Alice", 20),
new User("Bob", 17),
new User("Charlie", 25)
);
// 筛选年龄≥18的用户(使用Predicate函数式接口,后续章节详解)
List<User> adultUsers = filterUsers(users, (user) -> user.getAge() >= 18);
// 提取用户名(使用Function函数式接口,后续章节详解)
List<String> adultNames = transformUsers(adultUsers, (user) -> user.getName());
System.out.println(adultNames); // 输出:[Alice, Charlie]
}
// 过滤用户列表
private static List<User> filterUsers(List<User> users, Predicate<User> predicate) {
List<User> result = new ArrayList<>();
for (User user : users) {
if (predicate.test(user)) {
result.add(user);
}
}
return result;
}
// 转换用户列表
private static List<String> transformUsers(List<User> users, Function<User, String> function) {
List<String> result = new ArrayList<>();
for (User user : users) {
result.add(function.apply(user));
}
return result;
}
}
2.5.2 案例 2:自定义计算器
需求:实现一个灵活的计算器,支持加法、减法、乘法、除法四种运算,运算逻辑通过 Lambda 表达式传入。
实现代码:
// 自定义函数式接口:二元运算
@FunctionalInterface
interface BinaryOperator<T> {
T operate(T a, T b);
}
// 计算器类
class Calculator {
// 执行运算
public static <T> T calculate(T a, T b, BinaryOperator<T> operator) {
return operator.operate(a, b);
}
}
public class LambdaCalculatorDemo {
public static void main(String[] args) {
// 加法
Integer sum = Calculator.calculate(10, 5, (x, y) -> x + y);
// 减法
Integer difference = Calculator.calculate(10, 5, (x, y) -> x - y);
// 乘法
Integer product = Calculator.calculate(10, 5, (x, y) -> x * y);
// 除法
Double quotient = Calculator.calculate(10.0, 5.0, (x, y) -> x / y);
System.out.println("加法结果:" + sum); // 输出:15
System.out.println("减法结果:" + difference); // 输出:5
System.out.println("乘法结果:" + product); // 输出:50
System.out.println("除法结果:" + quotient); // 输出:2.0
}
}
第 3 章 函数式编程核心:函数式接口
3.1 函数式接口基础:定义与规范
3.1.1 函数式接口的定义
函数式接口是指仅包含一个抽象方法的接口,它是 Lambda 表达式的目标类型。Java8 中,可通过@FunctionalInterface注解明确标识函数式接口,该注解具有以下特性:
- 可选性:即使不添加该注解,只要接口满足 “仅一个抽象方法” 的条件,就是函数式接口;
- 校验性:若添加该注解后,接口不符合函数式接口定义(如包含多个抽象方法),编译器会抛出错误。
示例:
// 正确的函数式接口
@FunctionalInterface
interface MyFunctionalInterface {
void doSomething();
}
// 错误的函数式接口(包含两个抽象方法,编译报错)
@FunctionalInterface
interface BadFunctionalInterface {
void method1();
void method2();
}
3.1.2 函数式接口的允许成员
函数式接口除了包含一个抽象方法外,还可包含以下成员,这些成员不影响其函数式接口的身份:
- 默认方法(default method):用default关键字修饰,包含方法体,用于接口的升级与扩展;
- 静态方法(static method):用static关键字修饰,包含方法体,用于提供工具方法;
- 从 Object 类继承的方法:如equals()、hashCode()、toString()等,这些方法不会被视为抽象方法。
示例:
@FunctionalInterface
interface FunctionalInterfaceDemo {
// 唯一的抽象方法
void abstractMethod();
// 默认方法
default void defaultMethod() {
System.out.println("这是默认方法");
}
// 静态方法
static void staticMethod() {
System.out.println("这是静态方法");
}
// 从Object继承的方法(不视为抽象方法)
@Override
boolean equals(Object obj);
}
3.1.3 图解:函数式接口的结构组成
图3-1 函数式接口结构组成图解
+-----------------------------------+
| 函数式接口 |
+-----------------------------------+
| 1. 抽象方法(仅1个) |
| 例:void abstractMethod(); |
+-----------------------------------+
| 2. 可选成员 |
| - 默认方法(default) |
| 例:default void m1() {} |
| - 静态方法(static) |
| 例:static void m2() {} |
| - Object类继承方法 |
| 例:@Override boolean equals(...) |
+-----------------------------------+
3.2 Java8 内置函数式接口
为避免开发者重复定义常用的函数式接口,Java8 在java.util.function包中提供了大量内置函数式接口,可分为四大类:消费型、供给型、函数型、断言型。
3.2.1 消费型接口:Consumer
- 定义:public interface Consumer { void accept(T t); }
- 功能:接收一个参数T,无返回值(消费参数);
- 常用场景:对参数进行处理(如打印、修改属性);
- 扩展方法:andThen(Consumer<? super T> after):先执行当前Consumer的accept方法,再执行after的accept方法。
示例:
public class ConsumerDemo {
public static void main(String[] args) {
// 消费字符串:打印
Consumer<String> printConsumer = (s) -> System.out.println("打印:" + s);
printConsumer.accept("Hello Consumer"); // 输出:打印:Hello Consumer
// 消费字符串:转为大写后打印(组合两个Consumer)
Consumer<String> upperConsumer = (s) -> System.out.println("大写打印:" + s.toUpperCase());
printConsumer.andThen(upperConsumer).accept("hello");
// 输出:
// 打印:hello
// 大写打印:HELLO
}
}
3.2.2 供给型接口:Supplier
- 定义:public interface Supplier { T get(); }
- 功能:无参数,返回一个T类型的结果(提供数据);
- 常用场景:生成数据(如随机数、对象实例)。
示例:
public class SupplierDemo {
public static void main(String[] args) {
// 提供随机整数(1-100)
Supplier<Integer> randomIntSupplier = () -> new Random().nextInt(100) + 1;
System.out.println("随机整数:" + randomIntSupplier.get()); // 输出:随机整数:XX(1-100)
// 提供User对象
Supplier<User> userSupplier = () -> new User("Alice", 20);
User user = userSupplier.get();
System.out.println("提供的用户:" + user.getName() + "," + user.getAge());
// 输出:提供的用户:Alice,20
}
}
3.2.3 函数型接口:Function<T, R>
- 定义:public interface Function<T, R> { R apply(T t); }
- 功能:接收一个T类型参数,返回一个R类型结果(数据转换);
- 常用场景:参数转换(如类型转换、属性提取);
- 扩展方法:
- andThen(Function<? super R, ? extends V> after):先执行当前Function的apply,再将结果作为after的参数执行;
- compose(Function<? super V, ? extends T> before):先执行before的apply,再将结果作为当前Function的参数执行。
示例:
public class FunctionDemo {
public static void main(String[] args) {
// 函数1:将字符串转为整数(长度)
Function<String, Integer> strLengthFunction = (s) -> s.length();
Integer length = strLengthFunction.apply("Function");
System.out.println("字符串长度:" + length); // 输出:8
// 函数2:将整数加10
Function<Integer, Integer> add10Function = (n) -> n + 10;
// 组合1:strLengthFunction.andThen(add10Function)
// 先求长度,再加10
Integer result1 = strLengthFunction.andThen(add10Function).apply("Test");
System.out.println("结果1:" + result1); // 输出:14(4+10)
// 组合2:strLengthFunction.compose(add10Function)
// 先加10(但参数为String,此处仅为演示逻辑,实际会报错)
// 正确示例:参数类型需匹配,如Function<Integer, String>先转换,再求长度
Function<Integer, String> intToStringFunction = (n) -> String.valueOf(n);
Integer result2 = intToStringFunction.andThen(strLengthFunction).apply(123);
System.out.println("结果2:" + result2); // 输出:3("123"的长度)
}
}
3.2.4 断言型接口:Predicate
- 定义:public interface Predicate { boolean test(T t); }
- 功能:接收一个T类型参数,返回boolean值(条件判断);
- 常用场景:数据过滤、条件校验;
- 扩展方法:
- and(Predicate<? super T> other):逻辑与(短路与);
- or(Predicate<? super T> other):逻辑或(短路或);
- negate():逻辑非;
- isEqual(Object targetRef):判断参数是否与目标对象相等(静态方法)。
示例:
public class PredicateDemo {
public static void main(String[] args) {
// 断言1:判断整数是否大于5
Predicate<Integer> greaterThan5 = (n) -> n > 5;
System.out.println("6>5? " + greaterThan5.test(6)); // 输出:true
// 断言2:判断整数是否小于10
Predicate<Integer> lessThan10 = (n) -> n < 10;
// 组合1:and(大于5且小于10)
Predicate<Integer> between5And10 = greaterThan5.and(lessThan10);
System.out.println("7在5-10之间? " + between5And10.test(7)); // 输出:true
// 组合2:or(大于5或小于10,始终为true)
Predicate<Integer> greaterThan5OrLessThan10 = greaterThan5.or(lessThan10);
System.out.println("11满足条件? " + greaterThan5OrLessThan10.test(11)); // 输出:true
// 组合3:negate(不大于5,即≤5)
Predicate<Integer> notGreaterThan5 = greaterThan5.negate();
System.out.println("4≤5? " + notGreaterThan5.test(4)); // 输出:true
// 静态方法:判断是否相等
Predicate<String> equalsHello = Predicate.isEqual("Hello");
System.out.println("\"Hello\"是否相等? " + equalsHello.test("Hello")); // 输出:true
}
}
3.2.5 其他常用内置函数式接口
除上述四大基础接口外,java.util.function包还提供了针对特定场景的扩展接口,部分如下图所示:
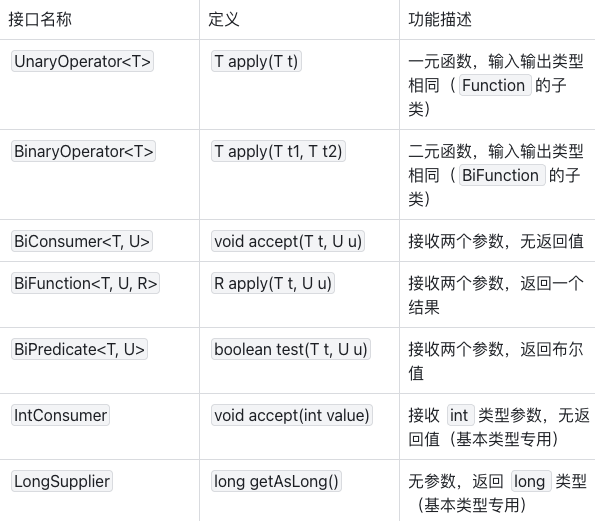
示例(UnaryOperator与BinaryOperator):
public class OperatorDemo {
public static void main(String[] args) {
// UnaryOperator:整数自增1
UnaryOperator<Integer> increment = (n) -> n + 1;
System.out.println("自增后:" + increment.apply(5)); // 输出:6
// BinaryOperator:整数加法
BinaryOperator<Integer> add = (a, b) -> a + b;
System.out.println("加法结果:" + add.apply(3, 4)); // 输出:7
}
}
3.3 自定义函数式接口
虽然 Java8 提供了丰富的内置函数式接口,但在特定业务场景下,自定义函数式接口能更贴合需求。自定义函数式接口需遵循以下步骤:
3.3.1 自定义步骤
- 定义接口,添加@FunctionalInterface注解(可选但推荐);
- 声明唯一的抽象方法,方法名、参数列表、返回值类型根据业务需求定义;
- (可选)添加默认方法或静态方法,提供扩展功能。
3.3.2 实战案例:自定义带异常的函数式接口
Java8 内置函数式接口的抽象方法均未声明异常,若业务逻辑可能抛出受检异常,需自定义带异常的函数式接口。
示例:
// 自定义带受检异常的函数式接口
@FunctionalInterface
interface ThrowingFunction<T, R, E extends Exception> {
R apply(T t) throws E;
}
// 工具类:处理可能抛出异常的操作
class ExceptionHandler {
// 执行带异常的函数,并捕获异常
public static <T, R, E extends Exception> R execute(T t, ThrowingFunction<T, R, E> function) {
try {
return function.apply(t);
} catch (Exception e) {
System.out.println("捕获异常:" + e.getMessage());
return null;
}
}
}
// 业务类:读取文件内容(可能抛出IOException)
public class CustomFunctionalInterfaceDemo {
public static void main(String[] args) {
// 读取文件内容,使用自定义函数式接口
String content = ExceptionHandler.execute("test.txt", (fileName) -> {
// 读取文件的逻辑,可能抛出IOException
BufferedReader reader = new BufferedReader(new FileReader(fileName));
String line = reader.readLine();
reader.close();
return line;
});
System.out.println("文件内容:" + content);
}
}
3.4 函数式接口的高级应用:方法引用与构造器引用
方法引用与构造器引用是 Lambda 表达式的语法糖,用于简化 Lambda 表达式的写法,当 Lambda 表达式的方法体仅调用一个已存在的方法时,可使用方法引用替代。
3.4.1 方法引用的分类与语法
方法引用可分为三类:静态方法引用、实例方法引用、对象方法引用。其语法均为类名/对象名::方法名。
3.4.1.1 静态方法引用
- 语法:类名::静态方法名;
- 适用场景:Lambda 表达式的方法体仅调用某个类的静态方法,且参数列表与静态方法一致。
示例:
public class StaticMethodReferenceDemo {
public static void main(String[] args) {
List<String> strings = Arrays.asList("2", "1", "3");
// 传统Lambda:调用Integer.parseInt静态方法
strings.sort((s1, s2) -> Integer.parseInt(s1) - Integer.parseInt(s2));
// 静态方法引用:简化写法
strings.sort((s1, s2) -> Integer.compare(Integer.parseInt(s1), Integer.parseInt(s2)));
// 进一步简化(若直接使用compare静态方法)
List<Integer> integers = Arrays.asList(2,1,3);
integers.sort(Integer::compare); // 静态方法引用:Integer::compare
System.out.println(integers); // 输出:[1, 2, 3]
}
}
3.4.1.2 实例方法引用
- 语法:对象实例::实例方法名;
- 适用场景:Lambda 表达式的方法体仅调用某个对象的实例方法,且参数列表与实例方法一致。
示例:
public class InstanceMethodReferenceDemo {
public static void main(String[] args) {
// 创建StringBuilder对象
StringBuilder sb = new StringBuilder();
// 传统Lambda:调用sb.append实例方法
Consumer<String> appendConsumer1 = (s) -> sb.append(s);
appendConsumer1.accept("Hello ");
// 实例方法引用:简化写法
Consumer<String> appendConsumer2 = sb::append;
appendConsumer2.accept("World");
System.out.println(sb.toString()); // 输出:Hello World
}
}
3.4.1.3 对象方法引用
- 语法:类名::实例方法名;
- 适用场景:Lambda 表达式的第一个参数是方法的调用者,后续参数是方法的参数,且方法是该类的实例方法。
示例:
public class ObjectMethodReferenceDemo {
public static void main(String[] args) {
List<String> strings = Arrays.asList("apple", "banana", "cherry");
// 传统Lambda:比较两个字符串的长度(s1是compareToIgnoreCase的调用者)
strings.sort((s1, s2) -> s1.compareToIgnoreCase(s2));
// 对象方法引用:简化写法(String::compareToIgnoreCase)
strings.sort(String::compareToIgnoreCase);
System.out.println(strings); // 输出:[apple, banana, cherry]
}
}
3.4.2 构造器引用
- 语法:类名::new;
- 适用场景:Lambda 表达式的方法体仅创建某个类的对象,且参数列表与类的构造器一致。
示例:
public class ConstructorReferenceDemo {
public static void main(String[] args) {
// 传统Lambda:创建User对象
Supplier<User> userSupplier1 = () -> new User("Alice", 20);
User user1 = userSupplier1.get();
// 构造器引用:简化写法(匹配User(String, int)构造器)
BiFunction<String, Integer, User> userSupplier2 = User::new;
User user2 = userSupplier2.apply("Bob", 17);
System.out.println(user1.getName()); // 输出:Alice
System.out.println(user2.getName()); // 输出:Bob
}
}
3.4.3 图解:方法引用与 Lambda 表达式的对应关系
图3-2 方法引用与Lambda表达式对应关系图解
+-------------------------+ 简化 +-------------------------+
| Lambda表达式 | -----> | 方法引用/构造器引用 |
+-------------------------+ +-------------------------+
| (s) -> Integer.parseInt(s) | | Integer::parseInt |
| (x,y) -> x.compareTo(y) | | String::compareTo |
| () -> new User() | | User::new |
| (name,age) -> new User(name,age) | User::new |
| (s) -> System.out.println(s) | System.out::println |
+-------------------------+ +-------------------------+
3.5 函数式接口实战案例:电商订单处理系统
需求:实现一个简化的电商订单处理系统,支持以下功能:
- 过滤订单:筛选金额≥100 元的订单;
- 转换订单:提取订单的用户 ID 和订单金额;
- 处理订单:计算订单的折扣价(满 100 减 10,满 200 减 30);
- 输出订单:打印处理后的订单信息。
实现代码:
// 订单类
class Order {
private String orderId;
private String userId;
private BigDecimal amount;
public Order(String orderId, String userId, BigDecimal amount) {
this.orderId = orderId;
this.userId = userId;
this.amount = amount;
}
// getter方法
public String getOrderId() { return orderId; }
public String getUserId() { return userId; }
public BigDecimal getAmount() { return amount; }
}
// 处理后的订单DTO
class ProcessedOrderDTO {
private String userId;
private BigDecimal originalAmount;
private BigDecimal discountAmount;
public ProcessedOrderDTO(String userId, BigDecimal originalAmount, BigDecimal discountAmount) {
this.userId = userId;
this.originalAmount = originalAmount;
this.discountAmount = discountAmount;
}
// toString方法
@Override
public String toString() {
return "ProcessedOrderDTO{" +
"userId='" + userId + '\'' +
", originalAmount=" + originalAmount +
", discountAmount=" + discountAmount +
'}';
}
}
// 订单处理服务
class OrderService {
// 1. 过滤订单(断言型接口)
public List<Order> filterOrders(List<Order> orders, Predicate<Order> predicate) {
List<Order> filtered = new ArrayList<>();
for (Order order : orders) {
if (predicate.test(order)) {
filtered.add(order);
}
}
return filtered;
}
// 2. 处理订单(函数型接口)
public List<ProcessedOrderDTO> processOrders(List<Order> orders, Function<Order, ProcessedOrderDTO> function) {
List<ProcessedOrderDTO> processed = new ArrayList<>();
for (Order order : orders) {
processed.add(function.apply(order));
}
return processed;
}
// 3. 输出订单(消费型接口)
public void printOrders(List<ProcessedOrderDTO> orders, Consumer<ProcessedOrderDTO> consumer) {
for (ProcessedOrderDTO order : orders) {
consumer.accept(order);
}
}
// 计算折扣价(静态方法,供方法引用使用)
public static BigDecimal calculateDiscount(BigDecimal amount) {
if (amount.compareTo(new BigDecimal("200")) >= 0) {
return amount.subtract(new BigDecimal("30"));
} else if (amount.compareTo(new BigDecimal("100")) >= 0) {
return amount.subtract(new BigDecimal("10"));
} else {
return amount;
}
}
}
public class OrderProcessingDemo {
public static void main(String[] args) {
// 初始化订单数据
List<Order> orders = Arrays.asList(
new Order("O001", "U001", new BigDecimal("80")),
new Order("O002", "U002", new BigDecimal("150")),
new Order("O003", "U003", new BigDecimal("220")),
new Order("O004", "U001", new BigDecimal("95"))
);
OrderService orderService = new OrderService();
// 1. 过滤金额≥100的订单
List<Order> filteredOrders = orderService.filterOrders(orders,
order -> order.getAmount().compareTo(new BigDecimal("100")) >= 0);
// 2. 处理订单:转换为DTO并计算折扣(使用方法引用)
List<ProcessedOrderDTO> processedOrders = orderService.processOrders(filteredOrders,
order -> new ProcessedOrderDTO(
order.getUserId(),
order.getAmount(),
OrderService::calculateDiscount.apply(order.getAmount())
));
// 3. 输出订单
orderService.printOrders(processedOrders, System.out::println);
// 输出结果:
// ProcessedOrderDTO{userId='U002', originalAmount=150, discountAmount=140}
// ProcessedOrderDTO{userId='U003', originalAmount=220, discountAmount=190}
}
}
第 4 章 集合处理革命:Stream API
4.1 Stream API 基础:概念与特性
4.1.1 什么是 Stream?
Stream(流)是 Java8 引入的一套用于处理集合数据的 API,它借鉴了函数式编程的思想,将集合数据视为一个流动的序列,通过一系列链式操作实现数据的过滤、转换、聚合等处理。
Stream 与集合的区别如下:
- 数据存储:集合存储具体的数据,Stream 不存储数据,仅通过数据源(如集合、数组)生成;
- 操作方式:集合是 “拉取式” 访问(主动遍历获取数据),Stream 是 “推送式” 处理(数据自动流过操作链);
- 可变性:集合中的数据可修改,Stream 操作不会修改数据源,而是生成新的流;
- 一次性:Stream 只能遍历一次,遍历结束后即 “消费” 完毕,再次使用需重新生成。
4.1.2 Stream 的核心特性
- 惰性求值:中间操作(如过滤、映射)仅记录操作逻辑,不立即执行;只有当终端操作(如收集、打印)触发时,才会一次性执行所有操作,提升效率;
- 链式操作:多个中间操作可通过链式调用组合,形成操作流水线,代码简洁易读;
- 并行处理:Stream 支持串行与并行两种处理模式,通过parallelStream()即可切换为并行流,利用多线程提升大数据量处理效率;
- 函数式编程:Stream 操作的参数多为函数式接口,支持 Lambda 表达式与方法引用,代码简洁灵活。
4.1.3 图解:Stream 的生命周期
图4-1 Stream生命周期图解
+----------------+ 1. 创建流 +----------------+ 2. 中间操作(多个) +----------------+
| 数据源 | ---------> | 初始Stream | -----------------> | 中间Stream |
| (集合/数组等) | | | | (操作链) |
+----------------+ +----------------+ +----------------+
|
| 3. 终端操作(1个)
v
+----------------+
| 结果/副作用 |
| (集合/值/打印)|
+----------------+
|
| 4. 流关闭(自动)
v
+----------------+
| Stream失效 |
+----------------+
4.2 Stream 的创建方式
Stream 的创建方式多样,常见的有以下几种:
4.2.1 从集合创建
所有Collection接口的实现类(如List、Set)均可通过stream()(串行流)或parallelStream()(并行流)方法创建 Stream:
List<String> list = Arrays.asList("a", "b", "c");
// 串行流
Stream<String> serialStream = list.stream();
// 并行流
Stream<String> parallelStream = list.parallelStream();
4.2.2 从数组创建
通过Arrays.stream(T[] array)方法从数组创建 Stream,支持基本类型数组与对象数组:
// 对象数组
String[] strArray = {"x", "y", "z"};
Stream<String> strStream = Arrays.stream(strArray);
// 基本类型数组(会自动装箱为包装类型)
int[] intArray = {1, 2, 3};
IntStream intStream = Arrays.stream(intArray); // IntStream是针对int的专用流
4.2.3 从值创建
通过Stream.of(T… values)方法直接传入多个值创建 Stream:
Stream<String> valueStream = Stream.of("apple", "banana", "cherry");
Stream<Integer> intValueStream = Stream.of(1, 2, 3, 4);
4.2.4 从空值创建
通过Stream.empty()方法创建空 Stream,避免null引发的空指针异常:
Stream<String> emptyStream = Stream.empty();
4.2.5 无限流创建
通过Stream.generate(Supplier)或Stream.iterate(T seed, UnaryOperator)创建无限流,需配合limit(n)限制流的长度:
// 1. generate:生成无限个随机数(需limit限制)
Stream<Double> randomStream = Stream.generate(Math::random).limit(5);
randomStream.forEach(System.out::println); // 输出5个随机数
// 2. iterate:生成无限个递增的整数(seed为初始值,UnaryOperator为递推规则)
Stream<Integer> iterateStream = Stream.iterate(0, n -> n + 2).limit(5);
iterateStream.forEach(System.out::println); // 输出:0,2,4,6,8
4.3 Stream 的中间操作
中间操作是对 Stream 进行处理后返回一个新 Stream 的操作,支持链式调用。中间操作分为无状态操作和有状态操作:
- 无状态操作:每个元素的处理不依赖于其他元素(如过滤、映射);
- 有状态操作:每个元素的处理依赖于其他元素(如排序、去重、限制长度)。
4.3.1 筛选与切片
4.3.1.1 filter(Predicate<? super T> predicate)
根据断言条件筛选元素,保留满足条件的元素:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
// 筛选偶数
Stream<Integer> evenStream = numbers.stream().filter(n -> n % 2 == 0);
evenStream.forEach(System.out::print); // 输出:246
4.3.1.2 distinct()
去除流中的重复元素(依赖equals()方法判断相等):
List<Integer> duplicates = Arrays.asList(1, 2, 2, 3, 3, 3);
// 去重
Stream<Integer> distinctStream = duplicates.stream().distinct();
distinctStream.forEach(System.out::print); // 输出:123
4.3.1.3 limit(long maxSize)
限制流的长度,保留前maxSize个元素:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// 保留前3个元素
Stream<Integer> limitStream = numbers.stream().limit(3);
limitStream.forEach(System.out::print); // 输出:123
4.3.1.4 skip(long n)
跳过流中的前n个元素,保留剩余元素:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// 跳过前2个元素
Stream<Integer> skipStream = numbers.stream().skip(2);
skipStream.forEach(System.out::print); // 输出:345
4.3.2 映射
4.3.2.1 map(Function<? super T, ? extends R> mapper)
将流中的每个元素通过映射函数转换为另一种类型,生成新的 Stream:
List<String> words = Arrays.asList("apple", "banana", "cherry");
// 映射为字符串长度
Stream<Integer> lengthStream = words.stream().map(String::length);
lengthStream.forEach(System.out::print); // 输出:566
4.3.2.2 flatMap(Function<? super T, ? extends Stream<? extends R>> mapper)
将流中的每个元素转换为一个 Stream,再将所有 Stream 合并为一个 Stream(扁平化):
List<String> sentences = Arrays.asList("Hello World", "Java Stream");
// 传统map:返回Stream<String[]>
Stream<String[]> arrayStream = sentences.stream().map(s -> s.split(" "));
// flatMap:将String[]转换为Stream<String>并合并
Stream<String> wordStream = sentences.stream().flatMap(s -> Arrays.stream(s.split(" ")));
wordStream.forEach(System.out::print); // 输出:HelloWorldJavaStream
4.3.3 排序
4.3.3.1 sorted()
自然排序,要求流中的元素实现Comparable接口:
List<String> names = Arrays.asList("Bob", "Alice", "Charlie");
// 自然排序(按字母顺序)
Stream<String> sortedStream = names.stream().sorted();
sortedStream.forEach(System.out::print); // 输出:AliceBobCharlie
4.3.3.2 sorted(Comparator<? super T> comparator)
定制排序,通过Comparator指定排序规则:
List<Integer> numbers = Arrays.asList(3, 1, 4, 1, 5);
// 降序排序
Stream<Integer> reversedStream = numbers.stream().sorted(Comparator.reverseOrder());
reversedStream.forEach(System.out::print); // 输出:54311
4.3.4 其他中间操作
4.3.4.1 peek(Consumer<? super T> action)
对流中的每个元素执行操作(如打印、日志记录),但不改变元素本身,常用于调试:
List<Integer> numbers = Arrays.asList(1, 2, 3);
// 调试:打印每个元素,再筛选偶数
Stream<Integer> debugStream = numbers.stream()
.peek(n -> System.out.println("原始元素:" + n))
.filter(n -> n % 2 == 0);
debugStream.forEach(n -> System.out.println("偶数元素:" + n));
// 输出:
// 原始元素:1
// 原始元素:2
// 偶数元素:2
// 原始元素:3
4.4 Stream 的终端操作
终端操作是触发 Stream 执行并生成结果或产生副作用的操作,执行后 Stream 即失效。终端操作分为短路操作和非短路操作:
- 短路操作:遇到满足条件的元素即停止遍历(如findFirst、anyMatch);
- 非短路操作:需遍历所有元素才能完成(如forEach、collect)。
4.4.1 遍历与 forEach
4.4.1.1 forEach(Consumer<? super T> action)
遍历流中的每个元素,执行指定操作(副作用操作,无返回值):
List<String> fruits = Arrays.asList("apple", "banana");
fruits.stream().forEach(f -> System.out.println("水果:" + f));
// 输出:
// 水果:apple
// 水果:banana
4.4.1.2 forEachOrdered(Consumer<? super T> action)
遍历流中的每个元素,保证元素的顺序与数据源一致(并行流中仍能保证顺序,但可能影响性能):
List<String> fruits = Arrays.asList("apple", "banana");
// 并行流中使用forEachOrdered保证顺序
fruits.parallelStream().forEachOrdered(f -> System.out.println("水果:" + f));
// 输出顺序仍为apple、banana
4.4.2 查找与匹配
4.4.2.1 findFirst()
返回流中的第一个元素,返回值为Optional(避免空指针,后续章节详解):
List<Integer> numbers = Arrays.asList(1, 2, 3);
Optional<Integer> first = numbers.stream().findFirst();
System.out.println(first.orElse(0)); // 输出:1
4.4.2.2 findAny()
返回流中的任意一个元素(串行流中通常返回第一个,并行流中可能返回任意一个):
List<Integer> numbers = Arrays.asList(1, 2, 3);
Optional<Integer> any = numbers.parallelStream().findAny();
System.out.println(any.orElse(0)); // 输出:可能为1、2或3
4.4.2.3 anyMatch(Predicate<? super T> predicate)
判断流中是否存在至少一个元素满足断言条件,返回boolean:
List<Integer> numbers = Arrays.asList(1, 2, 3);
// 判断是否存在偶数
boolean hasEven = numbers.stream().anyMatch(n -> n % 2 == 0);
System.out.println(hasEven); // 输出:true
4.4.2.4 allMatch(Predicate<? super T> predicate)
判断流中所有元素是否均满足断言条件,返回boolean:
List<Integer> numbers = Arrays.asList(2, 4, 6);
// 判断是否全为偶数
boolean allEven = numbers.stream().allMatch(n -> n % 2 == 0);
System.out.println(allEven); // 输出:true
4.4.2.5 noneMatch(Predicate<? super T> predicate)
判断流中是否所有元素均不满足断言条件,返回boolean:
List<Integer> numbers = Arrays.asList(1, 3, 5);
// 判断是否没有偶数
boolean noEven = numbers.stream().noneMatch(n -> n % 2 == 0);
System.out.println(noEven); // 输出:true
4.4.3 归约与收集
4.4.3.1 归约:reduce ()
归约是将流中的元素通过累加器(BinaryOperator)合并为一个值的操作,有三种重载形式:
- reduce(T identity, BinaryOperator accumulator):
- identity:初始值;
- accumulator:累加器,接收两个参数(前一次归约结果,当前元素),返回新的归约结果。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4);
// 初始值为0,累加器为(a,b)->a+b
Integer sum = numbers.stream().reduce(0, Integer::sum);
System.out.println(sum); // 输出:10
- reduce(BinaryOperator accumulator):
- 无初始值,返回Optional(避免流为空时返回null)。
示例(求最大值):
- 无初始值,返回Optional(避免流为空时返回null)。
List<Integer> numbers = Arrays.asList(3, 1, 4, 2);
Optional<Integer> max = numbers.stream().reduce(Integer::max);
System.out.println(max.orElse(0)); // 输出:4
- reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator combiner):
- 用于并行流的归约,combiner用于合并多个线程的归约结果。
示例(并行流求和):
List<Integer> numbers = Arrays.asList(1, 2, 3, 4);
Integer sum = numbers.parallelStream()
.reduce(0, Integer::sum, Integer::sum);
System.out.println(sum); // 输出:10
4.4.3.2 收集:collect ()
收集是将流中的元素转换为集合、数组或其他自定义类型的操作,核心是Collector接口。Java8 在Collectors工具类中提供了大量预定义的Collector。
- 收集为集合:
- toList():收集为List(具体实现为ArrayList);
- toSet():收集为Set(具体实现为HashSet);
- toCollection(Supplier collectionFactory):收集为指定类型的集合。
示例:
List<String> fruits = Arrays.asList("apple", "banana", "cherry");
// 收集为List
List<String> fruitList = fruits.stream().collect(Collectors.toList());
// 收集为HashSet
Set<String> fruitSet = fruits.stream().collect(Collectors.toSet());
// 收集为LinkedList
LinkedList<String> linkedList = fruits.stream()
.collect(Collectors.toCollection(LinkedList::new));
- 收集为数组:
通过toArray(IntFunction<A[]> generator)收集为指定类型的数组:
List<String> fruits = Arrays.asList("apple", "banana");
// 收集为String数组
String[] fruitArray = fruits.stream().toArray(String[]::new);
- 聚合统计:
- counting():统计元素个数;
- summingInt(ToIntFunction<? super T> mapper):计算整数属性的总和;
- averagingInt(ToIntFunction<? super T> mapper):计算整数属性的平均值;
- maxBy(Comparator<? super T> comparator):求最大值;
- minBy(Comparator<? super T> comparator):求最小值;
- summarizingInt(ToIntFunction<? super T> mapper):获取包含总和、平均值、最大值、最小值等的统计信息。
示例:
List<User> users = Arrays.asList(
new User("Alice", 20),
new User("Bob", 17),
new User("Charlie", 25)
);
// 统计用户个数
Long count = users.stream().collect(Collectors.counting());
// 计算年龄总和
Integer ageSum = users.stream().collect(Collectors.summingInt(User::getAge));
// 计算年龄平均值
Double ageAvg = users.stream().collect(Collectors.averagingInt(User::getAge));
// 求年龄最大的用户
Optional<User> oldestUser = users.stream()
.collect(Collectors.maxBy(Comparator.comparingInt(User::getAge)));
// 获取年龄统计信息
IntSummaryStatistics ageStats = users.stream()
.collect(Collectors.summarizingInt(User::getAge));
System.out.println("用户个数:" + count); // 输出:3
System.out.println("年龄总和:" + ageSum); // 输出:62
System.out.println("年龄平均值:" + ageAvg); // 输出:20.666...
System.out.println("最大年龄:" + oldestUser.get().getAge()); // 输出:25
System.out.println("年龄统计:" + ageStats);
// 输出:IntSummaryStatistics{count=3, sum=62, min=17, average=20.666667, max=25}
- 分组与分区:
- groupingBy(Function<? super T, ? extends K> classifier):根据分类函数分组,返回 - Map<K, List>;
- groupingBy(Function<? super T, ? extends K> classifier, Collector<? super T, A, D> downstream):分组后对每组元素进行收集;
- partitioningBy(Predicate<? super T> predicate):根据断言条件分区,返回Map<Boolean, List>(仅两个键:true和false)。
示例:
List<User> users = Arrays.asList(
new User("Alice", 20),
new User("Bob", 17),
new User("Charlie", 25),
new User("David", 20)
);
// 按年龄分组
Map<Integer, List<User>> groupByAge = users.stream()
.collect(Collectors.groupingBy(User::getAge));
// 按年龄分组,并统计每组人数
Map<Integer, Long> countByAge = users.stream()
.collect(Collectors.groupingBy(User::getAge, Collectors.counting()));
// 按年龄是否≥18分区
Map<Boolean, List<User>> partitionByAdult = users.stream()
.collect(Collectors.partitioningBy(u -> u.getAge() >= 18));
System.out.println("按年龄分组:" + groupByAge);
// 输出:{17=[Bob], 20=[Alice, David], 25=[Charlie]}
System.out.println("按年龄统计人数:" + countByAge);
// 输出:{17=1, 20=2, 25=1}
System.out.println("按成年分区:" + partitionByAdult);
// 输出:{false=[Bob], true=[Alice, Charlie, David]}
- 拼接字符串:
- joining():拼接元素为字符串;
- joining(CharSequence delimiter):使用分隔符拼接;
- joining(CharSequence delimiter, CharSequence prefix, CharSequence suffix):使用分隔符、前缀、后缀拼接。
示例:
List<String> fruits = Arrays.asList("apple", "banana", "cherry");
// 直接拼接
String joined1 = fruits.stream().collect(Collectors.joining());
// 使用逗号分隔
String joined2 = fruits.stream().collect(Collectors.joining(","));
// 逗号分隔,加前缀后缀
String joined3 = fruits.stream().collect(Collectors.joining(", ", "[", "]"));
System.out.println(joined1); // 输出:applebananacherry
System.out.println(joined2); // 输出:apple,banana,cherry
System.out.println(joined3); // 输出:[apple, banana, cherry]
4.5 并行 Stream
4.5.1 并行 Stream 的概念与优势
并行 Stream 是指利用多线程并行处理流中元素的 Stream,它通过Fork/Join框架实现任务拆分与合并,能大幅提升大数据量下的处理效率。
并行 Stream 的优势在于:无需手动创建线程池和管理线程,Java8 自动完成任务拆分、线程分配、结果合并等操作,简化了并行编程的复杂度。
4.5.2 并行 Stream 的创建与使用
创建并行 Stream 的两种方式:
- 集合的parallelStream()方法;
- 串行 Stream 的parallel()方法。
使用并行 Stream 与串行 Stream 的语法基本一致,仅创建方式不同:
List<Integer> numbers = new ArrayList<>();
// 初始化1000万个整数
for (int i = 0; i < 10_000_000; i++) {
numbers.add(i);
}
// 串行流求和(耗时较长)
long serialStart = System.currentTimeMillis();
long serialSum = numbers.stream().mapToLong(Integer::longValue).sum();
long serialEnd = System.currentTimeMillis();
System.out.println("串行求和耗时:" + (serialEnd - serialStart) + "ms");
// 并行流求和(耗时较短)
long parallelStart = System.currentTimeMillis();
long parallelSum = numbers.parallelStream().mapToLong(Integer::longValue).sum();
long parallelEnd = System.currentTimeMillis();
System.out.println("并行求和耗时:</doubaocanvas>



















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











