







答题思路
内存存储:Redis 将数据存储在内存中,而直接访问内存的速度比访问磁盘的速度要快多个数量级;
数据结构:Redis 提供了多种高效的数据结构,如字符串、哈希、列表、集合等,这些专门优化过的数据结构支持高效的读写操作;
非阻塞I/O:Redis 基于 IO 多路复用实现了非阻塞式 IO,这使它能够高效的处理大量的请求;
线程模型:Redis 的大部分读写命令由单线程完成,这使得它可以避免多线程键锁竞争和上下文切换的开销。
回答思路
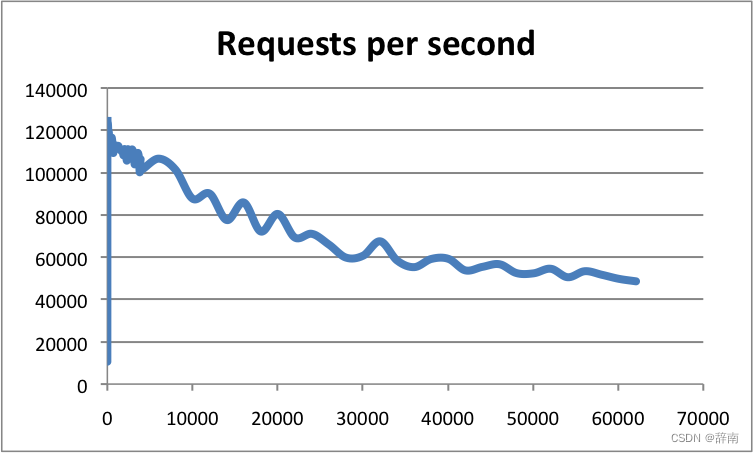
Redis 官方早前发布过一套基准测试,在 Redis 服务连接数小于1万时,并发数量每秒可以达到10-12万左右。连接数在3-6万时,也能支持每秒5-6万的并发。我觉得 Redis 之所以操作这么快,主要体现以下几个方面。
1. 内存存储
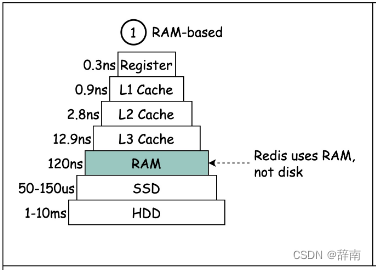
Redis 是基于内存操作的数据库,不论读写操作都是在内存上完成的,直接访问内存的速度远比访问磁盘的速度要快多个数量级。
备注:内存访问一次大概120ns(微秒),SSD 硬盘访问一次50-150us(纳秒),如果按照访问一次150us来算,性能差距在1000倍。这是因为1us等于1000ns。所以,150微秒是150,000纳秒,而120纳秒只是150微秒的一千分之一。
2. 数据结构
Redis 提供了多种高效的数据结构,如字符串、哈希、列表、集合等,这些专门优化过的数据结构支持高效的读写操作。
具体来说,字符串结构,作者底层使用简单动态字符串(SDS)替换传统字符串,内部有一个 len 字段记录了字符串长度:实现了 O(1) 复杂度的 strlen 操作,并保证了二进制安全性。以及 Redis 在内部针对区分了多种 SDS 类型,不同大小的字符串会对应不同的 SDS 实现,有效的节省内存。
另外值得一说的是,Redis 中的 ZSet 会在数据较多的时候使用跳表实现。跳表是一种基于链表实现的数据结构,它可以通过具有多级索引的方式来加速查找元素。相比起正常的列表,它在插入、删除和搜索时都具备 O(logn) 的复杂度,并且相比起树实现起来更加简单。
3. 非阻塞 IO
Redis 基于 IO 多路复用实现了非阻塞式 IO,采用 IO 多路复用技术,并发处理连接。通过 epoll 模型和自己实现的简单的事件框架,将 epoll 中的读、写、关闭、连接都转化成了事件,然后利用 epoll 的多路复用特性,把 IO 操作时间优化到了极致。
4. 线程模型
Redis 把所有主线操作使用单线程模型,将网络 IO 以及指令读写全部交由一个线程来执行。
这样可以带来避免线程创建而导致的性能消耗,多线程上下文切换而引起的 CPU 开销,以及避免了多个线程之间的竞争问题,比如临界区资源的线程安全、锁的申请、释放以及死锁等问题。
问题详解
Redis 官方提供的性能基准测试,横轴是连接 Redis 的连接数,纵轴是读写数量级。可以看到在客户端连接数少于1万时,并发数量每秒可以达到10-12万左右。
1. 内存存储
Redis 是一个内存数据库,它的数据存储在内存中,而计算机访问内存比起磁盘读写要快出数个数量级。因此,相较其他需要从磁盘读取数据的传统数据库而言,Redis 的速度要快得多。
此外,由于数据直接从内存进行读写,而不必过多考虑如何将它们高效地保存到磁盘上(只有将数据以 RDB 的方式持久化时才会面对这个问题),这也使得 Redis 可以直接使用高效的底层数据结构。
2. 数据结构
Redis 的高速很大程度上依赖于它丰富而高效的数据结构,而它们在底层实现上,都针对不同的使用场景进行了精心的设计和优化。
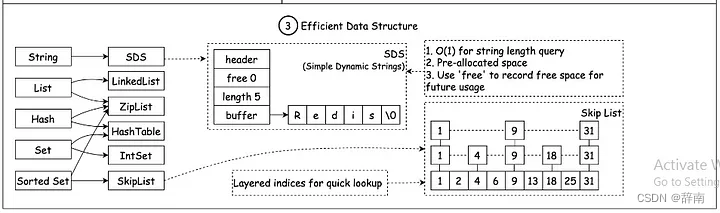
下面我们简单了解一下几种常问的底层数据结构。
2.1 简单动态字符串(SDS)
字符串是 Redis 中最常用的数据结构,不过作者并没有使用 C 标准款的实现,而是自己实现了一套简单动态字符串(SDS)作为替代。
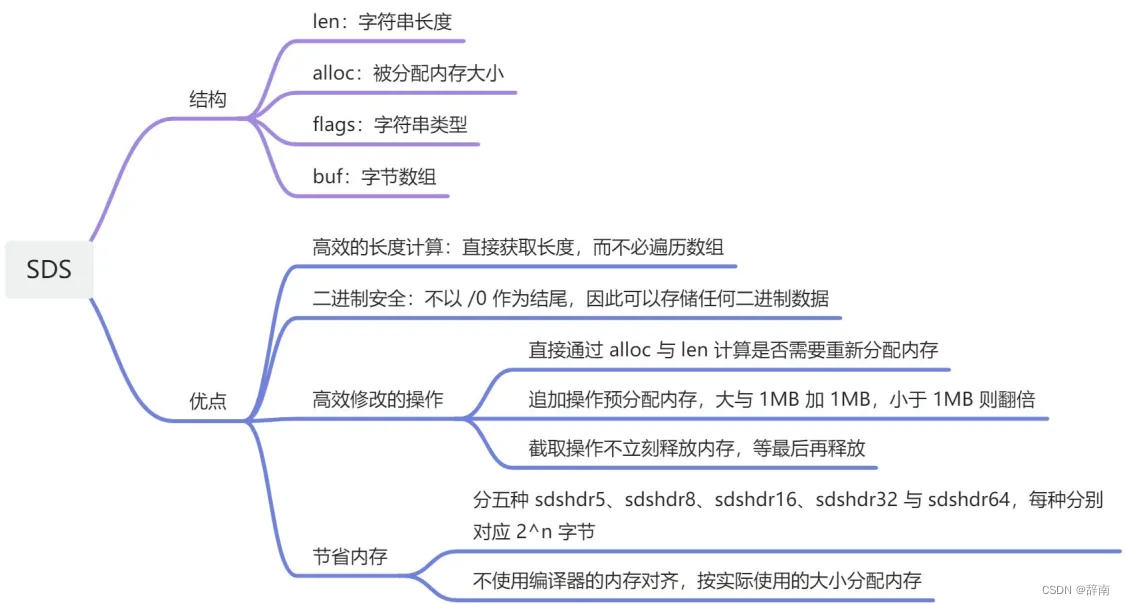
SDS 的特点是在保留 C 字符串特性的同时:
通过 len 记录了字符串长度:实现了 O(1) 复杂度的 strlen 操作,并保证了二进制安全性;
通过 alloc 记录了分配的内存大小 :这使得修改字符串的时候可以通过计算,仅当空间不足时再扩展;
通过 flags 表示不同的类型:Redis 在内部针对区分了多种 SDS 类型,不同大小的字符串会对应不同的 SDS 实现,有效的节省内存。
具体参见文章: 简单动态字符串 —— Redis 设计与实现
2.2 压缩列表(ZipList)
Redis 的 List、Hash、ZSet 个结构在数据量较小的情况下,会使用压缩列表保存数据。
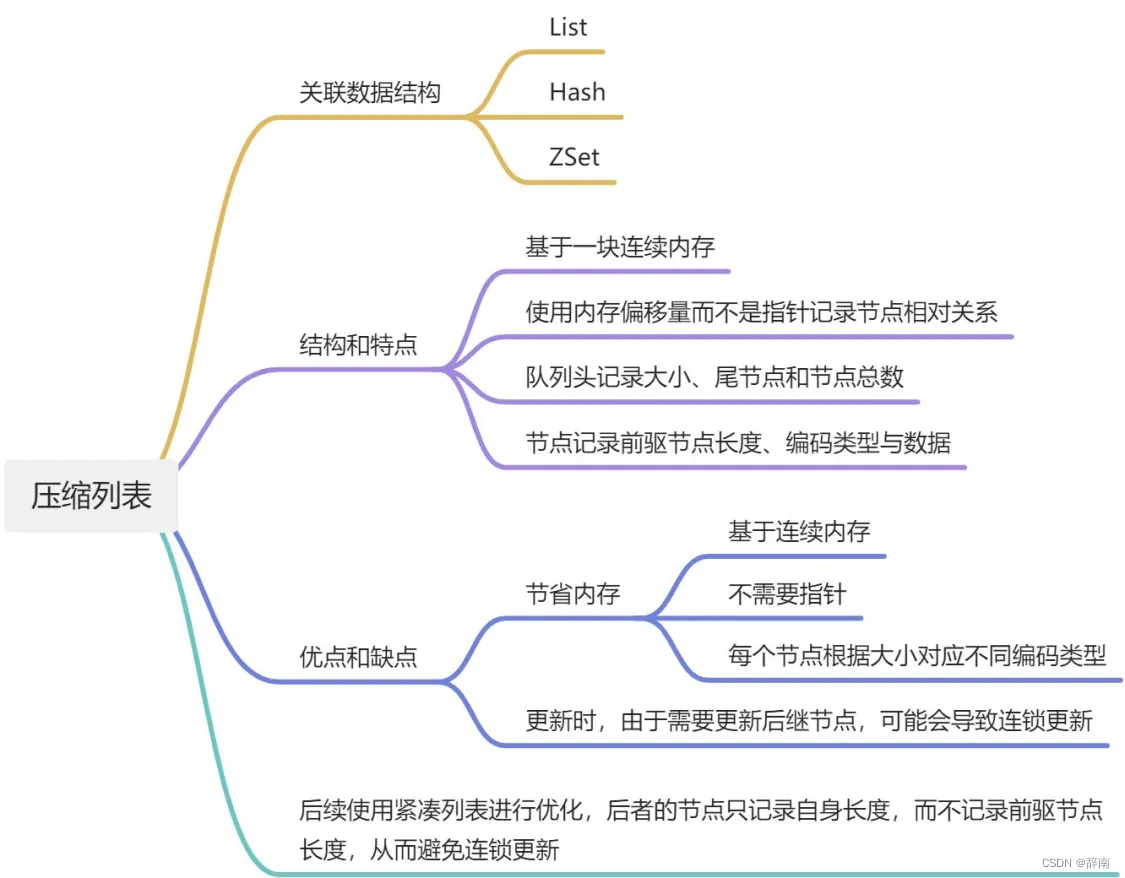
压缩列表是一种结构类似数组的顺序结构。相比起传统的链表,它节点连续的内存块组成,每个节点都不需要指向前驱接点、后继节点以及存储数据的指针,而是直接记录到前一个元素和后一个元素的内存偏移量作为替代。
它会在列表头记录占用整个列表的占用的字节数(zlbytes )、最后一个元素的偏移量(zltail)、元素数量(zllen),从而支持快速访问列表的开头和末尾,以及快速确定列表的大小。
这种设计和布局使得 Redis 的压缩链表非常高效,能够在占用较少内存的情况下存储大量数据。
在 3.2 以后的版本版本,Redis 又逐渐引入了 quicklist 和 listpack 来替代跳表和压缩列表。
2.3 字典/哈希表(Hash)
Redis 的哈希表与 Java 中相似,也是基于 key 得到的哈希值计算桶下标,再采用拉链法解决冲突,并在装载因子超过预定值时自动扩容。
它的特殊之处在于,当扩容的时候,它会基于扩容后的大小创建一张新的哈希表,然后在访问旧表的时候,每次将访问到的桶中的链表转移到新表中。
在这个过程中,每次操作的时候都会先访问旧表,然后再访问新表,直到旧表的数据组件的全部转移到新表以后,旧表会被回收,只留下新表。
这个过程被称为渐进式哈希,它巧妙地避免的在一次操作中大批量的进行数据迁移,而是将其分摊到多次请求中。
2.4 跳表
每个元素在不同层次的链表中出现,从最底层链表开始,每个级别的链表包含前一个级别链表的子集。当我们进行查找时,可以从最高层的 k 索引开始遍历,当我们确认一个元素大于 k 层的某个节点时,就进入 k-1 层,从这个节点开始继续向前遍历……直到找到为止。
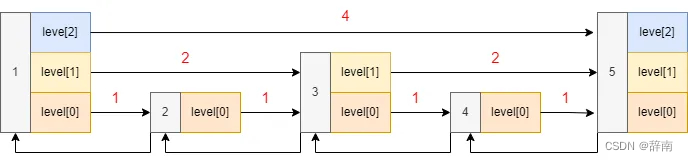
相比起正常的列表,它在插入、删除和搜索时都具备 O(logn) 的复杂度,并且相比起树实现起来更加简单。
3. 非阻塞式 IO
Redis 会根据不同的操作系统的函数实现 IO 多路复用,包括 Solaris 中的 evport、Linux 中的 epoll、Mac OS/FreeBSD 中的 kQueue 等…… 借助这些函数,即使只有单个线程, Redis 依然可以在事件循环中高效的响应并处理事件。
具体可以参见文章:一文搞懂 Redis 高性能之 IO 多路复用
4. 线程模型
Redis 的线程模型在不同版本有所不同:
2.0 版本:Redis 使用单个线程在事件循环中处理网络请求与执行操作指令,然后其他的后台线程负责释放 RDB/AOF 过程生成的临时文件资源与刷盘;
4.0 版本:Redis 添加了一个线程,用于异步执行UNLINK(异步删除指定键)、FLUSHALL ASYNC(清空所有 DB)和FLUSHDB ASYNC(清空指定 DB)这些比较重的删除指令;
6.0 版本:Redis 允许通过修改 io-threads 和 io-threads-do-reads 修改 IO 线程数。
总的来说:
读写指令的单线程执行避免了锁竞争和上下文切换带来的额外性能开销;
异步完成文件操作与大 key 删除避免了主线程的长时间阻塞;
多线程 IO 读写提高了网络 IO 性能。
另外一提,读写指令要保持单线程,这个设计的理由是因为 CPU 对内存的操作已经足够高效,因此性能瓶颈不大可能来自于 CPU ,而主要来自于内存和网络 IO,因此执行命令的线程有一个足矣。


















 4890
4890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









