






socket
在服务器与客户端之间相互通信时,会打开一个进程与端口号。这两个合并起来就是socket address
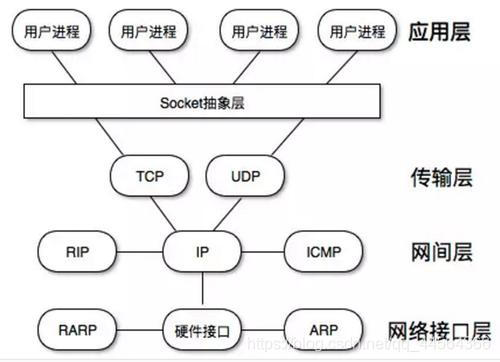
socket工作在应用层和传输层之间的抽象层。socket其实是一个编程接口(API)。相当于它为应用层和传输层定义来以何种方式来连接两层之间。
socket通信原理
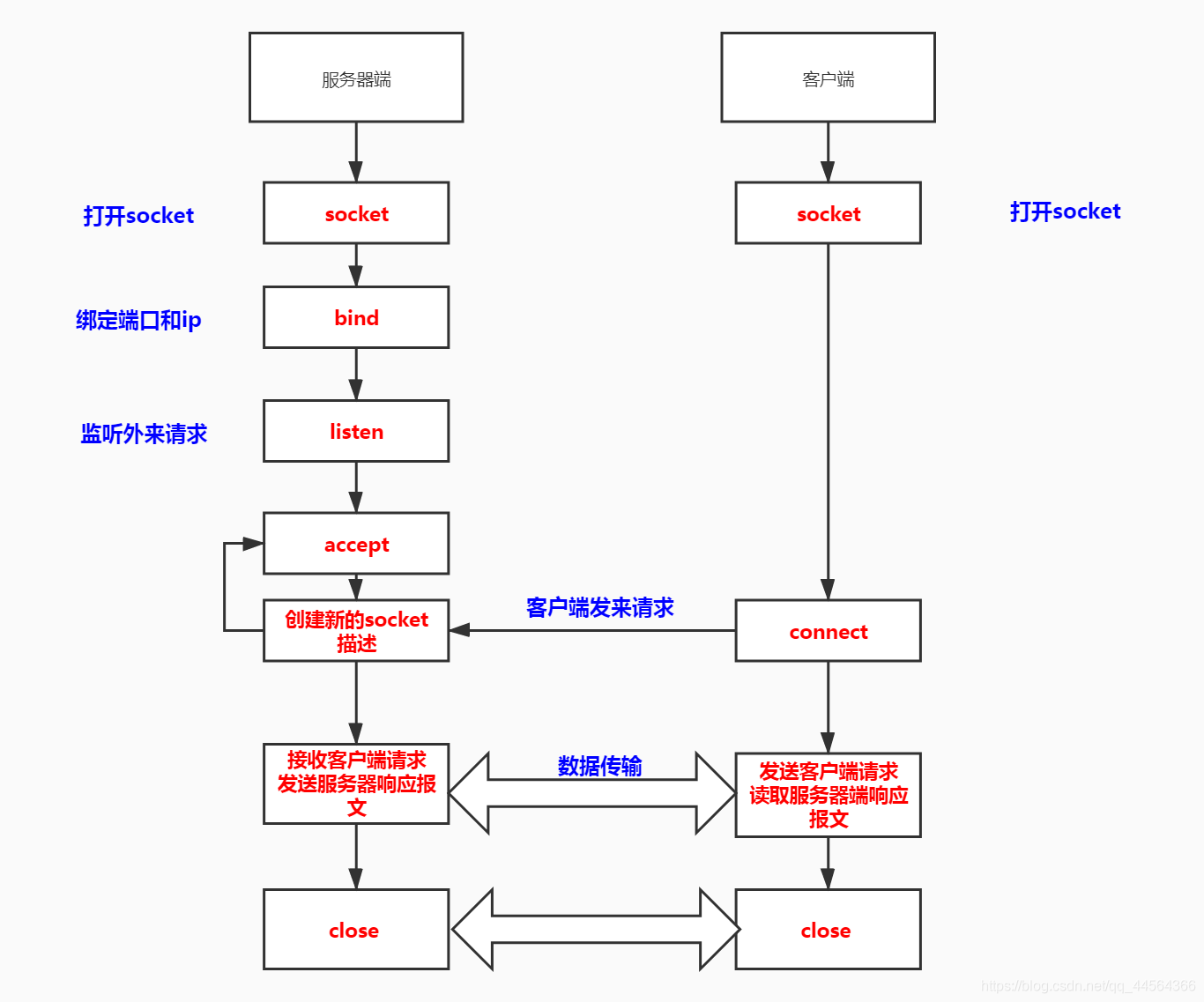
以httpd为例:
服务器端:
- 1、创建新的套接字(socket)
- 2、将套接字绑定到80端口上。(bind)
- 3、允许套接字进行监听(listen)
- 4、等待服务器的连接
客户端: - 1、创建的新的套接字
- 2、连接到服务器端的ip:port
服务器端:
- 1、监听到有客户端连接进来
- 2、接受客户端的请求
客户端:
- 1、连接成功。
- 2、发送请求报文
- 3、等待服务器的响应报文
服务器端:
- 1、读取客户端的请求报文
- 2、处理完毕,发送响应报文
客户端:
- 1、接收服务器端响应报文
- 2、结束请求,关闭连接
服务器端:
- 1、关闭与客户端的连接
http
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准。设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。
HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
HTTP协议工作于客户端-服务端架构上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。
HTTP有三个特性:
- HTTP是无连接:每次连接只能处理一个请求,在处理完请求之后就会关闭连接。
- HTTP是媒体独立的:只要客户端和服务器直到如何处理传输的数据内容,任何类型的数据都可以通过http来传送。客户端和服务器端都有指定的MMIE-type类型
- HTTP是无状态的:无状态是指对事务处理没有记忆,任何时候用户的访问,它都会像第一次接待一样。
html
HTML称为超文本标记语言,是一种标识性的语言。它包括一系列标签.通过这些标签可以将网络上的文档格式统一,使分散的Internet资源连接为一个逻辑整体。HTML文本是由HTML命令组成的描述性文本,HTML命令可以说明文字,图形、动画、声音、表格、链接等。
MIME
最早期的http协议版本只是用来传输文本邮件使用。无法发送附件一类的东西。直到MIME(多用途互联网邮件扩展类型)的出现。才让http协议焕发了新生。它能支持图片、声音等等一系列的东西。现在的浏览器可以自动识别你的MIME类型。
http协议介绍(转载)
HTTP/0.9是第一个版本的HTTP协议,已过时。它的组成极其简单,只允许客户端发送GET这一种请求,且不支持请求头。由于没有协议头,造成了HTTP/0.9协议只支持一种内容,即纯文本。不过网页仍然支持用HTML语言格式化,同时无法插入图片。
HTTP/0.9具有典型的无状态性,每个事务独立进行处理,事务结束时就释放这个连接。由此可见,HTTP协议的无状态特点在其第一个版本0.9中已经成型。一次HTTP/0.9的传输首先要建立一个由客户端到Web服务器的TCP连接,由客户端发起一个请求,然后由Web服务器返回页面内容,然后连接会关闭。如果请求的页面不存在,也不会返回任何错误码。
HTTP/1.0
HTTP协议的第二个版本,第一个在通讯中指定版本号的HTTP协议版本,至今仍被广泛采用。相对于HTTP/0.9增加了如下主要特性:
请求与响应支持头域
响应对象以一个响应状态行开始
响应对象不只限于超文本
开始支持客户端通过POST方法向Web服务器提交数据,支持GET、HEAD、POST方法
支持长连接(但默认还是使用短连接),缓存机制,以及身份认证
HTTP/1.1
HTTP协议的第三个版本是HTTP/1.1,是目前使用最广泛的协议版本。HTTP/1.1是目前主流的HTTP协议版本,相对于HTTP/1.0新增了以下内容:
(1) 默认为长连接HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启Connection:keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。
(2) 提供了范围请求功能(宽带优化)HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。这是支持文件断点续传的基础。
(3) 提供了虚拟主机的功能(HOST域)在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
(4) 多了一些缓存处理字段HTTP/1.1在1.0的基础上加入了一些cache的新特性,引入了实体标签,一般被称为e-tags,新增更为强大的Cache-Control头。
(5) 错误通知的管理在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
HTTP/2.0
HTTP协议的第四个版本是HTTP/2.0,相对于HTTP/1.1新增了以下内容:
二进制分帧HTTP 2.0 的所有帧都采用二进制编码
帧:客户端与服务器通过交换帧来通信,帧是基于这个新协议通信的最小单位。
消息:是指逻辑上的 HTTP 消息,比如请求、响应等,由一或多个帧组成。
流:流是连接中的一个虚拟信道,可以承载双向的消息;每个流都有一个唯一的整数标识符(1、2 … N);
多路复用多路复用允许同时通过单一的HTTP/2.0 连接发起多重的请求-响应消息。有了新的分帧机制后,HTTP/2.0不再依赖多个TCP 连接去处理更多并发的请求。每个数据流都拆分成很多互不依赖的帧,而这些帧可以交错(乱序发送),还可以分优先级。最后再在另一端根据每个帧首部的流标识符把它们重新组合起来。HTTP 2.0 连接都是持久化的,而且客户端与服务器之间也只需要一个连接(每个域名一个连接)即可。
头部压缩HTTP/1.1 的首部带有大量信息,而且每次都要重复发送。HTTP/2.0 要求通讯双方各自缓存一份首部字段表,从而避免了重复传输。
请求优先级浏览器可以在发现资源时立即分派请求,指定每个流的优先级,让服务器决定最优的响应次序。这样请求就不必排队了,既节省了时间,也最大限度地利用了每个连接。
服务端推送服务端推送能把客户端所需要的资源伴随着index.html一起发送到客户端,省去了客户端重复请求的步骤。正因为没有发起请求,建立连接等操作,所以静态资源通过服务端推送的方式可以极大地提升速度。
web资源
一个网页由多个资源组成,打开网页会有许多资源出来。每个资源都要单独请求。所以我们经常看到的网页不是单个资源,而是多个资源的集合
- 静态资源:服务器对文件不用做任何处理。直接将原文件呈现给用户。
- 动态资源:服务器需要将文件先进行处理,然后在呈现给用户。
URI
统一资源标识符(Uniform Resource Identifier,URI)是一个用于标识某一互联网资源名称的字符串。 分为URL和URN。
统一资源名(URN,Uniform Resource Name)是带有名字的因特网资源。如同人的名字,只提供给你的身份。不给出查找它的地址
统一资源定位系统(uniform resource locator;URL)是因特网的万维网服务程序上用于指定信息位置的表示方法。它定义来你去哪里找一个资源和方法
URL的组成
<scheme>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<frag>
- scheme:访问服务器的时候使用哪种协议
- user:访问某些资源时需要的用户名
- password:访问某些资源时需要的密码
- Host:主机,资源所在的主机或ip地址
- port:端口,资源所在服务器上正在监听的端口号
- path:路径,服务器所在的本地名称,例如:www.a.com/index.html
- params:参数,指定输入的参数,参数为名/值对,多个参数,用;分隔
- query:查询,传递参数给程序,用?分隔,多个查询用&分隔。例如?ie=utf-8&f=8&rsv_bp=1
- frag:片段,一小片或一部分资源的名字,此组件在客户端使用,用#分隔
网站访问量
IP:一天内来自相同客户机ip地址只算一次访问,记录远程客户机ip地址的计算机访问网站的次数,是衡量流量的重要指标
PV:即页面浏览量或点击量。用户每次刷新的时候就会计算一次。PV高不一定代表来访者多;PV与来访者的数量成正比,但是PV并不直接决定页面的真实来访者数量。比如一个网站就你一个人进来,通过不断的刷新页面,也可以制造出非常高的PV。
UV:即Unique Visitor,独立访客是指某站点被多少台电脑访问过,以用户电脑的Cookie作为统计依据。
独立访客很接近但并不完全就是真实独立的人。其次,独立访客这个指标会受浏览器设置的影响,如那些将浏览器设置成禁用cookie或是禁用第三方cookie的情况。大多数的网站分析工具都使用第一方cookie来尽量降低cookie被禁用的情况(被禁用百分比大概在2%至5%之间)。第三方cookie被禁用的比率相对而言就要高很多(大概在10%至30%之间)。
记录独立访客数的时间标准一般可为一天,一个月。按照国际惯例,独立访客数记录标准一般为“一天”,即一天内如果某访客从同一个IP地址来访问某网站n次的话,访问次数计作n, 独立访客数则计作1。一般不计算年UV数。
cookie
http是无状态的协议,无法来追踪用户的状态。例如在购物车放入东西,除非你删掉或者结账,否则它将会在你的购物车里一直存在。而这个就是cookie的功劳。 用户在访问网址的时候,用户发连着它的cookie信息一并发到服务器端。服务器端根据cookie信息来得知用户的信息状态。从而得到之前的信息。
[root@localhost httpd]# cat /var/www/html/test.php
<?php
setcookie("test", "Hello", time()+3600);
?>

sendfile机制
传统的网路传输过程:
- 1、调用read()函数,发生一个上下文切换,从用户空间切换到kernel空间。然后把文件数据从硬盘中拷贝到kernel缓冲区中。
- 2、数据从kernel拷贝到user buffer中,然后系统调用read()返回,这是又产生一个上下文切换,从kernel空间中切换到用户空间
- 3、系统调用 write() 产生一个上下文切换:从 user mode 切换到 kernel mode,然后把步骤2读到 user buffer 的数据拷贝到 kernel buffer(数据第2次拷贝到kernel buffer),不过这次是个不同的 kernel buffer,这个 buffer和 socket相关联
- 4、系统调用write()返回,产生一个上下文切换,从kernel空间切换到用户空间。然后将数据从kernelbuffer拷贝到协议栈
有了sendfile机制:
- 1、系统调用 sendfile() 通过 DMA 把硬盘数据拷贝到 kernelbuffer,然后数据被 kernel 直接拷贝到另外一个与 socket 相关的 kernel buffer。这里没有 user mode 和 kernel mode 之间的切换,在 kernel 中直接完成了从一个 buffer 到另一个 buffer的拷贝。
- 2、DMA 把数据从 kernel buffer 直接拷贝给协议栈,没有切换,也不需要数据从 user mode 拷贝到 kernel mode,因为数据就在kernel 里


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









