




 本文探讨了算法的定义、特征,包括确定性、可行性、输入、输出和有穷性,并介绍了基础算法如递归、冒泡排序、选择排序、归并排序、插入排序、快速排序和基数排序,强调了算法设计中的正确性、可读性和健壮性,以及时间效率和存储量的重要性。
本文探讨了算法的定义、特征,包括确定性、可行性、输入、输出和有穷性,并介绍了基础算法如递归、冒泡排序、选择排序、归并排序、插入排序、快速排序和基数排序,强调了算法设计中的正确性、可读性和健壮性,以及时间效率和存储量的重要性。
数据结构与算法(2)算法的认知
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
开发工具与关键技术: 数据结构与算法(2)算法的认知
作者: 梁柏源
撰写时间:2020/5/18
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
前面我们普遍认识了数据结构,那么我们先来了解一下算法。什么是算法?算法大家都很熟悉,不论在学习上还是生活中。算法都在我们身边围绕着。算法是指解题方案一个准确且完整的描述,更是一系列解决问题的清晰指令。对于我们程序猿来说代码中的算法就不是这么简单的了。在代码运算中算法要有一定的输入范围,在有限时间内获得所需求的输出。如果你编辑的算法有缺陷,或者是不适合某个问题,那么理所当然也不会解决这个问题。而且不同的算法用来完成同样任务所需的时间、空间或者是效率等等都会有所差距。在我们这行算法的优劣性在于它的空间复杂度和时间复杂度来衡量。
既然是数据结构与算法,数据结构有它的特征,那算法也不例外。
算法是独立存在的一种解决问题的方法和思想。
算法的概念:
算法是计算机处理信息的本质,因为计算机程序本质上是一个算法来告诉计算机确切的步骤来执行一个指定的任务。
一般地,当算法在处理信息时,会从输入设备或数据的存储地址读取数据,把结果写入输出设备或某个存储地址供以后再调用。
首先介绍一下算法的五个重要的特征:确定性、可行性、输入、输出、有穷性/有限性。
来,我们看一下官方说法:算法描述的是一种有穷的动作序列,即算法是由有限非步骤组成的,在算法中每一步动作的表现形式并没有规定的格式,可以是抽象的,也可以是具体的,但是这些动作的含义应当是明确的(即没有二义性),同时还应该是能行的(即在有限的时间内可以做到的。)下面我来为大家详细介绍:
- 有穷性:一个算法包含的操作步骤应该是有限的。
- 确定性:算法中每一条指令必须有确切的含义,不能有二义性,对于相同的输入必须能得到相同的执行结果。
- 可行性:算法中指定的操作,都可以通过已经验证过可以实现的基本运算执行有限次后实现。可以当做算法每一步都必须是可行的,也就是说,每一步都通过执行有限次数完成。
- 输入:算法具有零个或多个输入。
- 输出:算法至少具有一个或多个输出。
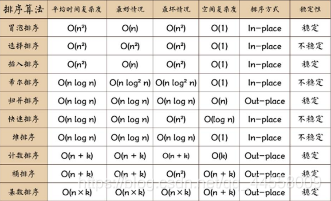
接下来介绍一下算法的基础算法:
递归(recursion):将大的计算不断分割成小的计算,递归函数不断调用自身。而递归的两个特点分别是:调用自身和结束条件
排序:
- 冒泡排序(bubble sort):顾名思义,冒泡排序就是让数组元素像水中的气泡一样逐渐上浮,进而达到排序的目的
- 选择排序(selection sort):选择排序的算法复杂度与冒泡排序类似,其比较的时间复杂度仍然为O(N2),但减少了交换次数,交换的复杂度为O(N),相对冒泡排序提升很多。算法的核心思想是每次选出一个最小的,然后与本轮循环中的第一个进行比较,如果需要则进行交换。
- 归并排序(merge sort):将原数组不断分解为前后两部分, 直到每个数组内只有一个元素, 然后不断进行排序合并, 最后合并为一个有序数组
- 插入排序(insertion sort):将一个未排序数组分为无序区和有序区,不断将无序区的第一个元素按照大小插入到有序区,最后直到无序区的元素都插入到有序区,排序完成。
- 快速排序(quick sort):使用了分治思想. 以数组中的一个数key为基准, 把小于key的数放到左边, 把大于key的数放到右边, 然后使用同样的方法作用于key两边的区间。快速排序中最坏情况是分区后一个分区是空, 另一个分区全满, 这种一般是key的选择不当导致的, 比如一个有序数组选择了第一个或最后一个元素为key, 可以采用以下方法优化:三位数取中取头部, 尾部, 中间的元素, 将3个数的中间值作为分界线。随机法:从数组中随机取一个数作为分界线
- 基数排序(radix sort):将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
归并排序和快速排序的区别在于:
归并排序:
排序顺序是从下到上, 先解决子问题, 再合并分区. 缺点: 不是原地排序, 合并需要占用额外空间
快速排序:
排序顺序是从上到下, 先分区, 再解决子问题. 可以通过合理的选择key来避免时间复杂度为最坏的O(n**2)
算法设计的要求是一定的正确性,然而正确性却不是算法的特征,如何算是正确呢?
- 语法没有错误
- 要有能够满足需求的合理输出结果
可读性:算法设计的另一个目的便是为了便于理解、阅读和交流
健壮性:当输入数据不合法时,算法也能做出相关处理,而不是产生异常或莫名其妙的结果
时间效率高和存储量低。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









