






此篇博客仅记录在使用sqoop时遇到的各种问题。持续更新,有问题评论区一起探讨,写得有不足之处见谅。
Oracle_to_hive
1. main ERROR Could not register mbeans java.security.AccessControlException: access denied ("javax.management.MBeanTrustPermission" "register")
日期:20241031
原因分析:Sqoop 在执行导入时依赖了 Hive,Hive 启用了 Log4j 的 JMX 功能,在没有足够权限的情况下尝试注册 MBeans 时被阻止,从而引发该错误
解决方法:
修改jdk的文件找到:jdk安装目录/jre/lib/security/java.policy
具体配置如下:在文件中添加如下内容
permission javax.management.MBeanTrustPermission "register";

2. org.apache.atlas.AtlasException: Failed to load application yaml
当集群配置了atlas时,可能会遇到此问题
日期:20241031
原因分析:无法在classpath提及的目录中找到application-atlas.yml文件

将找到的配置文件,拷贝到classpath起止一个地址中:

3. cannot recognize input near ','
'gcrq_month' ',' in column type
24/10/31 17:05:16 ERROR ql.Driver: FAILED: ParseException line 1:895 cannot recognize input near ',' 'gcrq_month' ',' in column type
org.apache.hadoop.hive.ql.parse.ParseException: line 1:895 cannot recognize input near ',' 'gcrq_month' ',' in column type。sqoop只支持单分区问题
日期:20241031
原因分析:导入数据到hive表时,使用了多个分区字段

源码级别解析可以看:Sqoop 数据导入多分区Hive解决方法_sqoop import 多个分区-优快云博客
换种简单的解决方式,通过HCatalog解决,先查看是否安装HCatalog

然后参数使用HCatalog:
--split-by MINUTE \
--hive-import \
--hive-table ods_pre_dat_dcsj_time \
--target-dir /user/sqoop/hive/oracle_to_hive/ods_pre_dat_dcsj_time \
--delete-target-dir \
-- --hive-drop-import-delims \
--hcatalog-database dw \
--hcatalog-table ods_pre_dat_dcsj_time \
--hcatalog-storage-stanza 'stored as orc' \
--hcatalog-partition-keys "gcrq_year,gcrq_month,gcrq_day" \
--hcatalog-partition-values "${gcrq_year},${gcrq_month},${gcrq_day}" \
--num-mappers 3
4. FAILED: HiveAuthzPluginException Error getting permissions for
hdfs://udh/user/sqoop/hive/oracle_to_hive/ods_pre_dat_dcsj_time : Unauthorized connection for super-user: hive from IP /xxx.xxx.xxx.xxx
日期:20241101
原因分析:猜测权限问题,其中xxx.xxx.xxx.xxx为我提交sqoop命令所在的服务器,“hive ”为我在服务器上以hive用户身份提交sqoop。我在sqoop命令中指定存放数据的临时目录为:--target-dir /user/sqoop/hive/oracle_to_hive/ods_pre_dat_dcsj_time,查看一下此目录的权限

发现存放临时数据目录下是有数据文件的,再看看它的父目录:

尝试用hdfs dfs -chown修改其父目录权限,改为拥有者为hive。再次执行,还是报错。
转换下思路,难道是hive的权限限制问题?Unauthorized connection for super-user: hive from IP /10.81.35.162,大白话翻译:超级用户的未经授权的连接。而在 Hive 中,hive 用户通常是一个默认的超级用户,具备访问和操作 Hive 的所有权限
在hdfs的core-site文件中配置:
<property>
<name>hadoop.proxyuser.hive.groups</name>
<value>*</value> <!-- 允许所有用户组访问 -->
</property>
<property>
<name>hadoop.proxyuser.hive.hosts</name>
<value>xxx.xxx.xxx.xxx</value> <!-- 允许特定 IP 地址访问 ,多ip逗号分隔-->
</property>
ambari修改的话一般在HDFS的自定义core-site中,改为以上配置后需要先重启HDFS再重启HIve

5.FAILED: HiveAccessControlException Permission denied
sqlstd.SQLStdHiveAccessController: Current user : hive, Current Roles : [public[hive:USER]]
FAILED: HiveAccessControlException Permission denied: Principal [name=hive, type=USER] does not have following privileges for operation LOAD [[INSERT, DELETE] on Object [type=TABLE_OR_VIEW, name=default.ods_pre_dat_dcsj_time, action=INSERT]]
原因分析:在使用sqoop将Oracle数据查询,导入到hive分区表时,遇到以上报错信息,当前用户hive对hive表default.ods_pre_dat_dcsj_time没有insert权限,但是在脚本中我指定的hive数据库明明是dw库,怎么成了default库呢?脚本相关参数如下:
--split-by MINUTE \
--hive-import \
--hive-table ods_pre_dat_dcsj_time \
--target-dir /user/sqoop/hive/oracle_to_hive/ods_pre_dat_dcsj_time \
--delete-target-dir \
-- --hive-drop-import-delims \
--hcatalog-database dw \
--hcatalog-table ods_pre_dat_dcsj_time \
--hcatalog-storage-stanza 'stored as orc' \
--hcatalog-partition-keys "gcrq_year,gcrq_month,gcrq_day" \
--hcatalog-partition-values "${gcrq_year},${gcrq_month},${gcrq_day}" \
--num-mappers 3这是因为同时使用了hcatalog和hive-import,参数冲突,
解决方法:删除hive-import相关参数,修改后的脚本内容如下:
--split-by MINUTE \
--target-dir /user/sqoop/hive/oracle_to_hive/ods_pre_dat_dcsj_time \
--delete-target-dir \
-- --hive-drop-import-delims \
--hcatalog-database dw \
--hcatalog-table ods_pre_dat_dcsj_time \
--hcatalog-storage-stanza 'stored as orc' \
--hcatalog-partition-keys "gcrq_year,gcrq_month,gcrq_day" \
--hcatalog-partition-values "${gcrq_year},${gcrq_month},${gcrq_day}" \
--num-mappers 36. sqoop导入hive动态分区表,数据已经导入到HDFS,但并未导入到hive表中
安装第5点中提及的解决方法修改sqoop脚本后:
sqoop import \
--connect "jdbc:oracle:thin:@//localhost:61521/LZY2" \
--username root\
--password '12345678' \
--query "SELECT
TO_NUMBER(TO_CHAR(GCRQ, 'YYYY')) AS gcrq_year,
TO_NUMBER(TO_CHAR(GCRQ, 'MM')) AS gcrq_month,
TO_NUMBER(TO_CHAR(GCRQ, 'DD')) AS gcrq_day,
YEAR,
GCRQ,
GCZBS,
......
UPDATE_BY,
UPDATE_TIME,
INSERT_TIME
FROM LZJHGX.DAT_DCSJ_TIME
WHERE TO_CHAR(GCRQ , 'YYYY-MM-DD') = TO_CHAR(SYSDATE, 'YYYY-MM-DD') AND \$CONDITIONS" \
--split-by MINUTE \
--target-dir /user/sqoop/hive/oracle_to_hive/ods_pre_dat_dcsj_time \
--delete-target-dir \
-- --hive-drop-import-delims \
--hcatalog-database dw \
--hcatalog-table ods_pre_dat_dcsj_time \
--hcatalog-storage-stanza 'stored as orc' \
--hcatalog-partition-keys "gcrq_year,gcrq_month,gcrq_day" \
--hcatalog-partition-values "${gcrq_year},${gcrq_month},${gcrq_day}" \
--num-mappers 3虽然执行没有报错了, 但是数据仅仅从Oracle中查询导入到了HDFS,并未将数据再从HDFS导入hive中:



解决办法:首先分区字段的类型必须为STRING,否则在使用--hcatalog参数时会遇见:
Only string fields are allowed in partition columns in HCatalog

然后sqoop关键参数如下:
--split-by MINUTE \
--hcatalog-database dw \
--hcatalog-table ods_pre_dat_dcsj_time \
--hcatalog-storage-stanza 'stored as orc' \
--num-mappers 3注意,如果导入的Oracle数据中有日期时间而对应hive字段为timestamp,建议进行一次类似如下的转换,避免格式问题:
TO_CHAR(INSERT_TIME, 'YYYY-MM-DD HH24:MI:SS') AS INSERT_TIME
最后如图成功:

完整sqoop代码:
sqoop import \
--connect "jdbc:oracle:thin:@//Oracle数据库IP:端口/模式名称" \
--username 用户名 \
--password '密码' \
--query "SELECT
TO_CHAR(GCRQ, 'YYYY') AS gcrq_year,
TO_CHAR(GCRQ, 'MM') AS gcrq_month,
TO_CHAR(GCRQ, 'DD') AS gcrq_day,
YEAR,
TO_CHAR(GCRQ, 'YYYY-MM-DD HH24:MI:SS') AS GCRQ,
GCZBS,
......,
TO_CHAR(DELETE_TIME, 'YYYY-MM-DD HH24:MI:SS') AS DELETE_TIME,
CREATE_BY,
TO_CHAR(CREATE_TIME, 'YYYY-MM-DD HH24:MI:SS') AS CREATE_TIME,
UPDATE_BY,
TO_CHAR(UPDATE_TIME, 'YYYY-MM-DD HH24:MI:SS') AS UPDATE_TIME,
TO_CHAR(INSERT_TIME, 'YYYY-MM-DD HH24:MI:SS') AS INSERT_TIME
FROM LZJHGX.dat_dcsj_time
WHERE TO_CHAR(GCRQ , 'YYYY-MM-DD') = TO_CHAR(SYSDATE, 'YYYY-MM-DD') AND \$CONDITIONS" \
--split-by split字段 \
--hcatalog-database 数据库名称 \
--hcatalog-table 表名 \
--hcatalog-storage-stanza 'stored as orc' \
--num-mappers mapper个数N6. Moving of data failed during commit : Failed to move file
hdfs://udh/warehouse/tablespace/managed/hive/dw.db/ods_pre_t_jszx_tf_kj2_ll/_DYN0.5253055999633814/tjsj_year=2021/tjsj_month=07/tjsj_day=21 to hdfs://udh/warehouse/tablespace/managed/hive/dw.db/ods_pre_t_jszx_tf_kj2_ll/tjsj_year=2021/tjsj_month=07
这个错误很明显,无法将A路径下的文件移动至B路径下。
首先我的sqoop脚本如下:
sqoop import -D mapred.job.queue.name=highway \
-D mapreduce.map.memory.mb=4096 \
-D mapreduce.map.java.opts=-Xmx3072m \
--connect "jdbc:oracle:thin:@//localhost:123456/LZY2" \
--username LZSHARE \
--password '12345678' \
--query "SELECT
ZBDM
,ZBMC
,TO_CHAR(TJSJ, 'YYYY') AS tjsj_year
,TO_CHAR(TJSJ, 'MM') AS tjsj_month
,TO_CHAR(TJSJ, 'DD') AS tjsj_day
,TO_CHAR(TJSJ, 'YYYY-MM-DD HH24:MI:SS') AS TJSJ
................
,JLDWMC
,TO_CHAR(INPUTTIME, 'YYYY-MM-DD HH24:MI:SS') AS INPUTTIME
,UUID
,TO_CHAR(INSERTTIME, 'YYYY-MM-DD HH24:MI:SS') AS INSERTTIME
FROM LZJHGX.T_JSZX_TF_KJ2_LL
WHERE TO_CHAR(TJSJ , 'YYYY-MM-DD') < TO_CHAR(SYSDATE,'YYYY-MM-DD') AND \$CONDITIONS" \
--split-by ROWNUM \
--boundary-query "select 1 as MIN , sum(1) as MAX from LZJHGX.T_JSZX_TF_KJ2_LL" \
--hcatalog-database dw \
--hcatalog-table ods_pre_T_JSZX_TF_KJ2_LL \
--hcatalog-storage-stanza 'stored as orc' \
--num-mappers 8首先,在hive 命令行中查看hive表的数据量 ,结果是0
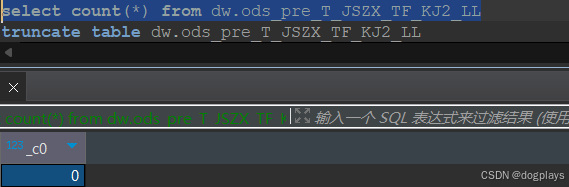
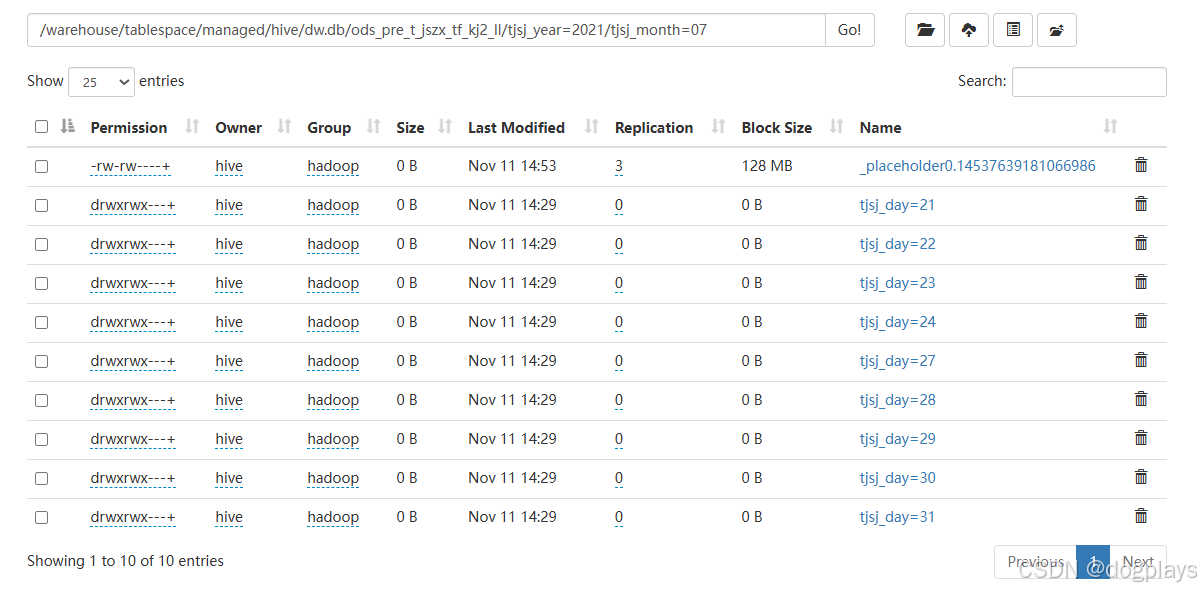
再查看对应的HDFS目录即报错信息中的hdfs://udh/warehouse/tablespace/managed/hive/dw.db/ods_pre_t_jszx_tf_kj2_ll/
发现路径下是有分区目录的
只不过最细分区目录下是没有数据文件的
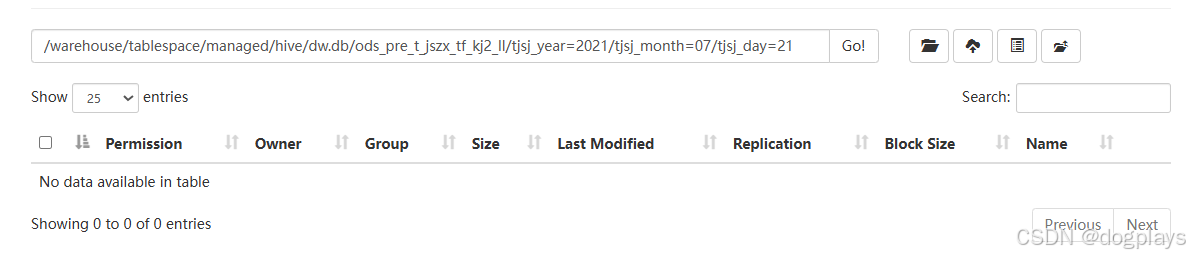
在执行此次sqoop import命令前,我有执行过一次sqoop import并且导入成功后执行hive sql truncate过。猜测可能是旧目录仍然存在,导致文件无法移动?验证一下我的猜想,将此表下原有的分区目录删除掉
hdfs dfs -rm -r /warehouse/tablespace/managed/hive/dw.db/ods_pre_t_jszx_tf_kj2_ll/*
再次执行,又出现另一个错误Partition already exists: Partition(values:[2021, 07, 21],
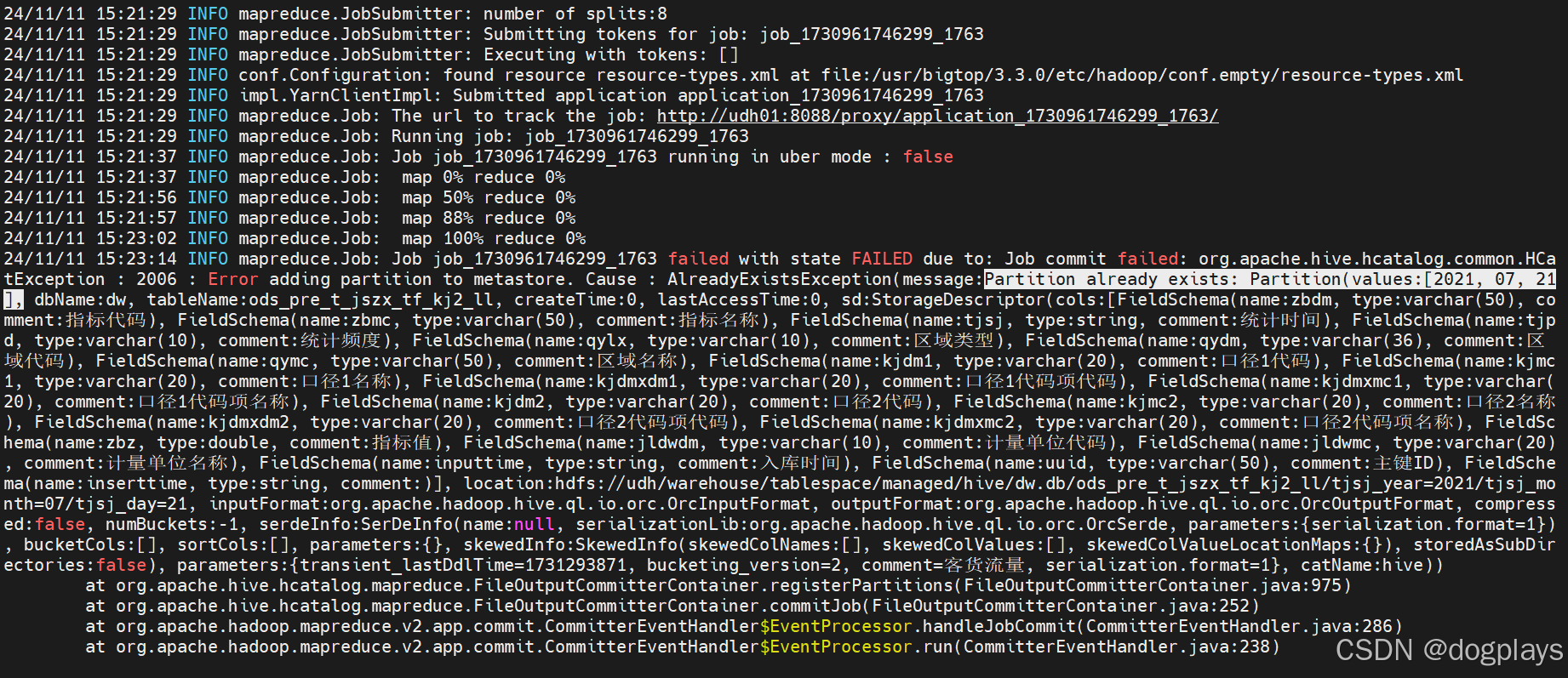
原因是分区未正确删除:hdfs dfs -rm -r 命令删除了文件,但 Hive 的元数据表中仍然保留了该分区的信息。即使没有物理数据文件,Hive 仍会认为该分区已存在。
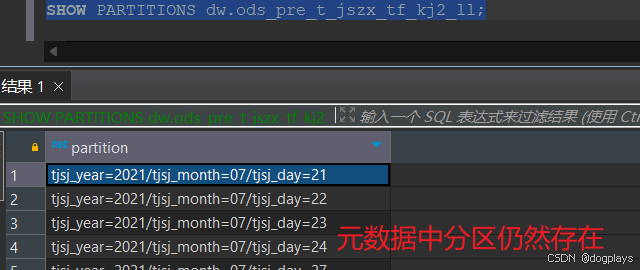
先手动删除物理文件
hdfs dfs -rm -r /warehouse/tablespace/managed/hive/dw.db/ods_pre_t_jszx_tf_kj2_ll/*
再执行hive sql删除所有分区
ALTER TABLE dw.ods_pre_t_jszx_tf_kj2_ll DROP IF EXISTS PARTITION (tjsj_year='2021');
我选择使用更快的方法,删除表后再重建一张一模一样的表。最后再次执行成功!

7. sqoop import将Oracle数据加载至hive,数据量变少,只能导入一个mapper的数据量
sqoop脚本如下:
sqoop import -D mapred.job.queue.name=highway \
-D mapreduce.map.memory.mb=4096 \
-D mapreduce.map.java.opts=-Xmx3072m \
--connect "jdbc:oracle:thin:@//1.2.3.4.5:61521/LZY2" \
--username root \
--password '123456' \
--query "SELECT
ZBDM
,ZBMC
,TO_CHAR(TJSJ, 'YYYY') AS tjsj_year
,TO_CHAR(TJSJ, 'MM') AS tjsj_month
,TO_CHAR(TJSJ, 'DD') AS tjsj_day
,TO_CHAR(TJSJ, 'YYYY-MM-DD HH24:MI:SS') AS TJSJ
......
,TO_CHAR(INPUTTIME, 'YYYY-MM-DD HH24:MI:SS') AS INPUTTIME
,UUID
,TO_CHAR(INSERTTIME, 'YYYY-MM-DD HH24:MI:SS') AS INSERTTIME
FROM LZJHGX.T_JSZX_TF_KJ2_LL
WHERE TO_CHAR(TJSJ , 'YYYY-MM-DD') < TO_CHAR(SYSDATE,'YYYY-MM-DD') AND \$CONDITIONS" \
--split-by ROWNUM \
--boundary-query "select 1 as MIN , sum(1) as MAX from LZJHGX.T_JSZX_TF_KJ2_LL" \
--hcatalog-database dw \
--hcatalog-table ods_pre_T_JSZX_TF_KJ2_LL \
--hcatalog-storage-stanza 'stored as orc' \
--num-mappers 8--query 参数的查询语句在Oracle中查询得到共计24563660数据,而加载到hive表dw.ods_pre_T_JSZX_TF_KJ2_LL中只有3070458数据。
24563660/8=3070457.5
这种巧合,刚好是一个mapper的向上取整量。这肯定有问题的,查看对应application的containers发现其实执行过程中是有做了split的:
例如mapper7,范围为:
ROWNUM >= 15352287.875 AND ROWNUM < 18422745.250

这是mapper8,范围为:
ROWNUM >= 18422745.250 AND ROWNUM < 21493202.625

但问题出现在Executing query,我把container7的语句放在Oracle中去执行,是没有返回任何结果集的:


但是container1中的Executing query查询却有结果集返回

这几个container中执行的Executing query查询,唯一不同的是条件ROWNUM的范围
AND ( ROWNUM >= 1 ) AND ( ROWNUM < 3070458.375 )
那么ROWNUM到底是什么?为什么AND ( ROWNUM >= 1 ) AND ( ROWNUM < 3070458.375 )有结果集返回,而ROWNUM >= 18422745.250 AND ROWNUM < 21493202.625却没有?
要明白其中的原因,必须要明白Oracle中的ROWNUM到底是什么?
先看一组Oracle查询:

Oracle 的 ROWNUM 是一个特殊的伪列,它按查询返回的顺序动态分配给结果集中的每一行。因此,ROWNUM 仅在行被提取时分配,而不是基于数据表中的实际行号。
-
第一部分查询:
SELECT COUNT(*) FROM LZJHGX.T_JSZX_TF_KJ2_LL WHERE TO_CHAR(TJSJ , 'YYYY-MM-DD') < TO_CHAR(SYSDATE,'YYYY-MM-DD')- 这一部分返回符合
TJSJ条件的所有记录数,结果为24,563,660。这表明符合条件的记录总数就是这么多。
- 这一部分返回符合
-
第二部分查询:
SELECT COUNT(*) FROM LZJHGX.T_JSZX_TF_KJ2_LL WHERE TO_CHAR(TJSJ , 'YYYY-MM-DD') < TO_CHAR(SYSDATE,'YYYY-MM-DD') AND ( ROWNUM >= 1 ) AND ( ROWNUM < 3070458.375 )- 这里你试图获取
ROWNUM在1和3,070,458.375范围内的行数。然而,ROWNUM在分配时是严格递增的,它只能用于获取从头开始的连续行。也就是说,只要有ROWNUM< 3,070,458.375 的限制,查询将返回符合条件的头3,070,458行。 - 因此,这个查询实际上在返回总符合条件的前
3,070,458行。
- 这里你试图获取
-
第三部分查询:
SELECT COUNT(*) FROM LZJHGX.T_JSZX_TF_KJ2_LL WHERE TO_CHAR(TJSJ , 'YYYY-MM-DD') < TO_CHAR(SYSDATE,'YYYY-MM-DD') AND ( ROWNUM >= 18422745.250 ) AND ( ROWNUM < 21493202.625 )- 这里的问题是,由于
ROWNUM的工作方式,ROWNUM永远不会满足>= 18422745.250和< 21493202.625这样的区间查询。ROWNUM是从1开始的递增序列,如果你直接使用ROWNUM >= 某值的条件,那么 Oracle 会从头重新生成行号,这种逻辑不支持从特定行号直接开始。因此,这个查询会返回 0 结果。
- 这里的问题是,由于
主要原因总结:
- ROWNUM 是一个动态生成的递增伪列,只能用于从查询的第一行依次生成,不能用来表示实际的物理行号。
- 当你用条件
ROWNUM >= 某值时,Oracle 会从第一个满足WHERE条件的行开始计算,无法跳过之前的行。
解决办法:所以在数据量很大时需要多个mapper并发执行时ROWNUM万万不能作为splitby字段,否则会出现数据量缺少,只有一个mapper数据量的问题。
方法1(不推荐):在--query利用开窗函数排序,数据量大时,非常消耗资源
方法2(推荐):将ROWNUM嵌套进子查询中,作为查询结果集中的一个字段,修改后的sqoop脚本如下:
sqoop import -D mapred.job.queue.name=highway \
-D mapreduce.map.memory.mb=4096 \
-D mapreduce.map.java.opts=-Xmx3072m \
-D sqoop.export.records.per.statement=1000 \
--fetch-size 10000 \
--connect "jdbc:oracle:thin:@//localhost:61521/LZY2" \
--username LZSHARE \
--password '123456' \
--query "SELECT * FROM(
SELECT
ROWNUM as splitby_column
,ZBDM
,ZBMC
,TO_CHAR(TJSJ, 'YYYY') AS tjsj_year
,TO_CHAR(TJSJ, 'MM') AS tjsj_month
,TO_CHAR(TJSJ, 'DD') AS tjsj_day
,TO_CHAR(TJSJ, 'YYYY-MM-DD HH24:MI:SS') AS TJSJ
,TJPD
......
,JLDWMC
,TO_CHAR(INPUTTIME, 'YYYY-MM-DD HH24:MI:SS') AS INPUTTIME
,UUID
,TO_CHAR(INSERTTIME, 'YYYY-MM-DD HH24:MI:SS') AS INSERTTIME
FROM LZJHGX.T_JSZX_TF_KJ2_LL
WHERE TO_CHAR(TJSJ , 'YYYY-MM-DD') < TO_CHAR(SYSDATE,'YYYY-MM-DD')) a WHERE \$CONDITIONS" \
--split-by splitby_column \
--hcatalog-database dw \
--hcatalog-table ods_pre_T_JSZX_TF_KJ2_LL \
--hcatalog-storage-stanza 'stored as orc' \
--num-mappers 208. sqoop加载Oracle数据到hive分区表,分区错乱
场景:sqoop脚本每日凌晨00:30定时执行,query查询昨日数据,加载至年-月-日分区。
sqoop脚本如下:
sqoop import -D mapred.job.queue.name=highway \
-D mapreduce.map.memory.mb=4096 \
-D mapreduce.map.java.opts=-Xmx3072m \
--connect "jdbc:oracle:thin:@//localhost:61521/LZY2" \
--username LZSHARE \
--password '123456' \
--query "SELECT
TO_CHAR(GCRQ, 'YYYY') AS gcrq_year,
TO_CHAR(GCRQ, 'MM') AS gcrq_month,
TO_CHAR(GCRQ, 'DD') AS gcrq_day,
YEAR,
TO_CHAR(GCRQ, 'YYYY-MM-DD HH24:MI:SS') AS GCRQ,
......
TO_CHAR(DELETE_TIME, 'YYYY-MM-DD HH24:MI:SS') AS DELETE_TIME,
CREATE_BY,
TO_CHAR(CREATE_TIME, 'YYYY-MM-DD HH24:MI:SS') AS CREATE_TIME,
UPDATE_BY,
TO_CHAR(UPDATE_TIME, 'YYYY-MM-DD HH24:MI:SS') AS UPDATE_TIME,
TO_CHAR(INSERT_TIME, 'YYYY-MM-DD HH24:MI:SS') AS INSERT_TIME
FROM LZJHGX.dat_dcsj_time
WHERE TO_CHAR(GCRQ , 'YYYY-MM-DD') = TO_CHAR(SYSDATE - 1, 'YYYY-MM-DD') AND \$CONDITIONS" \
--split-by sjxh \
--hcatalog-database dw \
--hcatalog-table ods_pre_dat_dcsj_time \
--hcatalog-storage-stanza 'stored as orc' \
--num-mappers 2记录显示在2024-11-12 00:29:14开始执行
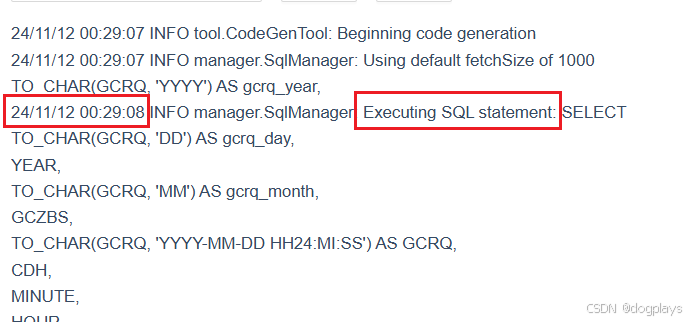
按照上述sqoop脚本来看,应该生成gcrq_year=2024 gcrq_month=11 gcrq_day=11的分区,但是实际情况是并没有
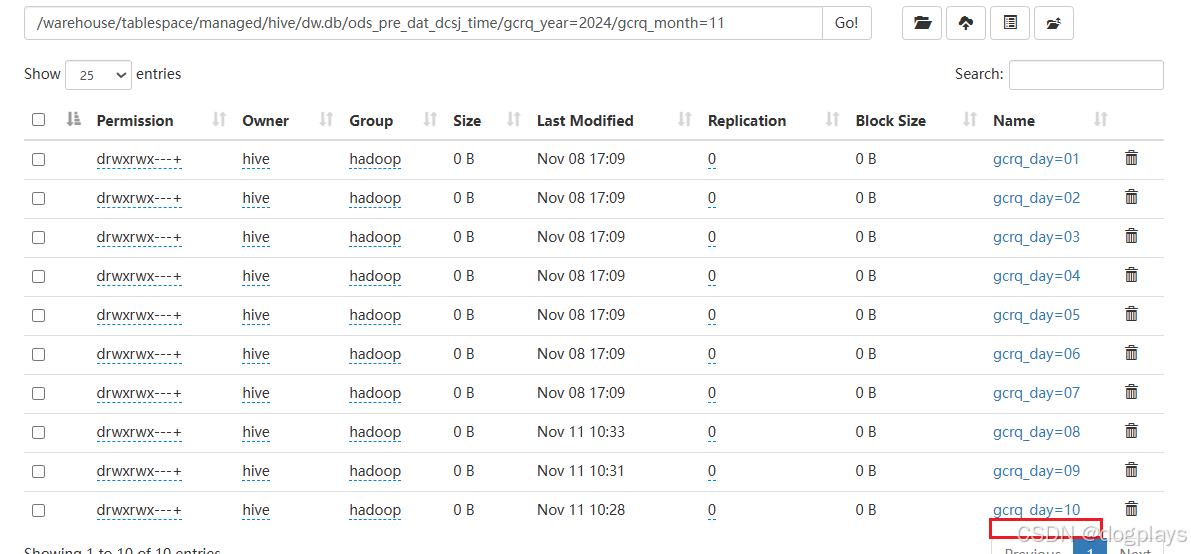
翻看日志发现虽然状态为成功
但是实际是导入失败的
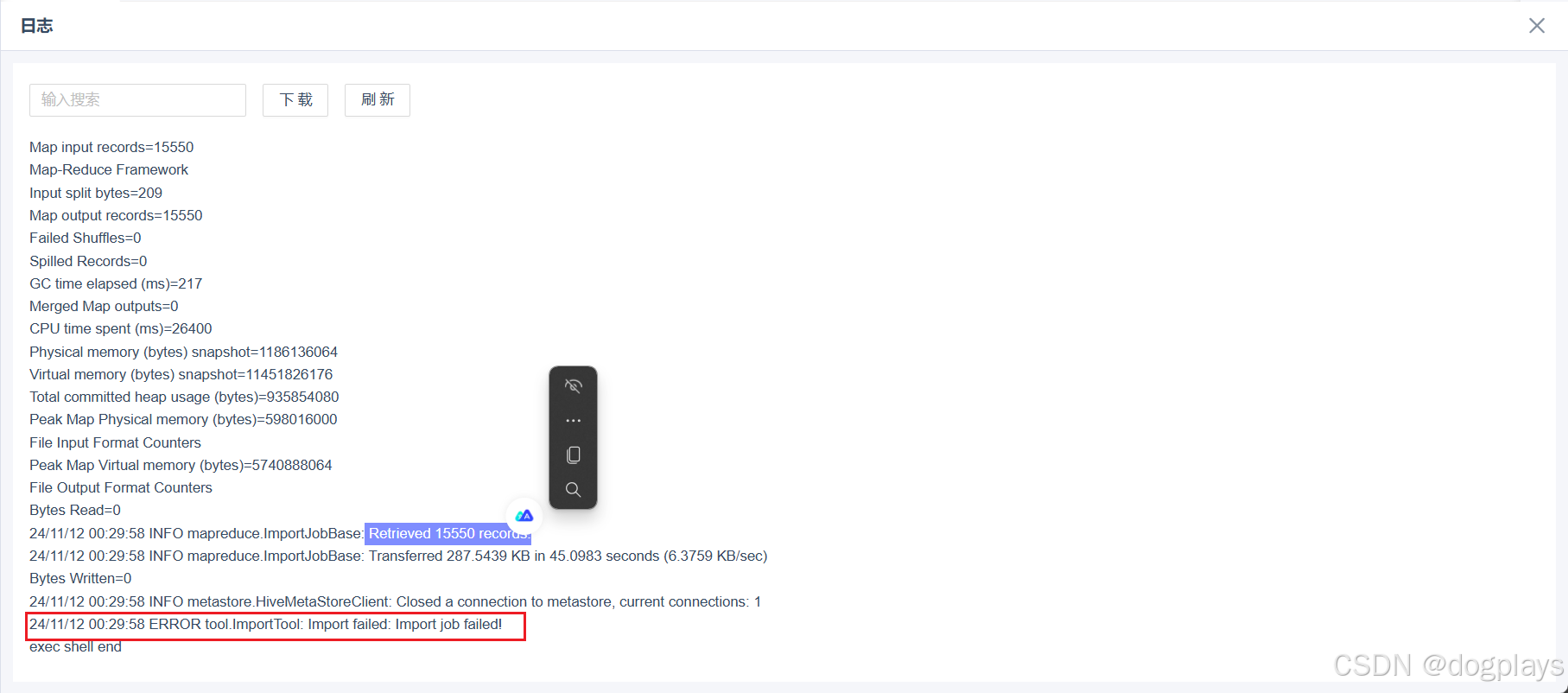
原因是权限拒绝,因为我是以root身份去执行sqoop命令,既不是hive用户,也不属于hadoop用户组。
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=root, access=EXECUTE, inode="/warehouse/tablespace/managed/hive":hive:hadoop:drwxrwx---
解决方法在服务器上将root用户添加至hadoop组中。再次执行分区创建正常


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









