







活动地址:优快云21天学习挑战赛
目录
1、从 Inception 到 Xception
Xception 是 Google 在 2017 年出品的轻量级神经网络,它与 GoogLeNet 中的 Inception 相似,可以认为是 Inception 的一种极端情况。同时,它与 MobileNet 的思想一致,即推动 Depthwise Conv + Pointwise Conv 的使用。另外,在 Xception 中,类似于 ResNet,一些 residual connects 被应用了进来。
最终模型在ImageNet等数据集上都取得了相比Inception v3与Resnet-152更好的结果。当然其模型大小与计算效率相对Inception v3也取得了较大提高。
Figure1是一个典型的 Inception 模块。
我们知道,卷积层的功能是同时学习跨通道相关性和空间相关性,而 Inception 的思想是尝试将这两个相关性的学习分割开来,即:
- 先用 1x1 conv来着重学习各通道之间的关联,
- 再用 3x3/5x5 conv (两个 3x3 conv 即为 5x5 conv)来学习其不同维度上的单个通道内在空间上的关联(也会学到部分各通道之间的关联)。
考虑一个 Inception 模块的简化版本,只使用一种规格的卷积(例如 3×3 conv),并且不含平均池化。如Figure2所示
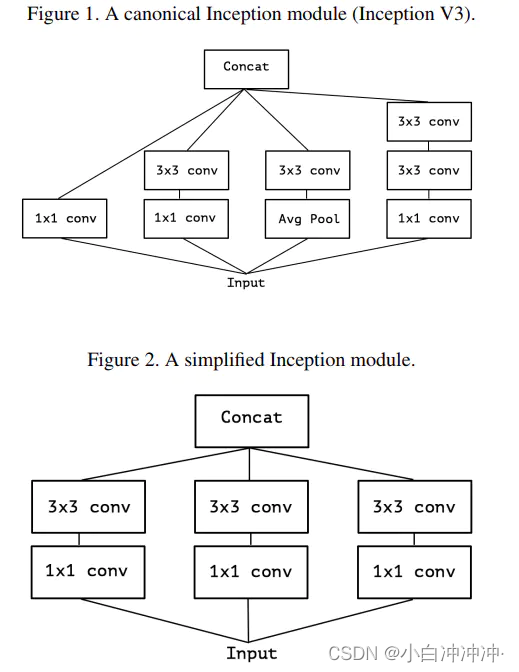
而本质上上图2中表示的简化版Inception模块又可被表示为下图3中的形式。可以看出实质上它等价于先使用一个1x1 conv来学习input feature maps之上channels间特征的关联关系,然后再将1x1 conv输出的feature maps进行分割,分别交由下面的若干个3x3 conv来处理其内的空间上元素的关联关系。如下图所示
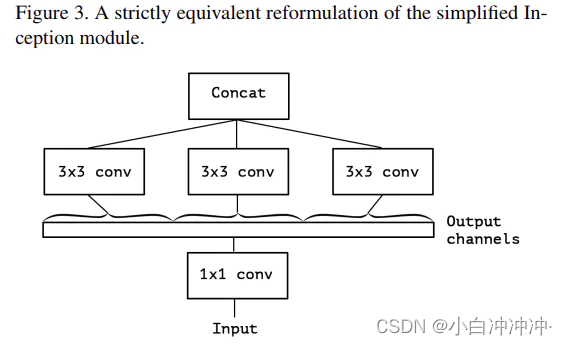
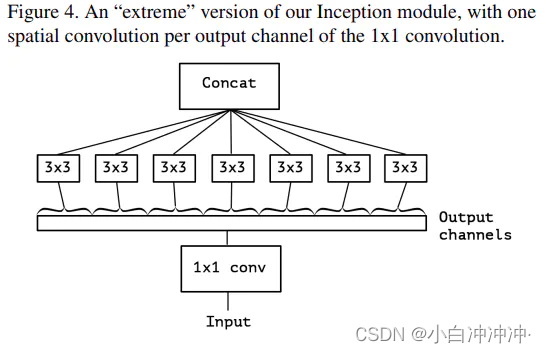
更进一步,何不做事做绝将每个channel上的空间关联分别使用一个相应的conv 3x3来单独处理呢。如此就得到了下图4中所示的Separable conv。
2、MobileNet vs Xception
MobileNet 和 Xception 之间有相同的地方也有不同的地方,主要体现在:
-
相同:都由 channel-wise 空间卷积和 1x1 卷积两个操作组成。
-
不同:
- 操作顺序不同:MobileNet 先进行 channel-wise 空间卷积,然后使用 1x1 卷积进行融合;Xception 先进行 1x1 卷积,然后进行 channel-wise 空间卷积。
- 非线性激励函数:MobileNet 中的两个操作之间添加了 ReLU 非线性激励;而为了保证数据不被破坏,Xception 中的两个操作之间没有激励函数。
上述两个不同点中,第一个并不是太重要,因为这些操作会被堆叠起来,从而改变一下结构中的模块划分顺序,两者基本上就等价了。而对于第二点就比较重要了。
3、Xception架构
Xception 结构由 36 个卷积层组成网络的特征提取基础。这些卷积层被分成 14 个模块,除最后一个外,模块间有线性残差连接。
另外,Xception 引入了 Entry/Middle/Exit 三个 flow,每个 flow 内部使用不同的重复模块,Entry flow主要是用来不断下采样,减小空间维度;中间则是不断学习关联关系,优化特征;最终则是汇总、整理特征,用于交由全连接层来进行表达。
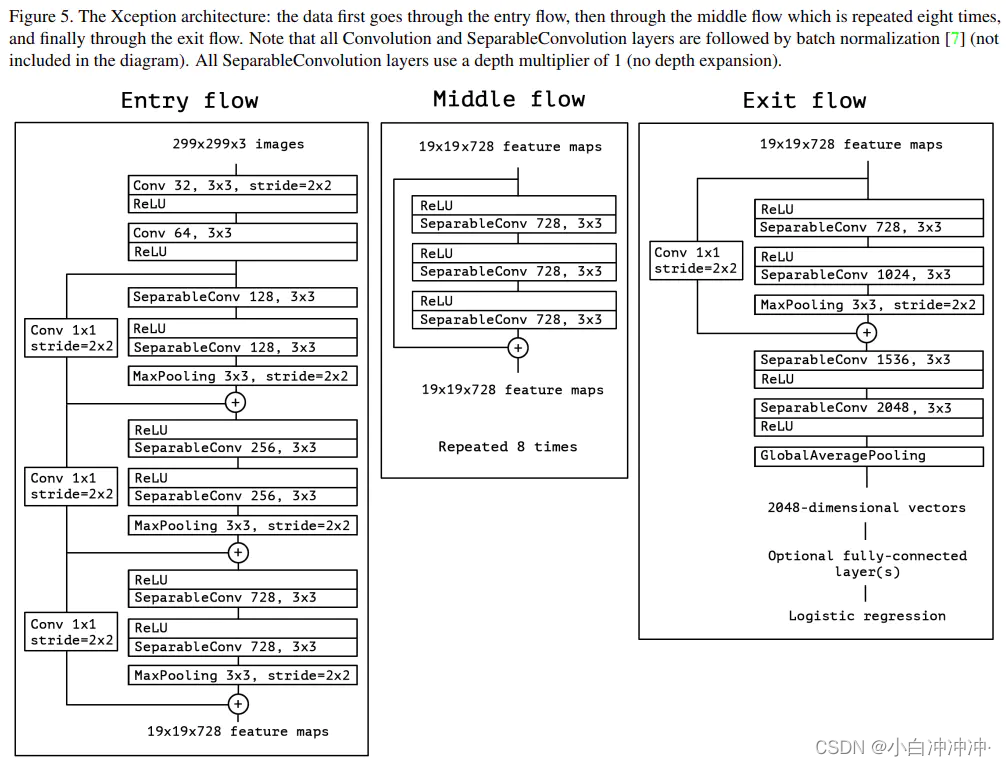
4、实验结果
下表为Xception与其它模型在Imagenet上分类精度的结果比较。
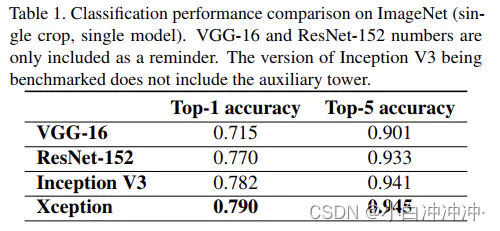
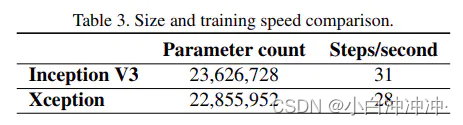
然后下表则为Xception与Inception v3在模型参数大小与计算速度上的比较。
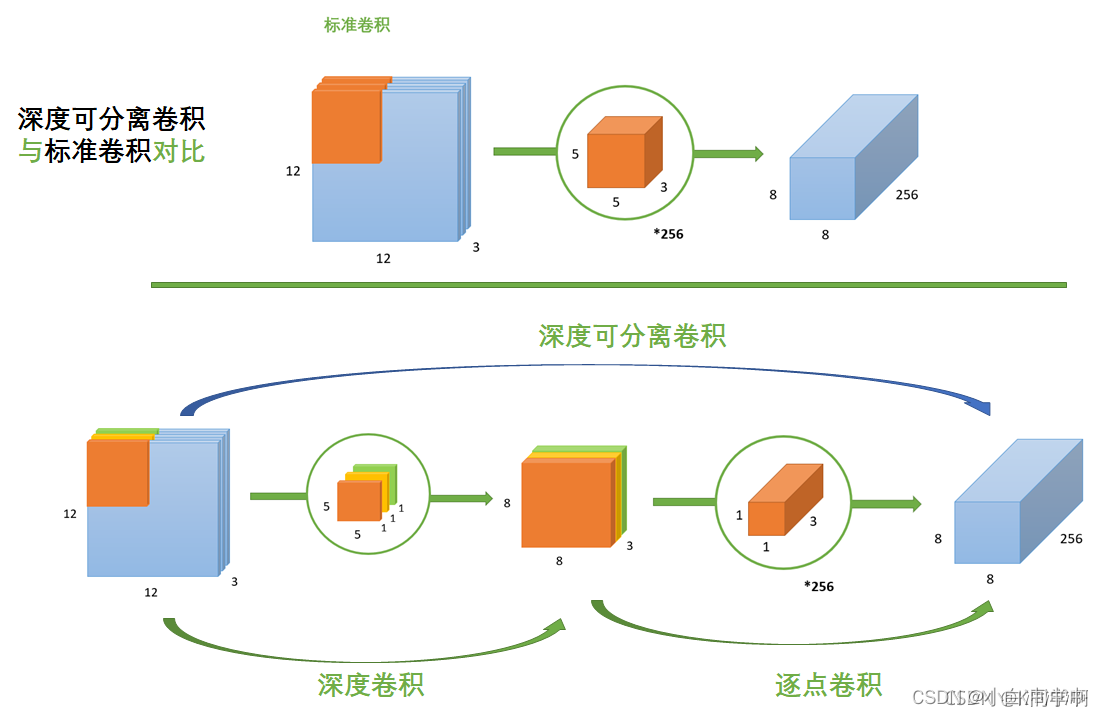
5、深度可分离卷积
深度可分离卷积其实是一种可分解卷积操作(factorized convolutions)。其可以分解为两个更小的操作:depthwise convolution 和 pointwise convolution。

(1)标准卷积
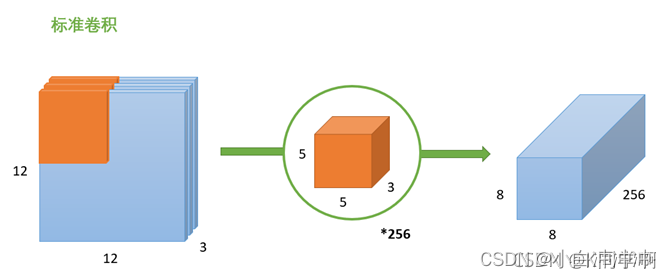
输入一个
12
∗
12
∗
3
12*12*3
12∗12∗3的一个输入特征图,经过
5
∗
5
∗
3
5*5*3
5∗5∗3的卷积核得到一个
8
∗
8
∗
1
8*8*1
8∗8∗1的输出特征图。如果此时有256个卷积核,将得到
8
∗
8
∗
256
8*8*256
8∗8∗256的输出特征图。
(2)深度卷积
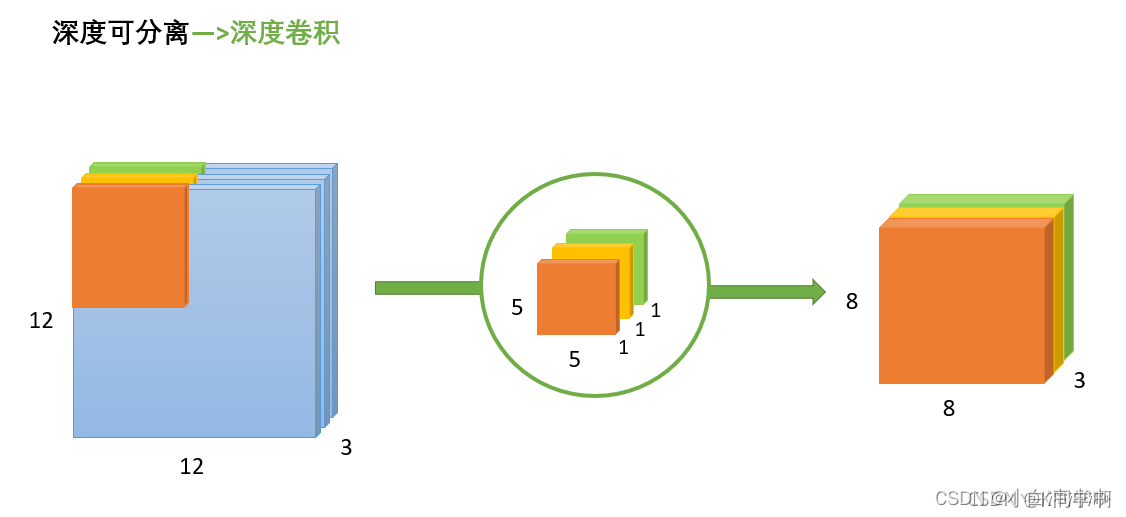
与标准卷积网络不一样的是,这里会将卷积核拆分为单通道形式,在不改变输入特征图像的深度情况下,对每一通道进行卷积操作,这样就得到了和输入特征图像通道数一致的输出特征图。如上图,输入
12
∗
12
∗
3
12*12*3
12∗12∗3的特征图,经过
5
∗
5
∗
1
∗
3
5*5*1*3
5∗5∗1∗3的深度卷积之后,得到
8
∗
8
∗
3
8*8*3
8∗8∗3的输出特征图。输入和输出的维度是不变的3,这样就有一个问题,通道数太少,特征图的维度太少,能获得足够的有效信息吗?
(3)逐点卷积
逐点卷积就是 1 ∗ 1 1*1 1∗1卷积,主要作用就是对特征图进行升维和降维,如下图:
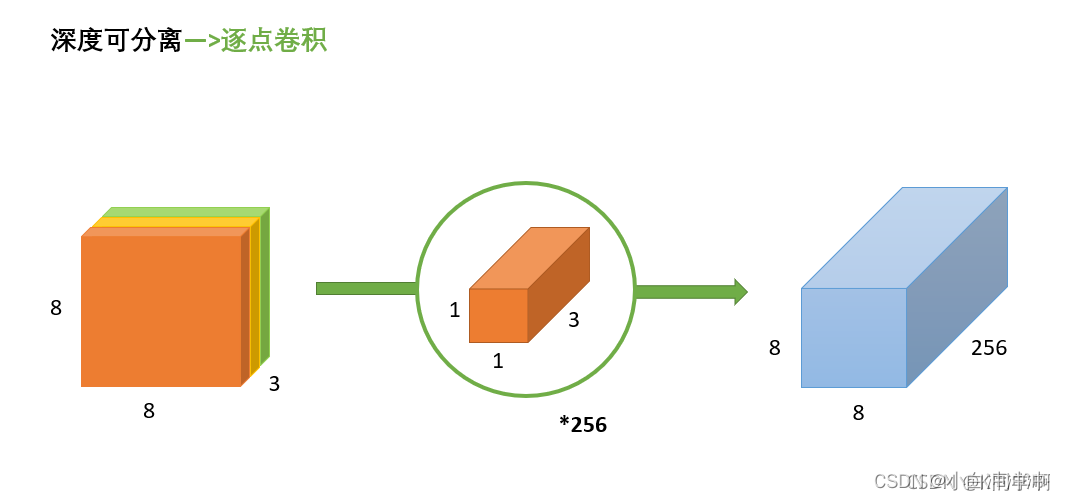
在深度卷积的过程中,我们得到了
8
∗
8
∗
3
8*8*3
8∗8∗3的输出特征图,我们用256个
1
∗
1
∗
3
1*1*3
1∗1∗3的卷积核对输入特征图进行卷积操作,输出的特征图和标准的卷积操作一样都是
8
∗
8
∗
256
8*8*256
8∗8∗256了。
标准卷积与深度可分离卷积的过程对比如下:
(4)为什么用深度可分离卷积?
深度可分离卷积可以实现更少的参数,更少的运算量。
6、SeparableConv2D() vs DepthwiseConv2D()
首先,我们要引入 Tensorflow2.0 中函数 tf.keras.layers.SeparableConv2D(filters, kernel_size, strides=(1, 1), padding=‘valid’) 用于构建 Separable conv。在实现 MobileNet 网络时,我们使用的函数是 tf.keras.layers.DepthwiseConv2D(kernel_size, strides=(1, 1), padding=‘valid’),这两个函数之间是包含与被包含的关系。
简单来说,SeparableConv2D() 是 DepthwiseConv2D() 的升级版。由上面的介绍我们可以知道,深度可分离卷积分为两步:
- 第一步:depthwise convolution 是在每个通道上独自的进行空间卷积,图a
- 第二步:pointwise convolution 是利用 1x1 卷积核组合前面 depthwise convolution 得到的特征,图b
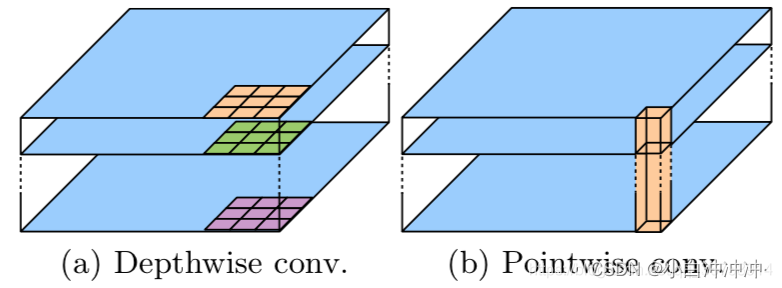
而 DepthwiseConv2D() 实现了第一步, SeparableConv2D() 直接实现了两步。故 SeparableConv2D() 与 DepthwiseConv2D() 相比,需要输入的参数多了一个 pointwise convolution 时的滤波器数量。
7、代码实现
代码原地址:https://blog.youkuaiyun.com/qq_36758914/article/details/106899041
import tensorflow as tf
class conv_block(tf.keras.Model):
def __init__(self, filters, kernel_size = (3,3), strides=(1,1)):
super().__init__()
self.listLayers = []
self.listLayers.append(tf.keras.layers.Conv2D(filters=filters,
kernel_size=kernel_size,
strides=strides,
padding='SAME'))
self.listLayers.append(tf.keras.layers.BatchNormalization())
self.listLayers.append(tf.keras.layers.Activation('relu'))
def call(self, x):
for layer in self.listLayers.layers:
x = layer(x)
return x
class separable_conv_block(tf.keras.Model):
def __init__(self, filters):
super().__init__()
self.listLayers = []
self.listLayers.append(tf.keras.layers.Activation('relu'))
self.listLayers.append(tf.keras.layers.SeparableConv2D(filters,
kernel_size=(3,3),
strides=(1,1),
padding='SAME'))
self.listLayers.append(tf.keras.layers.BatchNormalization())
def call(self, x):
for layer in self.listLayers.layers:
x = layer(x)
return x
def entry_flow(inputs):
x = conv_block(filters=32, strides=(2, 2))(inputs)
x = conv_block(filters=64)(x)
previous_block_activation = x
for size in [128, 256, 728]:
x = separable_conv_block(size)(x)
x = separable_conv_block(size)(x)
x = tf.keras.layers.MaxPooling2D(3, strides=2, padding='SAME')(x)
residual = tf.keras.layers.Conv2D(filters=size,
kernel_size=1,
strides=2,
padding='SAME')(previous_block_activation)
x = tf.keras.layers.add([x, residual])
previous_block_activation = x
return x
def middle_flow(x, num_blocks=8):
previous_block_activation = x
for _ in range(num_blocks):
for _ in range(3):
x = separable_conv_block(728)(x)
x = tf.keras.layers.add([x, previous_block_activation])
previous_block_activation = x
return x
def exit_flow(x, num_classes=1000):
previous_block_activation = x
for size in [728, 1024]:
x = separable_conv_block(size)(x)
x = tf.keras.layers.MaxPooling2D(3, strides=2, padding='SAME')(x)
residual = tf.keras.layers.Conv2D(filters=1024,
kernel_size=1,
strides=2,
padding='SAME')(previous_block_activation)
x = tf.keras.layers.add([x, residual])
for size in [1536, 2048]:
x = tf.keras.layers.SeparableConv2D(size,
kernel_size=(3,3),
strides=(1,1),
padding='SAME')(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Activation('relu')(x)
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Dense(num_classes, activation='softmax')(x)
return x
def xception(inputs):
x = entry_flow(inputs)
x = middle_flow(x, num_blocks=8)
x = exit_flow(x, num_classes=1000)
return x
inputs = np.zeros((1, 299, 299, 3), dtype=np.float32)
outputs = xception(inputs)
outputs.shape

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









