







文章目录
前言
2022.7.15 吴恩达深度学习第四课第一周 卷积神经网络
一、计算机视觉(引言)
如果你要操作一张比较大的图片,如1000* 1000的图片,但是它的特征向量的维度达到了1000* 1000*3(3个RGB通道)。在第一隐藏层,你或许有1000个隐藏单元,那么此时𝑊[1]的维度为(1000,3m),这是非常巨大的数字。在参数如此大量的情况下,难以获得足够的数据来防止神经网络发生过拟合等等,因为数据稍微多点就内存不够了。。。
这时就需要卷积计算,它是卷积神经网络中非常重要的一块。那我们就开始吧。
二、边缘检测示例(过滤器)
给一张图片,让电脑去搞清楚这张图片里有什么物体,你可能做的第一件事是检测图片中的垂直边缘。同样,你也可能想检测水平边缘,所以如何在图像中检测这些边缘?
看一个例子,这是一个6*6的灰度图像。因为是灰度图像,所以它是6 * 6 * 1的矩阵,而不是6 * 6 * 3,因为没有RGB三通道。为了检测垂直边缘,你可以构造一个3 * 3的矩阵,它被称为过滤器,在论文中他有时被称为核。
最右边的矩阵中有一段亮一点的区域,对应检查到这个6 * 6图像中间的垂直边缘。这里的维数似乎有点不正确,检测到的边缘太粗了。因为在这个例子中,图片太小了。如果你用一个1000 * 1000的图像,你会发现其实会很好地检测出图像中的垂直边缘。
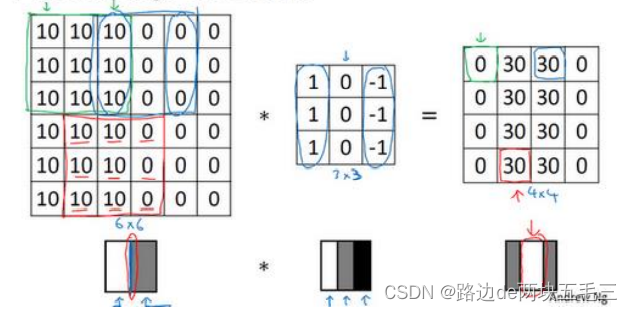
三、更多边缘检测内容(由亮到暗还是由暗到亮?)
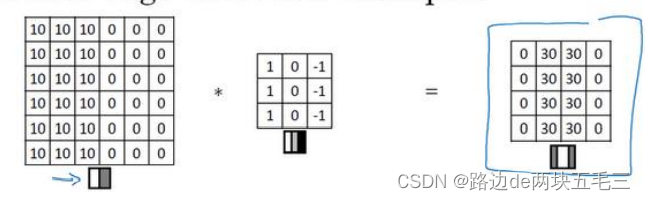
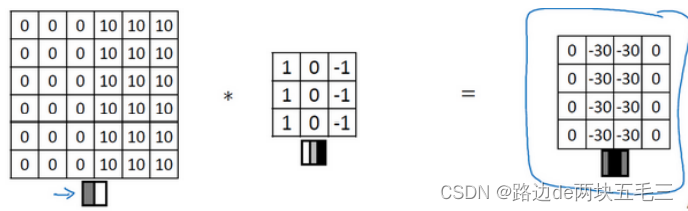
最右边图片中,中间向两侧由亮到暗,再加上过滤器也是有亮到暗,所以判断左侧图片也是有亮到暗。同理
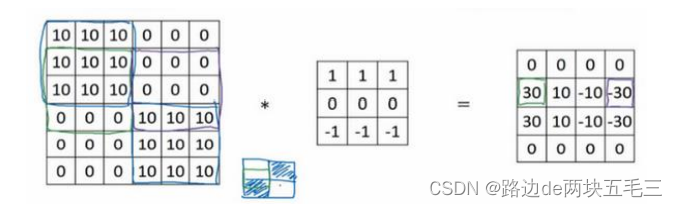
将3 * 3矩阵的所有数字都设置成参数,通过数据反馈,让神经系统自动去学习他们,我们会发现神经系统可以学习一些低级的特征。不过这些计算的基础依然是卷积运算,使得反向传播能够让神经网络学习任何它需要的3 * 3的过滤器,并在整幅图片上面应用它。
四、Padding(Valid、Same、p)
如果有一个n * n的图像,用f * f的过滤器做卷积,那么输出的维度就是(n-f+1)*(n-f+1)。这样的话有两个缺点。
第一每次做卷积操作,图像就会缩小,你可不想让你的图像在每次识别边缘或其他特征时都缩小。
第二你注意角落边缘的像素,这个像素点只被一个输出所触碰或使用。但如果是中间的像素点,就会有许多3 * 3的区域与之重叠,所以那些在角落或者边缘的像素点在输出中采用较少,意味着你丢掉了图像边缘位置许多信息。
为了解决这些问题,你可以在卷积操作之前填充这幅图像。至于选择填充多少像素,通常有两个选择,分别叫Valid卷积和Same卷积。
Valid卷积意味着不填充。Same卷积意味着你填充后,你的输出大小和输入大小是一样的。当然你也可以指定p的值。
五、卷积步长(s)

六、三维卷积(通道)
你已经知道如何对二维图像做卷积了,现在看看如何卷积在三维立体上。
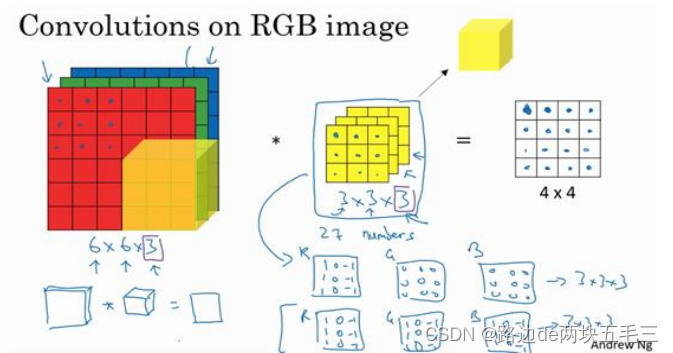
那么,这个能干嘛呢?举个例子,这个过滤器是3 * 3 *3的,如果你想检测图像红色通道的边缘,那么你可以将第一个过滤器设为[[1,0,-1],[1,0,-1],[1,0,-1]],和之前一样,而绿色通道全为0,蓝色通道全为0.如果你把这个三个堆叠在一起形成一个3 * 3 * 3的过滤器,那么这就是一个检测垂直边界的过滤器,但只是红色通道有用。
或者如果你不关心垂直边界在哪个颜色通道里,那么你可以用一个这样的过滤器,[[1,0,-1],[1,0,-1],[1,0,-1]],[[1,0,-1],[1,0,-1],[1,0,-1]],[[1,0,-1],[1,0,-1],[1,0,-1]]。
七、单层卷积网络
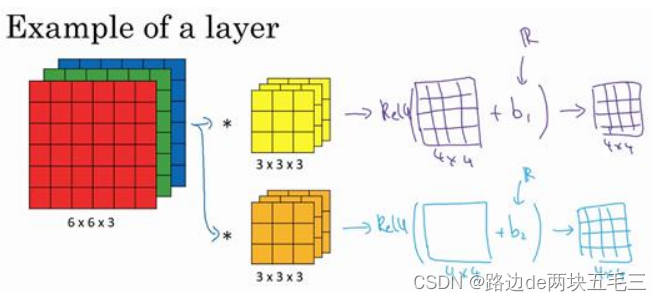
假设使用第一个过滤器进行卷积,得到第一个4 * 4矩阵,使用第二个过滤器进行卷积得到另外一个4 * 4矩阵。最终各自形成一个卷积神经网络层,然后增加偏差,它是一个实数,通过Python的广播机制给这16个元素都加上同一个偏差。然后应用非线性函数,为了说明,它是一个非线性激活函数ReLU,输出结果是一个4 * 4矩阵。
对于第二个4 * 4矩阵,我们加上不同的偏差,他是一个实数,再应用激活函数ReLU,最终得到一个4 * 4 * 2的矩阵。
单层的解释:上面的例子就通过神经网络的一层把一个6 * 6 *3的维度a[0]演化为一个4 * 4 * 2维度的a[1],这就是卷积网络的一层。
八、简单卷积网络示例(Conv,POOL,FC)
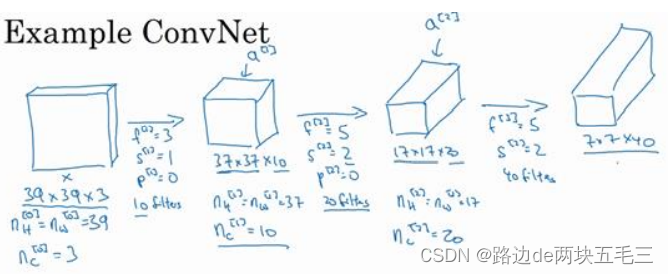
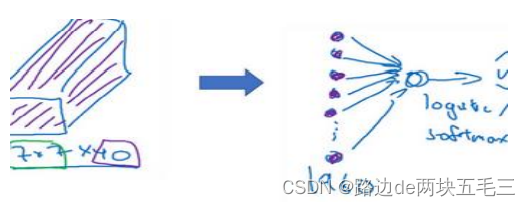
到此,这张39 * 39 * 3的输入图像就处理完毕了,为图片提取了7 * 7 * 40个特征,计算出来就是1960个特征。然后对该卷积进行处理,可以将其平滑或展开成1960个单元,其填充内容是logistic回归单元还是softmax回归单元,完全取决于我们是想识别图片上有没有猫,还是想识别K种不同对象中的一种,用y^表示最终神经网络的预测输出。
一个典型的卷积神经网络通常有三层,一个是卷积层(Conv),还有两种常见类型的层,池化层(POOL),全连接层(FC)。虽然仅用卷积层也可能构建出很好的神经网络,但大部分神经网络架构师依然会添加池化层和全连接层。幸运的是,池化层和全连接层比卷积层更容易设计。
九、池化层(max pooling、average pooling)
除了卷积层,卷积网络也经常使用池化层来缩减模型的大小,提高计算速度,同时提高所提其特征的鲁棒性。
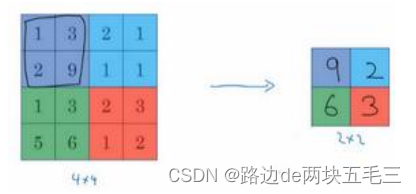
这是对最大池化功能的直观理解,你可以把这个4 * 4输入看作某些特征的集合,数字大意味着可能探测到了某些特定的特征,左上象限具有的特征可能是一个垂直边缘,一个眼睛。所以最大化操作的功能就是只要在任何一个象限内提取到某个特征,它都会保留其最大值。如果没有提取到这个特征,可能在右上象限中不存在这个特征,那么其中的最大值也还是很小,这就是最大池化的直观理解。
不知道大家能否理解最大池化效率很高的真正原因。他有一组超参数,但并没有参数需要学习。实际上,梯度下降没什么可学的,一旦确定了f和s,他就是一个固定运算,梯度下降无需改变任何值。
还有一个类型的池化,平均池化,他不常用。
最大池化只是计算神经网络某一层的静态属性,没什么需要学习的,他只是一个静态属性。
十、卷积神经网络示例
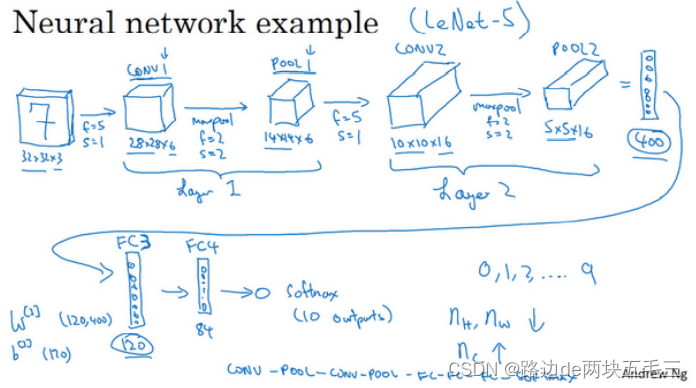
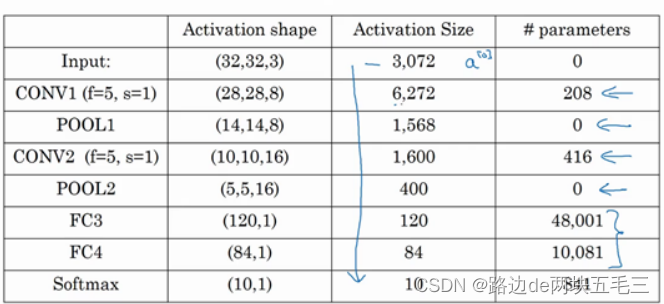
此图片parameters有歧义,此处CONV1和CONV2的过滤器通道数个层的参数是一样的,也就是各个通道检查的特征是一样的。故208=(5*5+1)*8,同理416.
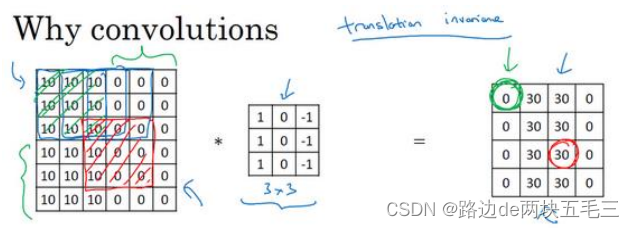
十一、为什么使用卷积?
假设有一张32 * 32 * 3维度的图片,假设用了6个大小为5 * 5的过滤器,输出维度为28 * 28 * 6,此处过滤器需要参数156个。我们构建一个神经网络,其中一层含有3072个单元,下一层含有4074个单元,两层的每个单元彼此相连,然后计算权重矩阵,他等于4074 * 3072~1400万,参数太多。
卷积网络映射这么少参数的有两个原因:
一是参数共享。特征检测如垂直边缘检测如果是用于图片的某个区域,那么它也可能适用于图片的其他区域。
二是这个方法是使用稀疏链接。这个0是通过3 * 3的卷积计算得到的,他只依赖这个3 * 3的输入的单元格,右边这个输出单元(0)仅与36个输入特征中9个相连接。而其他像素都不会对输出产生任何影响,这就是稀疏链接的概念。
第一周作业
情景引入
实现卷积神经网络,使用TensorFlow实现手势识别。

资料下载
提取码:6666
完整代码
import math
import numpy as np
import h5py
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import tensorflow as tf
from tensorflow.python.framework import ops
from cnn_utils import load_dataset
import cnn_utils
%matplotlib inline
np.random.seed(1)
def create_placeholders(n_H0, n_W0, n_C0, n_y):
"""
为session创建占位符
参数:
n_H0 - 实数,输入图像的高度
n_W0 - 实数,输入图像的宽度
n_C0 - 实数,输入的通道数
n_y - 实数,分类数
输出:
X - 输入数据的占位符,维度为[None, n_H0, n_W0, n_C0],类型为"float"
Y - 输入数据的标签的占位符,维度为[None, n_y],维度为"float"
"""
X = tf.placeholder(tf.float32,[None, n_H0, n_W0, n_C0])
Y = tf.placeholder(tf.float32,[None, n_y])
return X,Y
def initialize_parameters():
"""
初始化权值矩阵,这里我们把权值矩阵硬编码:
W1 : [4, 4, 3, 8]
W2 : [2, 2, 8, 16]
返回:
包含了tensor类型的W1、W2的字典
"""
tf.set_random_seed(1)
W1 = tf.get_variable("W1",[4,4,3,8],initializer=tf.contrib.layers.xavier_initializer(seed=0))
W2 = tf.get_variable("W2",[2,2,8,16],initializer=tf.contrib.layers.xavier_initializer(seed=0))
parameters = {"W1": W1,
"W2": W2}
return parameters
def forward_propagation(X,parameters):
"""
实现前向传播
CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED
参数:
X - 输入数据的placeholder,维度为(输入节点数量,样本数量)
parameters - 包含了“W1”和“W2”的python字典。
返回:
Z3 - 最后一个LINEAR节点的输出
"""
W1 = parameters['W1']
W2 = parameters['W2']
#Conv2d : 步伐:1,填充方式:“SAME”
Z1 = tf.nn.conv2d(X,W1,strides=[1,1,1,1],padding="SAME")
#ReLU :
A1 = tf.nn.relu(Z1)
#Max pool : 窗口大小:8x8,步伐:8x8,填充方式:“SAME”
P1 = tf.nn.max_pool(A1,ksize=[1,8,8,1],strides=[1,8,8,1],padding="SAME")
#Conv2d : 步伐:1,填充方式:“SAME”
Z2 = tf.nn.conv2d(P1,W2,strides=[1,1,1,1],padding="SAME")
#ReLU :
A2 = tf.nn.relu(Z2)
#Max pool : 过滤器大小:4x4,步伐:4x4,填充方式:“SAME”
P2 = tf.nn.max_pool(A2,ksize=[1,4,4,1],strides=[1,4,4,1],padding="SAME")
print(str(P2.shape))
#一维化上一层的输出
P = tf.contrib.layers.flatten(P2)
print(str(P.shape))
#全连接层(FC):使用没有非线性激活函数的全连接层 全连接和数据库的全外连接相似,P.shape * 6个连接,也就是维度为(P.shape,6)
Z3 = tf.contrib.layers.fully_connected(P,6,activation_fn=None)
print(str(Z3.shape))
return Z3
tf.reset_default_graph()
np.random.seed(1)
with tf.Session() as sess_test:
X,Y = create_placeholders(64,64,3,6)
parameters = initialize_parameters()
Z3 = forward_propagation(X,parameters)
init = tf.global_variables_initializer()
sess_test.run(init)
a = sess_test.run(Z3,{X: np.random.randn(2,64,64,3), Y: np.random.randn(2,6)})
print("Z3 = " + str(a))
sess_test.close()
def compute_cost(Z3,Y):
"""
计算成本
参数:
Z3 - 正向传播最后一个LINEAR节点的输出,维度为(6,样本数)。
Y - 标签向量的placeholder,和Z3的维度相同
返回:
cost - 计算后的成本
"""
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=Z3,labels=Y))
return cost
def model(X_train, Y_train, X_test, Y_test, learning_rate=0.009,
num_epochs=100,minibatch_size=64,print_cost=True,isPlot=True):
"""
使用TensorFlow实现三层的卷积神经网络
CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED
参数:
X_train - 训练数据,维度为(None, 64, 64, 3)
Y_train - 训练数据对应的标签,维度为(None, n_y = 6)
X_test - 测试数据,维度为(None, 64, 64, 3)
Y_test - 训练数据对应的标签,维度为(None, n_y = 6)
learning_rate - 学习率
num_epochs - 遍历整个数据集的次数
minibatch_size - 每个小批量数据块的大小
print_cost - 是否打印成本值,每遍历100次整个数据集打印一次
isPlot - 是否绘制图谱
返回:
train_accuracy - 实数,训练集的准确度
test_accuracy - 实数,测试集的准确度
parameters - 学习后的参数
"""
ops.reset_default_graph() #能够重新运行模型而不覆盖tf变量
tf.set_random_seed(1) #确保你的数据和我一样
seed = 3 #指定numpy的随机种子
(m , n_H0, n_W0, n_C0) = X_train.shape
n_y = Y_train.shape[1]
costs = []
#为当前维度创建占位符
X , Y = create_placeholders(n_H0, n_W0, n_C0, n_y)
#初始化参数
parameters = initialize_parameters()
#前向传播
Z3 = forward_propagation(X,parameters)
#计算成本
cost = compute_cost(Z3,Y)
#反向传播,由于框架已经实现了反向传播,我们只需要选择一个优化器就行了
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
#全局初始化所有变量
init = tf.global_variables_initializer()
#开始运行
with tf.Session() as sess:
#初始化参数
sess.run(init)
#开始遍历数据集
for epoch in range(num_epochs):
minibatch_cost = 0
num_minibatches = int(m / minibatch_size) #获取数据块的数量
seed = seed + 1
minibatches = cnn_utils.random_mini_batches(X_train,Y_train,minibatch_size,seed)
#对每个数据块进行处理
for minibatch in minibatches:
#选择一个数据块
(minibatch_X,minibatch_Y) = minibatch
#最小化这个数据块的成本
_ , temp_cost = sess.run([optimizer,cost],feed_dict={X:minibatch_X, Y:minibatch_Y})
#累加数据块的成本值
minibatch_cost += temp_cost / num_minibatches
#是否打印成本
if print_cost:
#每5代打印一次
if epoch % 5 == 0:
print("当前是第 " + str(epoch) + " 代,成本值为:" + str(minibatch_cost))
#记录成本
if epoch % 1 == 0:
costs.append(minibatch_cost)
#数据处理完毕,绘制成本曲线
if isPlot:
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (per tens)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
#开始预测数据
## 计算当前的预测情况
predict_op = tf.arg_max(Z3,1)
corrent_prediction = tf.equal(predict_op , tf.arg_max(Y,1))
##计算准确度
accuracy = tf.reduce_mean(tf.cast(corrent_prediction,"float"))
print("corrent_prediction accuracy= " + str(accuracy))
train_accuracy = accuracy.eval({X: X_train, Y: Y_train})
test_accuary = accuracy.eval({X: X_test, Y: Y_test})
print("训练集准确度:" + str(train_accuracy))
print("测试集准确度:" + str(test_accuary))
return (train_accuracy,test_accuary,parameters)
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
X_train = X_train_orig/255.
X_test = X_test_orig/255.
Y_train = cnn_utils.convert_to_one_hot(Y_train_orig, 6).T
Y_test = cnn_utils.convert_to_one_hot(Y_test_orig, 6).T
_, _, parameters = model(X_train, Y_train, X_test, Y_test,num_epochs=150)
_, _, parameters = model(X_train, Y_train, X_test, Y_test,num_epochs=150)

















 1763
1763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









