






一、背景
运行面promtheus因为调整资源,进行了pod重启,导致控制面的一级 prometheus报错,监控数据无法显示。
二、处理过程
查看控制面prometheus pod日志,发现prometheus日志报如下错误:
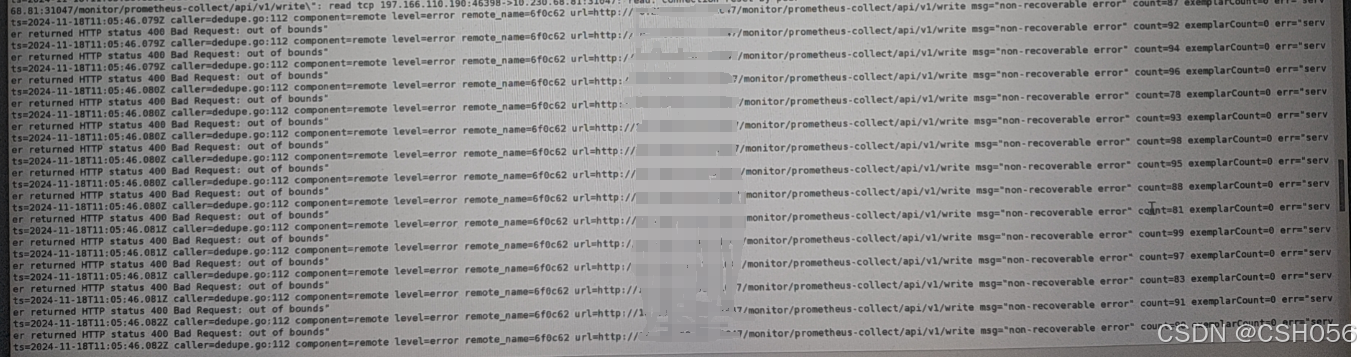 解决方法:
解决方法:
1、停止 prometheus 服务
2、删除 wal 目录
3、删除 chunks_head 目录
4、删除 lock 文件
5、删除queries.active 文件
6、启动 prometheus 服务
注: 官方反馈这是一个bug,具体iuess如下:
https://github.com/prometheus/prometheus/issues/12182

















 621
621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









