









注:笔记 来自课程 人工智能必备数学知识
Tips①:只是记录从这个课程学到的东西,不是推广、没有安利
Tips②:本笔记主要目的是为了方便自己遗忘查阅,或过于冗长、或有所缺省、或杂乱无章,见谅
Tips③:本笔记使用markdown编写,相关缩进为了方便使用了LaTeX公式的\qquad,复制粘贴请注意
文章目录
一、深度强化学习
深度强化学习 = 深度神经网络 + 强化学习 \color{#6666FF} \textbf{深度强化学习} = \textbf{深度神经网络} + \textbf{强化学习} 深度强化学习=深度神经网络+强化学习
一个模型是深度学习模型,同时又使用强化学习的方法进行训练,使其应用在某个具体的领域,就是深度强化学习模型
马尓可夫链就是强化学习的底层数学原理
当我们考虑一个问题能否用强化学习的方式来解决时,我们就要思考这个问题能否定义为一个马尔可夫决策过程
二、马尓可夫链(Markov Chain)
1、马尓可夫链
马尓可夫链是状态空间中从一个状态到另一个状态转换的随机过程,下一个状态的概率分布只由当前状态决定,且与它前面的事件均无关:
P ( S t + 1 ∣ S t , S t − 1 , ⋯ , S 0 ) = P ( S t + 1 ∣ S t ) \color{#6666FF} P(S_{t+1} | S_t, S_{t - 1}, \cdots, S_0) = P(S_{t+1} | S_t) P(St+1∣St,St−1,⋯,S0)=P(St+1∣St)
一种状态到另一种状态的转变,称为状态的转移
一种状态向另一种状态转移的概率,称为转移概率
示例1
:
\color{#FFA5FF} \textbf{示例1}:
示例1:
假
设
有
两
种
天
气
状
态
(
晴
天
、
下
雨
)
,
第
二
天
的
天
气
状
态
只
取
决
于
前
一
天
的
天
气
状
态
:
\color{#FFA5FF} \qquad 假设有两种天气状态(晴天、下雨),第二天的天气状态只取决于前一天的天气状态:
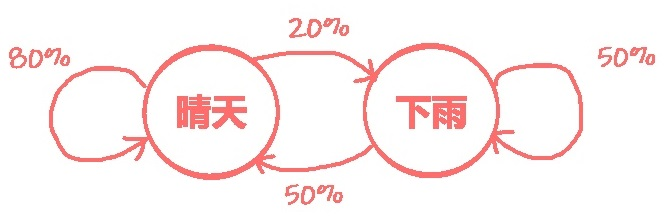
假设有两种天气状态(晴天、下雨),第二天的天气状态只取决于前一天的天气状态:
第
一
天
晴
天
,
第
二
天
:
晴
天
(
80
%
)
,
下
雨
(
20
%
)
\color{#FFA5FF} \qquad\qquad 第一天晴天,第二天:晴天(80\%),下雨(20\%)
第一天晴天,第二天:晴天(80%),下雨(20%)
第
一
天
下
雨
,
第
二
天
:
晴
天
(
50
%
)
,
下
雨
(
50
%
)
\color{#FFA5FF} \qquad\qquad 第一天下雨,第二天:晴天(50\%),下雨(50\%)
第一天下雨,第二天:晴天(50%),下雨(50%)
可
作
出
状
态
转
换
图
如
下
:
\color{#FF8080} 可作出状态转换图如下:
可作出状态转换图如下:
\qquad
2、状态转移矩阵
从 上 面 的 示 例 中 , 我 们 可 以 看 出 : \color{#00A000} 从上面的示例中,我们可以看出: 从上面的示例中,我们可以看出:
一
个
马
尓
可
夫
链
由
一
个
二
元
组
(
S
,
P
)
组
成
\color{#6666FF} \qquad 一个马尓可夫链由一个二元组(S, P)组成
一个马尓可夫链由一个二元组(S,P)组成
其
中
\color{#6666FF} \qquad 其中
其中
S
—
—
状
态
的
集
合
\color{#6666FF} \qquad\qquad S——状态的集合
S——状态的集合
P
—
—
状
态
转
移
矩
阵
(
记
录
了
从
任
意
一
个
状
态
到
另
一
个
状
态
的
转
移
概
率
)
\color{#6666FF} \qquad\qquad P——状态转移矩阵(记录了从任意一个状态到另一个状态的转移概率)
P——状态转移矩阵(记录了从任意一个状态到另一个状态的转移概率)
设
当
前
各
状
态
概
率
构
成
一
个
概
率
向
量
V
0
,
经
过
t
次
状
态
转
移
后
,
各
个
状
态
概
率
构
成
概
率
向
量
V
t
,
则
有
\color{#AA66FF} 设当前各状态概率构成一个概率向量V_0,经过t次状态转移后,各个状态概率构成概率向量V_t,则有
设当前各状态概率构成一个概率向量V0,经过t次状态转移后,各个状态概率构成概率向量Vt,则有
V
t
=
V
0
P
t
\color{#AA66FF} V_t = V_0 P^t
Vt=V0Pt
题例2
:
\color{#FFA5FF} \textbf{题例2}:
题例2:
假
设
有
三
种
天
气
状
态
(
晴
天
、
阴
天
、
下
雨
)
,
第
二
天
的
天
气
状
态
只
取
决
于
前
一
天
的
天
气
状
态
:
\color{#FFA5FF} \qquad 假设有三种天气状态(晴天、阴天、下雨),第二天的天气状态只取决于前一天的天气状态:
假设有三种天气状态(晴天、阴天、下雨),第二天的天气状态只取决于前一天的天气状态:
第
一
天
晴
天
,
第
二
天
:
晴
天
(
70
%
)
,
阴
天
(
20
%
)
,
下
雨
(
10
%
)
\color{#FFA5FF} \qquad\qquad 第一天晴天,第二天:晴天(70\%),阴天(20\%),下雨(10\%)
第一天晴天,第二天:晴天(70%),阴天(20%),下雨(10%)
第
一
天
阴
天
,
第
二
天
:
晴
天
(
40
%
)
,
阴
天
(
40
%
)
,
下
雨
(
20
%
)
\color{#FFA5FF} \qquad\qquad 第一天阴天,第二天:晴天(40\%),阴天(40\%),下雨(20\%)
第一天阴天,第二天:晴天(40%),阴天(40%),下雨(20%)
第
一
天
下
雨
,
第
二
天
:
晴
天
(
20
%
)
,
阴
天
(
40
%
)
,
下
雨
(
40
%
)
\color{#FFA5FF} \qquad\qquad 第一天下雨,第二天:晴天(20\%),阴天(40\%),下雨(40\%)
第一天下雨,第二天:晴天(20%),阴天(40%),下雨(40%)
(
1
)
.
今
天
是
晴
天
、
阴
天
、
下
雨
的
概
率
分
别
为
(
0.5
,
0.5
,
0
)
,
计
算
明
天
各
天
气
状
态
的
概
率
\color{#FFA5FF} \qquad (1).今天是晴天、阴天、下雨的概率分别为(0.5, 0.5, 0),计算明天各天气状态的概率
(1).今天是晴天、阴天、下雨的概率分别为(0.5,0.5,0),计算明天各天气状态的概率
(
2
)
.
今
天
是
晴
天
,
计
算
后
天
各
天
气
状
态
的
概
率
\color{#FFA5FF} \qquad (2).今天是晴天,计算后天各天气状态的概率
(2).今天是晴天,计算后天各天气状态的概率
解:
\color{#FF8080} \qquad \textbf{解:}
解:
状
态
转
移
矩
阵
P
=
(
0.7
0.2
0.1
0.4
0.4
0.2
0.2
0.4
0.4
)
\color{#FF8080} \qquad\qquad 状态转移矩阵P = \begin{pmatrix} 0.7 & 0.2 & 0.1\\ 0.4 & 0.4 & 0.2\\ 0.2 & 0.4 & 0.4\\ \end{pmatrix}
状态转移矩阵P=⎝⎛0.70.40.20.20.40.40.10.20.4⎠⎞
(
1
)
.
V
0
=
(
0.5
0.5
0
)
\color{#FF8080} \qquad\qquad(1).V_0 = \begin{pmatrix} 0.5& 0.5& 0 \end{pmatrix}
(1).V0=(0.50.50)
V
1
=
V
0
P
=
(
0.5
0.5
0
)
(
0.7
0.2
0.1
0.4
0.4
0.2
0.2
0.4
0.4
)
=
(
0.55
0.3
0.15
)
\color{#FF8080} \qquad\qquad\quad\;\; V_1 = V_0 P = \begin{pmatrix} 0.5 & 0.5 & 0 \end{pmatrix} \begin{pmatrix} 0.7 & 0.2 & 0.1\\ 0.4 & 0.4 & 0.2\\ 0.2 & 0.4 & 0.4\\ \end{pmatrix} = \begin{pmatrix} 0.55 & 0.3 & 0.15 \end{pmatrix}
V1=V0P=(0.50.50)⎝⎛0.70.40.20.20.40.40.10.20.4⎠⎞=(0.550.30.15)
(
2
)
.
V
0
=
(
1
0
0
)
\color{#FF8080} \qquad\qquad(2).V_0 = \begin{pmatrix} 1& 0& 0 \end{pmatrix}
(2).V0=(100)
V
2
=
V
0
P
2
=
(
1
0
0
)
(
0.7
0.2
0.1
0.4
0.4
0.2
0.2
0.4
0.4
)
2
=
(
0.59
0.26
0.15
)
\color{#FF8080} \qquad\qquad\quad\;\; V_2 = V_0 P^2 = \begin{pmatrix} 1 & 0 & 0 \end{pmatrix} {\begin{pmatrix} 0.7 & 0.2 & 0.1\\ 0.4 & 0.4 & 0.2\\ 0.2 & 0.4 & 0.4\\ \end{pmatrix}}^2 = \begin{pmatrix} 0.59 & 0.26 & 0.15 \end{pmatrix}
V2=V0P2=(100)⎝⎛0.70.40.20.20.40.40.10.20.4⎠⎞2=(0.590.260.15)
从
上
面
的
题
例
中
,
我
们
可
以
看
到
,
一
个
马
尓
可
夫
链
可
以
预
测
多
次
状
态
转
移
的
结
果
。
\color{#00A000} 从上面的题例中,我们可以看到,一个马尓可夫链可以预测多次状态转移的结果。
从上面的题例中,我们可以看到,一个马尓可夫链可以预测多次状态转移的结果。
但
是
随
着
转
移
次
数
的
增
加
,
某
些
状
态
的
概
率
可
能
会
越
来
越
小
,
因
此
我
们
需
要
加
一
些
约
束
。
\color{#00A000} 但是随着转移次数的增加,某些状态的概率可能会越来越小,因此我们需要加一些约束。
但是随着转移次数的增加,某些状态的概率可能会越来越小,因此我们需要加一些约束。
3、收敛和平稳条件
马
尔
可
夫
连
收
敛
和
平
稳
的
前
提
条
件
如
下
:
\color{#6666FF} 马尔可夫连收敛和平稳的前提条件如下:
马尔可夫连收敛和平稳的前提条件如下:
①
.
状
态
有
限
\color{#6666FF} \qquad ①.状态有限
①.状态有限
②
.
状
态
间
转
移
概
率
固
定
\color{#6666FF} \qquad ②.状态间转移概率固定
②.状态间转移概率固定
③
.
从
任
意
状
态
可
转
移
到
任
意
状
态
\color{#6666FF} \qquad ③.从任意状态可转移到任意状态
③.从任意状态可转移到任意状态
④
.
不
能
是
简
单
的
循
环
\color{#6666FF} \qquad ④.不能是简单的循环
④.不能是简单的循环
例
如
:
(
x
,
y
,
z
)
三
种
状
态
,
x
能
100
%
转
移
到
y
,
y
又
能
100
%
转
移
到
x
\color{#FFA5FF} \qquad\quad\; 例如:(x,y,z)三种状态,x能100\%转移到y,y又能100\%转移到x
例如:(x,y,z)三种状态,x能100%转移到y,y又能100%转移到x
三、马尓可夫奖励过程
马尔可夫过程 描 述 的 是 状 态 间 的 转 移 关 系 \color{#6666FF} \textbf{马尔可夫过程}描述的是状态间的转移关系 马尔可夫过程描述的是状态间的转移关系
在 各 个 状 态 的 转 移 过 程 中 赋 予 不 同 的 奖 励 值 , 就 得 到 了 马尔可夫奖励过程 \color{#6666FF} 在各个状态的转移过程中赋予不同的奖励值,就得到了\textbf{马尔可夫奖励过程} 在各个状态的转移过程中赋予不同的奖励值,就得到了马尔可夫奖励过程
马尔可夫奖励过程
可
以
用
一
个
四
元
组
(
S
,
P
,
R
,
γ
)
表
示
\color{#6666FF} \textbf{马尔可夫奖励过程}可以用一个四元组(S, P, R, \gamma)表示
马尔可夫奖励过程可以用一个四元组(S,P,R,γ)表示
其
中
\color{#6666FF} 其中
其中
S
—
—
状
态
集
合
\color{#6666FF} \qquad S——状态集合
S——状态集合
P
—
—
状
态
转
移
矩
阵
P
(
S
t
+
1
∣
S
t
)
\color{#6666FF} \qquad P——状态转移矩阵 \qquad P(S_{t+1} | S_t)
P——状态转移矩阵P(St+1∣St)
R
—
—
奖
励
函
数
R
(
S
)
=
E
(
R
t
+
1
∣
S
t
)
\color{#6666FF} \qquad R——奖励函数 \qquad\qquad R(S) = E(R_{t+1} | S_t)
R——奖励函数R(S)=E(Rt+1∣St)
e
g
:
在
之
前
的
天
气
示
例
中
,
不
同
的
天
气
会
给
人
不
同
的
心
情
状
态
(
奖
励
)
\color{#FFA5FF} \qquad\qquad eg: 在之前的天气示例中,不同的天气会给人不同的心情状态(奖励)
eg:在之前的天气示例中,不同的天气会给人不同的心情状态(奖励)
{
晴
天
+
2
阴
天
+
0
下
雨
−
1
\color{#FFA5FF} \qquad\qquad\qquad \begin{cases} 晴天 & +2 \\ 阴天 & +0 \\ 下雨 & -1 \\ \end{cases}
⎩⎪⎨⎪⎧晴天阴天下雨+2+0−1
γ
—
—
衰
减
因
子
γ
∈
[
0
,
1
]
\color{#6666FF} \qquad \;\gamma——衰减因子 \qquad\qquad \gamma \in [0, 1]
γ——衰减因子γ∈[0,1]
理
解
:
\color{#00A000} \qquad\qquad 理解:
理解:
举
个
例
子
:
\color{#FFA5FF} \qquad\qquad\qquad 举个例子:
举个例子:
“
2
天
后
得
到
100
元
”
和
“
35
天
后
得
到
100
元
”
,
我
们
往
往
会
认
为
他
们
的
价
值
是
不
同
的
\color{#FFA5FF} \qquad\qquad\qquad\qquad “2天后得到100元”和“35天后得到100元”,我们往往会认为他们的价值是不同的
“2天后得到100元”和“35天后得到100元”,我们往往会认为他们的价值是不同的
“
2
天
后
得
到
100
元
”
的
奖
励
值
可
能
是
γ
2
R
\color{#FFA5FF} \qquad\qquad\qquad\qquad “2天后得到100元”的奖励值可能是\gamma^2 R
“2天后得到100元”的奖励值可能是γ2R
而
“
35
天
后
得
到
100
元
”
的
奖
励
值
可
能
是
γ
35
R
\color{#FFA5FF} \qquad\qquad\qquad\qquad 而“35天后得到100元”的奖励值可能是\gamma^{35} R
而“35天后得到100元”的奖励值可能是γ35R
往
往
越
是
未
来
的
奖
励
,
它
们
的
价
值
就
越
低
\color{#00A000} \qquad\qquad\qquad 往往越是未来的奖励,它们的价值就越低
往往越是未来的奖励,它们的价值就越低
γ
值
设
置
越
大
,
衰
减
越
慢
,
表
示
一
个
人
更
在
乎
未
来
的
奖
励
\color{#AA66FF} \qquad\qquad \gamma值设置越大,衰减越慢,表示一个人更在乎未来的奖励
γ值设置越大,衰减越慢,表示一个人更在乎未来的奖励
γ
值
设
置
越
小
,
衰
减
越
快
,
表
示
一
个
人
更
在
乎
眼
前
的
奖
励
\color{#AA66FF} \qquad\qquad \gamma值设置越小,衰减越快,表示一个人更在乎眼前的奖励
γ值设置越小,衰减越快,表示一个人更在乎眼前的奖励
四、马尓可夫决策过程与强化学习
1、马尓可夫决策过程
马尔可夫决策过程
相
比
马尔可夫奖励过程
多
了
一
个
动
作
A
,
它
可
以
用
一
个
五
元
组
(
S
,
A
,
P
,
R
,
γ
)
表
示
\color{#6666FF} \textbf{马尔可夫决策过程}相比\textbf{马尔可夫奖励过程}多了一个动作A,它可以用一个五元组(S, A, P, R, \gamma)表示
马尔可夫决策过程相比马尔可夫奖励过程多了一个动作A,它可以用一个五元组(S,A,P,R,γ)表示
马尔可夫奖励过程
可
以
用
一
个
四
元
组
(
S
,
P
,
R
,
γ
)
表
示
\color{#6666FF} \textbf{马尔可夫奖励过程}可以用一个四元组(S, P, R, \gamma)表示
马尔可夫奖励过程可以用一个四元组(S,P,R,γ)表示
其
中
\color{#6666FF} 其中
其中
S
—
—
状
态
集
合
\color{#6666FF} \qquad S——状态集合
S——状态集合
A
—
—
动
作
集
合
(
决
策
过
程
集
合
)
\color{#6666FF} \qquad A——动作集合(决策过程集合)
A——动作集合(决策过程集合)
P
—
—
状
态
转
移
矩
阵
P
(
S
t
+
1
∣
S
t
,
A
t
)
\color{#6666FF} \qquad P——状态转移矩阵 \qquad P(S_{t+1} | S_t, A_t)
P——状态转移矩阵P(St+1∣St,At)
R
—
—
奖
励
函
数
R
(
S
)
=
E
(
R
t
+
1
∣
S
t
,
A
t
)
\color{#6666FF} \qquad R——奖励函数 \qquad\qquad R(S) = E(R_{t+1} | S_t, A_t)
R——奖励函数R(S)=E(Rt+1∣St,At)
γ
—
—
衰
减
因
子
γ
∈
[
0
,
1
]
\color{#6666FF} \qquad \;\gamma——衰减因子 \qquad\qquad \gamma \in [0, 1]
γ——衰减因子γ∈[0,1]
马尔可夫决策过程 是 强化学习 的 基 本 过 程 \color{#AA66FF} \textbf{马尔可夫决策过程}是\textbf{强化学习}的基本过程 马尔可夫决策过程是强化学习的基本过程
2、强化学习
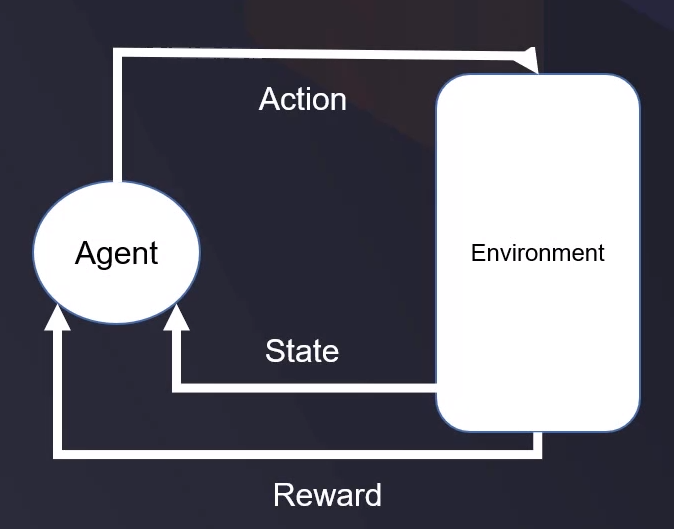
一 个 强 化 学 习 的 过 程 如 下 图 所 示 , 其 实 就 是 一 个 典 型 的 马 尓 可 夫 链 \color{#6666FF} 一个强化学习的过程如下图所示,其实就是一个典型的马尓可夫链 一个强化学习的过程如下图所示,其实就是一个典型的马尓可夫链
强
化
学
习
的
原
理
:
\color{#6666FF} 强化学习的原理:
强化学习的原理:
最
大
化
期
望
回
报
π
(
A
t
∣
S
t
)
,
相
应
的
结
果
就
是
找
到
从
状
态
空
间
S
映
射
到
动
作
空
间
A
的
最
优
策
略
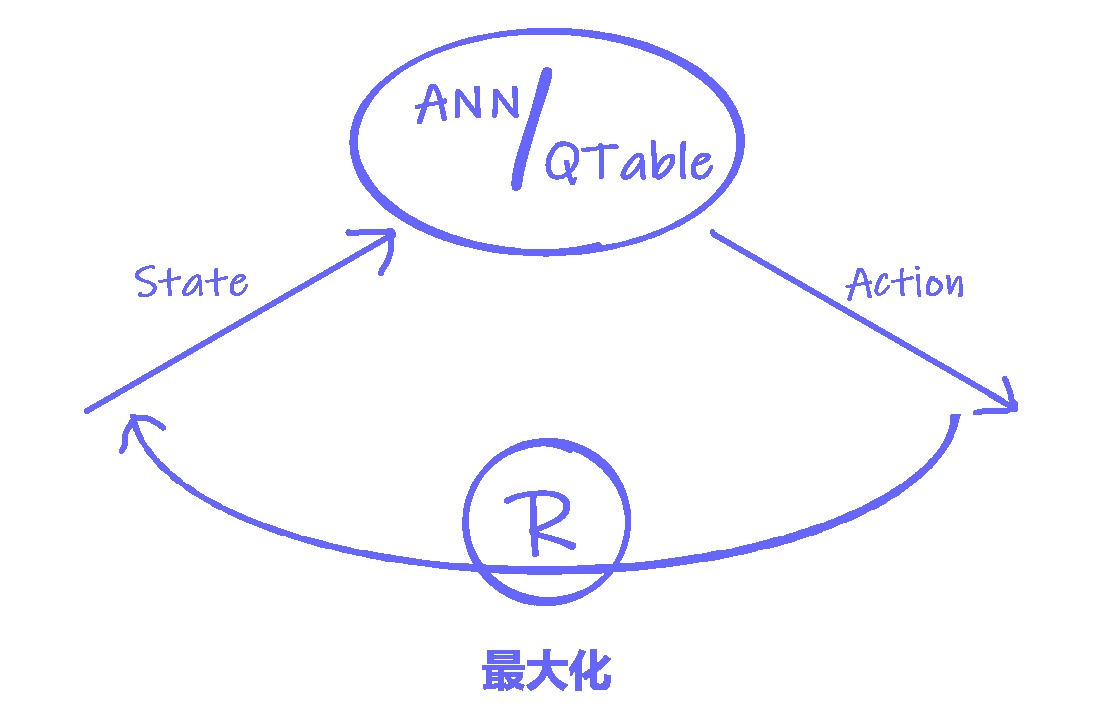
\color{#6666FF} \qquad 最大化期望回报\pi(A_t | S_t),相应的结果就是找到从状态空间S映射到动作空间A的最优策略
最大化期望回报π(At∣St),相应的结果就是找到从状态空间S映射到动作空间A的最优策略
示例3 : \color{#FFA5FF} \textbf{示例3}: 示例3:
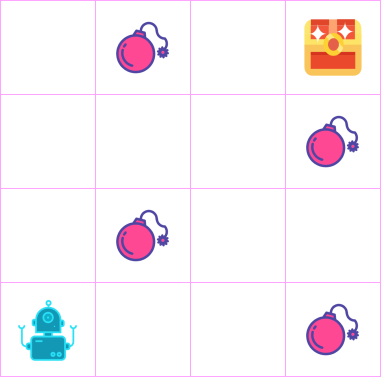
可以设置
 遇到-100
遇到-100
 遇到+100
遇到+100
随着不断的训练,可以优化模型
让模型找到最短的直接到达终点的路径
(最短是因为有衰减因子γ存在)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











