









 本文深入探讨了编译程序的基本概念、逻辑结构及其组织方式,包括编译程序的工作原理、编译基础设施介绍、编译程序的逻辑结构分析,并讨论了单遍与多遍编译程序的区别。
本文深入探讨了编译程序的基本概念、逻辑结构及其组织方式,包括编译程序的工作原理、编译基础设施介绍、编译程序的逻辑结构分析,并讨论了单遍与多遍编译程序的区别。
注:前言、目录见 https://blog.youkuaiyun.com/qq_44220418/article/details/108428971
文章目录
一、编译程序
1、编译程序
从基本功能来看,编译程序(Compiler)是一种翻译程序(Translator),可以将语言A的程序翻译为语言B的程序
其中
- 称语言A为源语言
- 称语言B为目标语言
编译程序是较为复杂的翻译程序
- 需要对源程序进行分析
识别源程序的语法结构信息,理解源程序的语义信息,反馈相应的出错信息 - 根据分析结果及目标信息进行综合
生成语义上等价于源程序的目标程序
编译程序通常是从较高级语言的程序翻译成为较低级语言的程序
2、编译基础设施
-
共享的编译程序研究 / 开发平台
- SUIF (Stanford)
- Zephyr (Virginia and Princeton )
- IMPACT, LLVM (UIUC)
- GCC (GNU Compiler Collection )
- Open64(SGI, 中科院计算所, Intel, HP, Delaware, 清华, …)
- …… 多源语言多目标机体系结构
-
如GCC,有C, C++, Objective C, Fortran, Ada, and Java ,…
等诸多前端,以及支持30多类体系结构、上百种平台的后端
多级中间表示
- 如 Open64 的中间表示语言 WHIRL 分5个级别
3、编译程序的逻辑结构
(1).两大阶段
编译程序逻辑结构上至少包含两大阶段 { 分析 阶 段 理 解 源 程 序 , 挖 掘 源 程 序 的 语 义 综合 阶 段 生 成 与 源 程 序 语 义 上 等 价 的 目 标 程 序 \begin{cases} \textbf{分析}阶段 & \small{理解源程序,挖掘源程序的语义} \\ \textbf{综合}阶段 & \small{生成与源程序语义上等价的目标程序} \end{cases} {分析阶段综合阶段理解源程序,挖掘源程序的语义生成与源程序语义上等价的目标程序
(2).前端、中端和后端
-
前端
- 实现主要的分析任务
- 通常以第一次生成中间代码为标志 中端
- 实现各级中间代码上的操作(中间代码生成与优化) 后端
- 实现主要的综合任务(目标代码生成和优化)
- 通常以从最后一级中间代码生成目标代码为标志
(3).逻辑过程
典型编译程序的逻辑过程如下如所示
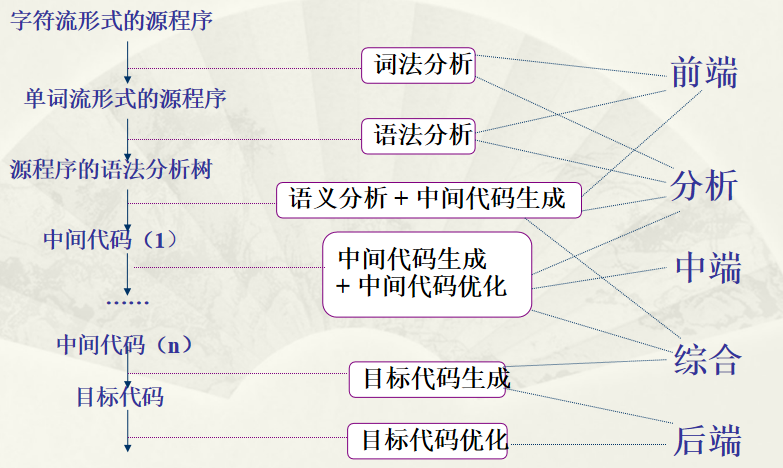
(4).主要逻辑模块
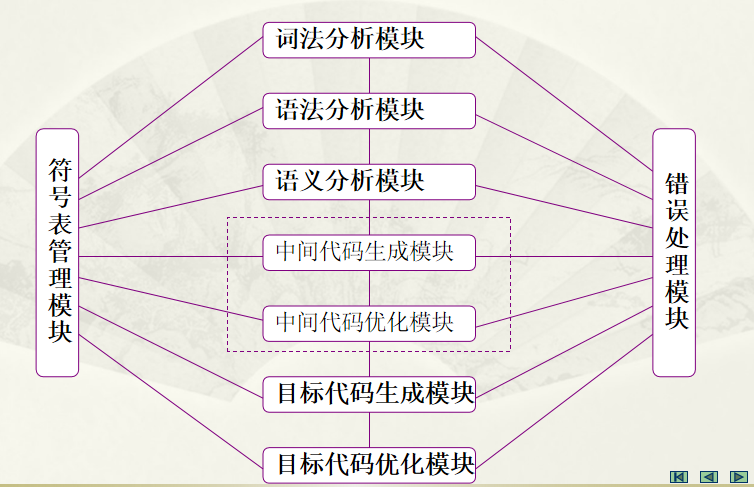
典型编译程序的主要逻辑模块如下图所示
(5).逻辑结构
-
词法分析
-
词法分析程序又称扫描程序
-
从左到右逐个字符地扫描源程序的字符,根据词法规则识别出具有独立意义的各个最小语法单位——符号(单词),并把它们转换成通常是等长的内部形式(属性字)
语法分析
-
语法分析程序又称识别程序
-
读入由词法分析程序识别出的符号,根据给定的语法规则,识别出各个语法结构,同时也检查了语法的正确性 { 若 存 在 语 法 错 误 则 给 出 相 应 的 出 错 信 息 若 无 语 法 错 误 则 生 成 另 一 种 内 部 表 示 , 如 语 法 分 析 树 或 其 他 中 间 表 示 \begin{cases} 若存在语法错误 & 则给出相应的出错信息 \\ 若无语法错误 & 则生成另一种内部表示,如语法分析树或其他中间表示 \end{cases} {若存在语法错误若无语法错误则给出相应的出错信息则生成另一种内部表示,如语法分析树或其他中间表示
语义分析
-
语义分析工作由一些语义子程序完成,这些语义子程序对语法分析树或其他内部中间表示进行静态语义检查并生成目标代码
-
四项功能 { 确 定 类 型 类 型 检 查 识 别 含 义 相 应 的 语 义 处 理 \begin{cases} 确定类型 \\ 类型检查 \\ 识别含义 \\ 相应的语义处理 \end{cases} ⎩⎪⎪⎪⎨⎪⎪⎪⎧确定类型类型检查识别含义相应的语义处理
符号表
-
收集每个名字的各种属性用于语义分析及后续各阶段
出错处理
-
{ 检 查 错 误 报 告 出 错 信 息 排 错 恢 复 编 译 工 作 \begin{cases} 检查错误 & 报告出错信息 \\ 排错 & 恢复编译工作 \end{cases} {检查错误排错报告出错信息恢复编译工作
中间代码生成
-
生成抽象语法树、四元式或三元式
目标代码生成
-
目标代码可以在语义分析时生成,如果语义分析的结果是中间表示代码,就必须把中间表示代码变换成等价的目标程序,即目标语言代码
4、编译程序的组织
-
遍(趟)
- 对一种代码形式从头到尾扫描一遍
- 将一个代码空间变换到另一个代码空间
- 代 码 空 间 = 代 码 + 符 号 表 + 其 他 有 用 信 息 代码空间 = 代码 + 符号表 + 其他有用信息 代码空间=代码+符号表+其他有用信息
- 编译程序可分为 { 单 遍 编 译 程 序 多 遍 编 译 程 序 \begin{cases} 单遍编译程序 \\ 多遍编译程序 \end{cases} {单遍编译程序多遍编译程序
-
-
e
g
1
:
eg1:
eg1:
一个以语法、语义分析程序为中心的单遍编译程序的组织如下图所示:
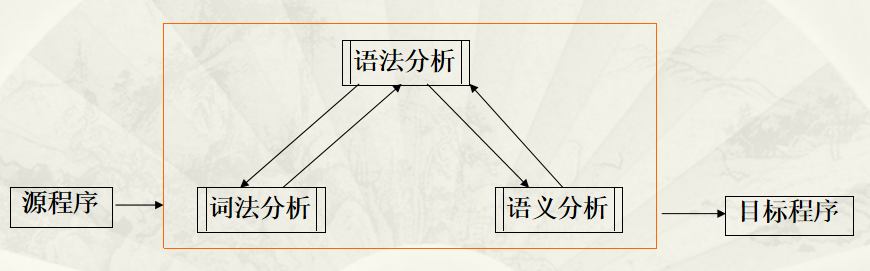
在上图所示的组织中,应以语法分析为主,将语法分析作为主函数。
需要一个单词时,调用词法分析模块去读源程序中的若干个字符构成一个单词反馈给语法分析模块。
当读取完一条语句后,语法分析模块判断是否出错,若无错则调用语义分析模块分析语义、生成目标代码。
Tips:因此,单遍编译程序需要控制好源程序文件读取的位置 -
-
e
g
2
:
eg2:
eg2:
一个多遍编译程序的组织如下图所示:上述编译程序其实经过了3遍扫描
5、编译程序的伙伴程序
(1).解释程序
-
解释程序
- 不产生目标程序文件(若要再次执行则需要再次解释一遍)
- 不区别翻译阶段和执行阶段
- 翻译源程序的每条语句后直接执行
- 程序执行期间一直有解释程序守候
- 常用于实现虚拟机
-
比较编译程序和解释程序
-
-
编译程序
-
-
-
-
解释程序
-
-
(2).预处理程序
-
解释程序
-
支持宏定义,
如C源程序的
#define -
支持文件包含,
如C源程序的
#include - 支持其他更复杂的源程序扩展信息
-
预处理程序和编译程序的关系
-
(3).汇编程序
-
汇编程序
- 翻译汇编语言程序至可重定位的机器语言程序
- Tips:机器语言程序的地址仍是相对地址(逻辑地址),将在装入和连接程序中进行重定位,将相对地址变换为机器绝对地址
(4).装入和连接程序
-
装入和连接程序
- 装入程序 对可重定位机器语言程序进行修改(地址重定位)
- 连接程序 合并多个可重定位机器语言程序文件到同一个程序
- 装入和连接程序 产生最终可执行的机器语言程序
(5).几种程序间的关系
6、编译程序与T型图
(1).T型图
可用T型图来表示一个编译程序,如下图所示:
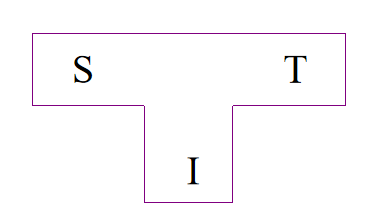
其中, { S 源 语 言 T 目 标 语 言 I 编 译 程 序 的 实 现 语 言 \begin{cases} \text{S} & 源语言 \\ \text{T} & 目标语言 \\ \text{I} & 编译程序的实现语言 \end{cases} ⎩⎪⎨⎪⎧STI源语言目标语言编译程序的实现语言
(2).本地编译器
本地编译器即用自己的机器语言书写一个编译器,把源语言转换成自己机器上能够运行的语言
其T型图如下图所示:

(3).交叉编译器
交叉编译器即用自己的机器语言书写一个编译器,把源语言转换成另一台机器上能够运行的语言
其T型图如下图所示:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











