









2021.1.2 16:00
刚出考场,心情沉重
考试前半小时,院表白墙有人发帖说
表白某老师,之前说不考试,后来又考
考啥也不明确
复习起来像开天辟地
评论区开始接龙“他甚至连天和地是啥都没说”
属实给我逗乐了
一、简答
1.大数据的全生命周期的各个阶段是什么,用疫情监测应用例子来描述。
2.(1)什么是EDA(Exploratory data analysis),探索性数据分析
(2)探索性数据分析的过程,以及与传统的统计分析的区别?
3.举例说明为什么传统的关系型数据库在web2.0的数据管理中很好的发挥作用?
二、分析
1.关系型数据库中的关系代数自然连接的mapreduce过程,写出map函数和reduce函数的逻辑过程
2.微博的数据用了redis存储,分为了关注表,粉丝表,互粉表
(1)说明这样设计的好处
(2)粉丝表的规模会很大,甚至上亿,是一个有序的set集合,如果查一个用户ID,遍历耗时严重,问怎么设计一个索引机制来快速查询一个ID是不是粉丝
三、计算
1.实体融合TF-IDF
一个文章里有1000个词,中国,软件,开发 这三个词的TF均为0.02。假设,网络上的网页一共250亿个,含有 中国的62.3亿,含有软件的0.484亿,含有开发的0.972亿。(数据有误差,不会差数量级)
(1)问三个词的IDF 和TF-IDF
(2)如果选一个词代表这个文章,选哪个
2.往年的题目
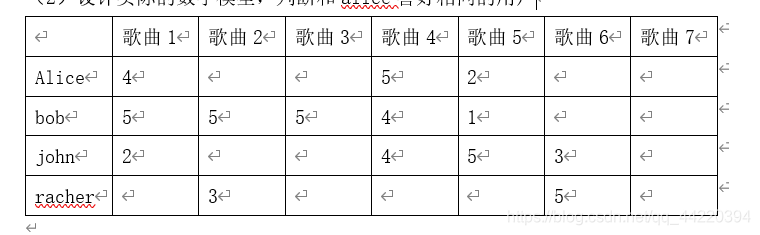
(1)画出二部图
(2)Alice除了音乐1 4 5之外,给他推荐哪首歌?试用随机游走进行验证,写出验证步骤


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









