






https://github.com/LetusRoll/IMM-UKF-JPDA-tracking/blob/main/src/JPDA_UKF_Tracking/src/UKF/UKF.h
源代码如上,结合了交互多模型和无迹卡尔曼滤波方法,应该是个优秀的轮子,为了整合进自己的项目,特此注释一些代码笔记如下,侵删。
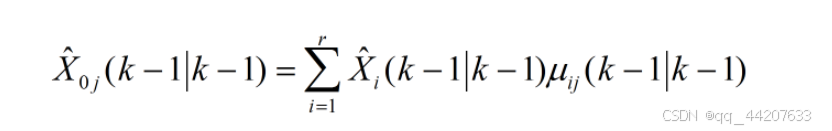
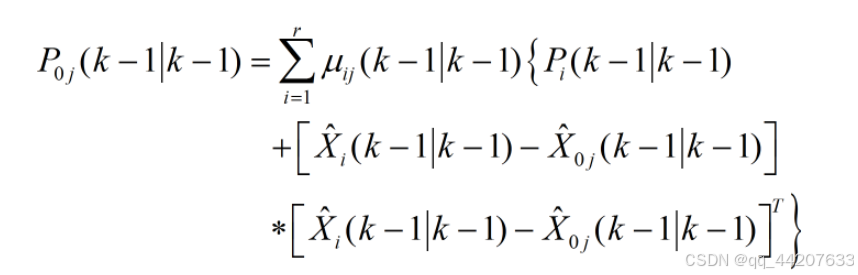
以上为IMM的模型协方差混合方程,产生对上一时刻模型j状态混合估计均值和协方差,导入各个子UKF滤波模块。
以CTRV模型为例,它在代码中的变量为X_ctrv,P_ctrv,至此输入UKF。
- X = X_ctrv;
- P = P_ctrv;
- X_sig.col(0) = X;
Eigen::MatrixXd P_sqrt = P.llt().matrixL();##似乎是计算矩阵的Cholesky分解,用完这里之后P就没用了
- for (int i = 1; i < state_num_ + 1; ++i)
- {
- X_sig.col(i) = X + sqrt(state_num_ + lambda) * P_sqrt.col(i - 1);
- X_sig.col(i)[3] = NormalizeAngle(X_sig.col(i)[3]);
- }
状态预测函数PredictMotion(const double dt, int mode)中,X_sig即无迹变换中k-1时刻状态的sigma采样点。k时刻的预测状态均值在CTRV(X_sig)中进行了计算,X_ctrv发生更新,已经变为状态sigma采样点在k时刻的预测值的均值,与UKF方法原公式中描述的相符。但是CTRV(X_sig)函数中似乎未对X_sig本身进行更新,因为一直没有出现在等式左边,这又与UKF精神不符。
- void UKF::CTRV(const Eigen::MatrixXd &X_sig, const double dt)
- {
- for (int i = 0; i < X_sig.cols(); ++i)
- {
- //防止分母为0
- if (fabs(X_sig(4, i)) > 0.001)
- {
- X_predict_sig_ctrv(0, i) = X_sig(0, i) + X_sig(2, i) / X_sig(4, i) * (sin(dt * X_sig(4, i) + X_sig(3, i)) - sin(X_sig(3, i))); //X
- X_predict_sig_ctrv(1, i) = X_sig(1, i) + X_sig(2, i) / X_sig(4, i) * (-cos(dt * X_sig(4, i) + X_sig(3, i)) + cos(X_sig(3, i))); //Y
- }
- else
- {
- X_predict_sig_ctrv(0, i) = X_sig(0, i) + X_sig(2, i) * dt * sin(X_sig(3, i)); //x
- X_predict_sig_ctrv(1, i) = X_sig(1, i) + X_sig(2, i) * dt * cos(X_sig(3, i)); //y
- }
- X_predict_sig_ctrv(2, i) = X_sig(2, i); //v
- X_predict_sig_ctrv(3, i) = X_sig(3, i) + dt * X_sig(4, i); //yaw
- X_predict_sig_ctrv(4, i) = X_sig(4, i); //dyaw
- X_predict_sig_ctrv(3, i) = NormalizeAngle(X_predict_sig_ctrv(3, i));
- X_ctrv += w_s(i) * X_predict_sig_ctrv.col(i);
- }
- X_ctrv(3) = NormalizeAngle(X_ctrv(3));
- }
(CTRV函数传入了一个X_sig引用,结果却对另外的变量进行了更新,挺神奇的写法)
以下为P_ctrv的更新。
- CTRV(X_sig, dt);##对k-1时刻X_sig采样点,根据模型前进一步推理得到k时刻的预测状态
- P_ctrv.fill(0);#本来是用来存储模型的初始混合协方差的,代表上一时刻k-1到当前时刻k的转移,之前已经用过它,这里就将它清空了,用来存储k时刻sigma点的预测方差
- Eigen::VectorXd diff = X_sig.col(i) - X_ctrv;##这里减的仍是未经状态预测的X_ctrv
- diff(3) = NormalizeAngle(diff(3));
- P_ctrv += w_c(i) * diff * diff.transpose();
(正确的更新应该是对采样点预测之后,再进行加权均值处理,如下图)
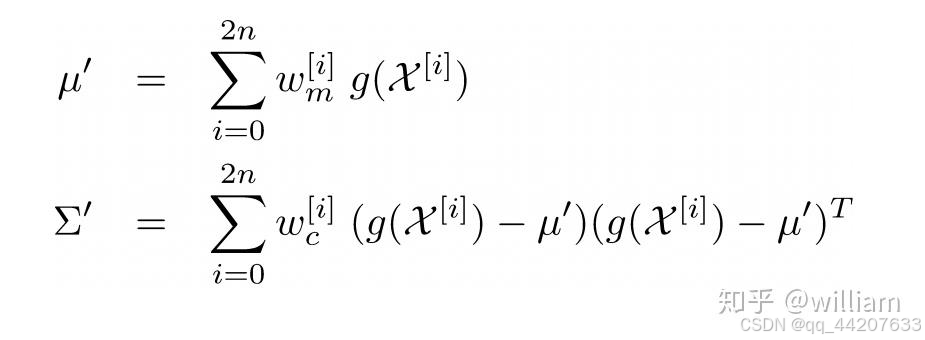
预测测量函数void UKF::PredictMeasurement(int mode)
对k时刻预测状态进行sigma采样,得到X_predict_meas_sig,不过这次没有对角度进行正则化,可能考虑到后续的观测方程也没用到角度,猜测是用了lidar的观测模型,这里用到的P_ctrv已经更新为k时刻预测sigma点拟合的方差了
- if (mode == Mode::CTRV)
- {
- X = X_ctrv;
- P = P_ctrv;
- }
- X_predict_meas_sig.col(0) = X;
- X_predict_meas_sig.col(0) = X;
- Eigen::MatrixXd P_sqrt = P.llt().matrixL();
- for (int i = 1; i < state_num_ + 1; ++i)
- {
- X_predict_meas_sig.col(i) = X + sqrt(state_num_ + lambda) * P_sqrt.col(i);
- }
- for (int i = state_num_ + 1; i < 2 * state_num_ + 1; ++i)
- {
- X_predict_meas_sig.col(i) = X - sqrt(state_num_ + lambda) * P_sqrt.col(i - state_num_ - 1);
- }
直接赋值给了Z_sig,应该是代表对当前k时刻预测状态的预测状态观测,只取了x,y,可能是采用了Lidar的线性观测模型。(反思:既然这一步是是线性的,为何还要用无迹变换呢)
- for (int i = 0; i < 2 * state_num_ + 1; ++i)
- {
- Z_sig(0, i) = X_predict_meas_sig(0, i); //x
- Z_sig(1, i) = X_predict_meas_sig(1, i); //y
- }
- Z_sigma_ctrv = Z_sig;
- for (int i = 0; i < 2 * state_num_ + 1; ++i)
- {
- Z_predict_ctrv += w_s(i) * Z_sigma_ctrv.col(i);
- }
- S_ctrv.fill(0);
- for (int i = 0; i < 2 * state_num_ + 1; ++i)
- {
- Eigen::VectorXd diff = Z_sigma_ctrv.col(i) - Z_predict_ctrv;
- S_ctrv += w_c(i) * diff * diff.transpose();
- }
- S_ctrv += R_ctrv;
更新了预测观测的均值Z_predict_ctrv和方差(似乎见到有种说法叫“新息”)S_ctrv
以上就是UKF中比较关键的观测和预测了,主要是明白了IMM到UKF的接口是X_ctrv和P_ctrv;
----------------------------------------------- ----(手动分割线)-------------------------------------------------------
进入IMM环节的学习,首先经过考证,有理由认为该代码的交互矩阵计算出错
void UKF::MixProbability()
{
Eigen::VectorXd sum = Eigen::VectorXd(3);
sum << initial_mode_trans_prob(0, 0) * mode_prob(0) + initial_mode_trans_prob(0, 1) * mode_prob(0) + initial_mode_trans_prob(0, 2) * mode_prob(0),
initial_mode_trans_prob(1, 0) * mode_prob(1) + initial_mode_trans_prob(1, 1) * mode_prob(1) + initial_mode_trans_prob(1, 2) * mode_prob(1),
initial_mode_trans_prob(2, 0) * mode_prob(2) + initial_mode_trans_prob(2, 1) * mode_prob(2) + initial_mode_trans_prob(2, 2) * mode_prob(2);
for (int i = 0; i < mode_trans_prob.rows(); ++i)
{
for (int j = 0; j < mode_trans_prob.cols(); ++j)
{
mode_trans_prob(i, j) = initial_mode_trans_prob(i, j) * mode_prob(i) / sum(i);
}
}
} 此处sum的计算出错,sum={Cj}其中即对当前模型j,遍历所有的模型i到当前模型j的可能性。而源代码中的写法,显然变成了
即对当前模型i,遍历当前模型i到其他所有模型j的可能性。读者可以仔细理解这两句话的区别,前者是收,后者是放。前者可以表示当前模型的先验概率,而后者不知道表示什么意思。
源代码写法会导致sum的中每一项都可以提出一个公因数mode_prob(j),从而导致mode_trans_prob(i,j)=initial_mode_trans_prob*mode_prob(i)/sum(i)的更新中,实际上会分子分母同时约掉一个mode_prob(i),导致mode_trans_prob(i,j)=initial_mode_trans_prob*mode_prob(i)/mode_prob(i),从而失去更新意义,变成常数项。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









