







什么是覆盖索引?
理解方式一:索引是高效找到行的一个方法,但是一般数据库也能使用索引找到一个列的数据,因此它不必读取整个行。毕竟索引叶子节点存储了它们索引的数据;当能通过读取索引就可以得到想要的数据,那就不需要读取行了。一个索引包含了满足查询结果的数据就叫做覆盖索引;
理解方式二:非聚簇复合索引的一种形式,它包括在查询里的SELECT、JOIN和WHERE子句用到的所有列(即建索引的字段正好是覆盖查询条件中所涉及的字段);
简单来说就是,索引列+主键 包含 SELECT 到 FROM之间查询的列;
覆盖索引的利弊
- 避免Innodb表进行索引的二次查询(回表)
Innodb是以聚集索引的顺序来存储的,对于Innodb来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据,在查找到相应的键值后,还需通过主键进行二次查询才能获取我们真实所需要的数据。在覆盖索引中,二级索引的键值中可以获取所要的数据,避免了对主键的二次查询,减少了IO操作,提升了查询效率。
- 把随机IO变成顺序IO加快查询效率
由于覆盖索引是按键值的顺序存储的,对于I0密集型的范围查找来说,对比随机从磁盘读取每一行的数据IO要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的IO转变成索引查找的顺序IO。由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
弊端:索引字段的维护总是有代价的。因此,在建立冗余索引来支持覆盖索引时就需要权衡考虑;
前缀索引
在varchar字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据实际文本区分度决定索引长度。
说明:索引的长度与区分度是一对矛盾体,一般对字符串类型数据,长度为20的索引,区分度会高达90%以上,可以使用count(distinct left(列名,索引长度)/count(*)的区分度来确定。
使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本。区分度越高越好,因为区分度越高,意味着重复的键值越少。
前缀索引对覆盖索引的影响
结论: 使用前缀索引就用不上覆盖索引对查询性能的优化了;
什么是索引下推?
索引下推(Index Condition Pushdown,简称ICP),是MySQL5.6版本的新特性,它能减少回表查询次数,提高查询效率;
使用ICP扫描的过程
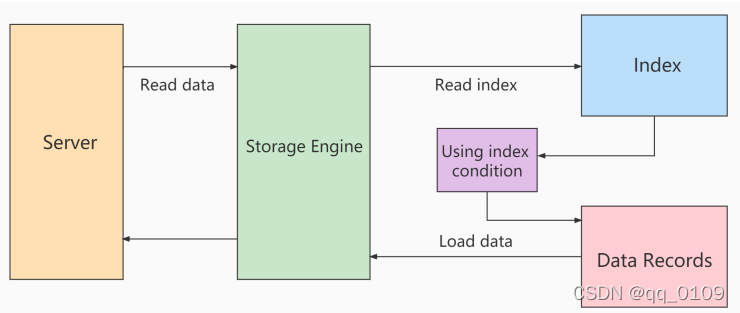
- storage 层
首先将index key条件满足的索引记录区间确定,然后在索引上使用index filter进行过滤。将满足的index filter条件的索引记录才去回表取出整行记录返回server层。不满足index filter条件的索引记录丢弃,不回表、也不会返回server层;
- server 层
对返回的数据,使用table filter条件做最后的过滤;
ICP的使用条件
- 只能用于二级索引(secondary index);
- explain显示的执行计划中type值(join 类型)为 range 、 ref 、 eq_ref 或者 ref_or_null ;
- 并非全部where条件都可以用ICP筛选,如果where条件的字段不在索引列中,还是要读取整表的记录 到server端做where过滤;
- ICP可以用于MyISAM和InnnoDB存储引擎;
- MySQL 5.6版本的不支持分区表的ICP功能,5.7版本的开始支持;
- 当SQL使用覆盖索引时,不支持ICP优化方法;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









