






前言
Ultravox 是一种新型的多模态语言模型,能够理解文本以及语音,无需单独的音频语音识别(ASR)阶段。基于像AudioLM、SeamlessM4T、Gazelle、SpeechGPT等研究,Ultravox 能够使用多模态投影扩展任何开放权重的语言模型,该投影将音频直接转换为语言模型使用的高维空间。我们已经在 Llama 3、Mistral 和 Gemma 上训练了版本。这种直接耦合使得 Ultravox 比结合单独的 ASR 和语言模型组件的系统响应速度快得多。在未来,这也将使 Ultravox 能够原生地理解在人类语音中无处不在的时间和情感的副语言线索。
仓库地址:https://github.com/fixie-ai/ultravox
简单来说,Ultravox通过一个投影层,对齐音频和文本特征,冻结音频编码器和大模型的参数,只训练投影层的参数
这种做法在VLM中也很常见。
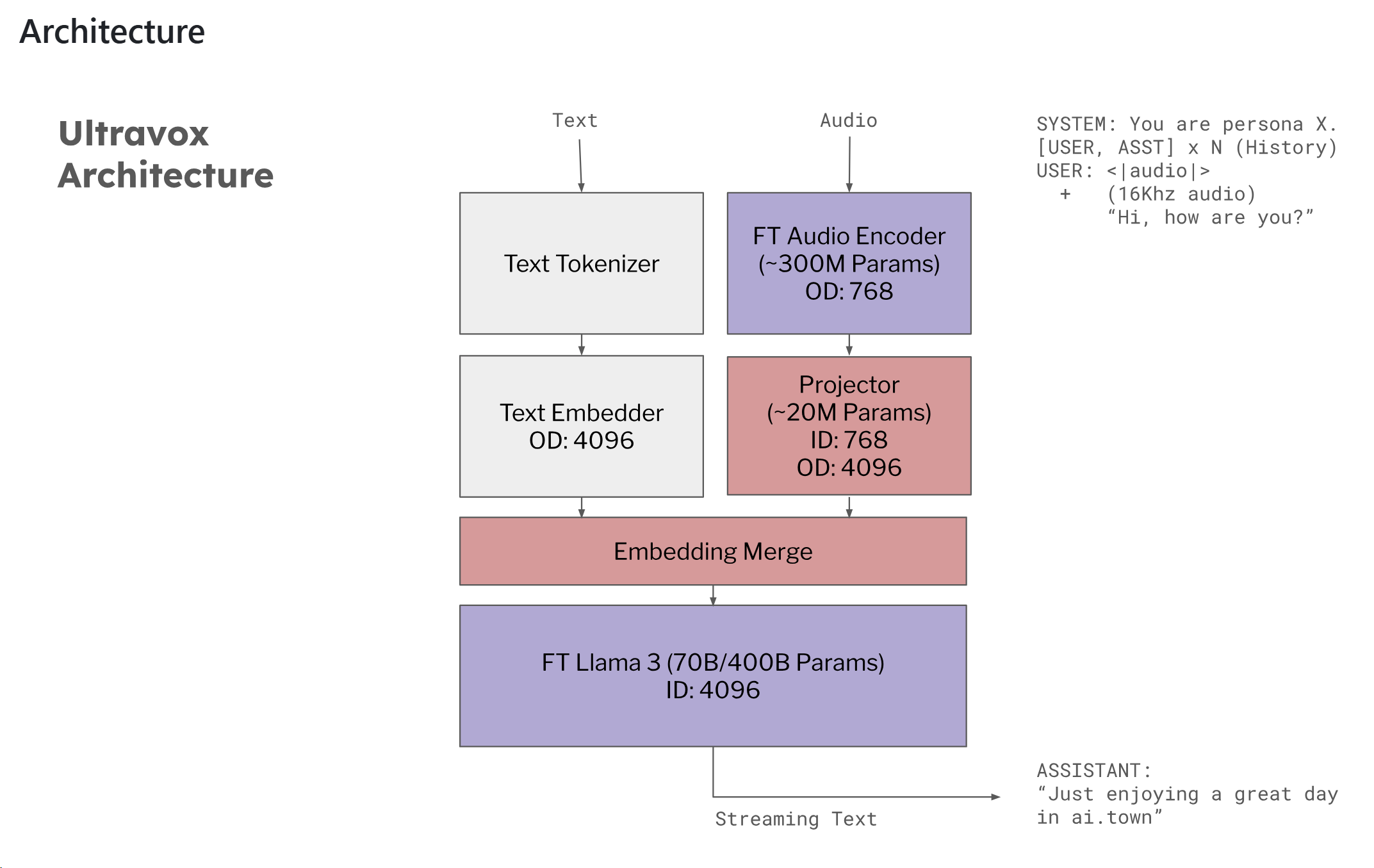
音频模型为whisper-medium、LLM为Qwen2.5-7B-Instruct的模型结构
UltravoxModel(
(audio_tower): ModifiedWhisperEncoder(
(conv1): Conv1d(80, 1024, kernel_size=(3,), stride=(1,), padding=(1,))
(conv2): Conv1d(1024, 1024, kernel_size=(3,), stride=(2,), padding=(1,))
(embed_positions): Embedding(1500, 1024)
(layers): ModuleList(
(0-23): 24 x WhisperEncoderLayer(
(self_attn): WhisperSdpaAttention(
(k_proj): Linear(in_features=1024, out_features=1024, bias=False)
(v_proj): Linear(in_features=1024, out_features=1024, bias=True)
(q_proj): Linear(in_features=1024, out_features=1024, bias=True)
(out_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
(self_attn_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(activation_fn): GELUActivation()
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(final_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
(layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
(multi_modal_projector): UltravoxProjector(
(_pad_and_stack): StackAudioFrames()
(ln_pre): RMSNorm((8192,), eps=1e-06)
(linear_1): Linear(in_features=8192, out_features=4096, bias=False)
(act): SwiGLU()
(linear_2): Linear(in_features=2048, out_features=3584, bias=False)
(ln_mid): RMSNorm((2048,), eps=1e-06)
(ln_post): Identity()
)
(language_model): Qwen2ForCausalLM(
(model): Qwen2Model(
(embed_tokens): Embedding(152064, 3584)
(layers): ModuleList(
(0-27): 28 x Qwen2DecoderLayer(
(self_attn): Qwen2Attention(
(q_proj): Linear(in_features=3584, out_features=3584, bias=True)
(k_proj): Linear(in_features=3584, out_features=512, bias=True)
(v_proj): Linear(in_features=3584, out_features=512, bias=True)
(o_proj): Linear(in_features=3584, out_features=3584, bias=False)
)
(mlp): Qwen2MLP(
(gate_proj): Linear(in_features=3584, out_features=18944, bias=False)
(up_proj): Linear(in_features=3584, out_features=18944, bias=False)
(down_proj): Linear(in_features=18944, out_features=3584, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Qwen2RMSNorm((3584,), eps=1e-06)
(post_attention_layernorm): Qwen2RMSNorm((3584,), eps=1e-06)
)
)
(norm): Qwen2RMSNorm((3584,), eps=1e-06)
(rotary_emb): Qwen2RotaryEmbedding()
)
(lm_head): Linear(in_features=3584, out_features=152064, bias=False)
)
)
由于官方只开源了几个基于Llama 3、Mistral 和 Gemma 训练的模型,这些模型对中文的处理都不是很好,因此,为了提升在中文上表现,基于中文LLM训练一个Ultravox是一个比较好的选择。
通过这篇文章,你能掌握如何训练一个中文版的ultravox。
接下来,我们进入正题
一、环境安装
我的机器是ubuntu,其它环境请看官方教程
1、安装just
sudo apt update
sudo apt install snapd
sudo snap install just --classic
2、安装环境
git clone https://github.com/fixie-ai/ultravox.git
cd ultravox
just install
二、准备数据与模型
export HF_ENDPOINT=https://hf-mirror.com
git lfs install
git clone https://hf-mirror.com/openai/whisper-large-v3-turbo
git clone https://www.modelscope.cn/Qwen/Qwen2.5-7B-Instruct.git
huggingface-cli download --repo-type dataset --resume-download fixie-ai/covost2 --local-dir datasets --local-dir-use-symlinks False
我这里只用fixie-ai/covost2这一个数据集,因此只下这一个就好了,其它数据集,在https://huggingface.co/fixie-ai都可以找到
注意:如果不把数据集下到本地的话,训练过程中会自行从huggingface中下载,而且网络不稳定,会导致整个训练流程非常慢,建议还是下载到本地。
三、修改对应代码及配置
当我们使用本地模型和本地数据集时,也需要修改对应的代码
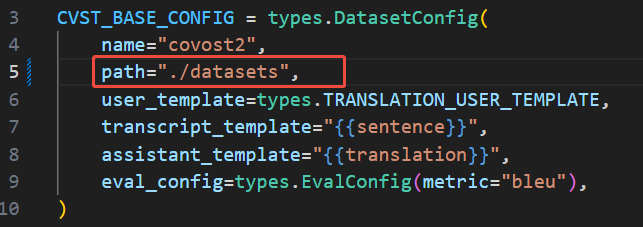
第一处: ultravox/data/configs/covost2.py 将图中的path参数改为数据集的路径,我的数据在datasets文件夹下
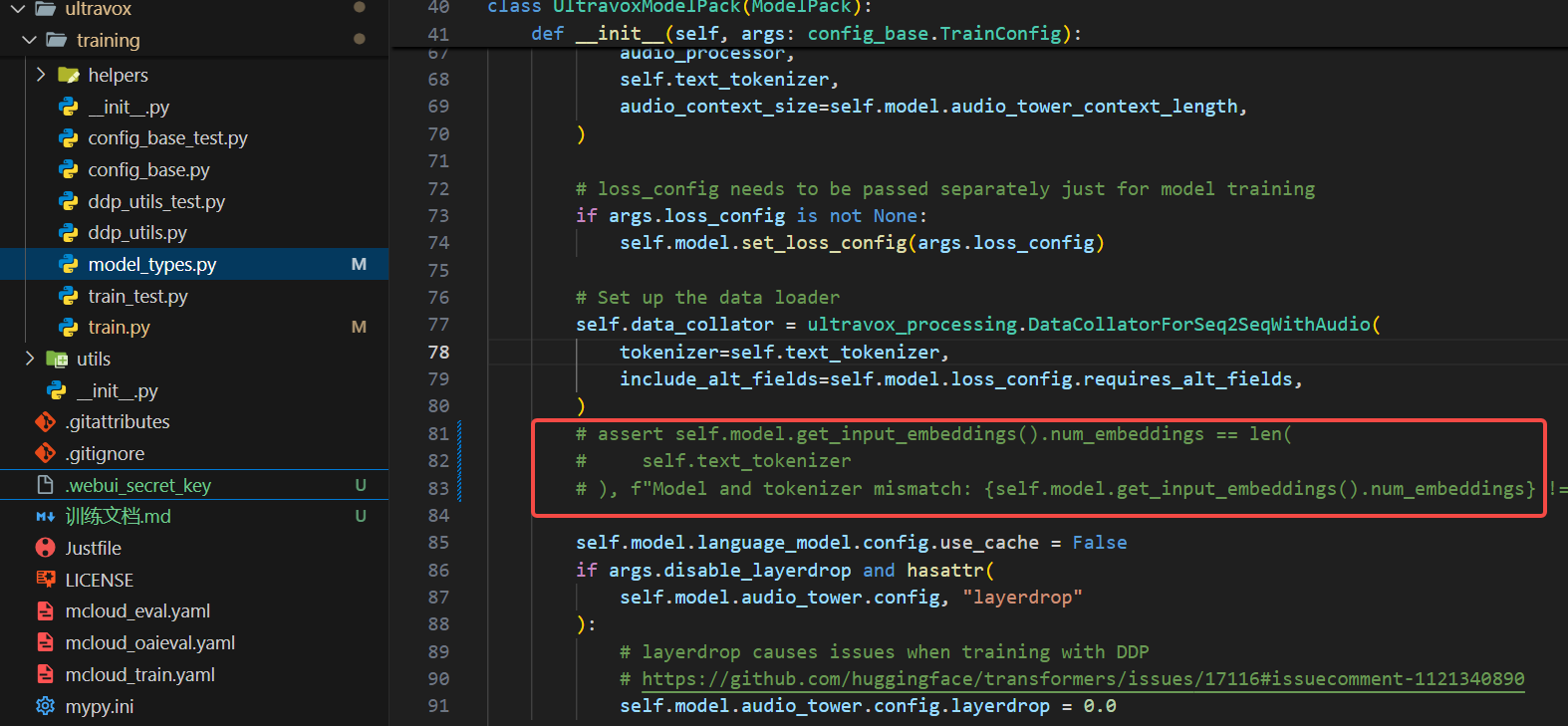
**第二处:**注释ultravox/training/model_types.py的81-83行,如图所示。
这是因为Qwen2.5的embedding size != vocab_size,llama模型二者是相等的
具体的原因可以在https://github.com/QwenLM/Qwen2.5/issues/147找到。
实际作用不大,不必纠结
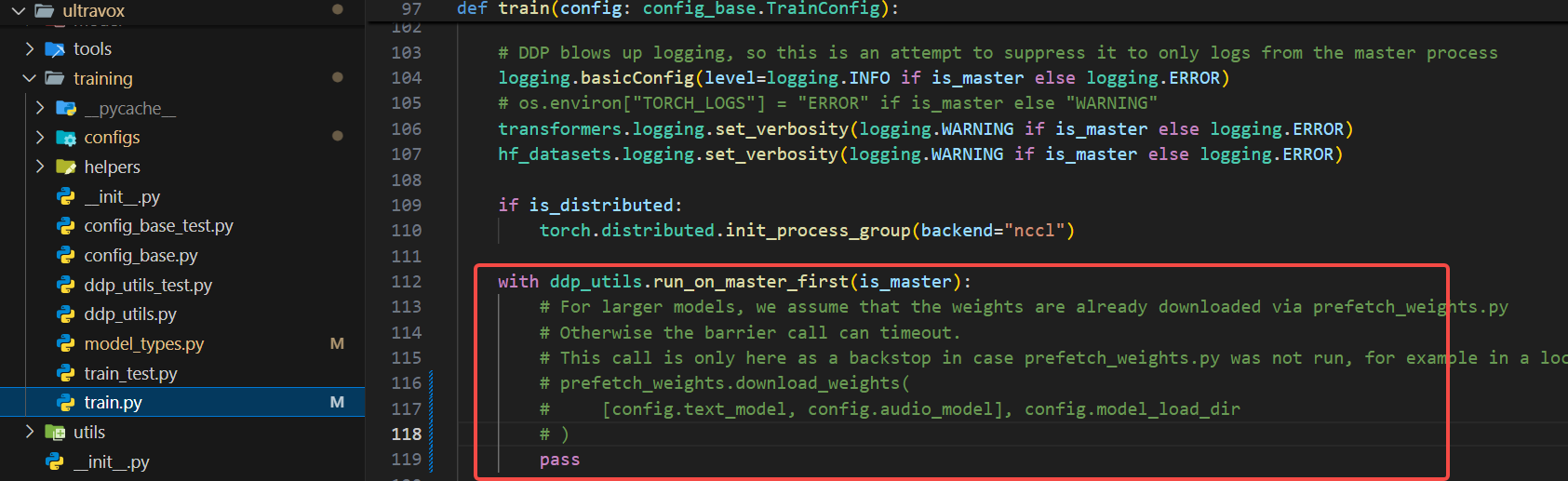
第三处: ultravox/training/train.py直接注释112-118行或者按如下图修改也行,这一处,主要是根据传入的model id下载对应的模型,我们前面已经都将模型下载到本地了,所以可以忽略此处
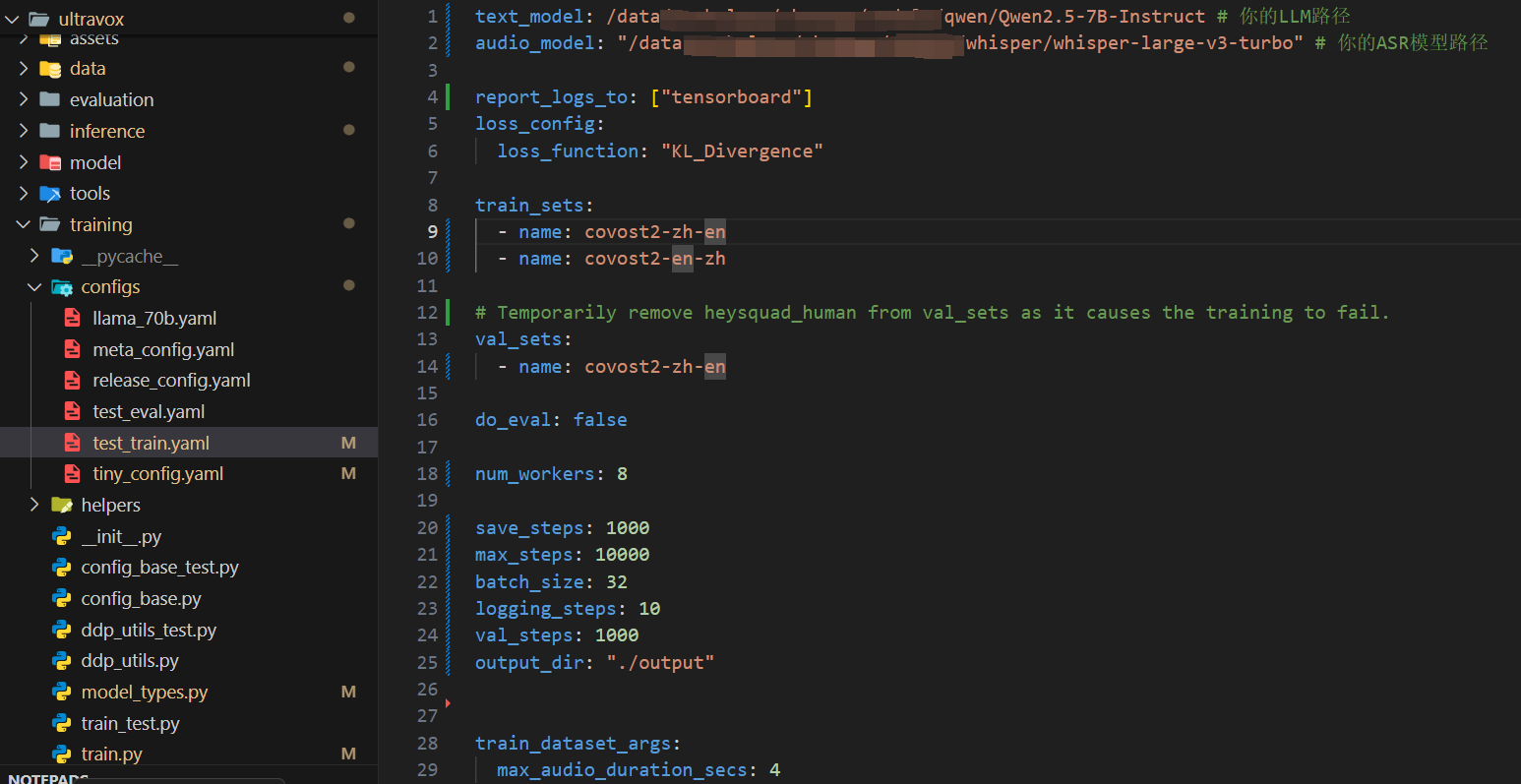
最后一步 修改配置文件,将text_model,audio_model 修改为自己下好的本地模型的路径
都修改好后,我们就可以开始训练了
四、训练Ultravox
单卡
cd ultravox
python ultravox/training/train.py --config ultravox/training/configs/test_train.yaml
多卡
cd ultravox
torchrun --nproc_per_node=2 ultravox/training/train.py --config ultravox/training/configs/test_train.yaml
不出意外的话,应该成功开始训练了

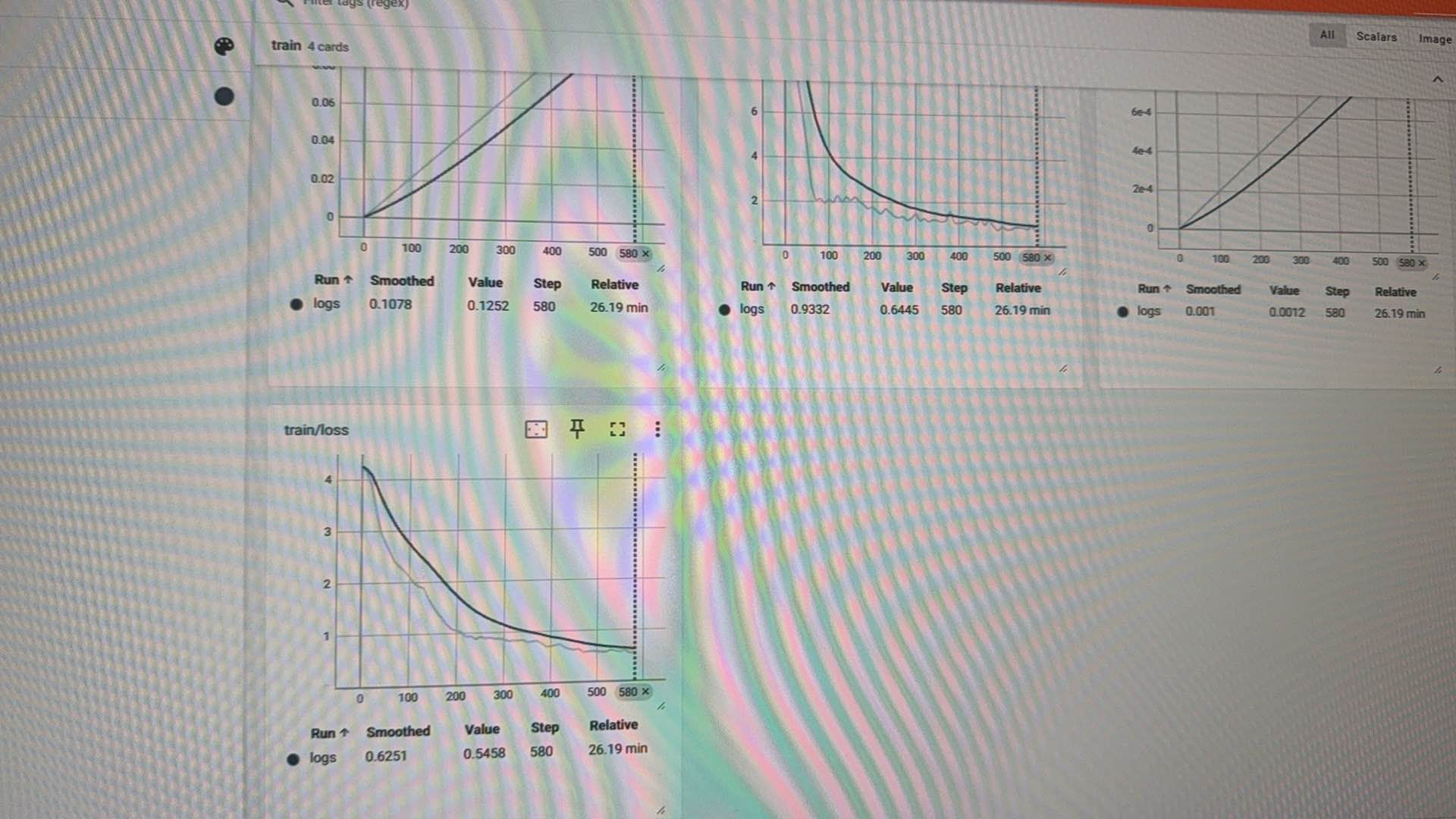
我296515 条数据,whisper medium + qwen2.5 7B 训练了8小时,2个epoch, batch size 32,两张A100
loss如下:
五、推理
vllm是支持ultravox的,但是你换了其它底座的LLM后,部署时会报错。
所以,最后只能用ultravox仓库中的gradio demo部署,代码路径ultravox/tools/gradio_demo.py
部署命令
python ultravox/tools/gradio_demo.py --model_path ./output/checkpoint-10000
中文效果好非常多。
对大模型感兴趣的同学,可以关注我的公众号:AI算法之门。
随机更新文章
商业合作请联系WX



















 290
290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











