







 本文详细介绍了C++11的新特性,包括列表初始化、auto和decltype关键字、nullptr、范围for等。重点讲解了右值引用和移动语义,还提及新的类功能、可变参数模版、lambda表达式和包装器等内容,让C++更现代化、灵活和易用。
本文详细介绍了C++11的新特性,包括列表初始化、auto和decltype关键字、nullptr、范围for等。重点讲解了右值引用和移动语义,还提及新的类功能、可变参数模版、lambda表达式和包装器等内容,让C++更现代化、灵活和易用。
文章目录

C++11新特性
1、C++11简介
C++11 是 C++ 语言的一个重要版本,它于 2011 年发布。在此之前,C++ 的最新标准是 C++03,自 2003 年发布以来,C++ 缺乏了许多现代编程语言的特性和功能。因此,C++ 社区开始呼吁更新 C++ 标准以适应现代编程需求。
在 C++11 发布之前,有几个候选提案被提出并讨论,其中包括称为 TR1(Technical Report 1)的技术报告,它包含了许多库扩展,这些扩展后来成为了 C++ 标准库的一部分。此外,还有一些针对语言核心和语法的提案,例如 lambda 表达式、自动类型推导、范围-based for 循环等。
C++11 标准于 2011 年 8 月由 ISO(国际标准化组织)正式发布。它引入了许多重要的新特性和改进,使得 C++ 更加现代化、灵活和易用。这些特性和改进包括自动类型推导、范围-based for 循环、lambda 表达式、右值引用和移动语义、智能指针、新的标准库特性等。
C++11 的发布标志着 C++ 语言的重大进步,为开发者提供了更强大的工具和功能,使得 C++ 成为一种更加适用于现代软件开发的编程语言。自此以后,C++ 标准委员会开始采取更加积极的态度,定期发布新的 C++ 标准,以满足不断发展的编程需求和技术挑战。
2、列表初始化
2.1、{}列表初始化
C++11 引入了初始化列表,即使用大括号
{}进行初始化的语法。这种初始化方式可以用于初始化各种类型的对象,包括基本数据类型、数组、结构体、类对象以及标准库容器等。使用大括号
{}进行初始化的好处是,它提供了一种统一的初始化语法,可以简化代码,并且在某些情况下可以避免一些常见的问题,例如窄化转换和不明确的初始化。C++98的时候,也有
{}初始化,但是当时只支持数组初始化。int array1[] = {1, 2, 3, 4, 5};现在C++11 还支持基本数据类型、结构体、类对象以及标准库容器等对象的初始化。并且还可以省略赋值符号
=。struct Point { int _x; int _y; }; // {} 列表初始化 int main() { int array1[] = {1, 2, 3, 4, 5}; int array2[]{1, 2, 3, 4, 5}; int array3[5] = {0}; Point p1 = {1, 2}; Point p2{1, 2}; return 0; }class Date { public: Date(int year, int month, int day) : _year(year), _month(month), _day(day) { cout << "Date(int year, int month, int day)" << endl; } private: int _year; int _month; int _day; }; int main() { Date d1(2022, 1, 1); // old style // C++11支持的列表初始化,这里会调用构造函数初始化 Date d2{2022, 1, 2}; Date d3 = {2022, 1, 3}; // 隐式类型转换 构造+拷贝构造 = 构造 Date *d4 = new Date[3]{d1, d2, d3}; Date *d5 = new Date[3]{{2022, 1, 2}, {2022, 1, 2}, {2022, 1, 2}}; // 构造+拷贝构造 = 构造 return 0; }
2.2、initializer_list
2.2.1、initializer_list的介绍
此类型用于访问C++初始化列表中的值,该列表是const T类型元素的列表。
这种类型的对象由编译器从初始化列表声明中自动构建,初始化列表声明是用大括号括起来的逗号分隔元素列表:
auto il = { 10, 20, 30 }; // il的类型是initializer_list请注意,此模板类不是隐式定义的,即使该类型是隐式使用的,也应包含头文件<initializer_list>来访问它。
initializer_list对象会自动构建,就像分配了T类型元素的数组一样,列表中的每个元素都被复制初始化为数组中的相应元素,使用任何必要的非窄隐式转换(不能权限缩小)。
Initializer_list对象引用此数组的元素,但不包含它们:复制Initializer_list对象会产生另一个对象,该对象引用相同的基础元素,而不是它们的新副本(引用语义)。
此临时数组的生命周期与Initializer_list对象相同。
只接受此类型的一个参数的构造函数是一种特殊类型的构造函数,称为Initializer_list构造函数。当使用Initializer_list构造函数语法时,Initializer_list构造函数优先于其他构造函数:
struct myclass { myclass (int,int); myclass (initializer_list<int>); /* definitions ... */ }; myclass foo {10,20}; // calls initializer_list ctor myclass bar (10,20); // calls first constructor
2.2.2、initializer_list的使用
initializer_list一般是用来做构造函数的参数,C++11大部分容器都有initializer_list做其构造函数的参数,这样初始化容器对象就更方便了。也可以作为operator=的参数,这样就可以用大括号赋值。
// initializer_list<T> int main() { // the type of il is an initializer_list auto il = {10, 20, 30}; // initializer_list<T>的 构造 + 拷贝构造 = 构造 vector<int> v = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; for (auto e: v) { cout << e << " "; } cout << endl; // initializer_list<T>的赋值 v = {1, 2, 3}; for (auto e: v) { cout << e << " "; } cout << endl; char i = 1; cout << typeid(il).name() << endl; cout << typeid(i).name() << endl; // 打印类型 pair<string, string> kv1("sort", "排序"); pair<string, string> kv2("insert", "插入"); map<string, string> dict1 = {kv1, kv2}; // pair<string,string> 拷贝构造 pair<const string,string> map<string, string> dict2 = {{"sort", "排序"}, {"insert", "插入"}};// pair<const char* ,const char*>拷贝构造 pair<string,string> // 因为pair的拷贝构造是带模版参数的,不强制类型一样,但是得能正确赋值 return 0; }
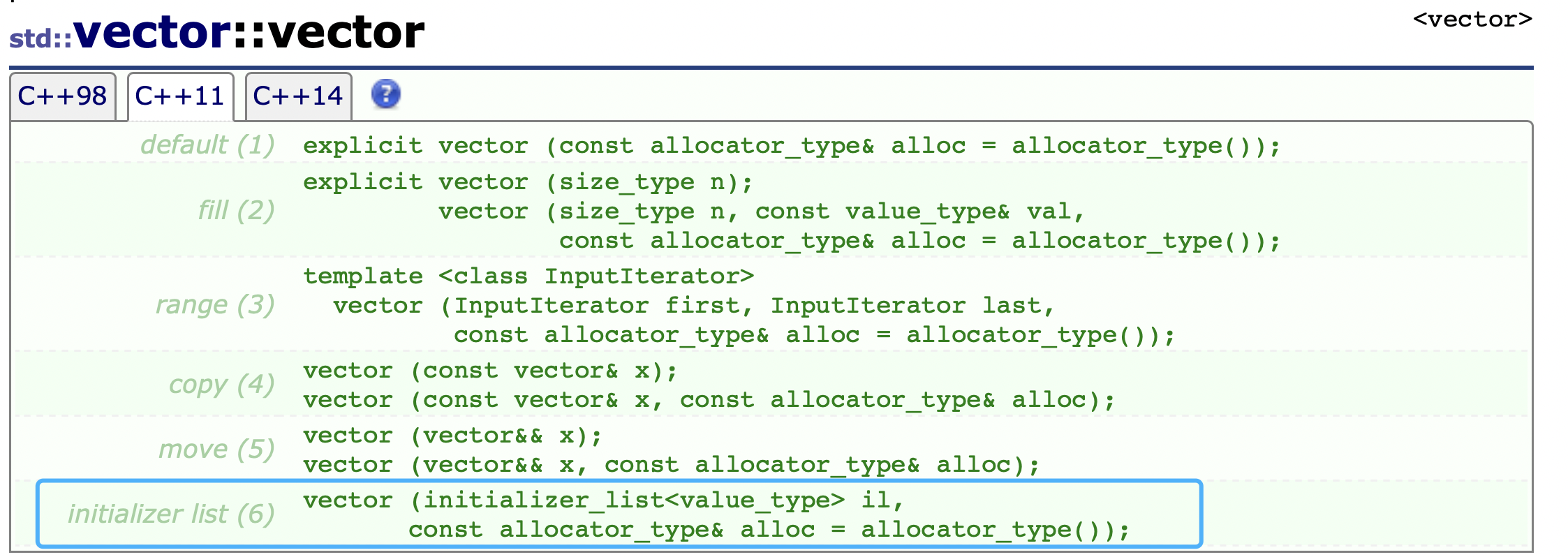


3、auto关键字
C++11中的auto关键字,可以用来推导类型。这样要求必须进行显示初始化,让编译器将定义对象的类型设置为初始化值的类型。
支持在范围for(也是C++11新特性)中使用。
// auto类型推导 -- 不推荐做返回值 int main() { int i = 10; auto p = &i; auto pf = strcpy; cout << typeid(p).name() << endl; cout << typeid(pf).name() << endl; map<string, string> dict = {{"sort", "排序"}, {"insert", "插入"}}; //map<string, string>::iterator it = dict.begin(); auto it = dict.begin(); for(auto& e : dict){ cout << e.first << " " << e.second << endl; } return 0; }
4、decltype关键字
关键字decltype将变量的类型声明为表达式指定的类型。也就是获取一个变量的类型来作为另外的变量的类型。
// decltype的一些使用使用场景 template<class T1, class T2> void F(T1 t1, T2 t2) { decltype(t1 * t2) ret; cout << typeid(ret).name() << endl; } int main() { const int x = 1; double y = 2.2; decltype(x * y) ret; // ret的类型是double decltype(&x) p; // p的类型是int* cout << typeid(ret).name() << endl; cout << typeid(p).name() << endl; F(1, 'a'); return 0; }
5、nullptr
由于C++中NULL被定义成字面量0,这样就可能回带来一些问题,因为0既能指针常量,又能表示整形常量。所以出于清晰和安全的角度考虑,C++11中新增了nullptr,用于表示空指针。
#ifndef NULL #ifdef __cplusplus #define NULL 0 #else #define NULL ((void *)0) #endif #endif
6、范围for
在STL中我们已经使用过很多次范围for,其实其底层就是调用迭代器来实现的。
int main() { map<string, string> dict = {{"sort", "排序"}, {"insert", "插入"}}; for(auto& e : dict){ cout << e.first << " " << e.second << endl; } return 0; }
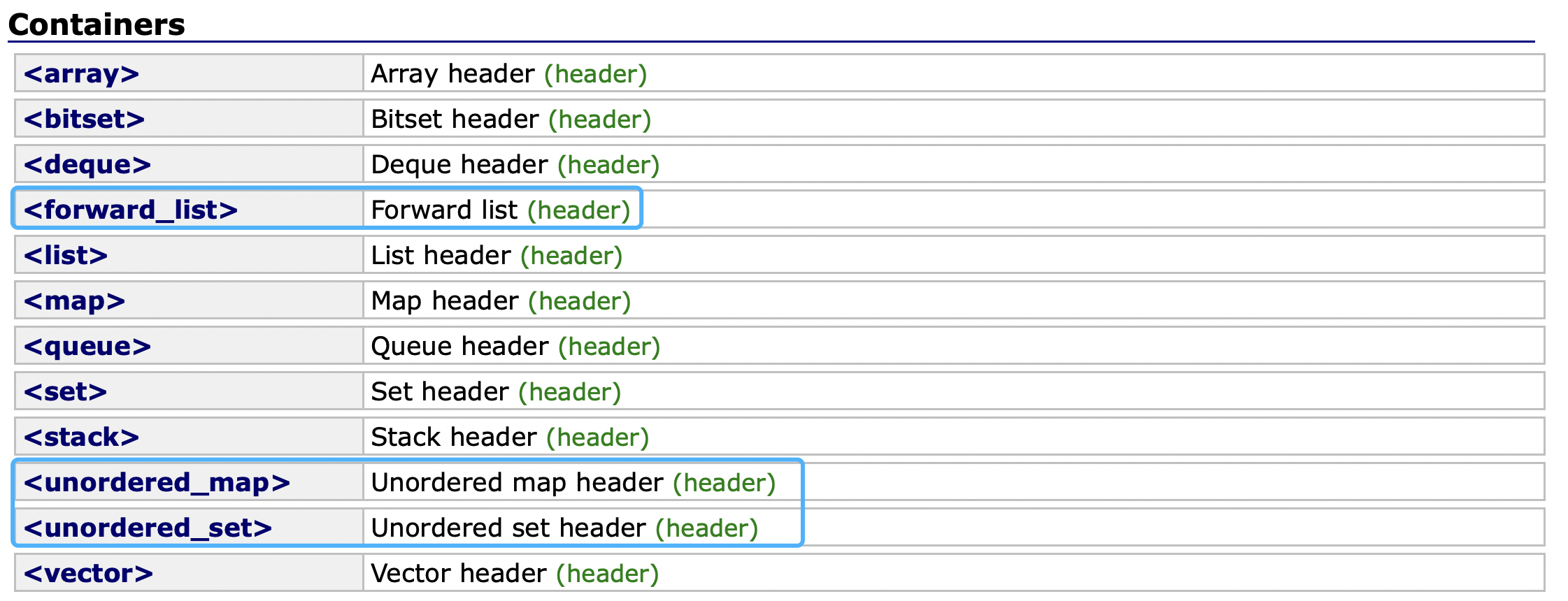
7、STL中新增的容器
forward_list是单链表,支持头插头删,和尾插尾删,只支持在当前结点的后面插入和删除,比较鸡肋。
unordered_map和unordered_set都是我们学过的,它们的底层都是哈希表。这里不再解释。
实际上C++11更新后,容器中增加的新方法最后用的插入接口函数的右值引用版本。
下面讲解右值引用。

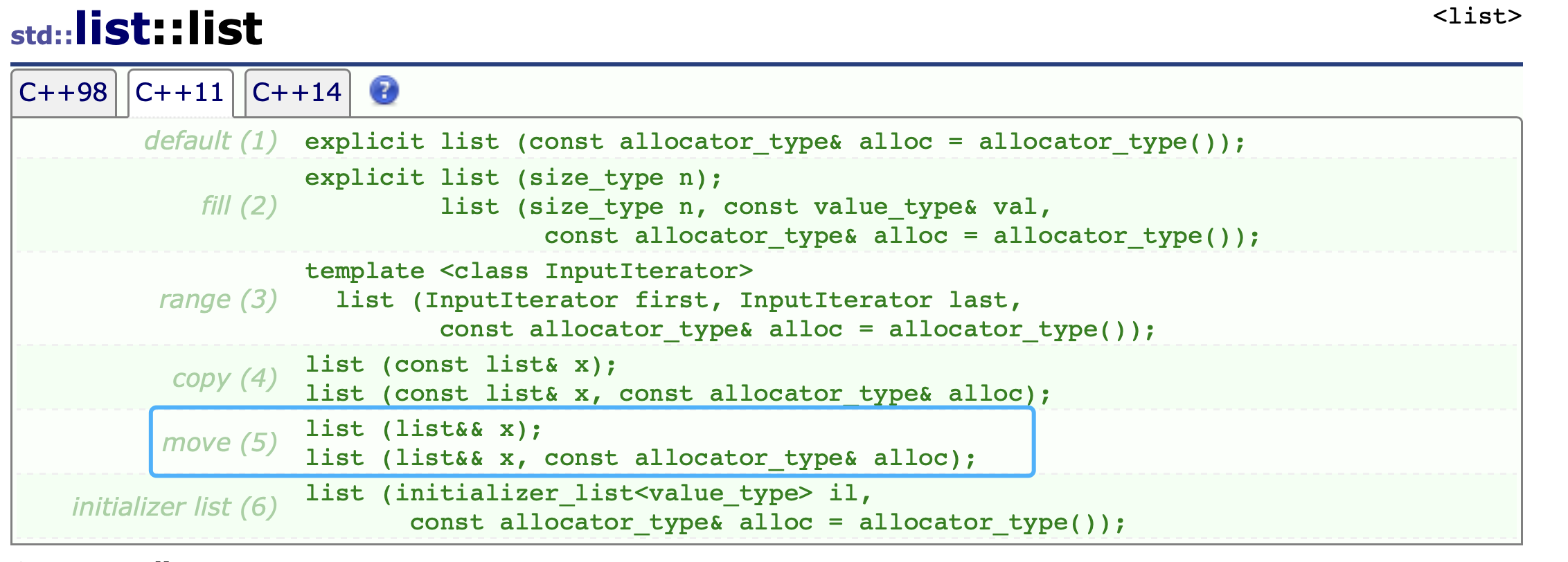

8、右值引用和移动语义
重点
8.1、左值和左值引用
左值:左值是可以放在赋值操作符(=)的左边的表达式,因为它们具有地址,可以在内存中存储。左值可以是变量、数组元素或对象的成员等。
左值引用:就是可以给左值的引用,即左值的别名。
// 返回右值 // 右值是指不能被修改的临时值,它们通常是表达式的结果或者临时对象。 int funcr() { static int ret = 1; return ret; } // 返回左值 // 左值是可以放在赋值操作符(=)的左边的表达式,因为它们具有地址,可以在内存中存储。左值可以是变量、数组元素或对象的成员等。 int &funcl() { static int ret = 1; return ret; } // 左值及左值引用 // 左值:可以取地址 int main() { // 以下的p、b、c、*p都是左值 int *p = new int(0); int b = 1; const int c = 2; // int* res1 = &funcr(); // 因为返回值是临时对象 int *res2 = &funcl(); // 以下几个是对上面左值的左值引用 int *&rp = p; int &rb = b; const int &rc = c; int &pvalue = *p; int *&pres2 = res2; return 0; }
8.2、右值和右值引用
右值:右值是指不能被修改的临时值,它们通常是表达式的结果或者临时对象。右值也有地址,但是右值并不具有持久性。右值是临时的、短暂存在的值,可能是表达式的结果或者临时对象。因此右值通常不能取地址,因为它们可能不存储在内存中的具体位置,或者即使存在,也没有持久性。
右值引用:就是给右值的引用,即给右值取别名。
// 右值是指不能被修改的临时值,它们通常是表达式的结果或者临时对象。 int main() { double x = 1.1, y = 2.2; // 以下几个都是常见的右值 10; x + y; funcr(); // 以下几个都是对右值的右值引用 int &&rr1 = 10; double &&rr2 = x + y; double &&rr3 = funcr(); // 这里编译会报错:error C2106: “=”: 左操作数必须为左值 // 10 = 1; // x + y = 1; // funcr() = 1; return 0; }需要注意的是右值是不能取地址的,但是给右值取别名后,会导致右值被存储到特定位置,且可以取到该位置的地址,也就是右值引用的属性是左值。
int main() { double x = 1.1, y = 2.2; int &&rr1 = 10; // 不能修改10的值,但可以修改rr1的值 const double &&rr2 = x + y; rr1 = 20; // rr2 = 5.5; // 报错 return 0; }
8.3、左值引用和右值引用对比
左值引用总结:左值引用只能引用左值,不能引用右值。但是const左值引用可以引用左值,也可以引用右值。
int main() { // 左值引用只能引用左值,不能引用右值。 int a = 10; int &ra1 = a; // ra为a的别名 //int& ra2 = 10; // 编译失败,因为10是右值 // const左值引用既可引用左值,也可引用右值。 const int &ra3 = 10; const int &ra4 = a; // ra3 = 1; // ra4 = 1; return 0; }右值引用总结:右值引用只能引用右值,不能引用左值。但是右值引用可以引用move以后的左值。
int main() { // 右值引用只能右值,不能引用左值。 int &&r1 = 10; // error C2440: “初始化”: 无法从“int”转换为“int &&” // message : 无法将左值绑定到右值引用 int a = 10; // int &&r2 = a; // 右值引用可以引用move以后的左值 int &&r3 = move(a); return 0; }
8.4、左值引用使用场景
做参数和做返回值都可以提高效率。
namespace xp { class string { public: typedef char *iterator; iterator begin() { return _str; } iterator end() { return _str + _size; } string(const char *str = "") : _size(strlen(str)), _capacity(_size) { //cout << "string(char* str)" << endl; _str = new char[_capacity + 1]; strcpy(_str, str); } // s1.swap(s2) void swap(string &s) { ::swap(_str, s._str); ::swap(_size, s._size); ::swap(_capacity, s._capacity); } // 拷贝构造 -- 没有写右值引用的拷贝构造的时候,左值和右值的拷贝构造都走这个const string& string(const string &s) : _str(nullptr) { cout << "string(const string& s) -- 深拷贝" << endl; string tmp(s._str); swap(tmp); } // 赋值重载 string &operator=(const string &s) { cout << "string& operator=(string s) -- 深拷贝" << endl; string tmp(s); swap(tmp); return *this; } ~string() { delete[] _str; _str = nullptr; } char &operator[](size_t pos) { assert(pos < _size); return _str[pos]; } void reserve(size_t n) { if (n > _capacity) { char *tmp = new char[n + 1]; strcpy(tmp, _str); delete[] _str; _str = tmp; _capacity = n; } } void push_back(char ch) { if (_size >= _capacity) { size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2; reserve(newcapacity); } _str[_size] = ch; ++_size; _str[_size] = '\0'; } //string operator+=(char ch) string &operator+=(char ch) { push_back(ch); return *this; } const char *c_str() const { return _str; } private: char *_str; size_t _size; size_t _capacity; // 不包含最后做标识的\0 }; string to_string(int value) { bool flag = true; if (value < 0) { flag = false; value = 0 - value; } string str; while (value > 0) { int x = value % 10; value /= 10; str += ('0' + x); } if (flag == false) { str += '-'; } std::reverse(str.begin(), str.end()); return str; } } void func1(xp::string s) {} void func2(const xp::string &s) {} int main() { xp::string s1("hello world"); // func1和func2的调用我们可以看到左值引用做参数减少了拷贝,提高效率的使用场景和价值 func1(s1); // 这里调用拷贝构造函数 ,用s1拷贝构造处理一个副本来初始化s func2(s1); // string operator+=(char ch) 传值返回存在深拷贝 // string& operator+=(char ch) 传左值引用没有拷贝提高了效率 s1 += '!'; return 0; }但是,有时候函数返回局部变量,就是会存在拷贝的问题,使用左值引用(不能引用临时对象)也解决不了问题。这时候就需要右值引用。如下面右值引用使用场景。
8.5、右值引用使用场景
前面有说道const左值引用既可以引用左值也可以引用右值,那么为什么C++11还要增加右值引用?
我们来看以下代码:
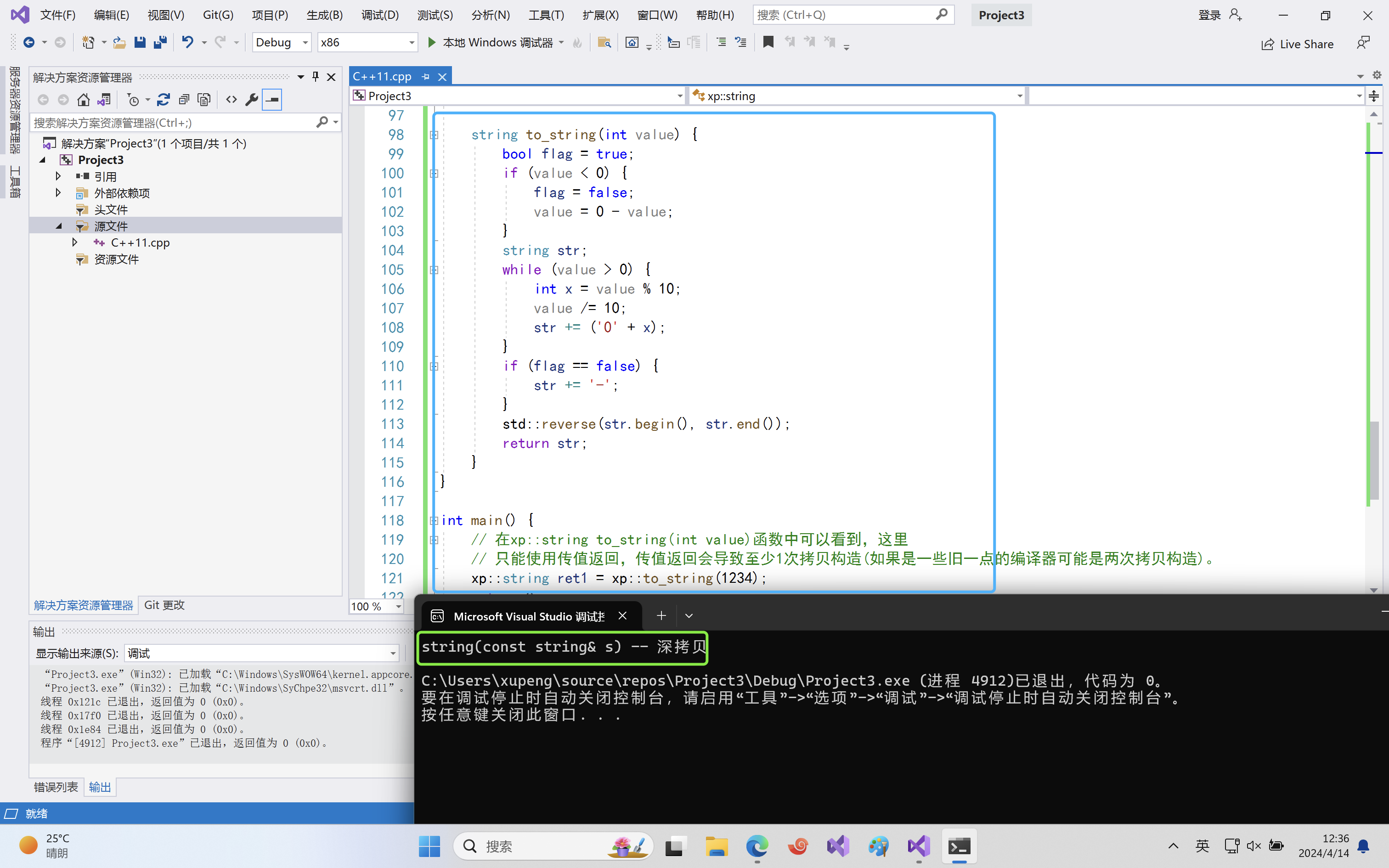
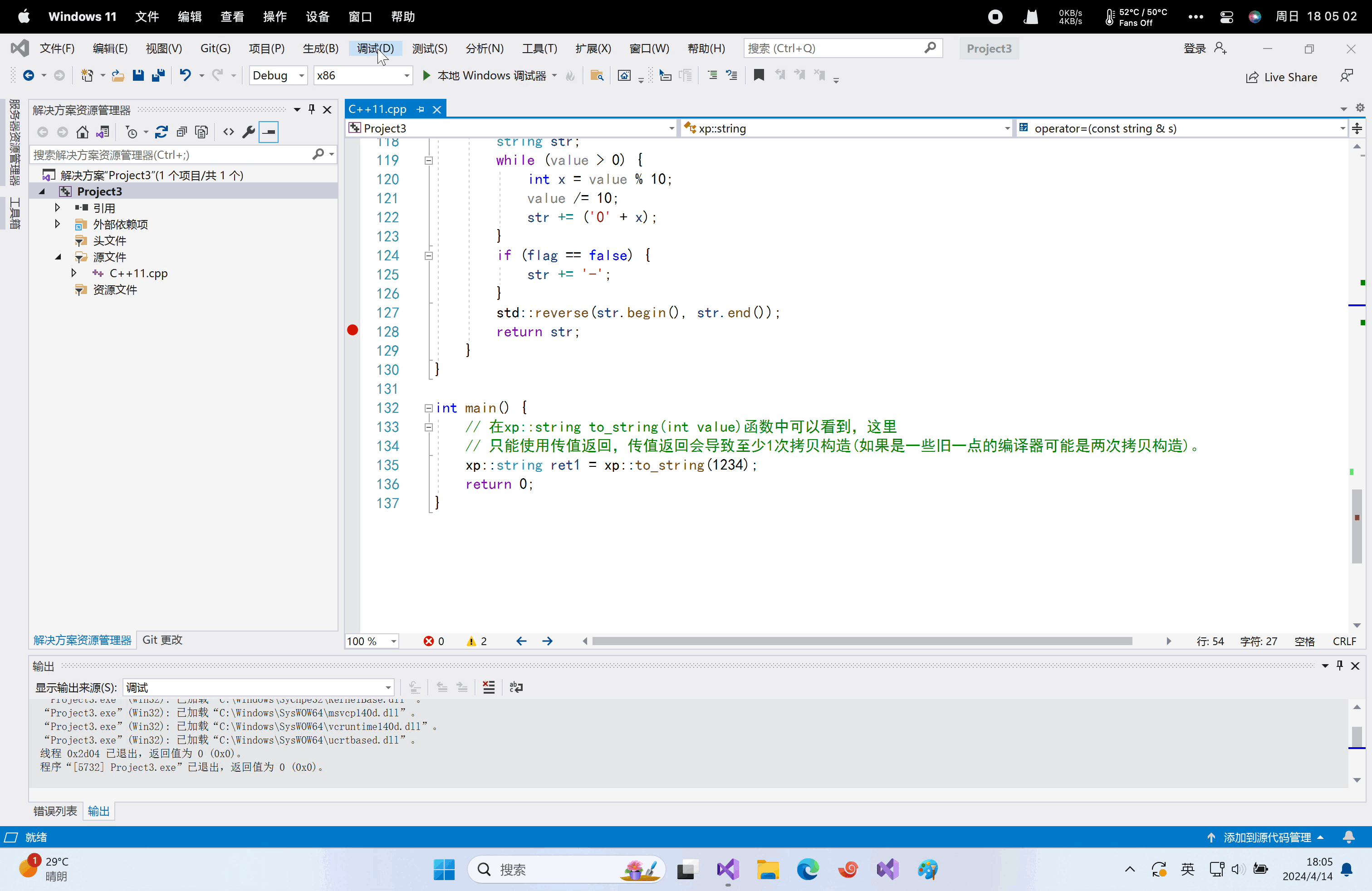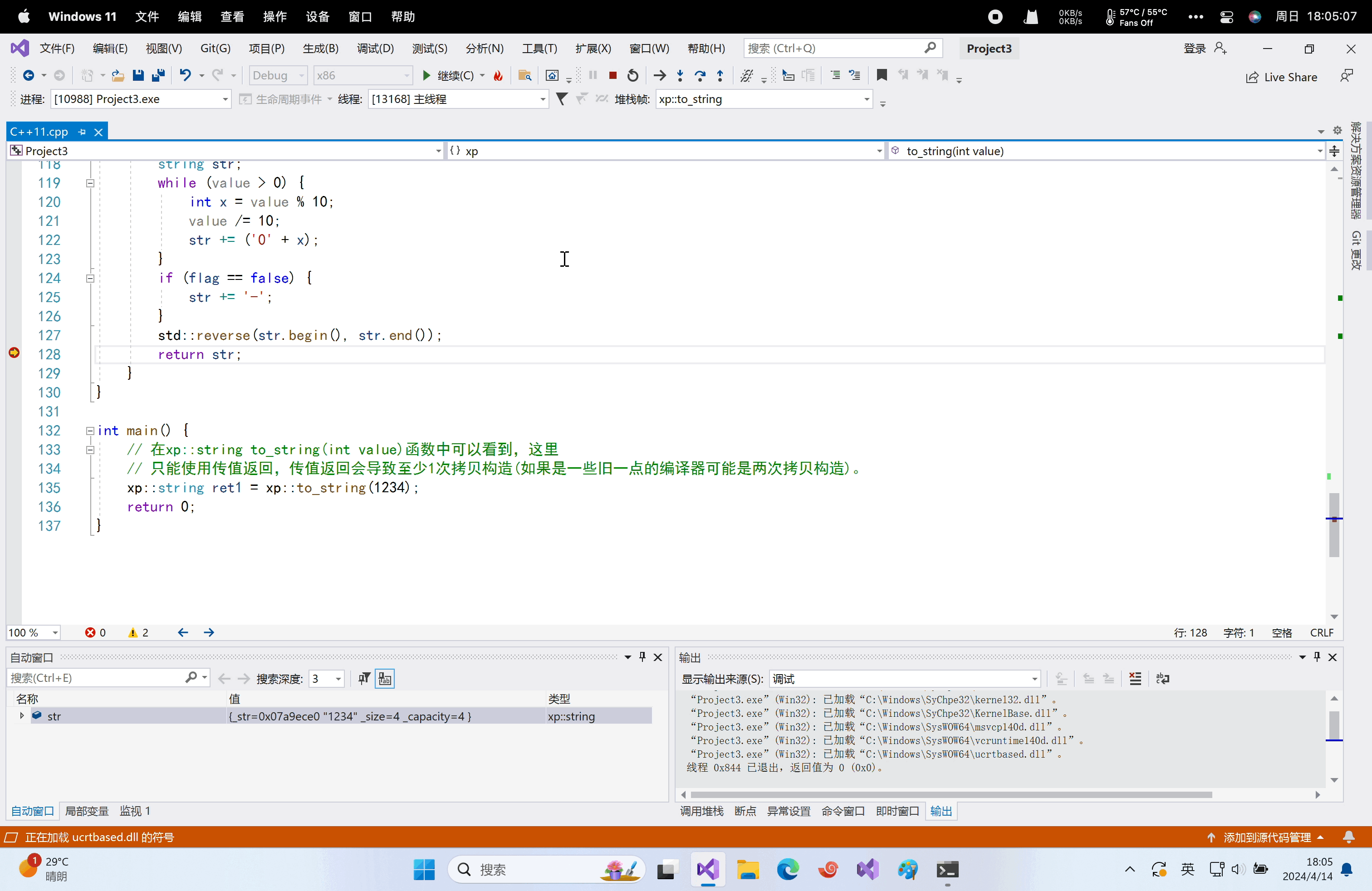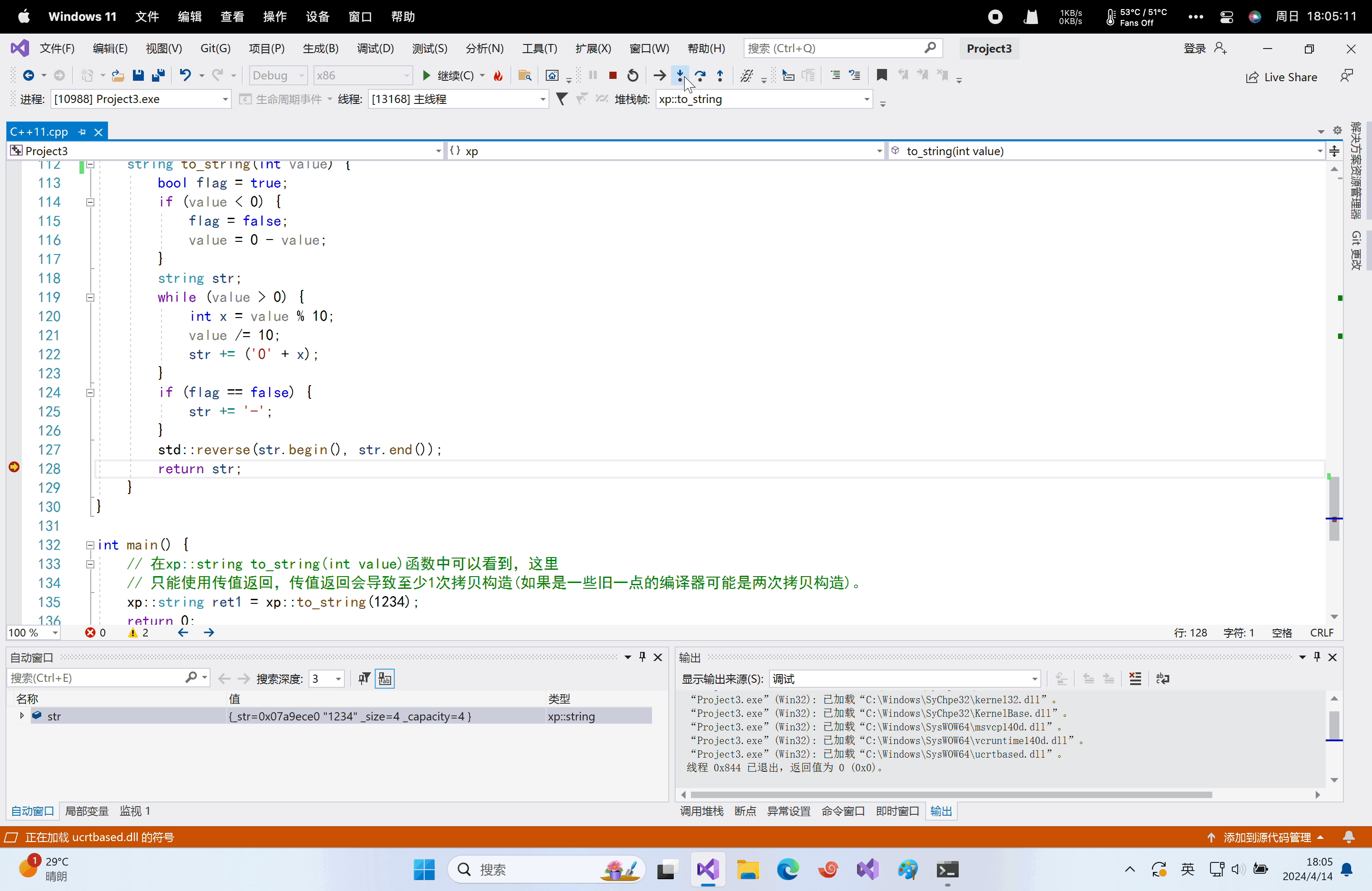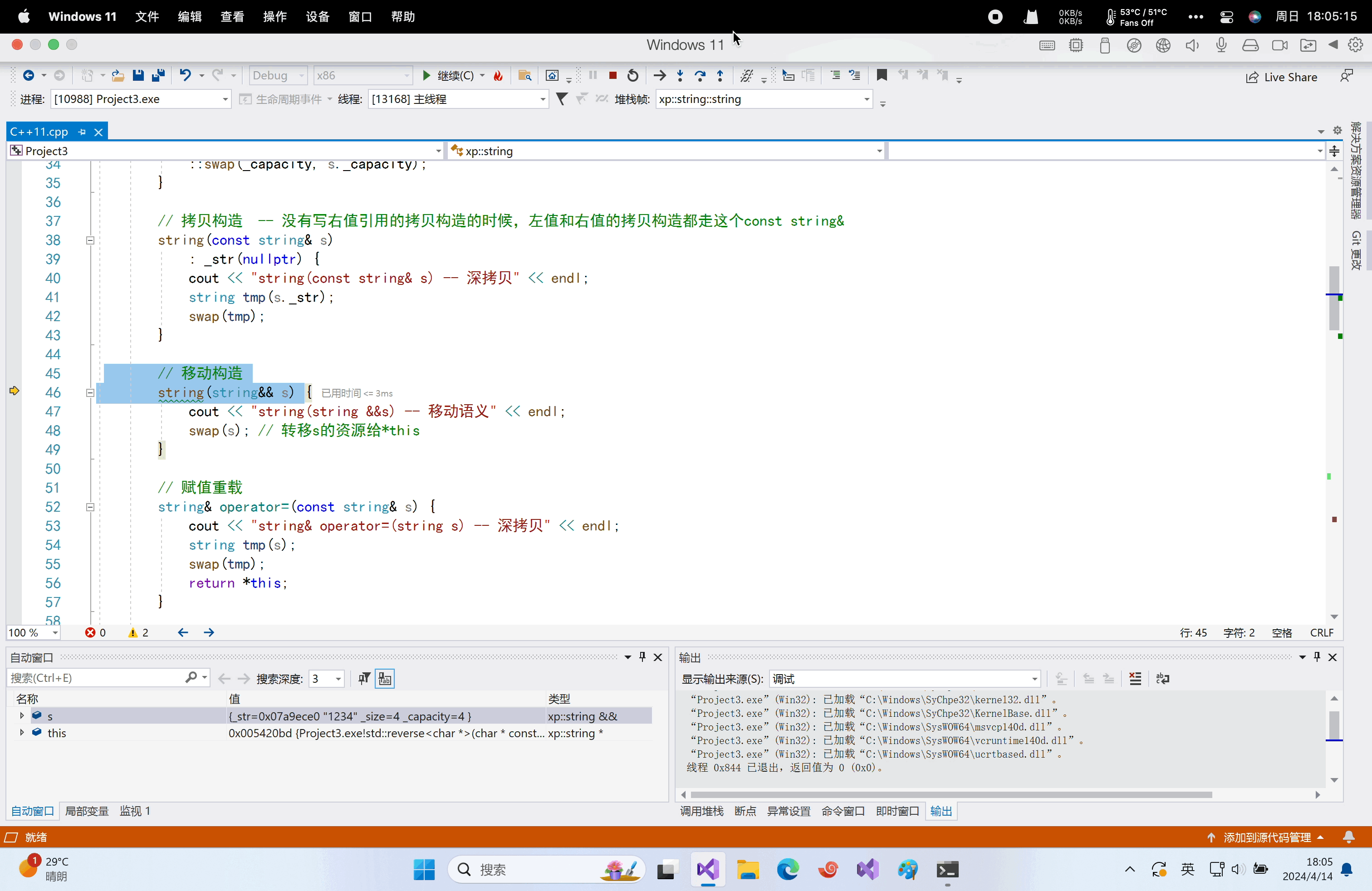
namespace xp { class string { public: typedef char *iterator; iterator begin() { return _str; } iterator end() { return _str + _size; } string(const char *str = "") : _size(strlen(str)), _capacity(_size) { //cout << "string(char* str)" << endl; _str = new char[_capacity + 1]; strcpy(_str, str); } // s1.swap(s2) void swap(string &s) { ::swap(_str, s._str); ::swap(_size, s._size); ::swap(_capacity, s._capacity); } // 拷贝构造 -- 没有写右值引用的拷贝构造的时候,左值和右值的拷贝构造都走这个const string& string(const string &s) : _str(nullptr) { cout << "string(const string& s) -- 深拷贝" << endl; string tmp(s._str); swap(tmp); } // 赋值重载 string &operator=(const string &s) { cout << "string& operator=(string s) -- 深拷贝" << endl; string tmp(s); swap(tmp); return *this; } ~string() { delete[] _str; _str = nullptr; } char &operator[](size_t pos) { assert(pos < _size); return _str[pos]; } void reserve(size_t n) { if (n > _capacity) { char *tmp = new char[n + 1]; strcpy(tmp, _str); delete[] _str; _str = tmp; _capacity = n; } } void push_back(char ch) { if (_size >= _capacity) { size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2; reserve(newcapacity); } _str[_size] = ch; ++_size; _str[_size] = '\0'; } //string operator+=(char ch) string &operator+=(char ch) { push_back(ch); return *this; } const char *c_str() const { return _str; } private: char *_str; size_t _size; size_t _capacity; // 不包含最后做标识的\0 }; string to_string(int value) { bool flag = true; if (value < 0) { flag = false; value = 0 - value; } string str; while (value > 0) { int x = value % 10; value /= 10; str += ('0' + x); } if (flag == false) { str += '-'; } std::reverse(str.begin(), str.end()); return str; } } int main() { // 在xp::string to_string(int value)函数中可以看到,这里 // 只能使用传值返回,传值返回会导致至少1次拷贝构造(如果是一些旧一点的编译器可能是两次拷贝构造)。 xp::string ret1 = xp::to_string(1234); return 0; }运行结果:vs2019下。在vs2022和CLion下不显式深拷贝,可能编译器优化太过分了。
我们来看这句代码:
xp::string ret1 = xp::to_string(1234);。这里使用了几次拷贝构造?答案是2次,一次是在to_string函数里return str;的时候,拷贝构造临时对象来返回,一次是xp::string ret1 = xp::to_string(1234);中将to_string函数的返回值来拷贝构造ret1。当然了,这里两次拷贝构造将会被编译器优化为一次拷贝构造。但是我们来思考这样一个问题:既然
str出了作用域要销毁,为什么还要给它来一次拷贝构造,而且拷贝构造后的对象又在给ret1进行拷贝构造后又销毁了,是不是太浪费资源空间了。那能不能直接略过拷贝构造,直接把str给ret1呢?答案是不可以的。当然了,有人会说,我们刚刚学过,使用右值引用,将
str引用过来作为返回值(而不是用str拷贝构造的临时对象),但是str是左值,不能进行右值引用!又有人会说,那使用move(str)来进行右值引用!我们来尝试一下:
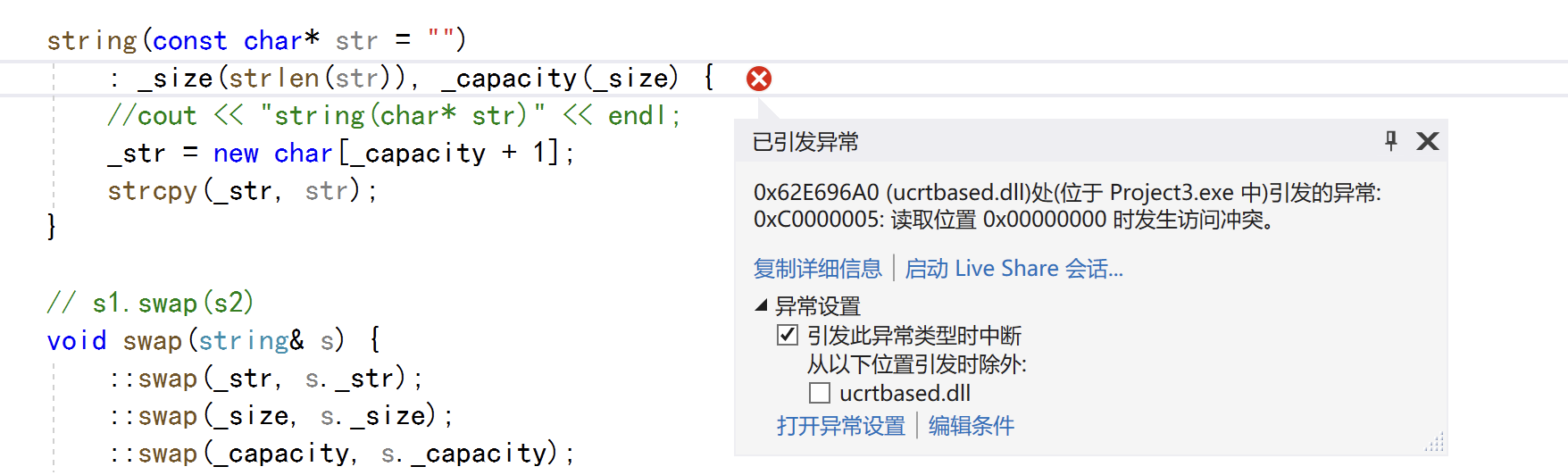
namespace xp { class string { public: typedef char *iterator; iterator begin() { return _str; } iterator end() { return _str + _size; } string(const char *str = "") : _size(strlen(str)), _capacity(_size) { //cout << "string(char* str)" << endl; _str = new char[_capacity + 1]; strcpy(_str, str); } // s1.swap(s2) void swap(string &s) { ::swap(_str, s._str); ::swap(_size, s._size); ::swap(_capacity, s._capacity); } // 拷贝构造 -- 没有写右值引用的拷贝构造的时候,左值和右值的拷贝构造都走这个const string& string(const string &s) : _str(nullptr) { cout << "string(const string& s) -- 深拷贝" << endl; string tmp(s._str); swap(tmp); } // 赋值重载 string &operator=(const string &s) { cout << "string& operator=(string s) -- 深拷贝" << endl; string tmp(s); swap(tmp); return *this; } ~string() { delete[] _str; _str = nullptr; } char &operator[](size_t pos) { assert(pos < _size); return _str[pos]; } void reserve(size_t n) { if (n > _capacity) { char *tmp = new char[n + 1]; strcpy(tmp, _str); delete[] _str; _str = tmp; _capacity = n; } } void push_back(char ch) { if (_size >= _capacity) { size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2; reserve(newcapacity); } _str[_size] = ch; ++_size; _str[_size] = '\0'; } //string operator+=(char ch) string &operator+=(char ch) { push_back(ch); return *this; } const char *c_str() const { return _str; } private: char *_str; size_t _size; size_t _capacity; // 不包含最后做标识的\0 }; string&& to_string(int value) { bool flag = true; if (value < 0) { flag = false; value = 0 - value; } string str; while (value > 0) { int x = value % 10; value /= 10; str += ('0' + x); } if (flag == false) { str += '-'; } std::reverse(str.begin(), str.end()); return move(str); } } int main() { // 在xp::string to_string(int value)函数中可以看到,这里 // 只能使用传值返回,传值返回会导致至少1次拷贝构造(如果是一些旧一点的编译器可能是两次拷贝构造)。 xp::string ret1 = xp::to_string(1234); return 0; }运行结果:vs2019出错了,说明这个编译器下,在返回的时候将str里面的数据清空了,不能被左值引用或者右值引用!。在vs2022和CLion下优化太过了,会显示一次深拷贝。
那将返回值右值引用去掉,也就是:
string to_string(int value) {}。运行结果:
还是有一次拷贝构造!为什么?
str出了作用域就是要销毁的,现在就看str用作左值还是右值。因为左值调用左值的拷贝构造,右值调用右值的拷贝构造,但是我们这里string的拷贝构造只有const string& s类型的参数,也就是左值右值都是调用这个拷贝构造,因此我们需要做的是自己再写一个针对的右值引用的拷贝构造!看下面
gif图:
代码修改后:
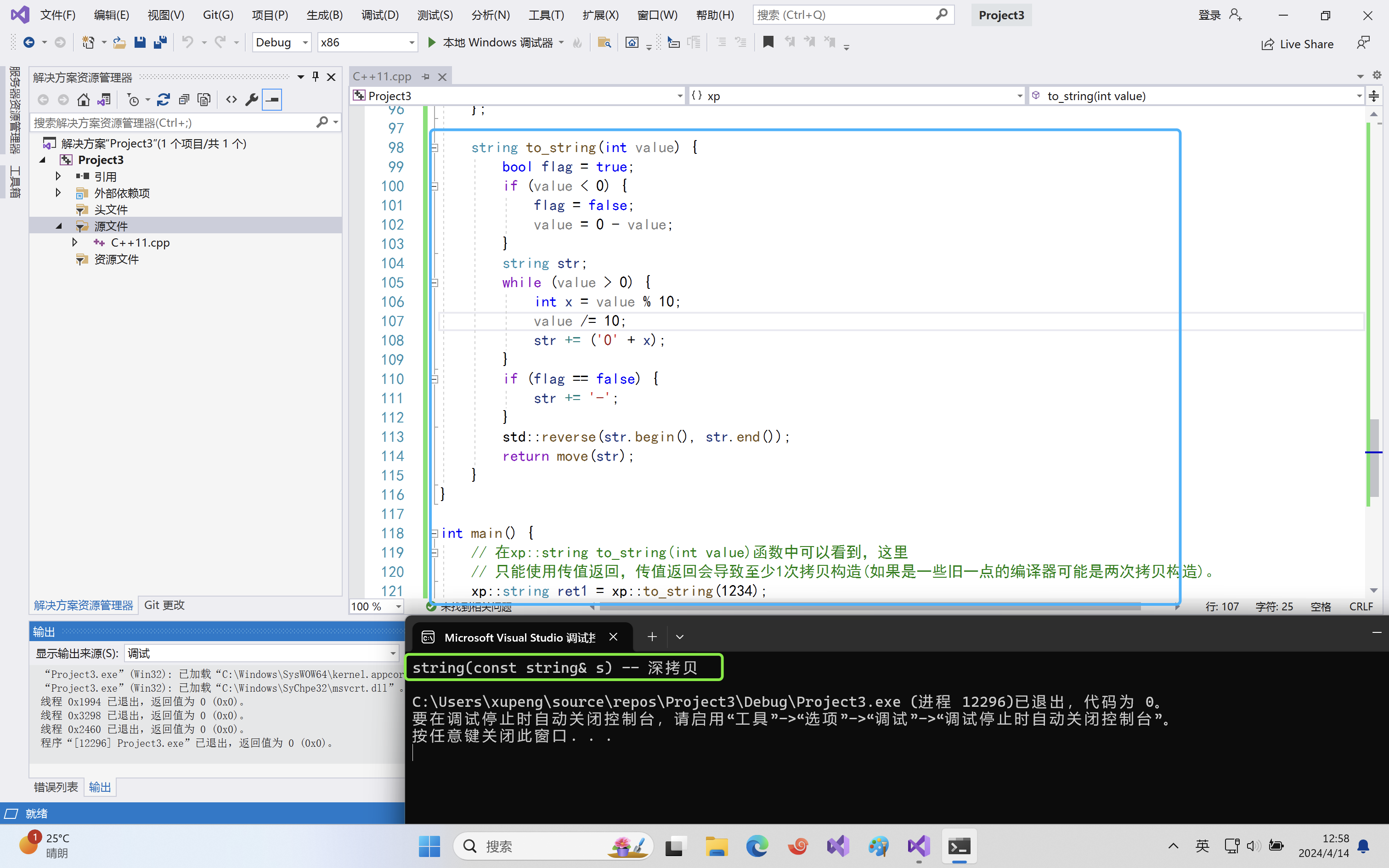
namespace xp { class string { public: typedef char *iterator; iterator begin() { return _str; } iterator end() { return _str + _size; } string(const char *str = "") : _size(strlen(str)), _capacity(_size) { //cout << "string(char* str)" << endl; _str = new char[_capacity + 1]; strcpy(_str, str); } // s1.swap(s2) void swap(string &s) { ::swap(_str, s._str); ::swap(_size, s._size); ::swap(_capacity, s._capacity); } // 拷贝构造 -- 没有写右值引用的拷贝构造的时候,左值和右值的拷贝构造都走这个const string& string(const string &s) : _str(nullptr) { cout << "string(const string& s) -- 深拷贝" << endl; string tmp(s._str); swap(tmp); } // 移动构造 string(string &&s){ cout << "string(string &&s) -- 移动语义" << endl; swap(s); // 转移s的资源给*this } // 赋值重载 string &operator=(const string &s) { cout << "string& operator=(string s) -- 深拷贝" << endl; string tmp(s); swap(tmp); return *this; } ~string() { delete[] _str; _str = nullptr; } char &operator[](size_t pos) { assert(pos < _size); return _str[pos]; } void reserve(size_t n) { if (n > _capacity) { char *tmp = new char[n + 1]; strcpy(tmp, _str); delete[] _str; _str = tmp; _capacity = n; } } void push_back(char ch) { if (_size >= _capacity) { size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2; reserve(newcapacity); } _str[_size] = ch; ++_size; _str[_size] = '\0'; } //string operator+=(char ch) string &operator+=(char ch) { push_back(ch); return *this; } const char *c_str() const { return _str; } private: char *_str; size_t _size; size_t _capacity; // 不包含最后做标识的\0 }; string&& to_string(int value) { bool flag = true; if (value < 0) { flag = false; value = 0 - value; } string str; while (value > 0) { int x = value % 10; value /= 10; str += ('0' + x); } if (flag == false) { str += '-'; } std::reverse(str.begin(), str.end()); return move(str); } } int main() { // 在xp::string to_string(int value)函数中可以看到,这里 // 只能使用传值返回,传值返回会导致至少1次拷贝构造(如果是一些旧一点的编译器可能是两次拷贝构造)。 xp::string ret1 = xp::to_string(1234); return 0; }运行结果:
这里我们解释一下什么叫移动构造和移动语义。
移动语义:
移动语义是一种语言特性,允许在不进行深拷贝的情况下将对象的资源(例如堆上分配的内存、文件句柄等)从一个对象转移到另一个对象。它适用于右值(临时对象、将要被销毁的对象等),并且通常使用右值引用来实现。移动语义的主要思想是,如果一个对象将要被销毁,那么它的资源可以被另一个对象“移动”而不是复制,从而避免额外的内存分配和复制开销。
移动构造函数:
移动构造函数是一个特殊的构造函数,用于实现移动语义。它接收一个右值引用作为参数,表示将要被移动资源的对象。移动构造函数通常从传入的对象“窃取”资源,而不是进行深拷贝。移动构造函数的目标是尽可能有效地获取资源的所有权,而不进行额外的资源分配或拷贝。
可以看到,这里只有一次移动构造,也就是调用了右值引用的拷贝构造(仅仅交换了资源),减少了一次拷贝。但是为什么是一次移动构造?因为
to_string返回时候一次移动构造,因为to_string移动构造后的对象还是右值,使用给ret1拷贝的时候有一次移动构造,编译器将两次移动构造优化为一次移动构造。这里其实返回值
str加不加move都无所谓,编译器会自动优化,将str强转为右值以便于调用移动构造。
看
gif动图:
再看下面这种情况:
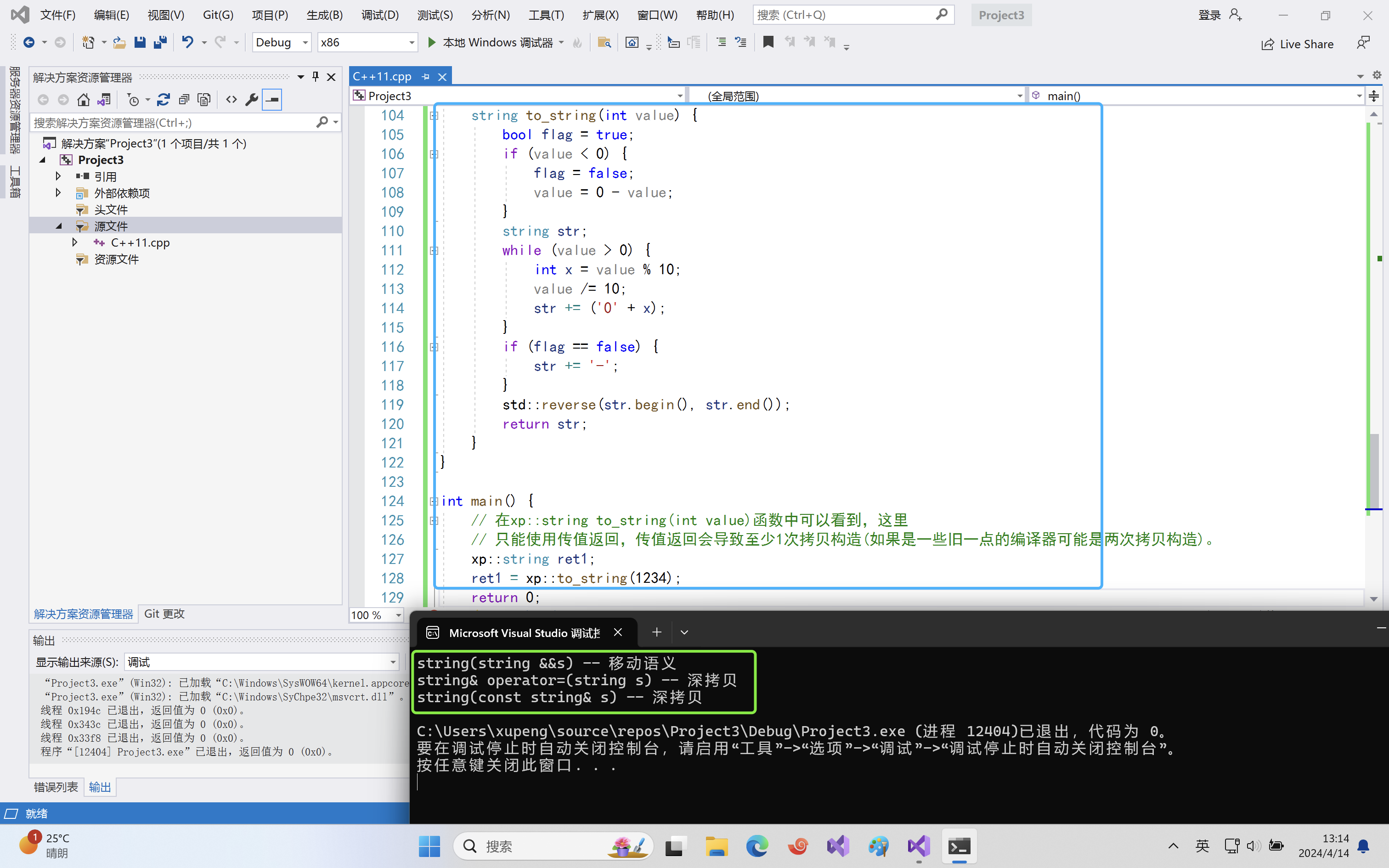
int main() { // 在xp::string to_string(int value)函数中可以看到,这里 // 只能使用传值返回,传值返回会导致至少1次拷贝构造(如果是一些旧一点的编译器可能是两次拷贝构造)。 xp::string ret1; ret1 = xp::to_string(1234); return 0; }运行结果:
我们可以发现,这里调用了一次移动构造(
to_string返回的时候),一次赋值重载,一次拷贝构造(赋值重载复用了拷贝构造)。也就是进行了一次深拷贝!那么这个深拷贝是必要的吗?显然不是,因为
to_string返回的临时对象还是要被销毁的,把它进行赋值的时候进行深拷贝是不必要的,我们可以像拷贝构造一样,写一个右值引用版本的赋值重载(我们叫移动赋值),进行转移资源!代码修改后:
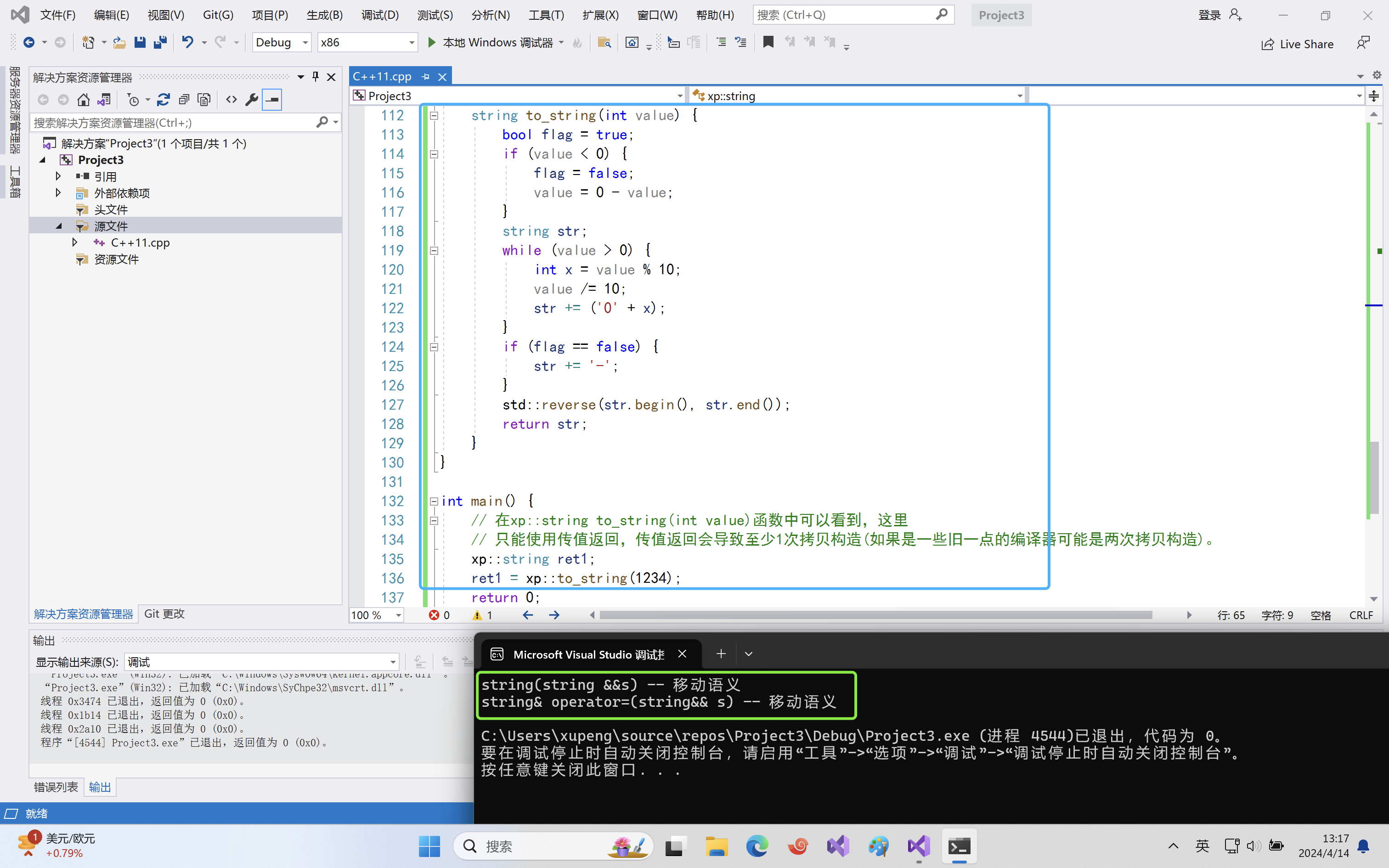
#define _CRT_SECURE_NO_WARNINGS 1 #include <iostream> #include <cstring> #include<assert.h> #include<algorithm> using namespace std; namespace xp { class string { public: typedef char* iterator; iterator begin() { return _str; } iterator end() { return _str + _size; } string(const char* str = "") : _size(strlen(str)), _capacity(_size) { //cout << "string(char* str)" << endl; _str = new char[_capacity + 1]; strcpy(_str, str); } // s1.swap(s2) void swap(string& s) { ::swap(_str, s._str); ::swap(_size, s._size); ::swap(_capacity, s._capacity); } // 拷贝构造 -- 没有写右值引用的拷贝构造的时候,左值和右值的拷贝构造都走这个const string& string(const string& s) : _str(nullptr) { cout << "string(const string& s) -- 深拷贝" << endl; string tmp(s._str); swap(tmp); } // 移动构造 string(string&& s) { cout << "string(string &&s) -- 移动语义" << endl; swap(s); // 转移s的资源给*this } // 赋值重载 string& operator=(const string& s) { cout << "string& operator=(string s) -- 深拷贝" << endl; string tmp(s); swap(tmp); return *this; } // 移动赋值 string& operator=(string&& s) { cout << "string& operator=(string&& s) -- 移动语义" << endl; swap(s); return *this; } ~string() { delete[] _str; _str = nullptr; } char& operator[](size_t pos) { assert(pos < _size); return _str[pos]; } void reserve(size_t n) { if (n > _capacity) { char* tmp = new char[n + 1]; strcpy(tmp, _str); delete[] _str; _str = tmp; _capacity = n; } } void push_back(char ch) { if (_size >= _capacity) { size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2; reserve(newcapacity); } _str[_size] = ch; ++_size; _str[_size] = '\0'; } //string operator+=(char ch) string& operator+=(char ch) { push_back(ch); return *this; } const char* c_str() const { return _str; } private: char* _str = nullptr; size_t _size = 0; size_t _capacity = 0; // 不包含最后做标识的\0 }; string to_string(int value) { bool flag = true; if (value < 0) { flag = false; value = 0 - value; } string str; while (value > 0) { int x = value % 10; value /= 10; str += ('0' + x); } if (flag == false) { str += '-'; } std::reverse(str.begin(), str.end()); return str; } } int main() { // 在xp::string to_string(int value)函数中可以看到,这里 // 只能使用传值返回,传值返回会导致至少1次拷贝构造(如果是一些旧一点的编译器可能是两次拷贝构造)。 xp::string ret1; ret1 = xp::to_string(1234); return 0; }运行结果:
我们发现一次拷贝构造都没有!
调用流程是:
to_string函数返回的时候调用移动构造返回临时对象(右值),这个临时对象再调用移动赋值给ret1,最后销毁这个临时对象(资源已经给ret1了,自己没有数据了)。这里解释一下移动赋值:
移动赋值是另一个与移动语义相关的重要概念,它允许在不进行深拷贝的情况下,将对象的资源从一个对象转移到另一个对象。与移动构造函数类似,移动赋值通常使用右值引用来实现。
8.6、右值引用引用左值及使用场景
上述to_string已经用到了move来将左值强制转右值来调用移动构造,下面给一个更深入的场景使用move。
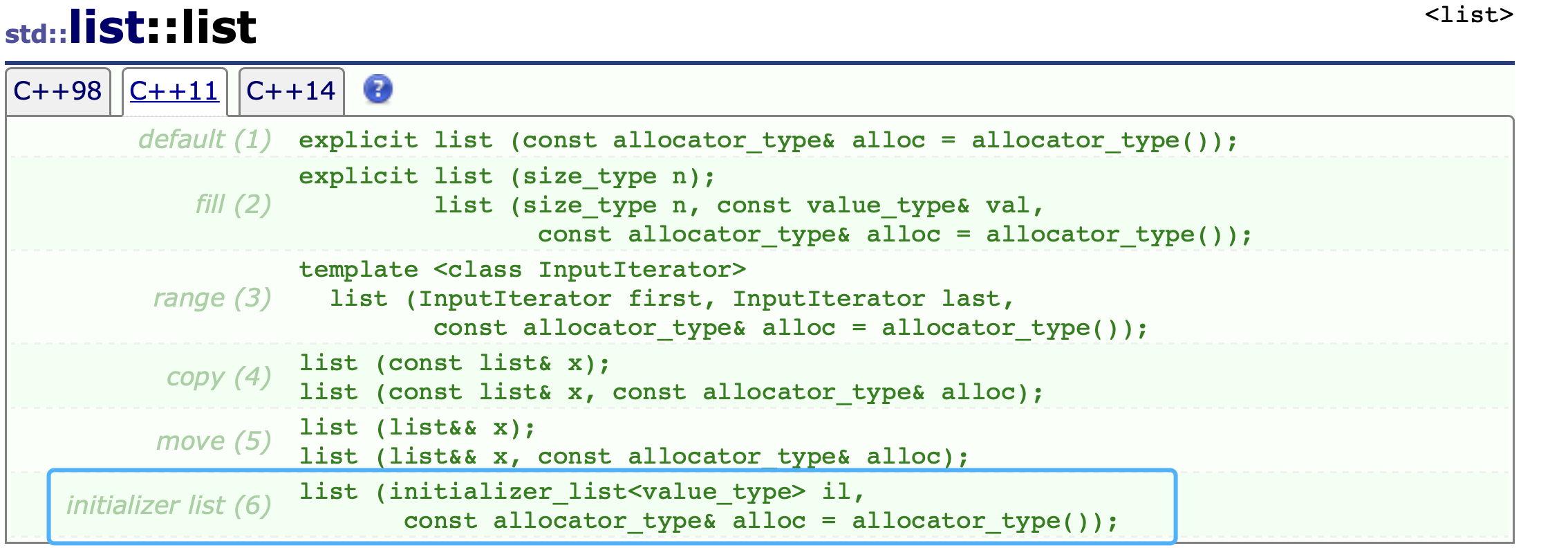
来看下面模拟实现的list的代码:
list.h文件// // Created by 徐鹏 on 2024/4/13. // #ifndef DEMO_02_LIST_H #define DEMO_02_LIST_H #endif //DEMO_02_LIST_H #include <iostream> using namespace std; // list的模拟实现(还未完成) namespace xp { // 结点 template<class T> struct ListNode { ListNode<T> *_next; ListNode<T> *_prev; T data; // 构造函数 -- 创建结点 ListNode(const T &val = T()) : _next(nullptr), _prev(nullptr), data(val) { // data(val)调用拷贝构造 } // 这里val的类型是左值 ListNode(T &&val) : _next(nullptr), _prev(nullptr), data(move(val)) { // data(val)调用拷贝构造 } }; template<class T, class Ref, class Ptr> class __list_iterator { public: typedef ListNode<T> Node; typedef __list_iterator<T, Ref, Ptr> self; // 迭代器本身 // 这里构造函数为了方便begin和end,直接隐式类型转换 __list_iterator(Node *node) : _node(node) { } Ref operator*() { return _node->data; } Ptr operator->() { return &_node->data; } self &operator++() { _node = _node->_next; return *this; } self operator++(int) { self temp(*this); // 这里*this的类型是self ,调用默认拷贝构造函数!因为是内置类型,不需要自己写 _node = _node->_next; return temp; } self &operator--() { _node = _node->_prev; return *this; } self &operator--(int) { self temp(*this); _node = _node->_prev; return temp; } bool operator!=(const self &s) { return _node != s._node; } bool operator==(const self &s) { return _node == s._node; } // 拷贝构造和析构不需要写,析构不能用,不然结点被删除了 // 比如 lt.begin(),这里的类型就是Node* Node *_node; // 内置类型不能重载++等操作符,因此对这个内置类型进行封装来实现++等功能 }; template<class T> class list { public: typedef ListNode<T> Node; typedef __list_iterator<T, T &, T *> iterator; typedef __list_iterator<T, const T &, const T *> const_iterator; //构造函数 list() { //创建带头节点的双向循环链表 _head = new Node; _head->_next = _head; _head->_prev = _head; } // 拷贝构造函数 list(list<T> <) { // 先创个头节点 _head = new Node; _head->_next = _head; _head->_prev = _head; iterator it = lt.begin(); while (it != lt.end()) { push_back(*it); ++it; } } void swap(list<T> <) { std::swap(_head, lt._head); } // 赋值 list<T> operator=(list<T> lt) { swap(lt); return *this; } iterator begin() { return _head->_next; } iterator end() { return _head; } const_iterator begin() const { return _head->_next; } const_iterator end() const { return _head; } void push_back(const T &val) { // Node *tail = _head->_prev;// 先找到尾 // // // 创建新节点 // Node *newnode = new Node(val); // // tail->_next = newnode; // newnode->_prev = tail; // // newnode->_next = _head; // _head->_prev = newnode; insert(end(), val); } // 这里val的类型是左值 void push_back(T &&val) { // Node *tail = _head->_prev;// 先找到尾 // // // 创建新节点 // Node *newnode = new Node(val); // // tail->_next = newnode; // newnode->_prev = tail; // // newnode->_next = _head; // _head->_prev = newnode; insert(end(), move(val)); } iterator insert(iterator pos, const T &val) { Node *cur = pos._node; Node *prev = cur->_prev; Node *newnode = new Node(val); newnode->_next = cur; newnode->_prev = prev; prev->_next = newnode; cur->_prev = newnode; return newnode; } // 这里val的类型是左值 iterator insert(iterator pos, T &&val) { Node *cur = pos._node; Node *prev = cur->_prev; Node *newnode = new Node(move(val)); newnode->_next = cur; newnode->_prev = prev; prev->_next = newnode; cur->_prev = newnode; return newnode; } iterator erase(iterator pos) { assert(pos != _head);// _head这个位置就是end() Node *cur = pos._node; Node *prev = cur->_prev; Node *tail = cur->_next; prev->_next = tail; tail->_prev = prev; delete cur; return tail; } void clear() { // 清空所有数据,只留一个头节点 iterator it = begin(); while (it != end()) { it = erase(begin()); } } ~list() { clear(); if (_head) { delete _head; _head = nullptr; } } private: Node *_head;// 头节点 -- 带头双向循环链表 }; }
main.cpp文件#include <iostream> using namespace std; namespace xp { class string { public: typedef char *iterator; iterator begin() { return _str; } iterator end() { return _str + _size; } string(const char *str = "") : _size(strlen(str)), _capacity(_size) { //cout << "string(char* str)" << endl; _str = new char[_capacity + 1]; strcpy(_str, str); } // s1.swap(s2) void swap(string &s) { ::swap(_str, s._str); ::swap(_size, s._size); ::swap(_capacity, s._capacity); } // 拷贝构造 -- 没有写右值引用的拷贝构造的时候,左值和右值的拷贝构造都走这个const string& string(const string &s) : _str(nullptr) { cout << "string(const string& s) -- 深拷贝" << endl; string tmp(s._str); swap(tmp); } // 赋值重载 string &operator=(const string &s) { cout << "string& operator=(string s) -- 深拷贝" << endl; string tmp(s); swap(tmp); return *this; } // 移动构造 --- 右值 // 右值引用的拷贝构造函数得到的是右值。 // 右值引用的属性是左值,也就是s是左值,所以才可以被转移资源(使用swap,swap的形参是左值引用(string&)) string(string &&s) : _str(nullptr), _size(0), _capacity(0) { cout << "string(string&& s) -- 移动语义" << endl; swap(s); // 转移s的资源给*this } // 移动赋值 string &operator=(string &&s) { cout << "string& operator=(string&& s) -- 移动语义" << endl; swap(s); return *this; } ~string() { delete[] _str; _str = nullptr; } char &operator[](size_t pos) { assert(pos < _size); return _str[pos]; } void reserve(size_t n) { if (n > _capacity) { char *tmp = new char[n + 1]; strcpy(tmp, _str); delete[] _str; _str = tmp; _capacity = n; } } void push_back(char ch) { if (_size >= _capacity) { size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2; reserve(newcapacity); } _str[_size] = ch; ++_size; _str[_size] = '\0'; } //string operator+=(char ch) string &operator+=(char ch) { push_back(ch); return *this; } const char *c_str() const { return _str; } private: char *_str; size_t _size; size_t _capacity; // 不包含最后做标识的\0 }; string to_string(int value) { bool flag = true; if (value < 0) { flag = false; value = 0 - value; } string str; while (value > 0) { int x = value % 10; value /= 10; str += ('0' + x); } if (flag == false) { str += '-'; } std::reverse(str.begin(), str.end()); return move(str); // 强制把str转右值 -- 去调用右值引用的拷贝构造 } } #include "list.h" // 右值引用使用move引用左值的场景 int main() { xp::list<xp::string> lt; xp::string s1("123"); // s1是左值 // lt.push_back(s1); move(s1); lt.push_back(move(s1)); // 这里move以后,s1的资源就被掠夺了,置空了,其实不是这么用的 cout << "=================" << endl; lt.push_back(xp::string("222")); // 右值 cout << "=================" << endl; lt.push_back("333"); // 右值 cout << "=================" << endl; return 0; }需要注意的是:move它并不搬移任何东西,只是将左值强转为右值!转移资源是交给移动语义的函数!
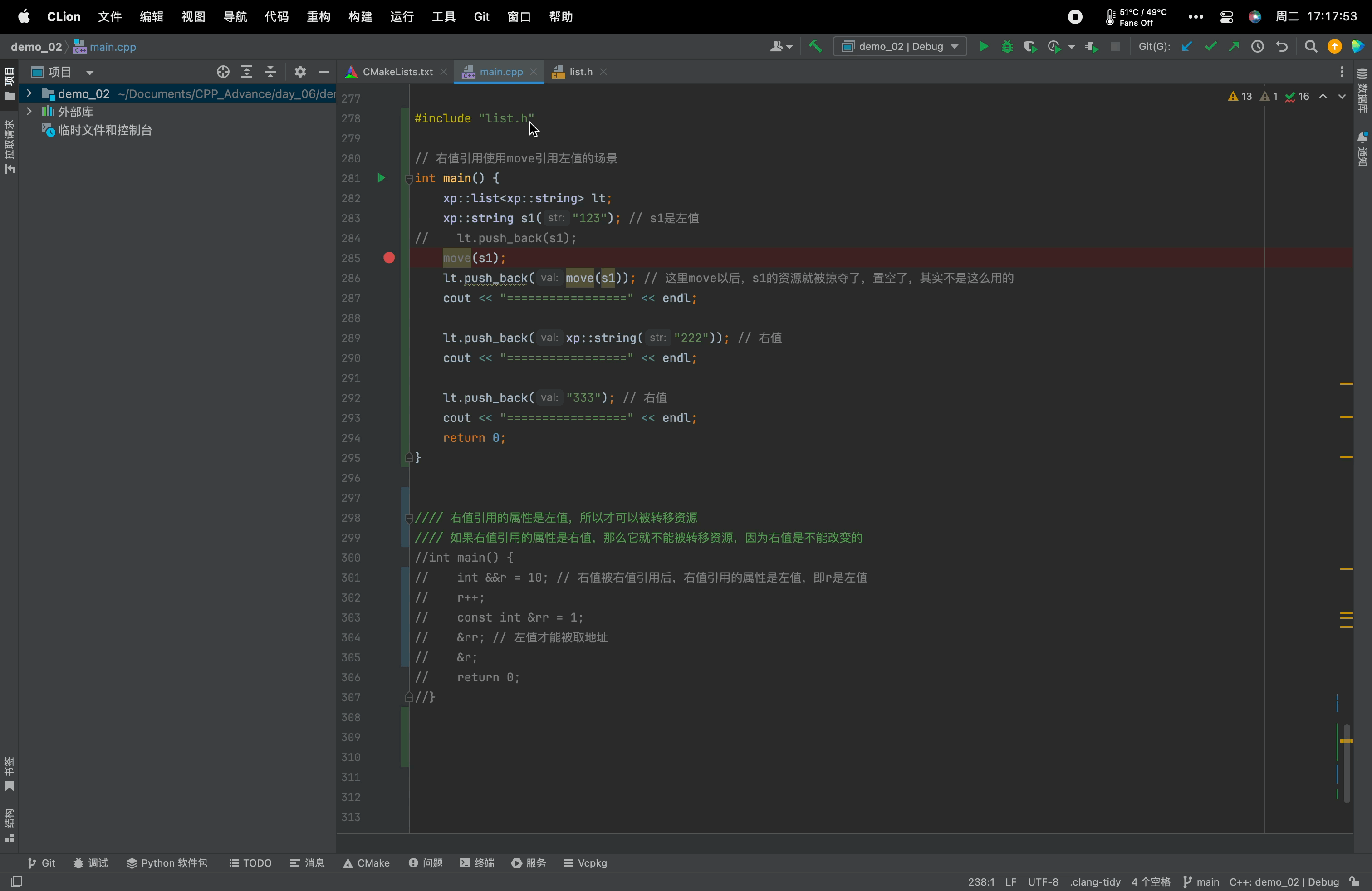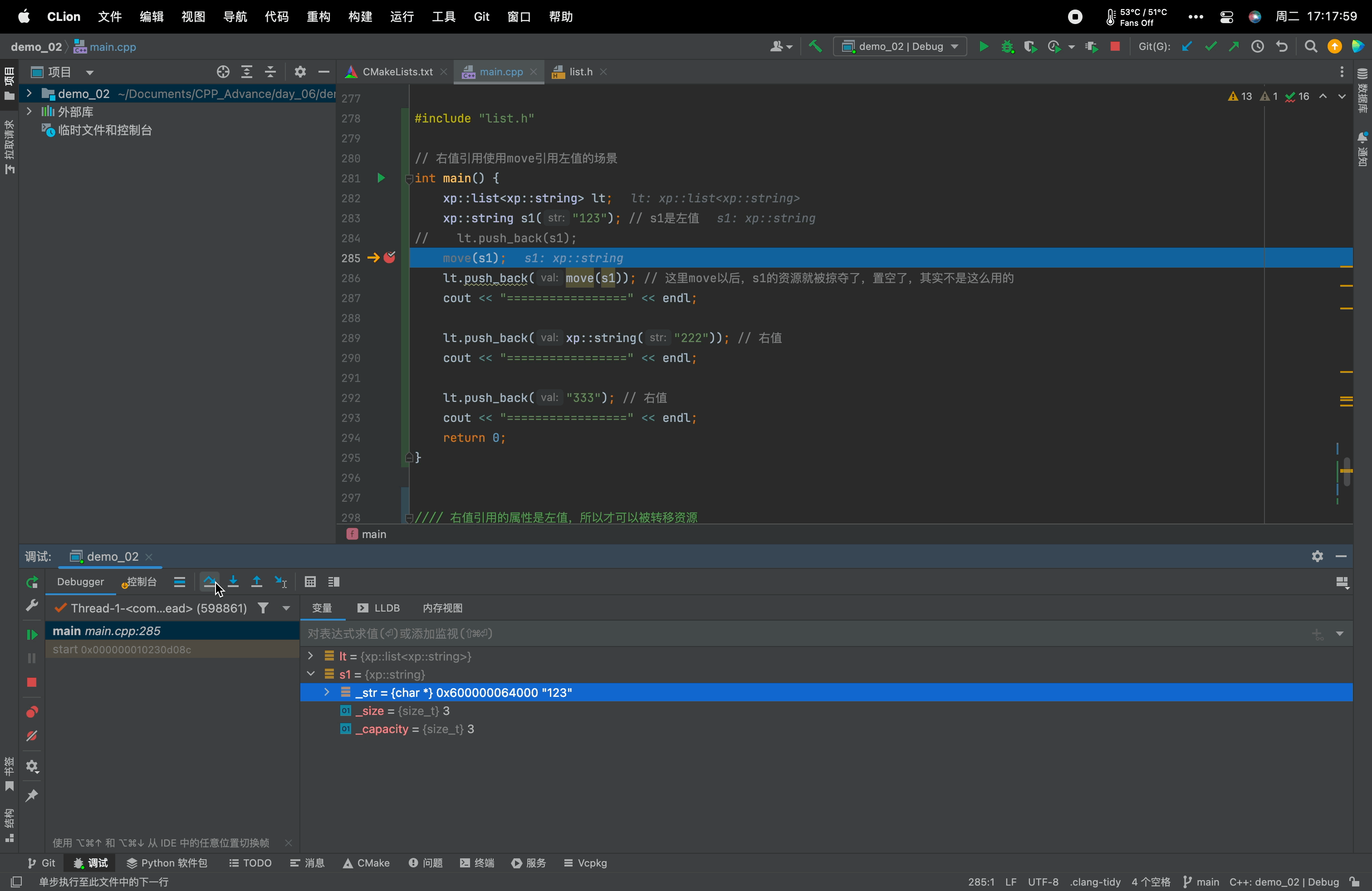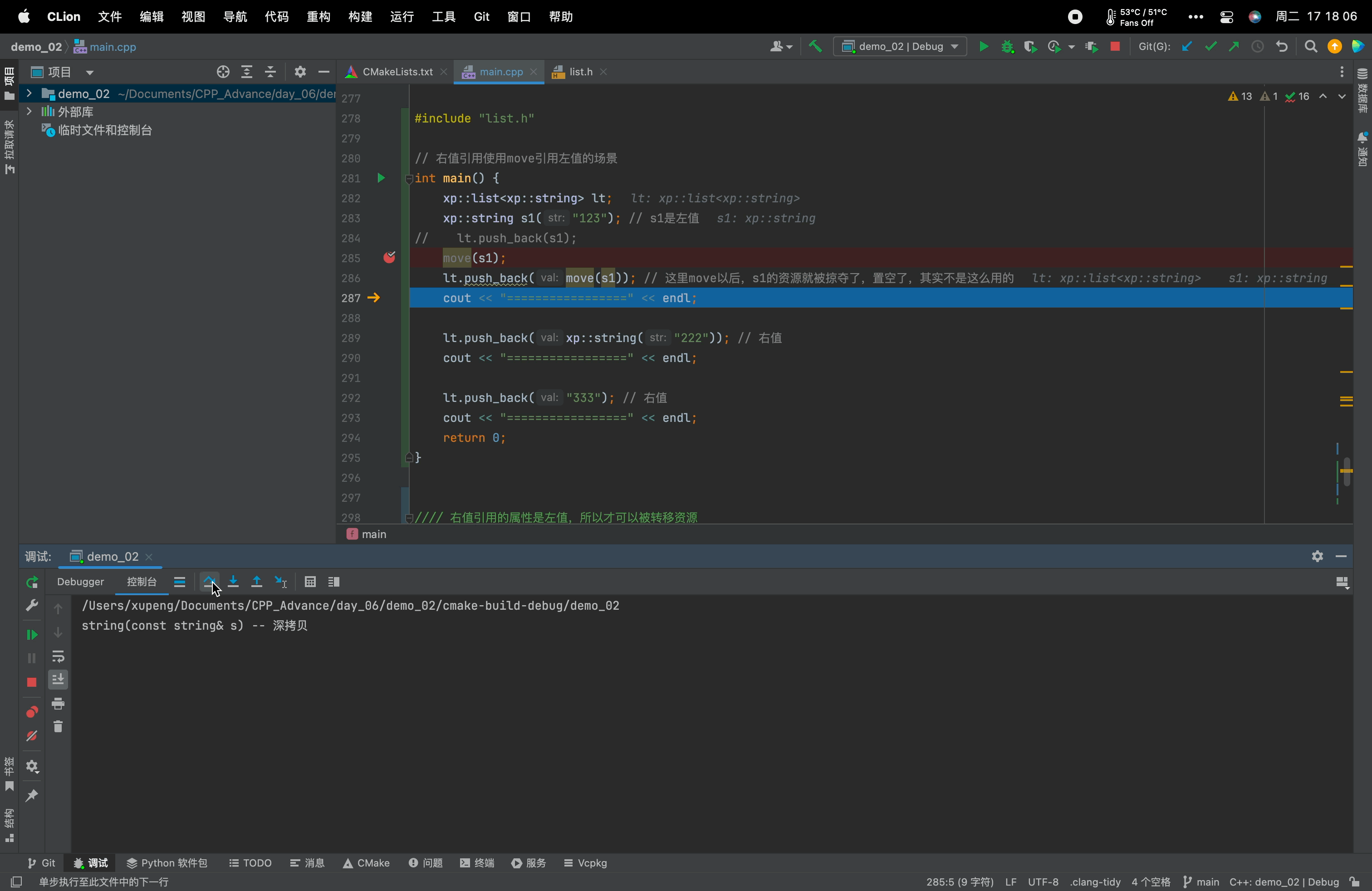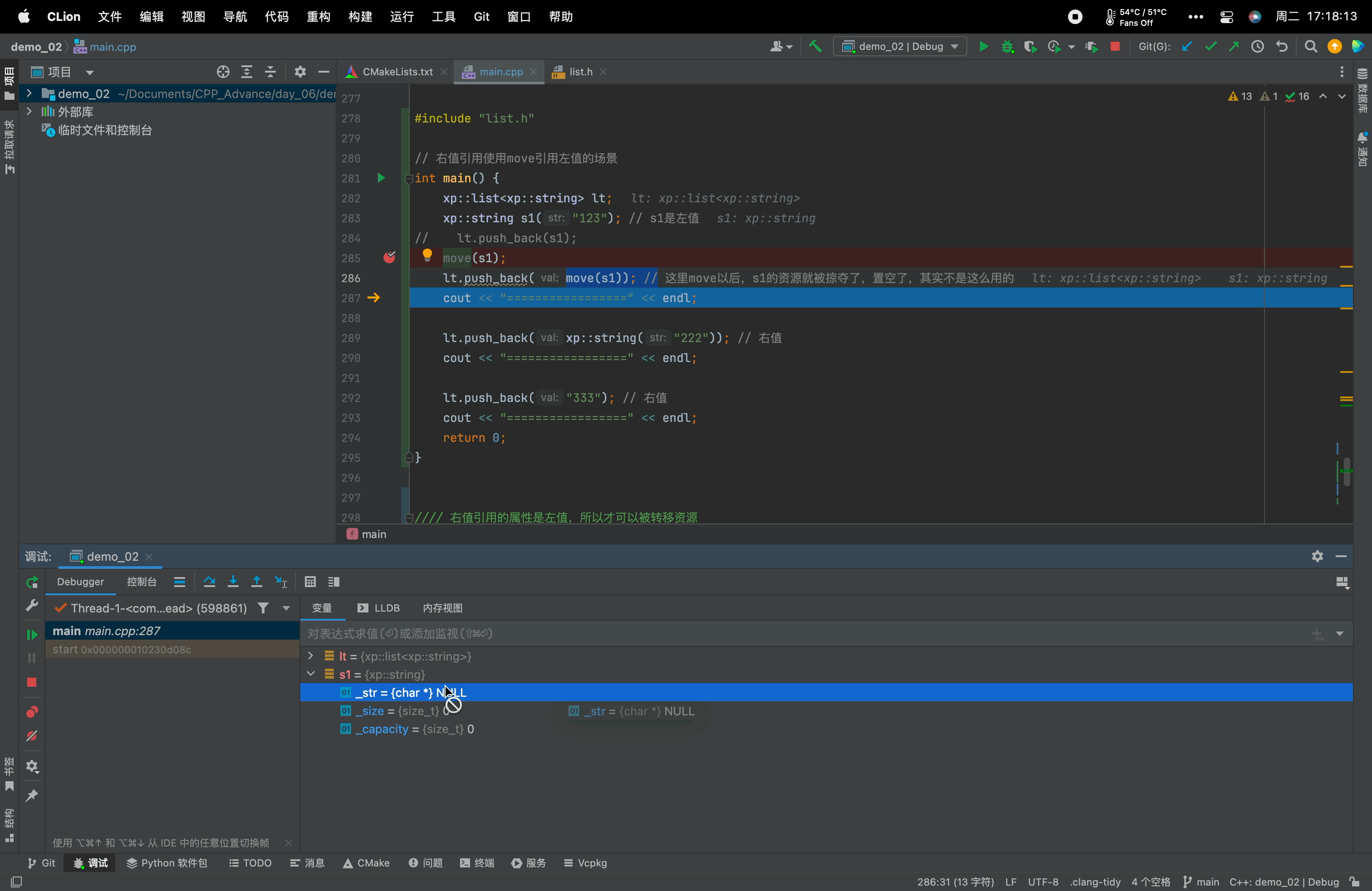
8.7、右值引用属性
右值引用的属性是左值,所以才可以被转移资源。如果右值引用的属性是右值,那么它就不能被转移资源,因为右值是不能改变的。
int main() { int &&r = 10; // 右值被右值引用后,右值引用的属性是左值,即r是左值 r++; const int &rr = 1; &rr; // 左值才能被取地址 &r; return 0; }
8.8、模版中的右值引用
模版中的右值引用是万能引用,可以引用:左值、const 左值、右值、const 右值。
template<class T> void Transit(T &&val) { cout << "T &&val" << endl; } int main() { int a = 10; // 左值 Transit(a); const int b = 11; // const 左值 Transit(b); Transit(10);// 右值 Transit(move(b));// const 右值 return 0; }
8.9、完美转发
使用forward函数模版,可以在传参的过程中保留对象原生类型属性。这就叫完美转发。
也就是参数是原本左值,经过右值引用后还是左值,再经forward转发后还是左值。
如果参数原本是右值,那经过右值引用后变为左值,再经forward转发后变为右值。
void Fun(int &val) { cout << "int& val" << endl; } void Fun(const int &val) { cout << "const int &val" << endl; } void Fun(int &&val) { cout << "int&& val" << endl; } void Fun(const int &&val) { cout << "const int&& val" << endl; } template<class T> void Transit(T &&val) { Fun(forward<T>(val)); } int main() { int a = 10; // 左值 Transit(a); const int b = 11; // const 左值 Transit(b); Transit(10);// 右值 Transit(move(b));// const 右值 return 0; }完美转发使用场景:还是以模拟list为例,也就是把move的地方换成forward。
// // Created by 徐鹏 on 2024/4/13. // #ifndef DEMO_02_LIST_H #define DEMO_02_LIST_H #endif //DEMO_02_LIST_H #include <iostream> using namespace std; // list的模拟实现(还未完成) namespace xp { // 结点 template<class T> struct ListNode { ListNode<T> *_next; ListNode<T> *_prev; T data; // 构造函数 -- 创建结点 ListNode(const T &val = T()) : _next(nullptr), _prev(nullptr), data(val) { // data(val)调用拷贝构造 } // 这里val的类型是左值 ListNode(T &&val) : _next(nullptr), _prev(nullptr), data(forward<T>(val)) { // data(val)调用拷贝构造 } }; template<class T, class Ref, class Ptr> class __list_iterator { public: typedef ListNode<T> Node; typedef __list_iterator<T, Ref, Ptr> self; // 迭代器本身 // 这里构造函数为了方便begin和end,直接隐式类型转换 __list_iterator(Node *node) : _node(node) { } Ref operator*() { return _node->data; } Ptr operator->() { return &_node->data; } self &operator++() { _node = _node->_next; return *this; } self operator++(int) { self temp(*this); // 这里*this的类型是self ,调用默认拷贝构造函数!因为是内置类型,不需要自己写 _node = _node->_next; return temp; } self &operator--() { _node = _node->_prev; return *this; } self &operator--(int) { self temp(*this); _node = _node->_prev; return temp; } bool operator!=(const self &s) { return _node != s._node; } bool operator==(const self &s) { return _node == s._node; } // 拷贝构造和析构不需要写,析构不能用,不然结点被删除了 // 比如 lt.begin(),这里的类型就是Node* Node *_node; // 内置类型不能重载++等操作符,因此对这个内置类型进行封装来实现++等功能 }; template<class T> class list { public: typedef ListNode<T> Node; typedef __list_iterator<T, T &, T *> iterator; typedef __list_iterator<T, const T &, const T *> const_iterator; //构造函数 list() { //创建带头节点的双向循环链表 _head = new Node; _head->_next = _head; _head->_prev = _head; } // 拷贝构造函数 list(list<T> <) { // 先创个头节点 _head = new Node; _head->_next = _head; _head->_prev = _head; iterator it = lt.begin(); while (it != lt.end()) { push_back(*it); ++it; } } void swap(list<T> <) { std::swap(_head, lt._head); } // 赋值 list<T> operator=(list<T> lt) { swap(lt); return *this; } iterator begin() { return _head->_next; } iterator end() { return _head; } const_iterator begin() const { return _head->_next; } const_iterator end() const { return _head; } void push_back(const T &val) { // Node *tail = _head->_prev;// 先找到尾 // // // 创建新节点 // Node *newnode = new Node(val); // // tail->_next = newnode; // newnode->_prev = tail; // // newnode->_next = _head; // _head->_prev = newnode; insert(end(), val); } // 这里val的类型是左值 void push_back(T &&val) { // Node *tail = _head->_prev;// 先找到尾 // // // 创建新节点 // Node *newnode = new Node(val); // // tail->_next = newnode; // newnode->_prev = tail; // // newnode->_next = _head; // _head->_prev = newnode; insert(end(), forward<T>(val)); } iterator insert(iterator pos, const T &val) { Node *cur = pos._node; Node *prev = cur->_prev; Node *newnode = new Node(val); newnode->_next = cur; newnode->_prev = prev; prev->_next = newnode; cur->_prev = newnode; return newnode; } // 这里val的类型是左值 iterator insert(iterator pos, T &&val) { Node *cur = pos._node; Node *prev = cur->_prev; Node *newnode = new Node(forward<T>(val)); newnode->_next = cur; newnode->_prev = prev; prev->_next = newnode; cur->_prev = newnode; return newnode; } iterator erase(iterator pos) { assert(pos != _head);// _head这个位置就是end() Node *cur = pos._node; Node *prev = cur->_prev; Node *tail = cur->_next; prev->_next = tail; tail->_prev = prev; delete cur; return tail; } void clear() { // 清空所有数据,只留一个头节点 iterator it = begin(); while (it != end()) { it = erase(begin()); } } ~list() { clear(); if (_head) { delete _head; _head = nullptr; } } private: Node *_head;// 头节点 -- 带头双向循环链表 }; }
9、新的类功能
9.1、新增两个默认成员函数
C++98中,原本有6个默认成员函数:构造函数、拷贝构造函数、拷贝赋值重载、析构函数、取地址重载、const 取地址重载。
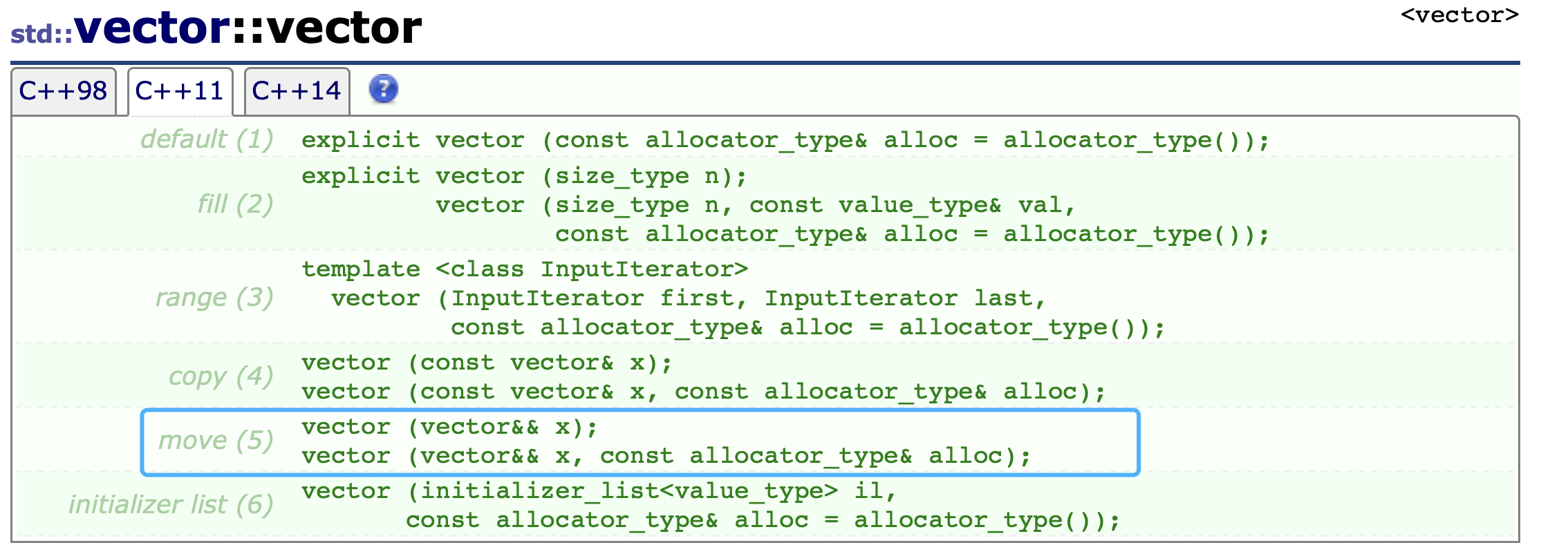
C++11新增两个默认成员函数:其实也就是我们上面谈到的两个移动语义的函数。
- 移动构造函数
- 移动赋值重载
需要注意的是:
- 如果你自己没有实现移动构造函数,并且没有实现析构函数、拷贝构造函数、赋值重载(包括移动赋值重载)的任意一个。那么编译器会默认生成一个默认的移动构造函数。默认的移动构造函数对内置类型会进行浅拷贝,对自定义类型去调用它的移动构造函数(如果没有实现就调用它的拷贝构造函数)。
- 如果你自己没有实现移动赋值重载函数,并且没有实现析构函数、拷贝构造函数、构造函数(包括移动构造)的任意一个。那么编译器会默认生成一个默认的移动赋值重载函数。默认的移动赋值重载函数对内置类型会进行浅拷贝,对自定义类型去调用它的移动赋值重载函数(如果没有实现就调用它的赋值重载函数)。
- 如果你提供了移动构造和移动赋值,那么编译器不会默认生成拷贝构造函数和赋值重载函数。
为什么实现了析构函数、拷贝构造函数、赋值重载(包括移动赋值重载)/构造函数(包括移动构造)的任意一个,编译器就不会生成默认的移动构造/移动赋值?
因为如果你实现了析构函数、拷贝构造函数、赋值重载(包括移动赋值重载)/构造函数(包括移动构造)的任意一个,说明需要进行深拷贝,那么如果需要进行深拷贝,就必须自己写析构函数、拷贝构造函数、赋值重载(包括移动赋值重载)/构造函数(包括移动构造)。
这里再解释一下什么叫浅拷贝,什么叫深拷贝。
浅拷贝:就是不存在开辟新空间或者指向新空间的成员变量。一般是自定义类型(如果指针指向一块空间,那么需要深拷贝)。
深拷贝:就是存在辟新空间或者指向新空间的成员变量。一般是自定义类型(如vector会开辟空间存值)。
class Person { public: Person(const char *name = "", int age = 0) : _name(name), _age(age) {} void Swap(Person &p) { std::swap(_age, p._age); std::swap(_name, p._name); } // 移动构造 -- 只写了移动构造,那么编译器移动赋值就不会生成了,赋值重载也不会生成 // Person(Person &&p) { // Swap(p); // } // 移动赋值 -- 只写了移动赋值,那么编译器移动构造就不会生成了,拷贝构造也不会生成 // Person &operator=(Person &&p) { // Swap(p); // return *this; // } // Person(const Person &p) : _name(p._name), _age(p._age) {} // // Person &operator=(const Person &p) { // if (this != &p) { // _name = p._name; // _age = p._age; // } // return *this; // } // // ~Person() {} private: xp::string _name; int _age; }; int main() { Person s1; Person s2 = s1; Person s3 = move(s1); // 调用默认的移动构造,默认的移动构造去调用string的移动构造 Person s4; s4 = move(s2); // 调用默认的移动赋值,默认的移动赋值去调用string的移动赋值 return 0; }
9.2、类成员变量初始化
C++11允许在类定义时给成员变量初始缺省值,默认生成构造函数会使用这些缺省值初始化。在前面的类和对象我们有讲过。
class Person{ public: //person(int age):_age(age){} // 非默认 -- 不写这个构造函数就会生成默认的构造函数 private: int _age = 10; }
9.3、强制生成默认成员函数的关键值default
假设你要使用哪个构造函数,但是由于某些原因编译器没有生成,那么这个时候你可以使用关键字default来生成。
比如:我们提供了拷贝构造,就不会生成移动构造了,那么我们可以使用default关键字显示指定移动构造生成。
class Person { public: Person(const char *name = "", int age = 0) : _name(name), _age(age) {} Person(const Person &p) = default; Person(Person &&p) = default; Person& operator=(Person &&p) = default; private: xp::string _name; int _age; }; int main() { Person s1; Person s2 = s1; Person s3 = move(s1); // 调用默认的移动构造,默认的移动构造去调用string的移动构造 Person s4; s4 = move(s2); // 调用默认的移动赋值,默认的移动赋值去调用string的移动赋值 return 0; }
9.4、禁止生成默认成员函数的关键值delete
如果想限制某些默认成员函数的生成,C++98是将该默认成员函数放到private下,并且只声明(这样类内也用不了),即权限设置为private。C++11提供了delete关键字,可以指明该默认成员函数禁止生成。我们成delete修饰的默认成员函数为删除函数。
class Person { public: Person(const char *name = "", int age = 0) : _name(name), _age(age) {} Person(Person &&p) = delete; Person &operator=(Person &&p) = delete; private: xp::string _name; int _age; }; int main() { Person s1; //Person s2 = s1; // 报错,没有默认的移动构造函数,也没有默认的构造函数 //Person s3 = move(s1); // 报错,没有默认的移动构造函数,也没有默认的构造函数 Person s4; //s4 = move(s2); // 报错,没有默认的移动赋值,也没有默认的赋值重载 return 0; }
9.5、继承中的final和override关键字
前面类和对象讲过,这里不再赘述。
10、可变参数模版
10.1、可变参数的使用
C++98中,参数模版是固定的。
// C++98 template<class Arg> void ShowList(Args arg) {}而在C++11中,参数模版是可变的。
用法规则:
// Args是一个模板参数包,args是一个函数形参参数包 // 声明一个参数包Args...args,这个参数包中可以包含0到任意个模板参数。 template<class ...Args> void ShowList(Args... args) {}这里三个点
...的位置一般是:参数模版声明的地方在左边,其他地方一般在右边。上面的args前面有省略号,所以它就是一个可变模版参数,我们把带省略号的参数成为参数包,它里面包含0~N个模版参数。我们无法直接获取args中的每个参数,只能通过展开该参数包来获取每个参数,这是使用可变模版参数的一个主要特点,也是最大的难点,即如何展开参数包。由于语法不支持args[i]来获取每个模版参数,因此我们用一些其他方法来一一获取参数包的值。
方法一:递归函数方式展开参数包(需要编译时递归)
// 编译时递归! // 递归退出条件 template<class T> void Showlist(const T& value) { cout << value << endl; } template<class T, class ...Args> void Showlist(T value, Args... args) { cout << value << " "; Showlist(args...); } int main() { Showlist(1); Showlist(1, 2); Showlist(1, 2, 'a'); Showlist(1, 2, 'a', "hello"); Showlist(1, 2, 'a', "hello", string("你好")); return 0; }方法二:逗号表达式展开参数包
// 可变参数模版的另一种调用 template<class T> void PrintArgs(T val) { cout << val << " "; } template<class ...Args> void Showlist(Args... args) { int arr[] = {(PrintArgs(args), 0)...};// arr初始化的时候调用了PrintArgs cout << endl; } int main() { Showlist(1); Showlist(1, 2, 3); Showlist(1, 2, 3, "hello"); Showlist(1, 2, 3, "hello", 'a'); Showlist(1, 2, 3, "hello", 'a', string("nihao")); return 0; }
10.2、可变参数的应用
库里list的emplace_back:可变参数和右值引用的结合
list.h文件// // Created by 徐鹏 on 2024/4/18. // #ifndef DEMO_04_LIST_H #define DEMO_04_LIST_H #include <iostream> using namespace std; // list的模拟实现(还未完成) namespace xp { // 结点 template<class T> struct ListNode { ListNode<T> *_next; ListNode<T> *_prev; T data; // 构造函数 -- 创建结点 ListNode(const T &val = T()) : _next(nullptr), _prev(nullptr), data(val) { // data(val)调用拷贝构造 } // 这里val的类型是左值 ListNode(T &&val) : _next(nullptr), _prev(nullptr), data(forward<T>(val)) { // data(val)调用拷贝构造 } template<class ...Args> ListNode(Args &&...args) : _next(nullptr), _prev(nullptr), data(forward<Args>(args)...) { // data(val)调用拷贝构造 } }; template<class T, class Ref, class Ptr> class __list_iterator { public: typedef ListNode<T> Node; typedef __list_iterator<T, Ref, Ptr> self; // 迭代器本身 // 这里构造函数为了方便begin和end,直接隐式类型转换 __list_iterator(Node *node) : _node(node) { } Ref operator*() { return _node->data; } Ptr operator->() { return &_node->data; } self &operator++() { _node = _node->_next; return *this; } self operator++(int) { self temp(*this); // 这里*this的类型是self ,调用默认拷贝构造函数!因为是内置类型,不需要自己写 _node = _node->_next; return temp; } self &operator--() { _node = _node->_prev; return *this; } self &operator--(int) { self temp(*this); _node = _node->_prev; return temp; } bool operator!=(const self &s) { return _node != s._node; } bool operator==(const self &s) { return _node == s._node; } // 拷贝构造和析构不需要写,析构不能用,不然结点被删除了 // 比如 lt.begin(),这里的类型就是Node* Node *_node; // 内置类型不能重载++等操作符,因此对这个内置类型进行封装来实现++等功能 }; template<class T> class list { public: typedef ListNode<T> Node; typedef __list_iterator<T, T &, T *> iterator; typedef __list_iterator<T, const T &, const T *> const_iterator; //构造函数 list() { //创建带头节点的双向循环链表 _head = new Node; _head->_next = _head; _head->_prev = _head; } // 拷贝构造函数 list(list<T> <) { // 先创个头节点 _head = new Node; _head->_next = _head; _head->_prev = _head; iterator it = lt.begin(); while (it != lt.end()) { push_back(*it); ++it; } } void swap(list<T> <) { std::swap(_head, lt._head); } // 赋值 list<T> operator=(list<T> lt) { swap(lt); return *this; } iterator begin() { return _head->_next; } iterator end() { return _head; } const_iterator begin() const { return _head->_next; } const_iterator end() const { return _head; } void push_back(const T &val) { // Node *tail = _head->_prev;// 先找到尾 // // // 创建新节点 // Node *newnode = new Node(val); // // tail->_next = newnode; // newnode->_prev = tail; // // newnode->_next = _head; // _head->_prev = newnode; insert(end(), val); } // 这里val的类型是左值 void push_back(T &&val) { // Node *tail = _head->_prev;// 先找到尾 // // // 创建新节点 // Node *newnode = new Node(val); // // tail->_next = newnode; // newnode->_prev = tail; // // newnode->_next = _head; // _head->_prev = newnode; insert(end(), forward<T>(val)); } template<class ...Args> void emplace_back(Args &&...args) { emplace(end(), forward<Args>(args)...); } template<class ...Args> iterator emplace(iterator pos, Args &&...args) { Node *cur = pos._node; Node *prev = cur->_prev; Node *newnode = new Node(forward<Args>(args)...); newnode->_next = cur; newnode->_prev = prev; prev->_next = newnode; cur->_prev = newnode; return newnode; } iterator insert(iterator pos, const T &val) { Node *cur = pos._node; Node *prev = cur->_prev; Node *newnode = new Node(val); newnode->_next = cur; newnode->_prev = prev; prev->_next = newnode; cur->_prev = newnode; return newnode; } // 这里val的类型是左值 iterator insert(iterator pos, T &&val) { Node *cur = pos._node; Node *prev = cur->_prev; Node *newnode = new Node(forward<T>(val)); newnode->_next = cur; newnode->_prev = prev; prev->_next = newnode; cur->_prev = newnode; return newnode; } iterator erase(iterator pos) { assert(pos != _head);// _head这个位置就是end() Node *cur = pos._node; Node *prev = cur->_prev; Node *tail = cur->_next; prev->_next = tail; tail->_prev = prev; delete cur; return tail; } void clear() { // 清空所有数据,只留一个头节点 iterator it = begin(); while (it != end()) { it = erase(begin()); } } ~list() { clear(); if (_head) { delete _head; _head = nullptr; } } private: Node *_head;// 头节点 -- 带头双向循环链表 }; } #endif //DEMO_04_LIST_H
main.cpp文件#include <iostream> #include <list> #include "list.h" using namespace std; namespace xp { class string { public: typedef char *iterator; iterator begin() { return _str; } iterator end() { return _str + _size; } string(const char *str = "") : _size(strlen(str)), _capacity(_size) { // cout << "string(char* str)" << endl; _str = new char[_capacity + 1]; strcpy(_str, str); } // s1.swap(s2) void swap(string &s) { ::swap(_str, s._str); ::swap(_size, s._size); ::swap(_capacity, s._capacity); } // 拷贝构造 -- 没有写右值引用的拷贝构造的时候,左值和右值的拷贝构造都走这个const string& string(const string &s) : _str(nullptr) { cout << "string(const string& s) -- 深拷贝" << endl; string tmp(s._str); swap(tmp); } // 移动构造 string(string &&s) { cout << "string(string &&s) -- 移动语义" << endl; swap(s); // 转移s的资源给*this } // 赋值重载 string &operator=(const string &s) { cout << "string& operator=(string s) -- 深拷贝" << endl; string tmp(s); swap(tmp); return *this; } // 移动赋值 string &operator=(string &&s) { cout << "string& operator=(string&& s) -- 移动语义" << endl; swap(s); return *this; } ~string() { delete[] _str; _str = nullptr; } char &operator[](size_t pos) { assert(pos < _size); return _str[pos]; } void reserve(size_t n) { if (n > _capacity) { char *tmp = new char[n + 1]; strcpy(tmp, _str); delete[] _str; _str = tmp; _capacity = n; } } void push_back(char ch) { if (_size >= _capacity) { size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2; reserve(newcapacity); } _str[_size] = ch; ++_size; _str[_size] = '\0'; } //string operator+=(char ch) string &operator+=(char ch) { push_back(ch); return *this; } const char *c_str() const { return _str; } private: char *_str = nullptr; size_t _size = 0; size_t _capacity = 0; // 不包含最后做标识的\0 }; string to_string(int value) { bool flag = true; if (value < 0) { flag = false; value = 0 - value; } string str; while (value > 0) { int x = value % 10; value /= 10; str += ('0' + x); } if (flag == false) { str += '-'; } std::reverse(str.begin(), str.end()); return str; } } // 把emplace_back的功能放到自己模拟实现的list中 //int main() { // // list <xp::string> lt; // xp::string s1("hello"); // // lt.push_back("dss"); // cout << "---------------------------" << endl; // lt.emplace_back("dss"); // 直接构造 -- 直接给其类的构造函数的参数 // cout << "============================" << endl; // lt.push_back(s1); // cout << "---------------------------" << endl; // lt.emplace_back(s1); // // cout << "============================" << endl; // lt.push_back(move(s1)); // cout << "---------------------------" << endl; // lt.emplace_back(move(s1)); // // cout << "============================" << endl; // cout << "============================" << endl; // // pair<xp::string, xp::string> kv1("xp", "xp"); // pair<xp::string, xp::string> kv2("zl", "zl"); // // list <pair<xp::string, xp::string>> lt1; // lt1.push_back(kv1); // cout << "---------------------------" << endl; // lt1.emplace_back(kv1); // cout << "============================" << endl; // // lt1.push_back(make_pair("hh", "hh")); // cout << "---------------------------" << endl; // lt1.emplace_back(make_pair("hh", "hh")); // cout << "============================" << endl; // // lt1.push_back({"hh", "hh"}); // cout << "---------------------------" << endl; // lt1.emplace_back("hh", "hh"); // 直接构造 -- 直接给其类的构造函数的参数 // // // return 0; //} int main() { xp::list <xp::string> lt; xp::string s1("hello"); lt.push_back("dss"); cout << "---------------------------" << endl; lt.emplace_back("dss"); // 直接构造 -- 直接给其类的构造函数的参数 cout << "============================" << endl; lt.push_back(s1); cout << "---------------------------" << endl; lt.emplace_back(s1); cout << "============================" << endl; lt.push_back(move(s1)); cout << "---------------------------" << endl; lt.emplace_back(move(s1)); cout << "============================" << endl; cout << "============================" << endl; pair<xp::string, xp::string> kv1("xp", "xp"); pair<xp::string, xp::string> kv2("zl", "zl"); xp::list <pair<xp::string, xp::string>> lt1; lt1.push_back(kv1); cout << "---------------------------" << endl; lt1.emplace_back(kv1); cout << "============================" << endl; lt1.push_back(make_pair("hh", "hh")); cout << "---------------------------" << endl; lt1.emplace_back(make_pair("hh", "hh")); cout << "============================" << endl; lt1.push_back({"hh", "hh"}); cout << "---------------------------" << endl; lt1.emplace_back("hh", "hh"); // 直接构造 -- 直接给其类的构造函数的参数 return 0; }

11、lambda表达式
11.1、C++98仿函数和函数指针缺陷
比如我们需要对自定义类型进行排序,需要用户自己定义排序规则:
struct Goods { string _name;// 名字 double _price; // 价格 int _evaluate; // 评价 Goods(const char *str, double price, int evaluate) : _name(str), _price(price), _evaluate(evaluate) {} }; struct ComparePriceLess { bool operator()(const Goods &gl, const Goods &gr) { return gl._price < gr._price; } }; struct ComparePriceGreater { bool operator()(const Goods &gl, const Goods &gr) { return gl._price > gr._price; } }; int main() { vector<Goods> v = {{"苹果", 2.1, 5}, {"香蕉", 3, 4}, {"橙子", 2.2, 3}, {"菠萝", 1.5, 4}}; sort(v.begin(), v.end(), ComparePriceLess()); sort(v.begin(), v.end(), ComparePriceGreater()); return 0; }我们可以看到,这里你需要几个比较规则,就需要几个仿函数,函数指针也一样(这里不解释)。
这样每次都得写几个类,而且功能类似。因此C++11推出了lambda表达式。
11.2、lambda表达式使用
// lambda 表达式使用 int main() { vector<Goods> v = {{"苹果", 2.1, 5}, {"香蕉", 3, 4}, {"橙子", 2.2, 3}, {"菠萝", 1.5, 4}}; // 按价格 sort(v.begin(), v.end(), [](const Goods &gl, const Goods &gr) { return gl._price < gr._price; }); // 按评价 sort(v.begin(), v.end(), [](const Goods &gl, const Goods &gr) { return gl._evaluate < gr._evaluate; }); }下面来讲解lambda表达式使用规则(语法)。
11.3、lambda表达式语法
书写格式:[capture-list] (parameters) mutable -> return-type { statement;}
lambda表达式各部分说明:
- [capture-list]:捕捉列表。该列表总是出现在lambda表达式的最开始,编译器根据[]来判断接下来的代码是否为lambda函数。捕捉列表能捕捉当前行及以上的使用变量供lambda函数使用。
- (parameters):参数列表。和普通函数的参数列表一致,如果没有参数,可以连同()一起省略。
- mutable:默认情况下都是省略的。lambda函数总是一个const函数,mutable可以取消其常量属性(也就是可以修改变量,但但事实是修改不了变量的实参值,只修改了变量的形参值)。使用该修饰符时候,参数列表不为空。
- -> return-type:返回值类型。返回值类型明确的情况下,可以省略,由编译器推导。
- { statement;}:函数体。和普通函数的函数体一样。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。
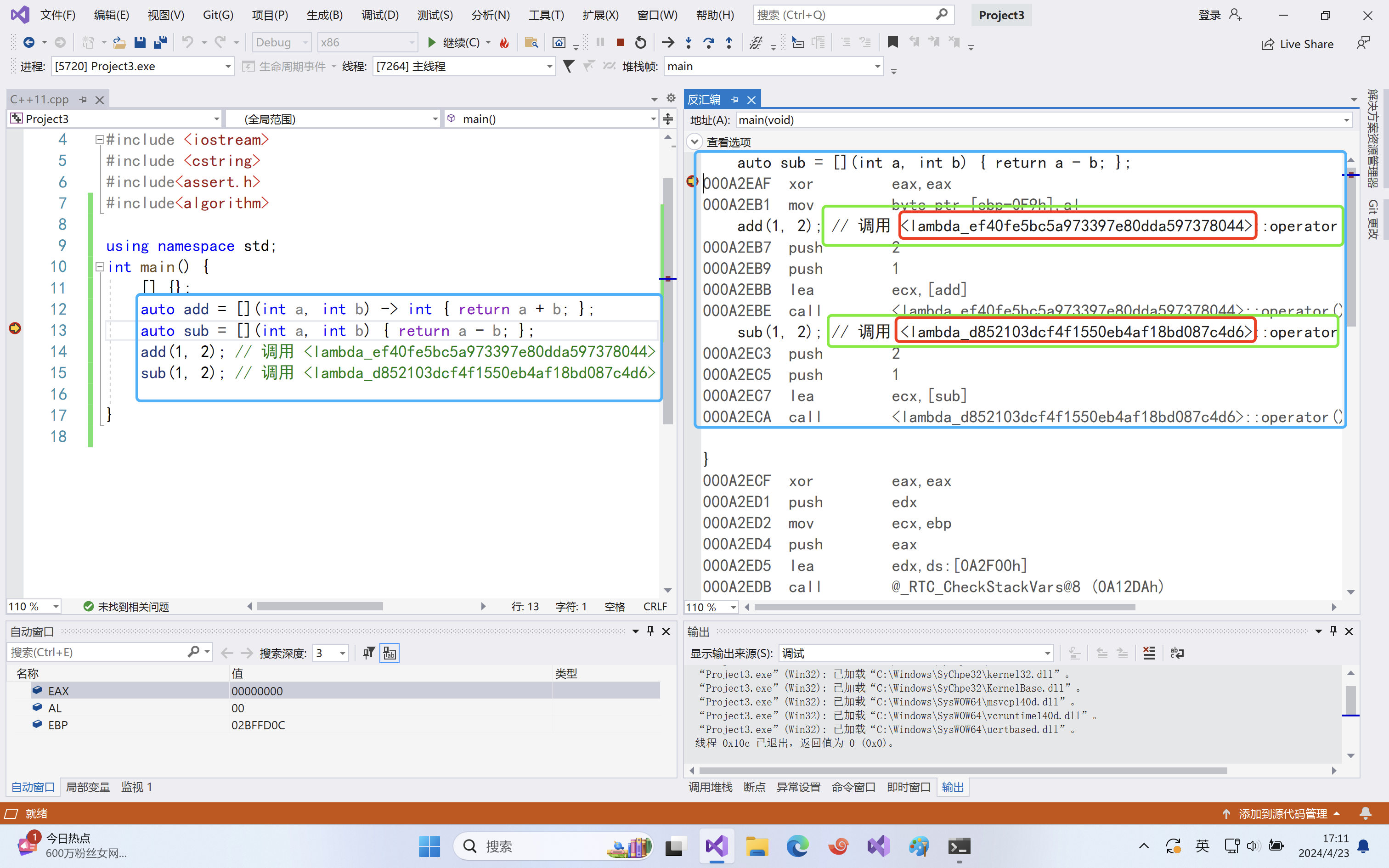
int main() { [] {}; auto add = [](int a, int b) -> int { return a + b; }; auto sub = [](int a, int b) { return a - b; }; cout << add(1, 2) << endl; cout << sub(1, 2) << endl; int a = 3, b = 4; auto ret1 = [=] { return a + b; }; // [=]捕捉当前行及以上所有的临时变量(参数),这里是传值 cout << ret1() << endl; auto ret2 = [&](int c) { return b = a + c; };// [&]捕捉当前行及以上所有的临时变量(参数),这里是传引用 cout << ret2(10) << endl; cout << b << endl; // 也可以混合使用 int c = 20; auto ret3 = [=, &b]mutable { b += a; a++; c++; };// 这里不使用mutable不行,因为a,c都是const([=]传过来就是给他加上const) cout << a << endl; // 因为式传值,不改变 cout << b << endl; // 传引用会改变 cout << c << endl; // 因为式传值,不改变 return 0; }通过上述例子可以看到,lambda表达式实际上可以理解为是一个无名函数,该函数无法直接调用,如果想要直接调用,可以借助auto来将其赋值给一个变量。
需要注意的是:lambda表达式直接不能相互赋值!
int main() { [] {}; auto add = [](int a, int b) -> int { return a + b; }; auto sub = [](int a, int b) { return a - b; }; add(1, 2); // 调用 <lambda_ef40fe5bc5a973397e80dda597378044>::operator() (0862100h) sub(1, 2); // 调用 <lambda_d852103dcf4f1550eb4af18bd087c4d6>::operator() (0862E20h) return 0; }
可以看到,这里add和sub调用的operator()的类型是不一样的。
11.4、函数对象和lambda表达式
函数对象,又叫仿函数。即类内部是重载了operator()运算符的类对象。
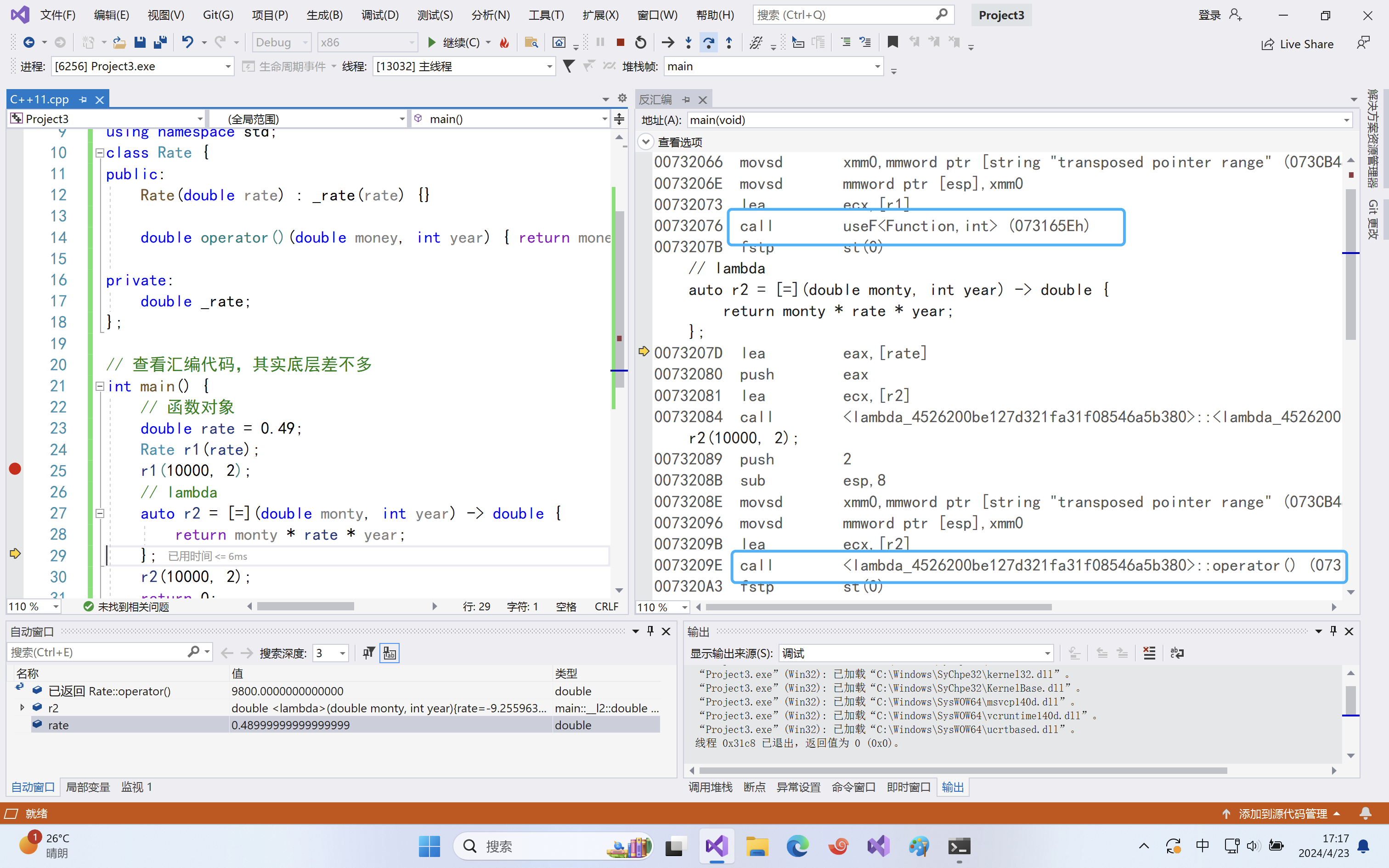
class Rate { public: Rate(double rate) : _rate(rate) {} double operator()(double money, int year) { return money * _rate * year; } private: double _rate; }; // 查看汇编代码,其实底层差不多 int main() { // 函数对象 double rate = 0.49; Rate r1(rate); r1(10000, 2); // lambda auto r2 = [=](double monty, int year) -> double { return monty * rate * year; }; r2(10000, 2); return 0; }
实际在底层编译器对于lambda表达式的处理方式,完全就是按照函数对象的方式处理的,即:如果定义了一个lambda表达式,编译器会自动生成一个类,在该类中重载了operator()。
12、包装器
12.1、function包装器
function包装器,也叫作适配器。C++中的function本质是一个类模板,也是一个包装器。
为什么需要包装器呢?
来看以下代码:
template<class F, class T> double useF(F f, T t) { static int count = 0; cout << "count :" << ++count << endl; cout << "count :" << &count << endl; return f(t); } double func(double i) { return i / 2; } struct Function { double operator()(double d) { return d / 3; } }; // 这里实例化了三份 int main() { // 函数名 cout << useF(func, 1) << endl; // 函数对象 cout << useF(Function(), 1) << endl; // lambda cout << useF([](double d) -> double { return d / 3; }, 1) << endl; return 0; }运行后发现这里是实例化了三份useF函数,因为count的地址有三份。
当使用包装器以后,只需要实例化一份!
包装器类模版原型:
std::function在头文件<functional> // 类模板原型如下 template<class T> function; // undefined template<class Ret, class... Args> class function<Ret(Args...)>; 模板参数说明: Ret:被调用函数的返回类型 Args…:被调用函数的形参
12.2、function包装器的使用
int f(int a, int b) { return a + b; } struct Functor { public: int operator()(int a, int b) { return a + b; } }; class Plus { public: static int plusi(int a, int b) { return a + b; } double plusd(double a, double b) { return a + b; } }; // 包装器使用 int main() { // 函数名(函数指针) std::function<int(int, int)> func1 = f; cout << func1(1, 2) << endl; // 函数对象 std::function<int(int, int)> func2 = Functor(); cout << func2(1, 2) << endl; // lambda表达式 std::function<int(int, int)> func3 = [](const int a, const int b) { return a + b; }; cout << func3(1, 2) << endl; // 类的静态成员函数 std::function<int(int, int)> func4 = &Plus::plusi; cout << func4(1, 2) << endl; // 类的非静态成员函数 std::function<double(Plus, double, double)> func5 = &Plus::plusd; cout << func5(Plus(), 1.1, 2.2) << endl; return 0; }解决前面实例化三份的问题。
template<class F, class T> double useF(F f, T t) { static int count = 0; cout << "count :" << ++count << endl; cout << "count :" << &count << endl; return f(t); } double func(double i) { return i / 2; } struct Function { double operator()(double d) { return d / 3; } }; int main() { // 函数名 function<double(double)> func1 = func; cout << useF(func1, 1) << endl; // 函数对象 function<double(double)> func2 = Function(); cout << useF(func2, 1) << endl; // lambda function<double(double)> func3 = [](double d) -> double { return d / 3; }; cout << useF(func3, 1) << endl; return 0; }这里输出的结果,count的地址都是一样的,说明只实例化了一份useF函数。
12.3、bind绑定
std::bind函数定义在头文件中,是一个函数模板,它就像一个函数包装器(适配器),接受一个可调用对象(callable object),生成一个新的可调用对象来“适应”原对象的参数列表。一般而言,我们用它可以把一个原本接收N个参数的函数func,通过绑定一些参数,返回一个接收M个(M可以大于N,但这么做没什么意义)参数的新函数。同时,使用std::bind函数还可以实现参数顺序调整等操作。这里涉及到一个占位符:std::placeholders,这个占位符的个数不限,可以是:
std::placeholders::_1,std::placeholders::_2,std::placeholders::_3 ...bind原型如下:
// 原型如下: template <class Fn, class... Args> /* unspecified */ bind (Fn&& fn, Args&&... args); // with return type (2) template <class Ret, class Fn, class... Args> /* unspecified */ bind (Fn&& fn, Args&&... args);bind的使用:
int f(int a, int b) { return a + b; } struct Functor { public: int operator()(int a, int b) { return a + b; } }; class Plus { public: static int plusi(int a, int b) { return a + b; } double plusd(double a, double b) { return a - b; } }; // bind绑定 int main() { // 类的静态成员函数 std::function<int(int, int)> func4 = &Plus::plusi; cout << func4(1, 2) << endl; // 类的非静态成员函数 std::function<double(double, double)> func5 = bind(&Plus::plusd, Plus(), placeholders::_1, placeholders::_2); cout << func5(1.1, 2.2) << endl; // 参数调换顺序 std::function<double(double, double)> func6 = bind(&Plus::plusd, Plus(), placeholders::_2, placeholders::_1); cout << func6(1.1, 2.2) << endl; return 0; }
OKOK,C++新特性就到这里。如果你对Linux和C++也感兴趣的话,可以看看我的主页哦。下面是我的github主页,里面记录了我的学习代码和leetcode的一些题的题解,有兴趣的可以看看。


















 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











