






今天碰到一个匹配数据失败的问题,用谷歌浏览器的xpath插件,在网页上能匹配到数据,复制到代码中,匹配为空。

解决办法
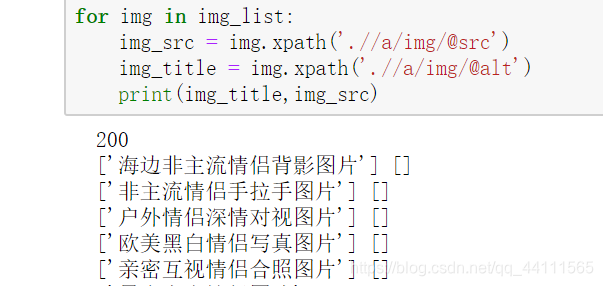
将响应的代码保存下来,查看响应的html页面对应的位置有啥区别

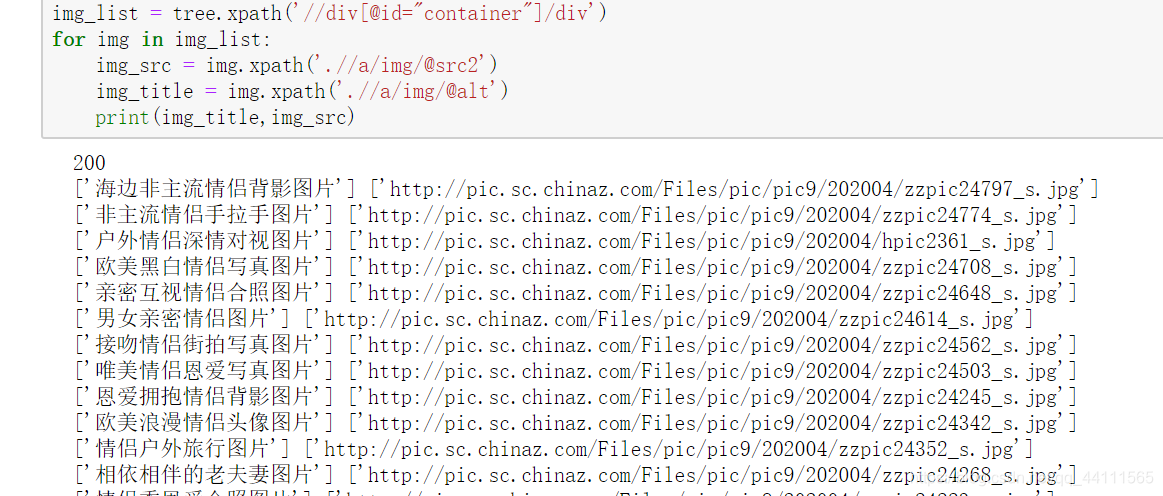
这里可以看到。我们得到的页面中跟网页上显示的有点不一致,网页上的是src,我们得到的是src2,所以修改我们的xpath选择器就可以匹配出我们需要的数据。
总结
出现这种情况是因为,当网站有很多图片时,网站会用到图片懒加载技术,即当网站图片过多时,出现在可视范围内的图片才会被加载,当我们用requests请求时,请求的数据不会出现在可视范围内,所有我们需要请求的是还未加载的数据,即src2.
这也算得上是一种反扒机制了吧,遇到问题不要慌,分析一下,只要思想不滑坡,办法总比困难多。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









