







模型量化的原理与实践 ——基于YOLOv5实践目标检测的PTQ与QAT量化
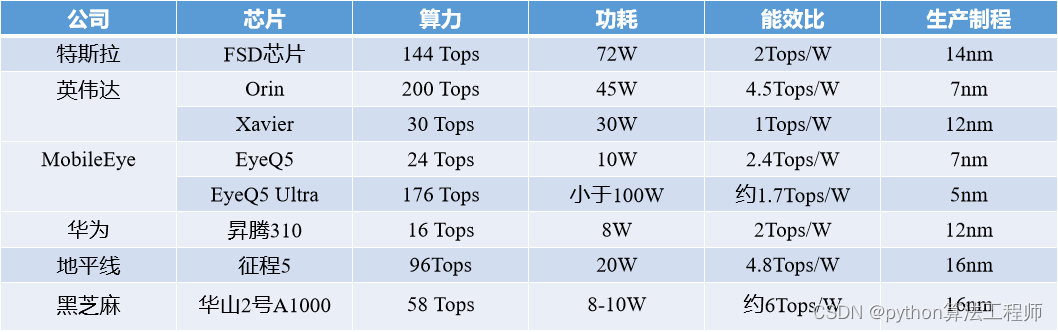
1、Tops是什么意思?
1TOPS代表处理器每秒可进行一万亿次(10^12)操作
3、什么是定点数
大家都知道,数字既包括整数,又包括小数,如果想在计算机中,既能表示整数,也能表示小数,关键就在于这个小数点如何表示?
于是计算机科学家们想出一种方法,即约定计算机中小数点的位置,且这个位置固定不变,小数点前、后的数字,分别用二进制表示,然后组合起来就可以把这个数字在计算机中存储起来,这种表示方式叫做定点表示法,用这种方法表示的数字叫做定点数。
也就是说「定」是指固定的意思,「点」是指小数点,所以小数点位置固定的数即为定点数。
定点数的表示方式如下:
其中S表示有符号(Signed),n和m分别代表定点数格式中的整数和小数位数,但是考虑到二进制的补码形式表示负数,总的位数为n+m+1,比如S2.13比对应n=2,m=13,二进制的长度为n+m+1=16,也就是说用的16位的定点化表示。
4、定点数转换
定点数转换涉及将实数值转换为定点数值或将定点数值转换为实数值。
实数转换为定点数
将实数转换为定点数需要确定小数点的位置和位数,以及表示范围和精度。
例如,将实数3.1415926转换为小数点位置在第三位上、精度为0.01的定点数,需要先将实数乘以100,得到314.15926,然后将其四舍五入为314,最后加上小数点,得到3.14,即表示3.1415926的定点数值。
定点数转换为实数
将定点数转换为实数需要根据小数点位置和位数进行反向计算。
例如,将小数点位置在第三位上、精度为0.01的定点数3.14转换为实数,需要先将定点数除以100,得到0.0314,然后将其加上小数点后面的数字乘以相应的精度,得到3.1414,即表示定点数3.14对应的实数值。
在实际应用中,定点数转换常用于数字信号处理、嵌入式系统、计算机图形学等领域。对于一些特殊的应用场景,也可以采用其他定点数表示方式,如Q格式、S格式等。
2、什么是量化?
模型量化是指将深度学习模型中的浮点数参数和计算操作转换为定点数参数和计算操作的过程。模型量化可以减小模型的存储空间和计算量,提高模型在移动设备和嵌入式系统上的部署效率。
在模型量化中,浮点数参数和计算操作被转换为定点数参数和计算操作。定点数通常采用8位整数或16位整数表示,可以使用卷积、矩阵乘法等计算操作进行模型推理。
模型量化的过程通常包括以下几个步骤:
选择量化方法,包括权重量化、激活量化、全精度量化、混合精度量化等。
确
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









