




内置函数总结
- 最大值函数max 最小值函数min
- 列表使用方法:max(list1)
- 求和函数 sum
- 列表使用方法: sum(list1)
- 求绝对值函数 abs
- 使用方法: abs(数字)
- 将字母转换为ASCII码对应的数字函数 ord
- 使用方法:ord(字母)
- 十进制转十六进制 使用函数 hex
- 使用方法: hex(十进制数字)
- 十进制转二进制 使用函数 bin
- 使用方法:bin(十进制数字)
- 幂运算 pow函数
- 使用方法:x的y次方 pow(x,y)
- 统计次数函数 count函数
- 列表使用方法:统计1出现的次数 list1.count(‘1’)
- 字符串使用方法:统计1出现的次数 x.count(‘1’)
- 找到列表中某一元素对应的下标 index函数
- 列表使用方法: list1.index(某一元素)
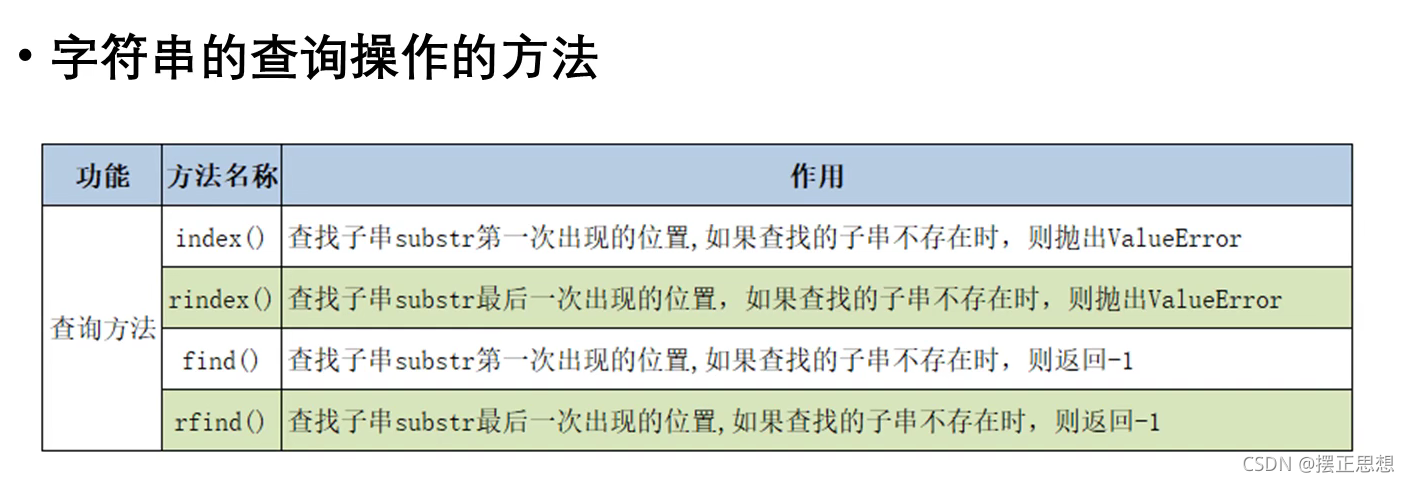
- 字符串的查找 用find函数
- 使用方法:查找k是否在字符串kan里,x = 'kan' ,x.find('k') #0 如果不在的话返回-1
- 注意,字符串可以用index和find,但是列表只能用index
- index找不到对应元素下标会报错,find不会报错,会返回-1
- 判断字符串是否只包含字母 用isalpha函数,返回值为True或者False
- 判断字符串是否只包含数字 用isdigit函数,返回值为True或者False
- 判断字符串是否只包含数字 用isspace函数,返回值为True或者False
- 使用方法 字符串.isalpha()
输出函数print
可以输出数字
可以输出字符串
可以输出含有运算符的表达式
可以将数据输出到文件中 a+如果文件不存在就创建,存在就在文件内容的后面继续追加
不进行换行输出(输出内容在一行中)
# 关心则乱
# 时间:2021/10/16 19:48
#print函数
#可以输出数字
print(98.5)
print(520)
#可以输出字符串
print('hello world')
print("hello world")
#可以输出含有运算符的表达式
print(3+1)
#将数据输出到文件中 a+如果文件不存在就创建,存在就在文件内容的后面继续追加
fp = open("D://text.text",'a+')
print('hello world',file = fp)
fp.close()
#不进行换行输出(输出内容在一行中)
print('hello','666','world')
切片
0:2:1
取值取首不取尾,中间用分号,1是步长(通俗理解就是1是一个一个往后查,2是两个两个往后查)
转义字符与原字符
\n 换行 newline光标移动到下一行的开头
\r 回车 return光标移动到本行的开头
\t 水平制表符 tab键,光标移动到下一组4个空格的开始处
\b 退格 键盘上的backspace键,回退一个字符
r 原字符,不希望字符串中的转义字符起作用;在字符串之前加上r或R,注意:最后一个字符不能是反斜线,但是可以是两个反斜线
# 关心则乱
# 时间:2021/10/16 20:28
#换行 \n newline光标移动到下一行的开头
print('hello\nworld')
#回车 \r return光标移动到本行的开头
print('hello\rworld')
#水平制表符 \t tab键,光标移动到下一组4个空格的开始处
print('hello\tworld')
#退格 \b 键盘上的backspace键,回退一个字符
print('hello\bworld')
print('http:\\\\www.biadu.com')
print('小明:\'老师好\'')
#原字符,不希望字符串中的转义字符起作用;在字符串之前加上r或R,注意:最后一个字符不能是反斜线
print(r'hello\nworld')
#错误案例print(r'hello\nworld\')
#但是可以是两个反斜线
print(r'helloworld\\')
标识符和保留字
保留字:有特定的意义,给任何对象起名字的时候都不能用
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
标识符:变量、函数、类、模块和其它对象起的名字就叫标识符
规则: 字母、数字、下划线
不能以数字开头
不能是保留字
严格区分大小写
变量的定义和使用
变量由三部分组成
标识:表示对象所存储的内存地址,使用内置函数id(obj)来获取
类型:表示的是对象的数据类型,使用内置函数type(obj)来获取
值:表示对象所存储的具体数据,使用print(obj) 可以将值进行打印输出
# 关心则乱
# 时间:2021/10/17 11:12
name = '康'
print(id(name))
print(type(name))
print(name)
当多次赋值之后,变量名会指向新的空间
# 关心则乱
# 时间:2021/10/17 11:21
name = 'kang'
print(name)
name = '康'
print(name)
数据类型
常用的数据类型
整数类型 int
浮点数类型 float
布尔类型 bool
字符串类型 str
整数类型
英文为Integer 简写为int 可以表示整数、负数和零
整数的不同进制表示方式
十进制 默认的进制
二进制 以0b开头
八进制 以0o开头
十六进制 以0x开头
# 关心则乱
# 时间:2021/10/17 11:45
print('十进制',118)
print('二进制',0b0110)
print('八进制',0o112)
print('十六进制',0xA12)
浮点类型
浮点数由整数部分和小数部分组成
浮点数存储不精确性
使用浮点数进行计算时,可能会出现小数位数不确定的情况,解决方案,导入模 块decimal
# 关心则乱
# 时间:2021/10/17 20:09
n1 = 1.1
n2 = 2.2
print(n1+n2) #3.3000000000000003
from decimal import Decimal
print(Decimal('1.1')+Decimal('2.2')) #3.3
布尔类型
用来表示真或假的值
True表示真,False表示假
布尔值可以转化为整数
True:1
False:0
# 关心则乱
# 时间:2021/10/17 19:59
t1 = True
t2 = False
print(t1,type(t1))
print(t2,type(t2))
print(t1+1) #2
print(t2+1) #1
字符串类型
字符串又被称为不可变的字符序列
可以使用单引号,双引号,三引号来定义
单引号和双引号定义的字符串必须在一行
三引号定义的字符串可以分布在连续的多行
# 关心则乱
# 时间:2021/10/17 20:19
print('关心则乱')
print("关心则乱")
print('''关心
则乱''')
print("""关心
则乱""")
类型转换
str():将其他类型转换成字符串,也可用引号转换
# 关心则乱
# 时间:2021/10/17 20:31
n1 = 12
n2 = 12.3
n3 = True
print(type(n1),type(n2),type(n3))
print(str(n1),str(n2),str(n3))
int():将其他数据类型转换成整数,文字类和小数类字符串,无法转化成整数
# 关心则乱
# 时间:2021/10/17 20:39
n1 = '关心'
n2 = '12.5'
n3 = '15'
n4 = True
n5 = 12.6
print(type(n1),type(n2),type(n3),type(n4),type(n5))
#print(int(n1)) 报错
#print(int(n2)) 报错
print(int(n3))
print(int(n4))
print(int(n5))
float():将其他数据类型转换成浮点数,文字类字符串无法转
# 关心则乱
# 时间:2021/10/17 20:43
n1 = 12
n2 = '关心'
n3 = '12.3'
n4 = '12'
n5 = True
print(type(n1),type(n2),type(n3),type(n4),type(n5))
print(float(n1)) #12.0
#print(float(n2)) 文字型字符串报错
print(float(n3)) #12.3
print(float(n4)) #12.0
print(float(n5)) #1.0
Python中的注释
注释:
在代码中对代码的功能进行解释说明的标注性文字,可以提高代码的可读性
注释的内容会被Python解释器忽略
通常包括三种类型的注释
单行注释:以#开头,直到换行结束
多行注释:并没有单独的多行注释,将一对三引号之间的代码称为多行注释
中文编码声明注释:在文件开头加上中文声明注释,用以指定源码文件的编码格 式,#coding:gbk
#coding:gbk
# 关心则乱
# 时间:2021/10/17 20:56
""" 我是多行
注释"""
#我是单行注释
input函数
input函数的介绍
作用:接收来自用户的输入
返回值类型:str
值的存储:使用=对输入的值进行存储
# 关心则乱
# 时间:2021/10/17 21:15
s1 = input('请输入一个数')
print(s1)
print(type(s1)) #<class 'str'>
Python中的运算符
算数运算符
加 +
减 -
乘 *
除 /
幂运算 **
取余 % 注意:一正一负计算公式 :余数 = 被除数-除数*商, 比如9%-4 取余 9-(-4)*(-3)结果为 -3
取整 // 注意:一正一负向下取整 比如:9//-4 结果为 -3
# 关心则乱
# 时间:2021/10/18 14:30
print(1+1) #2
print(1-1) #0
print(2*3) #6
print(8/4) #2.0
print(2**3) #8
print(8//6) #1
print(8%6) #2
print(8//-6) #-2 向下取整
print(8%-6) #-4 计算公式:被除数-除数*商
赋值运算符
=
执行顺序:从右到左
支持链式赋值:a=b=c=20
支持参数赋值:+=,-=,*=,/=,//=,%=
支持系列解包赋值:a,b,c = 20,30,40 数据交换:a,b = b,a
# 关心则乱
# 时间:2021/10/18 14:56
a,b = 20,30
print(a,b)
a,b = b,a #数据交换
print(a,b)
比较运算符
> < >= <= !=
== 对象value的比较
is , is not 对象id的比较
# 关心则乱
# 时间:2021/10/18 15:11
a = 10
b = 20
print(a>b) #False
print(a<b) #True
c = 10
print(a is c) #True
list1 = [1,2,3,4]
list2 = [1,2,3,4]
print(list1 is list2) #False is比较的是id,list1和list2的id不相等,所以是False
print(id(list1))
print(id(list2))
布尔运算符
布尔运算符:对于布尔值之间的运算
and
or
not
in
not in
# 关心则乱
# 时间:2021/10/18 15:20
n1 = 'hello world'
print('h' in n1) #True
print('h' not in n1) #False
位运算符
将数据转成二进制进行运算
位与& 对应数位都是1,结果数位才是1,否则为0
位或| 对应数位都是2,结果数位才是0,否则为1
左移位运算符<< 高位溢出舍弃,低位补0 左移1位相当于乘2
右移位运算符>> 低位溢出舍弃,高位补0 右移1位相当于除2
# 关心则乱
# 时间:2021/10/18 15:46
print(4<<1) #8
print(4>>1) #2
运算符的优先级
括号 > 算数运算 > 位运算 > 比较运算 > 布尔(逻辑)运算 > 赋值运算
对象的布尔值
python一切皆对象,所有对象都有一个布尔值
获取对象的布尔值,使用内置函数bool()
以下对象的布尔值为False
False
数值0
None
空字符串
空列表
空元祖
空字典
空集合
# 关心则乱
# 时间:2021/10/18 16:12
print(bool(False))
print(bool(0))
print(bool(None))
print(bool(''))
print(bool([]))#空列表
print(bool(list()))#空列表
print(bool(()))#空元组
print(bool(tuple()))#空元组
print(bool({}))#空字典
print(bool(dict()))#空字典
print(bool(set()))#空集合
程序的组织结构
顺序结构
程序从上到下顺序地执行代码,中间没有任何的判断和跳转,直到程序结束
分支结构
单分支结构
语法结构: if 条件表达式 :
条件执行体
# 关心则乱
# 时间:2021/10/18 16:30
money = 1000
print('当前余额为',money)
s = int(input('请输入取款金额:'))
if money >= s :
print('取款成功','余额为',money-s)
双分支结构
语法结构: if 条件表达式:
条件执行体1
else:
条件执行体2
# 关心则乱
# 时间:2021/10/19 13:39
#判断奇数还是偶数
s = int(input('请输入一个整数:'))
if s%2==0:
print(s,'是一个偶数')
else:
print(s,'是一个奇数')
多分支结构
语法结构:if 条件表达式1:
条件执行体1
elif 条件表达式2:
条件执行体2
elif 条件表达式N:
条件执行体N
else:
条件执行体N+1
# 关心则乱
# 时间:2021/10/19 13:48
s = int(input('请输入一个整数:'))
if s>=90 and s<=100:
print('A')
elif s>=80 and s<=89:
print('B')
elif s>=70 and s<=79:
print('C')
elif s>=60 and s<=69:
print('D')
elif s>=0 and s<=59:
print('E')
else:
print('输入的数字必须大于等于0且小于等于100')
嵌套if
语法结构:
if 条件表达式1:
if 内层条件表达式:
内层条件执行体1
else:
内层条件执行体2
else:
条件执行体
# 关心则乱
# 时间:2021/10/19 14:30
answer = (input('您是会员吗?y/n'))
money = int(input('你的消费金额是多少?'))
if answer=='y':
if money>=200:
print('打八折,支付',money*0.8)
elif money>=100:
print('打九折,支付',money*0.9)
else:
print('不打折,支付',money)
else:
print('不打折,支付',money)
条件表达式
条件表达式是if...else的简写
语法结构:
x if 判断条件 else y
运算规则:
如果判断条件为True,条件表达式的返回值为x,否则条件表达式的返回值为False
# 关心则乱
# 时间:2021/10/19 15:20
s = int(input('请输入一个整数:'))
print(str(s)+'是一个偶数' if s%2==0 else str(s)+'是一个奇数')
循环结构
while循环
语法结构:
while 条件表达式:
条件执行体(循环体)
# 关心则乱
# 时间:2021/10/19 15:50
#0到4的累加和
i = 0
sum = 0
while i<=4:
sum+=i
i = i+1
print(sum)
循环结构
for-in循环
in表达从(字符串、序列等)中依次取值,又称为遍历
for-in遍历的对象必须是可迭代对象
for-in的语法结构
for 自定义的变量 in 可迭代对象
循环体
如果循环体内不需要访问自定义变量,可以将自定义变量替代为下划线
# 关心则乱
# 时间:2021/10/19 16:07
#使用for循环,计算1到100之间的偶数和
sum = 0
for i in range(1,101):
if not bool(i%2):
sum+=i
print(sum)
pass语句
语句什么都不做,只是一个占位符,用在语法上需要语句的地方
range()函数
range()函数
用于生成一个整数序列
range(开始,结束,步长) 步长默认为1
流程控制语句break
break语句:
用于结束循环结构,通常与分支结构if一起使用
for .... in ... :
....
if ...:
break
while .... :
....
if ... :
break
# 关心则乱
# 时间:2021/10/21 14:18
a = int(input('请输入密码:'))
for i in range(2):
if a == 8888:
print('密码正确')
break
else:
a = int(input('密码错误,请重新输入:'))
# 关心则乱
# 时间:2021/10/21 14:27
a = 1
pwd = int(input('请输入密码:'))
while a<=2:
if pwd == 8888:
print('密码正确')
break
else:
pwd = int(input('密码错误,请重新输入:'))
a+=1
流程控制语句continue
continue语句
用于结束当前循环,进入下一次循环,通常与分支结构中的if一起使用
# 关心则乱
# 时间:2021/10/21 14:39
#输出1到50之间5的倍数
for i in range(1,51):
if i%5!=0:
continue
print(i)
else语句
else语句:与else语句配合使用的三种情 况
if.... :
....
else:
....
while ... :
....
else:
....
for ....
....
else:
....
a = int(input('请输入密码:'))
for i in range(2):
if a == 8888:
print('密码正确')
break
else:
a = int(input('密码错误,请重新输入:'))
else:
print('对不起,三次密码均输入错误')
嵌套循环
循环结构中又嵌套了另外的完整的循环结构,其中内层循环作为外层循环的循环体执行
# 关心则乱
# 时间:2021/10/21 14:57
#打出乘法口诀表
for i in range(9):
for j in range(1,i+1):
print(i,'*',j,'=',i*j,end='\t')
print()
二重循环中的break和continue
二重循环中的break和continue用于控制本层循环
列表
列表的创建 list1 = [ 'hello' , 'world' , 55] list2 = list([ 'hello' , 'world' , 55])
列表的特点
列表元素按顺序有序排序
索引映射唯一个数据
列表可以存储重复数据
任意数据类型混存
根据需要动态分配和回收内存
列表的查询操作
获取列表中指定元素的索引 index()
如果列表中存在N个相同的元素,只返回相同元素中的第一个元素的索引
还可以在指定的start和stop之间查找
获取列表中的单个元素
正向索引从0到N-1
逆向索引从-N到-1
获取列表中的多个元素
语法格式 列表名[开始:结束:步长]
如果步长为负数,则从开始往前计算切片
列表元素的判断及遍历
判断指定元素在列表中是否存在
元素 in 列表名
元素 not in 列表名
列表元素的遍历
for 迭代变量 in 列表名
列表的切片
[x,y,z]
x起始索引y终止索引(注意,这个索引对应的值是取不到的)
z是步长
例子: list1 = [4,7,8,3,5,2]
print(list1[0:2:1]) # [4, 7]
# 关心则乱
# 时间:2021/10/21 15:45
list1 = ['hello',23,'world','康','hello']
print(list1.index('hello')) #0
print(list1.index('hello',1,5)) #4
# 关心则乱
# 时间:2021/10/21 15:55
list1 = ['hello','baidu',555]
print(list1[0])
print(list1[-1])
# 关心则乱
# 时间:2021/10/21 19:56
list1 = [10,20,30,40,50,60,70,80]
print('原列表:',list1)
print(list1[::-1])
# 关心则乱
# 时间:2021/10/21 20:38
list1 = [1,2,4,5,6]
print(5 in list1)
print(1 not in list1)
for i in list1:
print(i)
列表元素的添加操作
append() 在列表的末尾添加一个元素
extend() 在列表的末尾至少添加一个元素
insert() 在列表的任意位置添加一个元素
切片 在列表的任意位置添加至少一个元素
# 关心则乱
# 时间:2021/10/21 20:50
list1 = [10,20,30,40]
print('原列表',list1)
#append在末尾加一个元素
list1.append(100)
print(list1)
#extend可以添加多个元素
list2 = [70,80]
list1.extend(list2)
print(list1)
#insert在任意位置添加元素
list1.insert(0,'hello')
print(list1)
#切片操作是把原列表的部分给切掉,然后加上新的列表
list1[1:] = list2 #原列表索引1后面的数据切掉,然后加上新列表list2
print(list1)
列表元素的删除操作
remove() 一次删除一个元素,重复元素只删除第一个,元素不存在抛出ValueError
pop() 删除一个指定索引位置上的元素;不指定索引,删除列表中最后一个元素
比如指定删除列表第一个元素,list1.pop(0)
切片 一次至少删除一个元素
clear() 清空列表
del 删除列表
# 时间:2021/10/21 21:26
list1 = [10,20,30,40,50,60]
print('原列表',list1)
list1.remove(10)
print(list1)
list1.pop()
print(list1)
list1[1::] = []
print(list1)
list1.clear()
print(list1)
del list1
列表元素的修改操作
# 关心则乱
# 时间:2021/10/21 21:44
list1 = [10,20,30,40,50]
list1[1] = 55
print(list1)
list1[0:2] = [88,99,66]
print(list1)
列表元素的排序操作
列表元素的排序操作
调用sort()方法,默认是按照从小到大的顺序进行排序,可以指定reverse=True,进行降序排序
调用内置函数sorted(),默认升序,指定 reverse=True进行降序,会产生新的列表
sort 和 sorted的区别
- sort() 是列表对象的方法,直接对列表进行排序,不会返回一个新的列表;而 sorted() 是 Python 内置的函数,能够对任何可迭代对象进行排序,并返回一个新的列表
- sort() 会改变原来列表的顺序,因此它是原地排序;而 sorted() 不会改变原来列表的顺序,因此它是非原地排序
-
sort() 没有返回值,因此无法将排序结果赋给一个变量;而 sorted() 会返回一个新的列表,可以将结果赋给一个变量。
# 关心则乱
# 时间:2021/10/22 16:08
list1 = [1,5,3,2,7,4,9]
list1.sort(reverse=True)
print(list1)
list12 = sorted(list1,reverse=True)
print(list12)
列表生成式
语法格式
list1 = [i for i in range(1,11)]
# 关心则乱
# 时间:2021/10/22 16:40
list1 = [i for i in range(1,11)]
print(list1)
字典
Python内置的数据结构之一,与列表一样是一个可变序列
以键值对的方式存储数据,字典是一个无序的序列
Python中的字典是根据key查找value所在的位置
字典的创建
常用的方式:使用花括号
使用内置函数dict()
# 关心则乱
# 时间:2021/10/22 17:02
score = {'张三':100,'李四':22,'王五':56}
print(score)
score1 = dict(张三=100,李四=22,王五=56)
print(score1)
n1 = dict(name='kang',age=22)
print(n1)
n2 = {'name':'kang','age':22}
print(n2)
字典中元素的获取
[]取值与使用get()取值的区别
[]如果字典中不存在指定的key,抛出keyError异常
get()方法取值,如果字典中不存在指定的key,不会抛出异常,而是返回None,可以通过参数设置默认的value
# 关心则乱
# 时间:2021/10/22 17:35
s=dict(name='kang',age=22)
print(s)
print(s.get('name'))
print(s['name'])
print(s.get('heigh')) #None
字典元素的增_删_改操作
key的判断 in not in
字典元素的删除 比如 del scores['张三']
字典元素的新增 比如 scores['kang'] = 90
# 关心则乱
# 时间:2021/10/22 19:24
scores = {'张三':80,'李四':60,'王五':90}
print(scores)
#删
del scores['李四']
print(scores)
#增
scores['kang'] = 20
print(scores)
#改
scores['王五']=10
print(scores)
#清空
scores.clear()
print(scores)
获取字典视图
keys() 获取字典中所有的key
values() 获取字典中所有的value
items() 获取字典中所有的key,value对
# 关心则乱
# 时间:2021/10/22 19:36
scores = {'张三':56,'李四':89,'王五':80}
keys = scores.keys()
print(list(keys))
values = scores.values()
print(list(values))
items = scores.items()
print(list(items))
字典元素的遍历
for item in scores:
print(item)
# 关心则乱
# 时间:2021/10/22 19:44
s = {'张三':56,'李四':89,'王五':90}
for key in s:
print(key,s[key])
字典的特点
字典中的所有元素都是一个 key-value对,key不允许重复,value可以重复
字典中的元素是无序的
字典中的key必须是不可变对象
字典也可以根据需要动态的伸缩
字典会浪费较大的内存,是一种使用空间换时间的数据结构
字典生成式
{key:value for key,value in zip (key,value)}
# 关心则乱
# 时间:2021/10/22 20:16
key = ['张三','李四']
value = [85,62]
s = {key:value for key,value in zip(key,value)}
print(s)
元组
元组:Python内置的数据结构之一,是一个不可变序列
不可变序列与可变序列
不可变序列:字符串、元组,没有增删改操作
可变序列:列表、字典 对序列执行增删改操作,对象地址不发生更改
元组可以相加
t1 = (1,2,3)
t2 = (4,5,6)
t3 = t1 + t2
那么 t3 = (1,2,3,4,5,6)
元组的创建方式
直接用小括号
使用内置函数tuple()
注意:只包含一个元组的元素需要使用逗号和小括号
tuple() 可以直接把列表转为原组
# 关心则乱
# 时间:2021/10/22 20:30
t = (25,'kang',85)
print(t)
t2 = tuple((666,89,55))
print(t2)
t3=(8,)
print(t3)
print(type(t3))
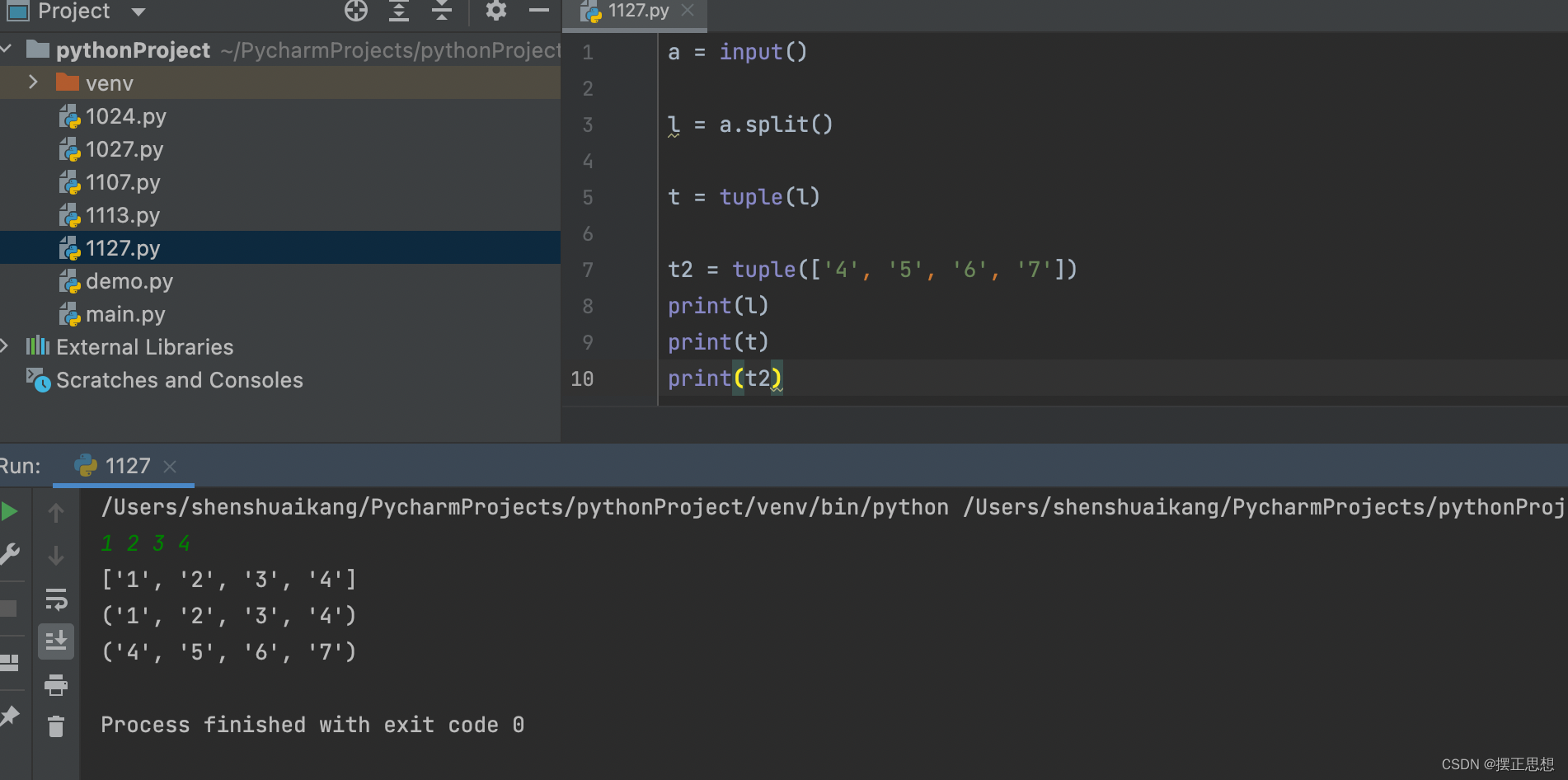
元组的遍历
元组是可迭代对象,所以可以使用for...in进行遍历
# 关心则乱
# 时间:2021/10/22 20:53
t = ('hello',56,23)
for i in t:
print(i)
集合
集合
Python语言提供的内置数据结构
与列表、字典一样都属于可变类型的序列
特点:无序、不可重复
集合的创建方式
直接{}
使用内置函数set() 注意:创建空集合必须用set(),不能用{}
s2 = set([1,2,3,4])
print(s2) #{1, 2, 3, 4}
s3 = set((5,9,7,8))
print(s3) #{8, 9, 5, 7}
s4 = set('python')
print(s4) #{'n', 'o', 'y', 'p', 'h', 't'}
s5 = set({5,6,7,8,9})
print(s5) #{5, 6, 7, 8, 9}
#空集合
s6 = set()
print(s6,type(s6)) #set() <class 'set'>
集合的增_删操作
集合元素的判断操作
in 或者 not in
集合元素的新增操作
调用add()方法,一次添加一个元素
调用update()方法至少添加一个元素
集合元素的删除操作
调用remove()方法,一次删除一个指定元素,如果指定元素不存在抛出KeyError
调用discard()方法,一次删除一个指定元素,如果指定元素不存在也不会抛出异常
调用pop()方法,无参数,一次删除一个任意元素
调用clear方法,清空集合
# 关心则乱
# 时间:2021/10/23 16:43
s = {10,20,30,40,50}
#判断
print(10 in s)# True
#新增
s.add(55)
print(s)
s.update([66,77])
print(s)
#删除
s.remove(10)
print(s)
s.discard(20)
print(s)
s.pop()
print(s)
#清空集合
s.clear()
print(s)
集合之间的关系
两个集合是否相等 == !=
一个集合是否是另一个的子集issubset
一个集合是否是另一个的超集issuperset
判断无交集 isdisjoint 无交集为True 有交集 为False
# 关心则乱
# 时间:2021/10/23 16:53
s = {10,20,30,40}
s2 = {20,10,40,30}
print(s == s2)
s3 = {10,20}
print(s.issuperset(s3))
print(s3.issubset(s))
print(s.isdisjoint(s3)) #有交集为False
集合的数据操作
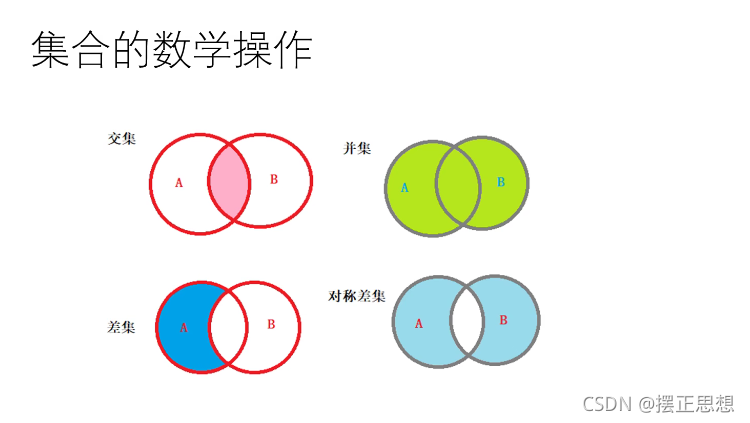
交集 s1.intersection(s2) s1 & s2
并集 s1.union(s2) s1 | s2
差集 s1.difference(s2) s1 - s2
对称差集 s1.symmetric_difference(s2) s1 ^ s2
集合生成式
{i for i in range(1,10)}
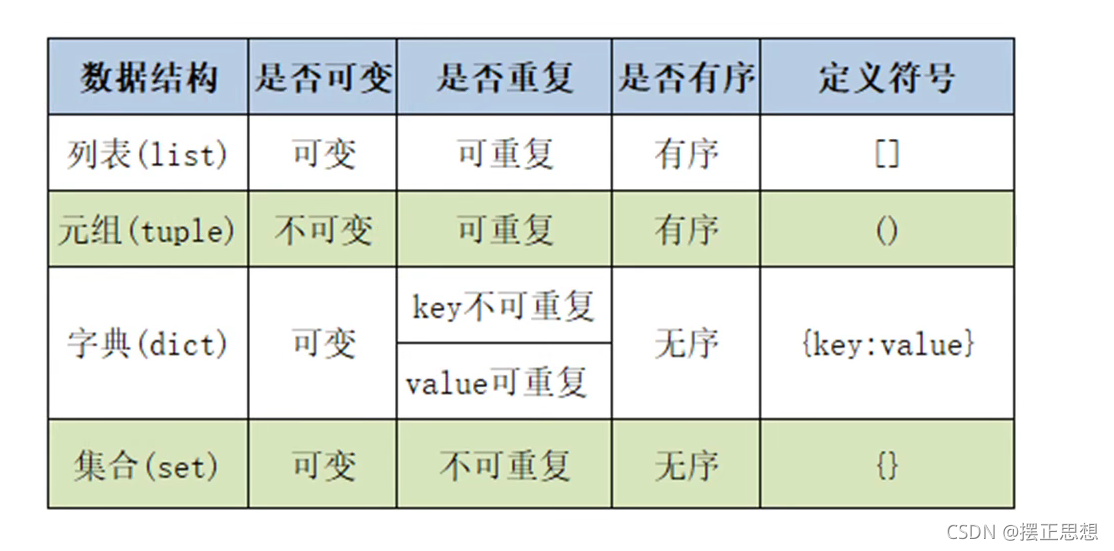
列表、字典、元组、集合总结
字符串的查找
# 关心则乱
# 时间:2021/10/23 17:29
s1 = 'hello,hello'
print(s1.find('lo'))
print(s1.rfind('lo'))
字符串的大小写转换
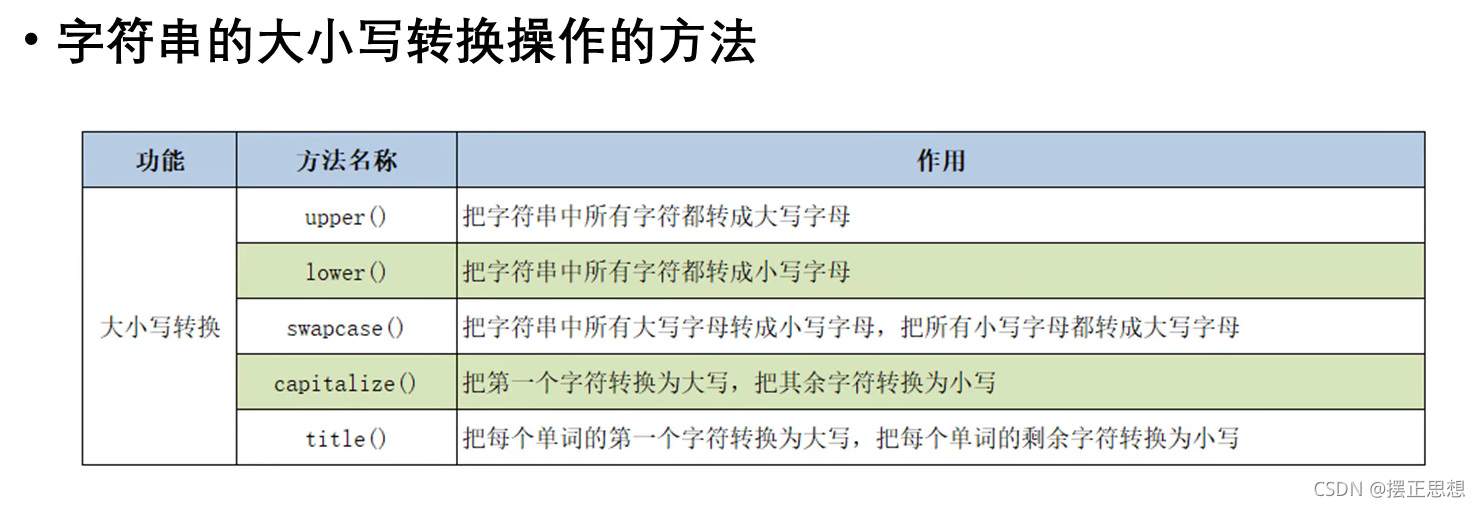
# 关心则乱
# 时间:2021/10/23 17:39
s1 = 'hello,python'
print(s1.capitalize())
print(s1.title())
字符串内容对齐操作
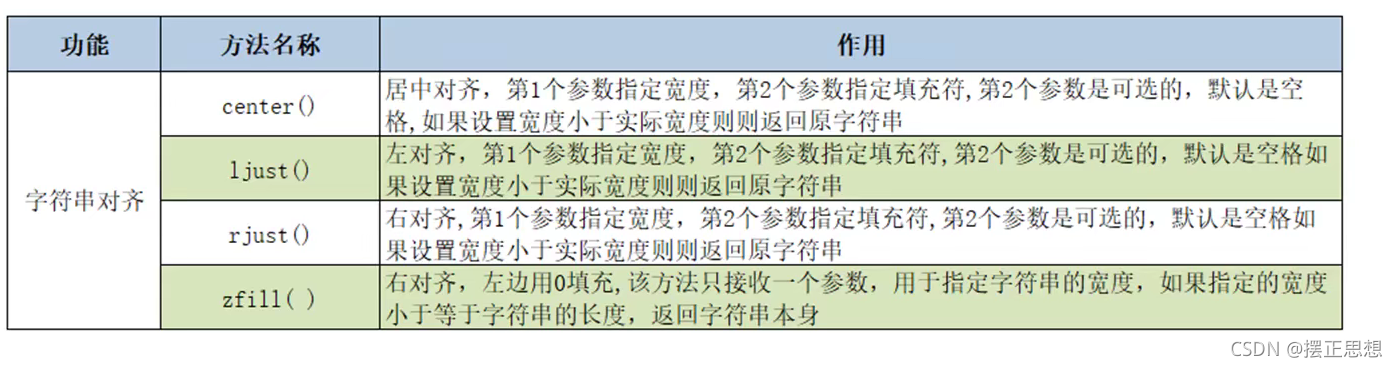
# 关心则乱
# 时间:2021/10/23 17:45
s1 = 'hello,python'
print(s1.center(20,'*'))#****hello,python****
字符串劈分操作
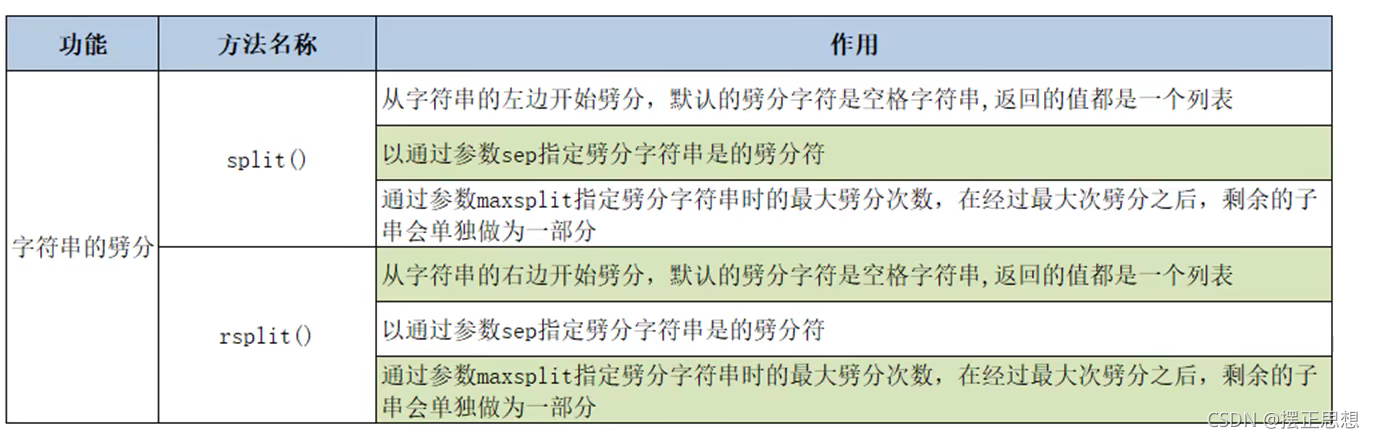
# 关心则乱
# 时间:2021/10/23 17:51
s = 'hello world python'
print(s.split(maxsplit=1))
字符串其他常用操作
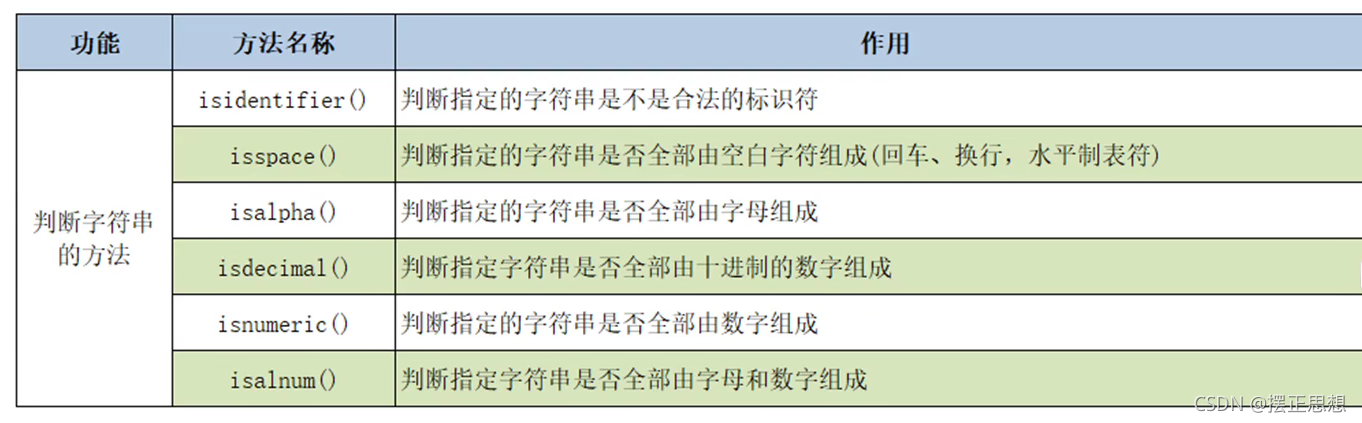

# 关心则乱
# 时间:2021/10/24 10:18
s = 'hello,python,python'
print(s.replace('python','java',1))#hello,java,python
# 关心则乱
# 时间:2021/10/24 10:20
s = ['hello','python']
print(''.join(s)) #hellopython
字符串的比较操作

# 关心则乱
# 时间:2021/10/24 10:25
print('apple'>'b')#False 依次比较ASCLL的值,比较出结果后停止后续比较
== 与 is 的区别
== 比较的是值,也就是value
is 比较的是id
格式化字符串
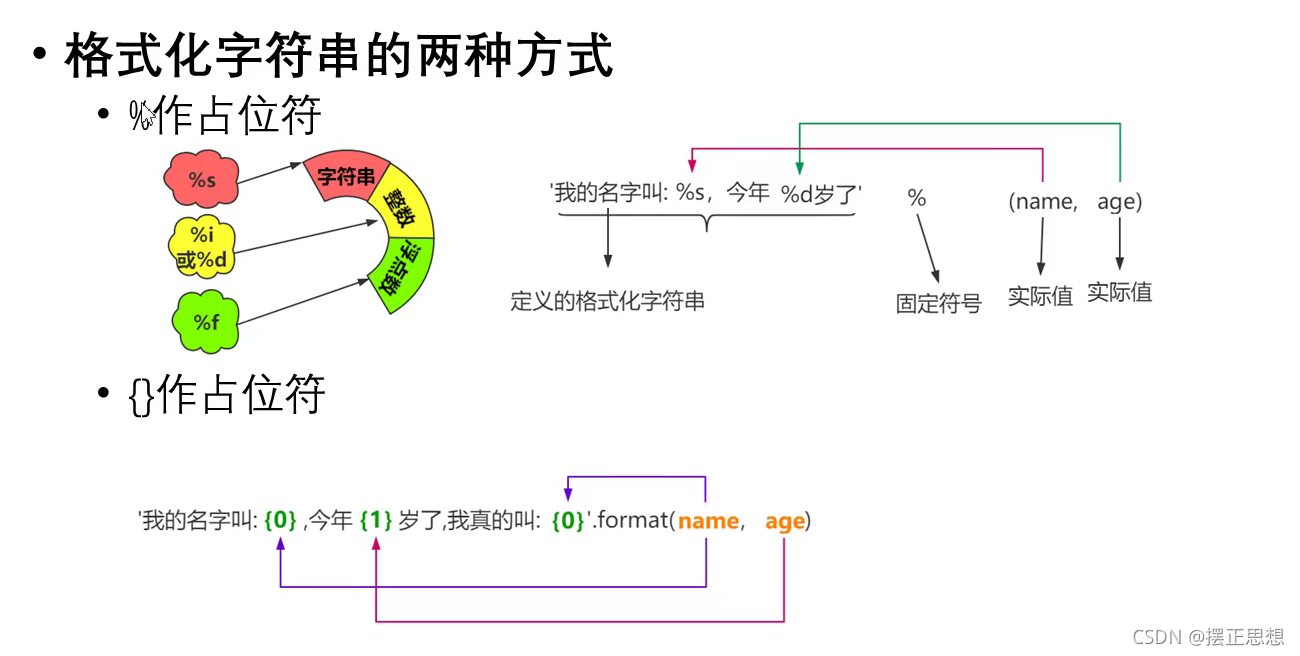
# 关心则乱
# 时间:2021/10/24 10:46
name = '张三'
age = 20
print('我叫%s,我今年%d岁了' % (name,age))
# 关心则乱
# 时间:2021/10/24 10:46
name = '张三'
age = 20
print('我叫%s,我今年%d岁了' % (name,age))
print('%10d' % 22) #10表示宽度
print('%.3f' % 3.141592)#保留三位小数
print('{0:.3}'.format(3.1415926))#一共三位数
print('{0:.3f}'.format(3.1415926))#保留三位小数
print('{0:10.3f}'.format(3.1415926))#同时设置精度和宽度
函数的创建和调用
什么是函数
函数就是完成特定功能的一段代码
为什么需要函数
复用代码
隐藏实现细节
提高可维护性
提高可读性便于调试
函数的创建 def 函数名(输入参数):
函数体
[return XX]
# 关心则乱
# 时间:2021/10/24 11:24
def add(a,b):
c = a+b
return c
result = add(1,2)
print(result)
函数的参数传递
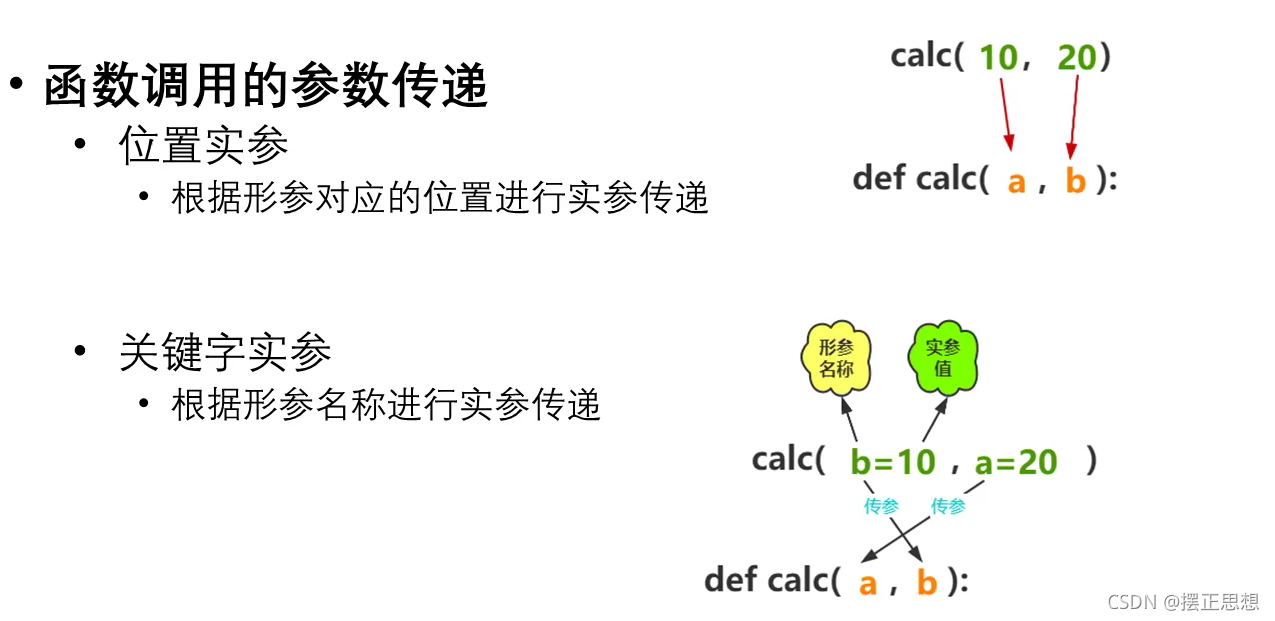
函数参数传递的内存分析
在函数调用的过程中,进行参数的传递
如果是不可变对象,在函数体的修改不会影响实参的值
如果是可变对象,在函数体的修改会影响到实参的值
# 关心则乱
# 时间:2021/10/24 16:10
def fun(a,b):
a = 100
b.append(10)
print('a',a)
print('b',b)
n1=11
n2=[22,33,44]
fun(n1,n2)
print('n1',n1) #n1 11
print('n2',n2) #n2 [22, 33, 44, 10]
函数的参数定义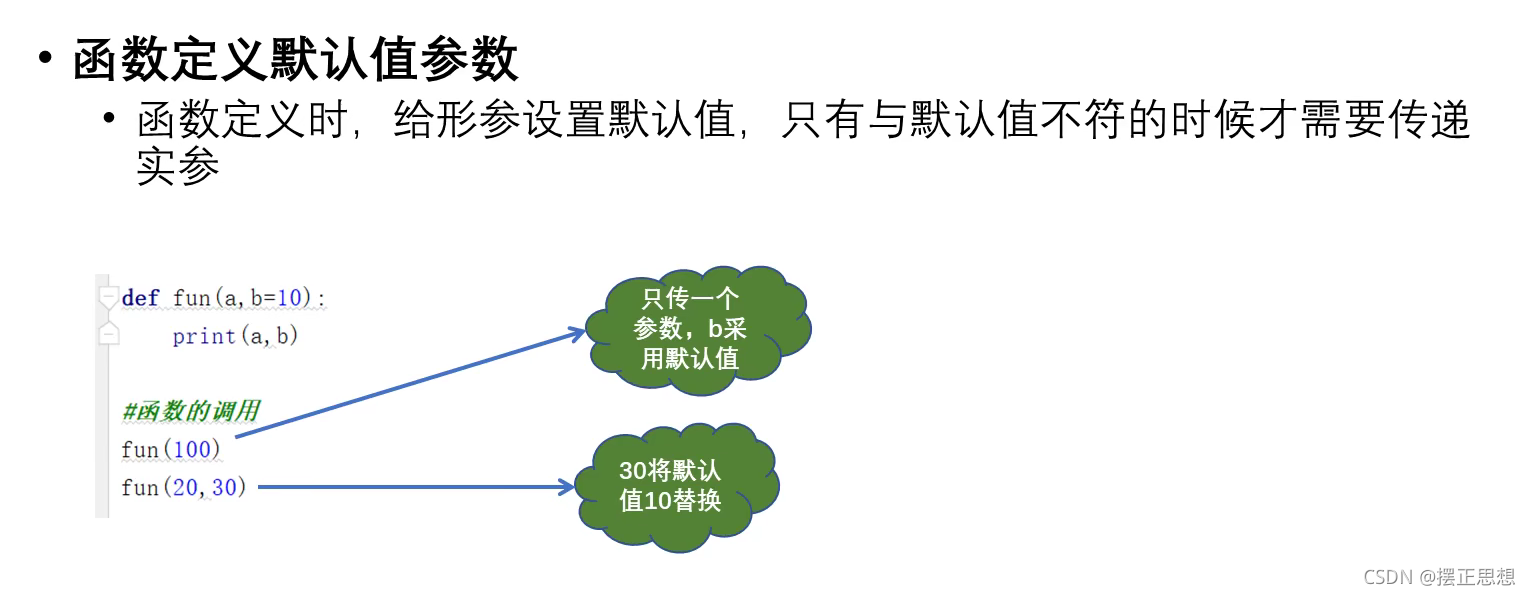
# 关心则乱
# 时间:2021/10/25 10:48
def fun(a,b=20):
print(a,b)
fun(100,10) #100 10
fun(100) #100 20

如果两种都存在,位置参数要放在 关键字形参之前
# 关心则乱
# 时间:2021/10/25 11:01
def fun(*a):
print(a)
fun(10,20,30)
def fun2(**a):
print(a)
fun2(name='张三',age=15)
变量的作用域

递归函数

# 关心则乱
# 时间:2021/10/25 11:57
def fun(n):
if n==1:
return 1
else:
return n*fun(n-1)
print(fun(6))
斐波那契数列
# 关心则乱
# 时间:2021/10/25 12:20
def fun(n):
if n==1:
return 1
elif n==2:
return 1
else:
return fun(n-1)+fun(n-2)
print(fun(6))
print('------------------')
for i in range(1,7):
print(fun(i))
BUG
粗心导致的错误

异常处理机制

# 关心则乱
# 时间:2021/10/26 14:28
try:
a= int(input('请输入第一个数'))
b= int(input('请输入第二个数'))
c = a/b
print(c)
except ZeroDivisionError:
print('除数不能为0')
except ValueError:
print('输入的字不合法')
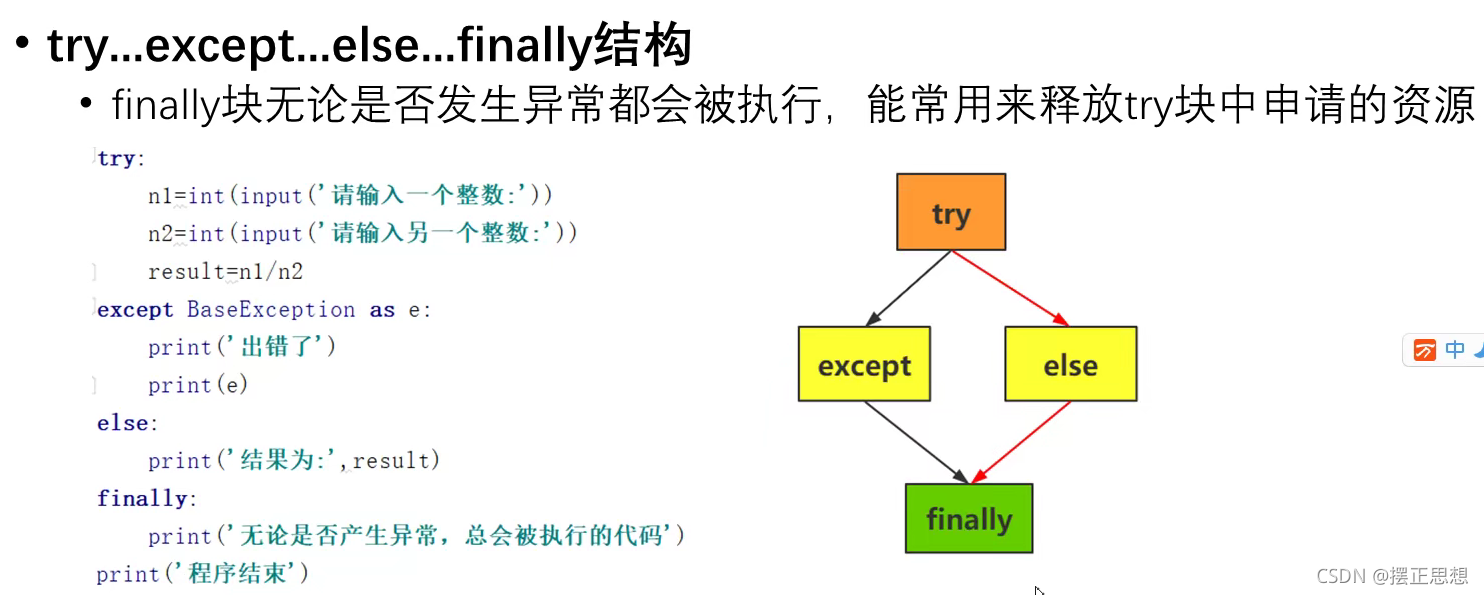
# 关心则乱
# 时间:2021/10/26 14:40
try:
a = int(input('请输入第一个数'))
b = int(input('请输入第二个数'))
c = a/b
except BaseException as e:
print('出错了,错误原因为:',end='')
print(e)
else:
print('结果为:',c)
finally:
print('感谢使用')
Python中常见的异常类型
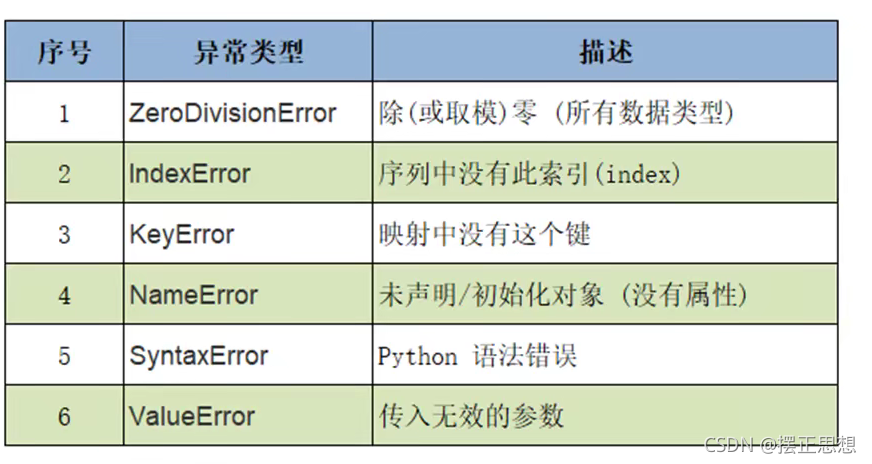 定义Python中的类
定义Python中的类

对象的创建
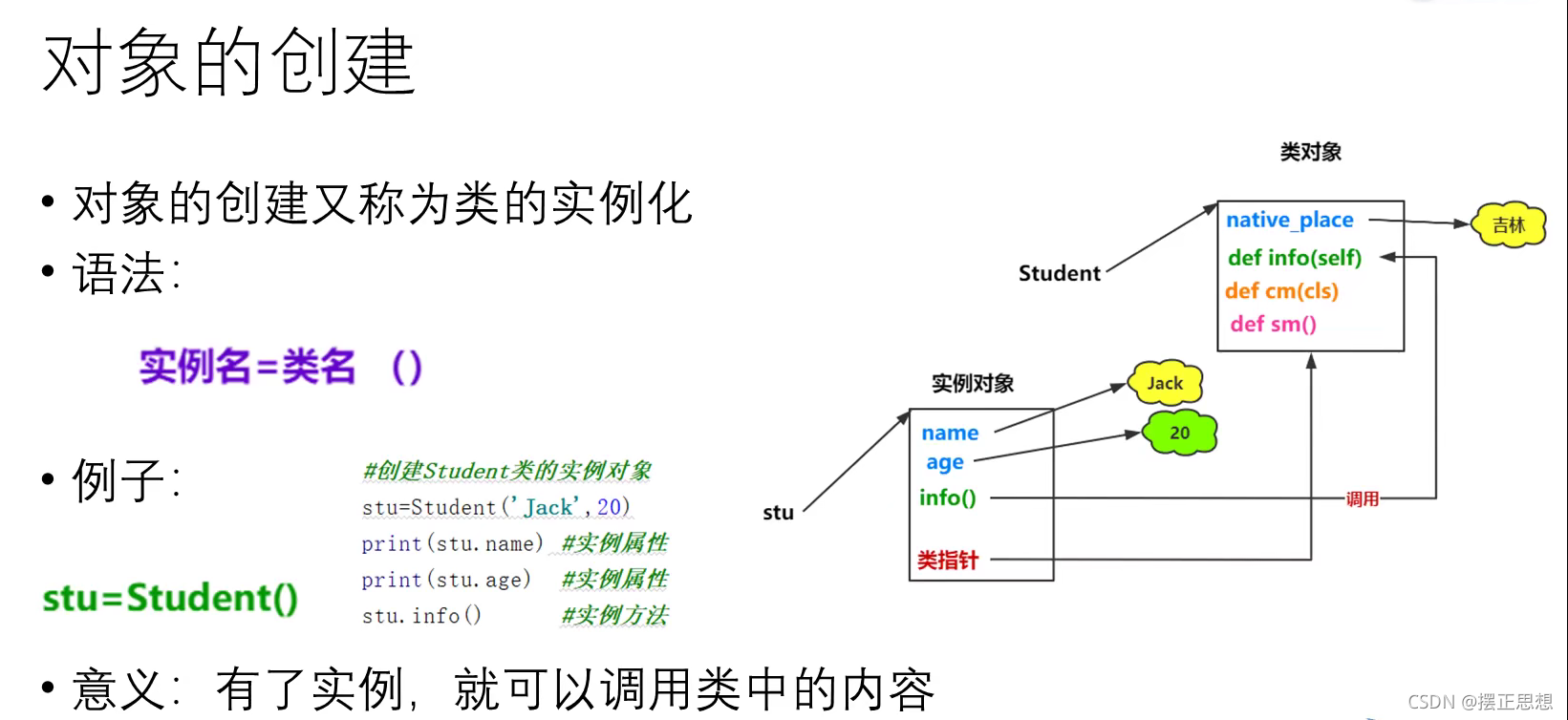
# 关心则乱
# 时间:2021/10/26 15:50
class Student:
native_place = '河南' #类属性
def __init__(self,name,age): #name,age为实例属性
self.name = name
self.age = age
#实例方法
def eat(self):
print('学生在吃饭...')
#类方法
@classmethod
def cm(cls):
print('类方法')
#静态方法
@staticmethod
def sm():
print('静态方法')
s1 = Student('kang',20)
s1.eat()
print(s1.name)
print(s1.age)
类属性、类方法、静态方法的使用方式

# 关心则乱
# 时间:2021/10/26 15:50
class Student:
native_place = '河南' #类属性
def __init__(self,name,age): #name,age为实例属性
self.name = name
self.age = age
#实例方法
def eat(self):
print('学生在吃饭...')
#类方法
@classmethod
def cm(cls):
print('类方法')
#静态方法
@staticmethod
def sm():
print('静态方法')
s1 = Student('kang',20)
s1.eat()
print(s1.name)
print(s1.age)
Student.cm()
Student.sm()
实例化对象的属性可以直接修改
比如上面的s1 = Student('kang' , 20)
直接 s1.age = 30
那么s1的属性就修改为了30
面向对象的三大特征

封装
# 关心则乱
# 时间:2021/10/27 15:41
class Car:
def __init__(self,brand):
self.brand = brand
def start(self):
print('汽车已经启动...')
c1 = Car('奔驰c')
c1.start()
print(c1.brand)
私有属性的实现
# 关心则乱
# 时间:2021/10/27 15:46
class Student:
def __init__(self,name,age):
self.name = name
self.__age = age #私有
def start(self):
print(self.name,'要去上课了')
s1 = Student("张三",'20')
s1.start()
print(s1.name)
继承

# 关心则乱
# 时间:2021/10/27 15:58
class Person:
def __init__(self,name,age):
self.name = name
self.age = age
def info(self):
print(self.name,self.age)
class Student(Person):
def __init__(self,name,age,sid):
super().__init__(name,age)
self.sid = sid
class Teacher(Person):
def __init__(self,name,age,tid):
super().__init__(name,age)
self.tid = tid
s1 = Student('张三',12,5)
t1 = Teacher('李四',22,6)
s1.info()
t1.info()
方法重写
# 关心则乱
# 时间:2021/10/27 15:58
class Person:
def __init__(self,name,age):
self.name = name
self.age = age
def info(self):
print(self.name,self.age)
class Student(Person):
def __init__(self,name,age,sid):
super().__init__(name,age)
self.sid = sid
def info(self):
super().info()
print(self.sid)
class Teacher(Person):
def __init__(self,name,age,tid):
super().__init__(name,age)
self.tid = tid
def info(self):
super().info()
print(self.tid)
s1 = Student('张三',12,5)
t1 = Teacher('李四',22,6)
s1.info()
print('-------------------')
t1.info()
object类

# 关心则乱
# 时间:2021/10/27 16:39
class Student:
def __init__(self,name,age):
self.name = name
self.age = age
def __str__(self):
return '我叫{0},今年{1}岁了'.format(self.name,self.age)
s1 = Student('张三',16)
print(dir(s1))
print(s1) #我叫张三,今年16岁了
多态

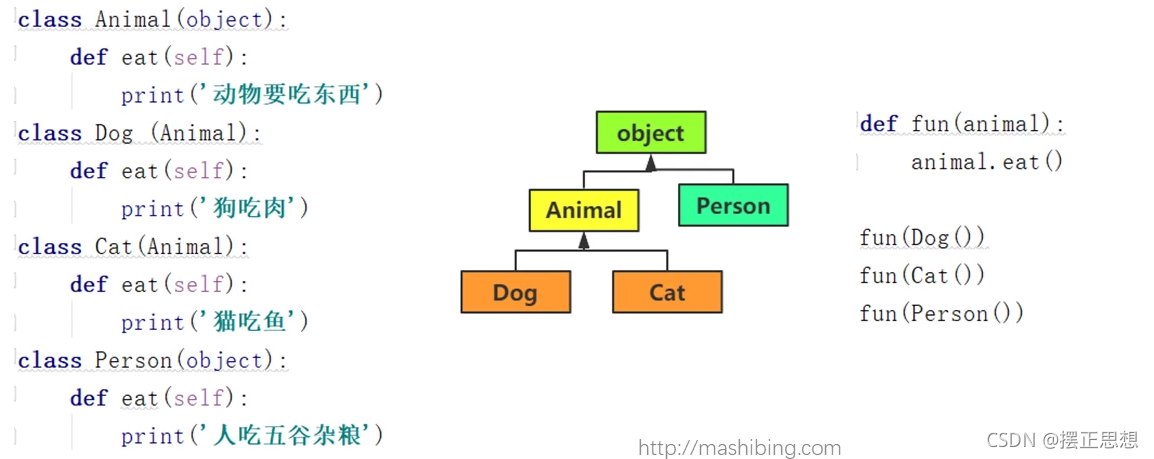
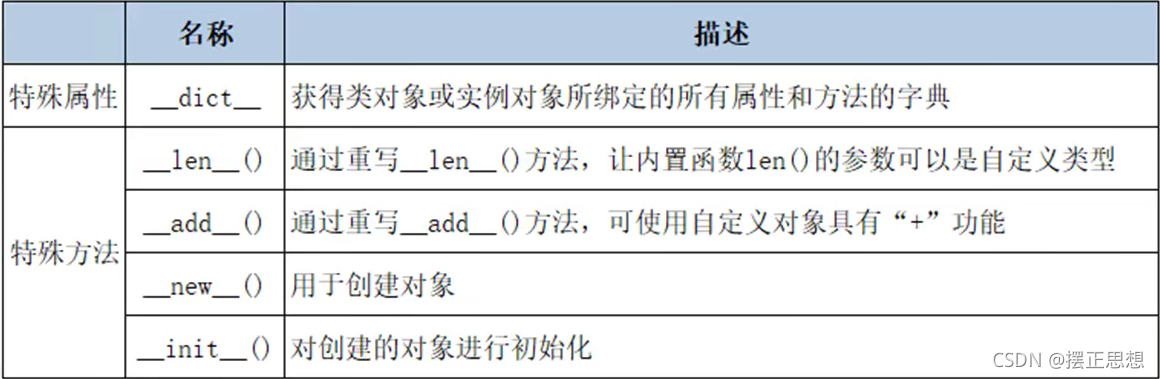
特殊方法和特殊属性
类的浅拷贝与深拷贝
·变量的赋值操作
只是形成两个变量,实际上还是指向同一个对象
浅拷贝
-Python拷贝一般都是浅拷贝,拷贝时,对象包含的子对象内容不拷贝,因此,源对象与拷贝对象会引用同一个子对象
深拷贝
使用copy模块的deepcopy函数,递归拷贝对象中包含的子对象,源对象和拷贝对象所有的子对象也不相同
正则表达式
re.match() 匹配,在w字符串中匹配开头为https://www
import re
w = input()
result = re.match('^https://www',w)
print(result.span()) # (0,11)
re.sub() 替换 \D 代表非数字
import re
s = input()
str2 = re.sub('\D','',s) #把非数字的字符串替换为空
print(str2) #假如输入的是123dad,输出的就是123

















 1723
1723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









