








wiki中文语料的word2vec模型构建
遇到的第一个问题:
按照上图操作发现
原因:可能是并没有运行opencc(不知道如何描述)
解决方法:找到解压的opencc文件夹,将要转换的文件放入。
 之后在上方输入cmd进入dos窗口
之后在上方输入cmd进入dos窗口
在输入opencc -i wiki.zh.txt -o wiki.zh.simp.txt -c t2s.json
就可得到文件
再将该文件粘贴到wiki中文语料的word2vec模型构建文件夹下
之后按博客继续,可以看到繁体字转化后简体字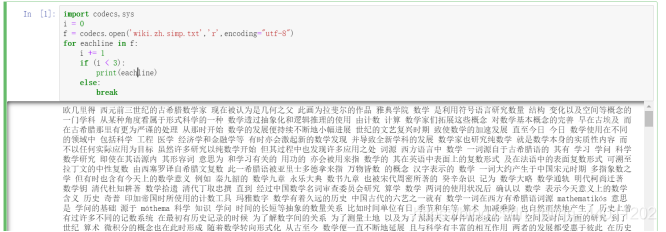
Jieba分词:
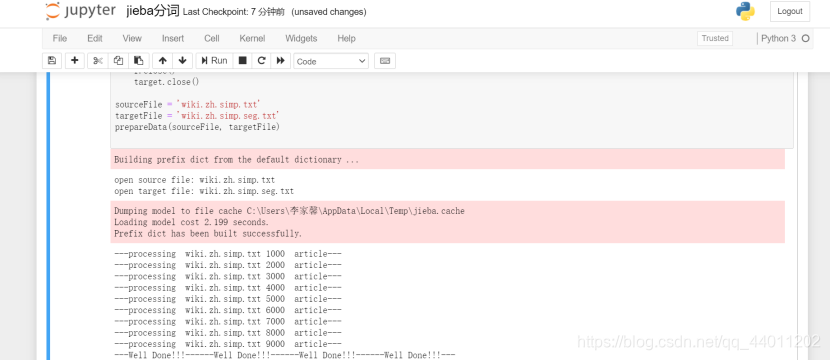
再看分完词的文档:

之后就是Word2Vec模型训练:
wiki.zh.text.model是建好的模型,wiki.zh.text.vector是词向量,如下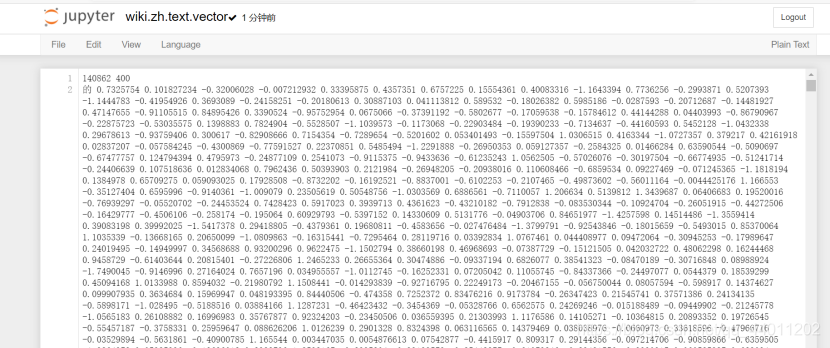 模型测试中出现的问题:
模型测试中出现的问题:
 按图修改就行了
按图修改就行了
model.wv.doesnt_match():找出不同类的词
model.wv.similarity():两个词向量的相似程度
最终运行结果: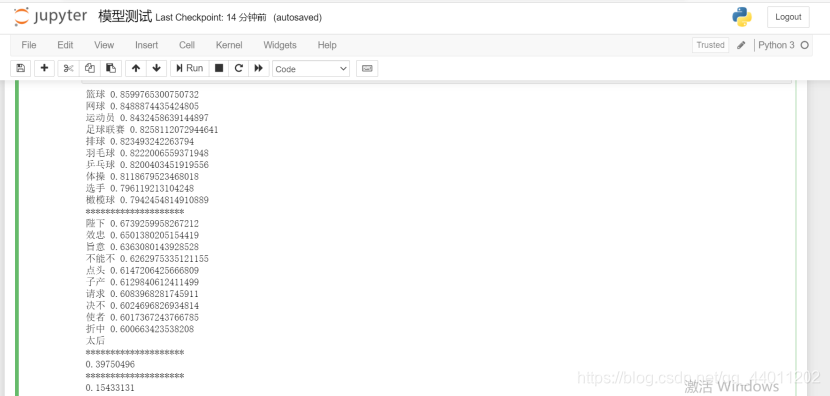
参考博客:http://www.cnblogs.com/always-fight/p/10310418.html

















 1835
1835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









