







目录
第一部分 MongoDB 安装
一 Ubuntu 上安装 MongoDB
Linux 系统上安装 MongoDB 的步骤都差不多,不过因为我自己的电脑是 Ubuntu 系统,所以这里展示的是 Ubuntu 系统上的安装步骤,下面我们一步一步地进行安装:
-
通过
head -n 1 /etc/issue命令查看自己 Linux 系统的系列类别和版本,我的是 Ubuntu 18.04.3; -
到官网下载对应的 MongoDB 安装包,这里给出官网下载地址:https://www.mongodb.com/try#community,然后点击 On-Premises 选择在自己本地安装 MongoDB:
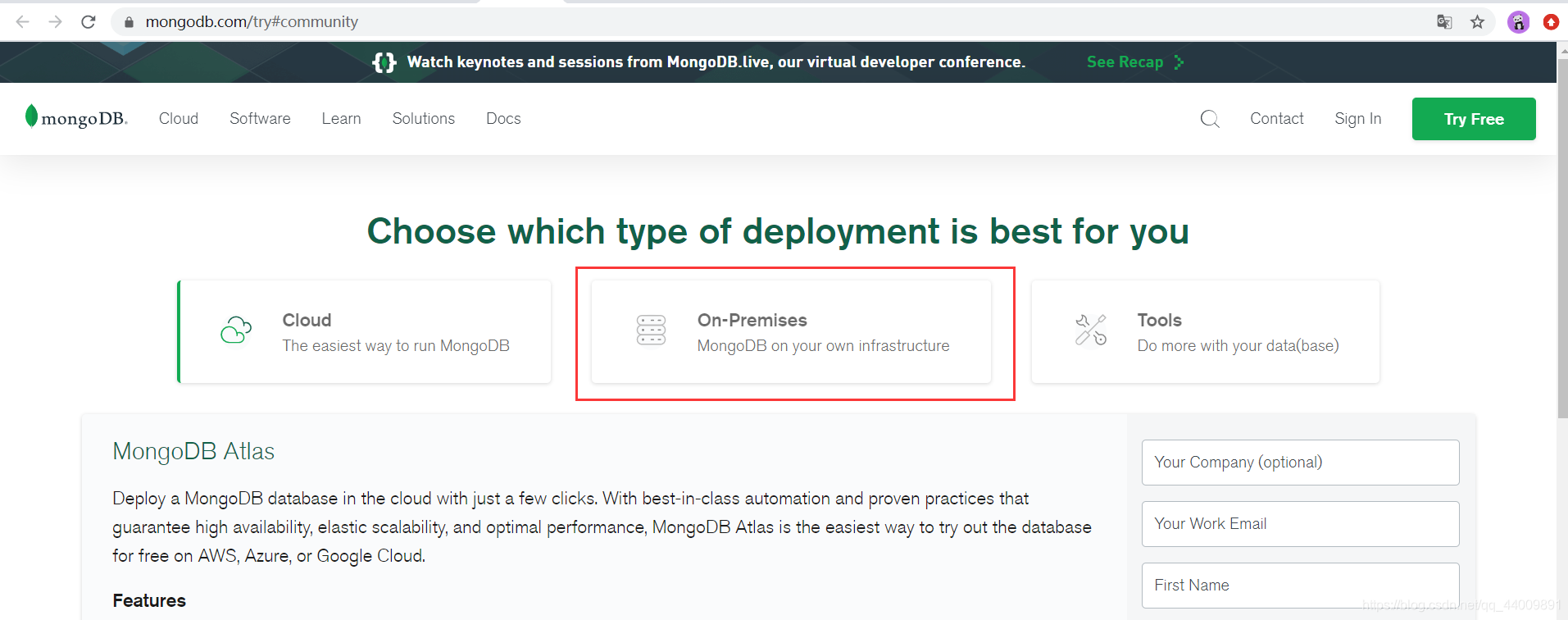
接着点击 MongoDB Community Server:
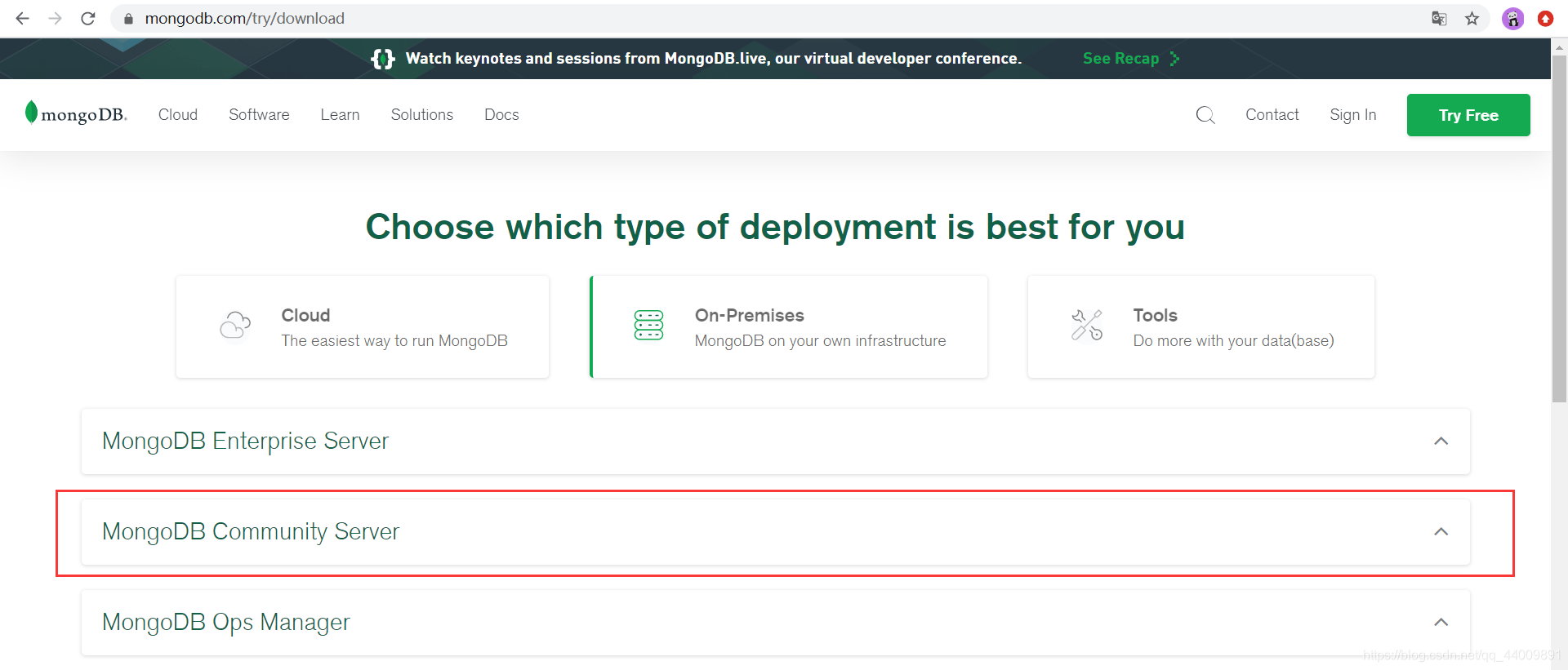
再分别选择 4.2.8 版本、Ubuntu 18.04 系统和 tgz 安装包格式:
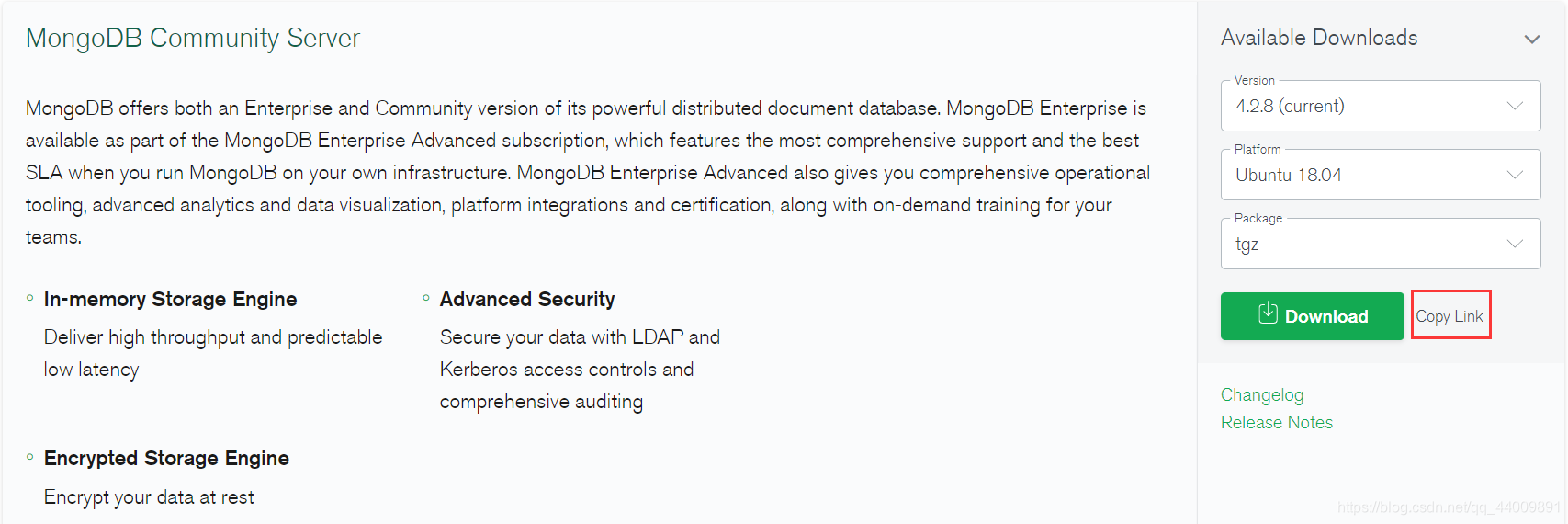
最后点击 Copy Link,通过以下命令将安装包下载下来并解压:wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-ubuntu1804-4.2.8.tgztar -zxvf mongodb-linux-x86_64-ubuntu1804-4.2.8.tgz -
配置用户环境变量,打开 ~/.bashrc 这个文件:
vim ~/.bashrc在文件的最前面位置加入如下单独一行,将 bin 目录加入环境变量:
export PATH=<自己的安装目录>/mongodb-linux-x86_64-ubuntu1804-4.2.8/bin保存并退出,执行以下命令使设置生效:
source ~/.bashrc -
创建 log 目录,在 log 目录里新建 mongodb.log,用来存放日志信息,创建 db 目录,用来存放数据库数据:
mkdir logcd logtouch mongodb.logcd ..mkdir db -
创建服务启动配置文件 mongodb.conf:
vim mongodb.conf在文件中写入下面内容:
logpath=/mnt/dxz/czy/MongoDB/log/mongodb.log logappend=true journal=true quiet=true fork=true port=27017 -
执行下面命令启动 MongoDB 服务:
mongod --config mongodb.conf再打开一个终端,输入
mongo命令进入 MongoDB 后台管理 Shell,出现以下信息说明 MongoDB 在 Ubuntu 系统上安装成功,我们就可以在>后输入我们想要执行的 MongoDB 命令了:

第二部分 初步了解 MongoDB
一 创建与删除数据库
我们可以通过 use database_name 命令创建数据库,然后可以通过 db 命令查看当前所操作的数据库:

我们也可以通过 show dbs 命令查看所有创建的数据库,但是需要注意,如果创建了一个数据库但没有插入任何文档,那么 show dbs 命令就不会显示该数据库。
我们可以通过 db.dropDatabase() 命令来删除当前数据库:

二 创建与删除集合
我们可以通过 db.createCollection('collection_name') 命令来在当前数据库中创建集合:

然后我们可以通过 show collections 或 show tables 命令来查看创建的数据库,其中 show collections 命令会更加准确点:

实际上,在 MongoDB 上还可以通过插入文档的方式自动创建集合,当我们插入一些文档时,MongoDB 会自动创建集合。
我们可以通过 db.collection_name.drop() 或 db.getCollection('collection_name').drop() 命令来删除当前数据库中的名为 collection_name 的集合,如果删除成功就会返回 true:

根据上图可以看到 db.collection_name.drop() 和 db.getCollection('collection_name').drop() 命令的效果一样,其实,只要是涉及到集合的操作, db.collection_name.操作名() 和 db.getCollection('collection_name').操作名() 都能达到同样的效果。
三 插入文档
我们可以通过 db.collection_name.insert(document) 或 db.collection_name.insertOne(document) 命令来向集合 collection_name 中插入文档 document,在插入后我们还可以通过 db.collection_name.find() 命令查看该集合中的所有文档来观察插入是否有问题:

如果我们想向集合中插入多条文档,就可以使用 db.collection_name.insertMany([document1, document2, document3, ...]) 命令:

如果我们碰到要插入大量文档的情况,这个时候通过上述方法来操作的效率就不是很高,因此我们通常会将要插入的大量数据存到 json 文件中,然后在终端的命令行上(不是 MongoDB 的 Shell 命令行)使用 mongoimport -d 数据库名 -c 集合名 --type 文件类型 --file 文件路径 --upsert 命令将 json 文件中的诸多文档批量插入到集合当中,比如我这里就是向数据库 DBLP 的集合 ICML 中批量插入 ICML.json 文件中的所有文档:

四 查询文档
我们可以通过 db.collection_name.find(query) 命令使用查询条件 query 来找出集合当中所有符合条件的文档,如果 query 缺省的话就是刚才所说的查询集合中的所有文档。
1 查询条件
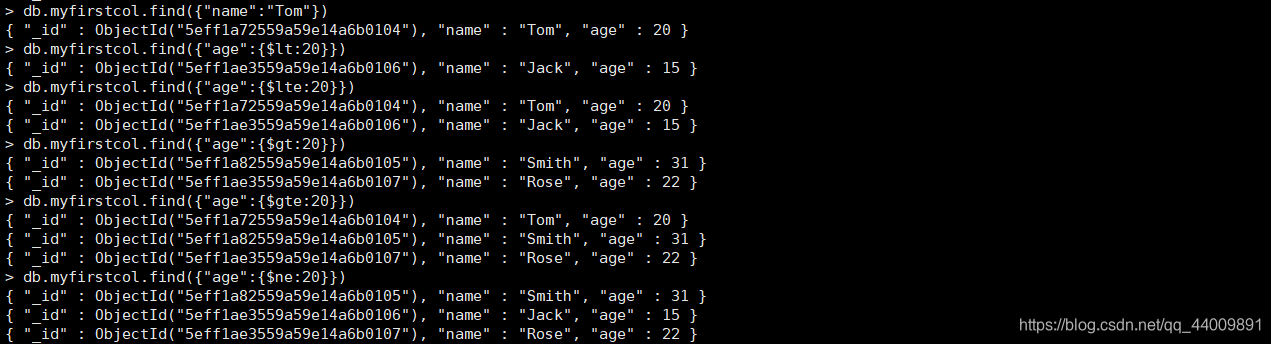
我们一般使用如下一些查询条件来帮助我们进行查询:
| 操作 | 格式 | 示例 | 示例说明 |
|---|---|---|---|
| 等于 | db.collection_name.find({key:value}) | db.myfirstcol.find({"name":"Tom"}) | 查询所有 name 字段为 Tom 的文档 |
| 小于 | db.collection_name.find({key:{$lt:value}}) | db.myfirstcol.find({"age":{$lt:20}}) | 查询所有 age 字段小于 20 的文档 |
| 小于等于 | db.collection_name.find({key:{$lte:value}}) | db.myfirstcol.find({"age":{$lte:20}}) | 查询所有 age 字段小于等于 20 的文档 |
| 大于 | db.collection_name.find({key:{$gt:value}}) | db.myfirstcol.find({"age":{$gt:20}}) | 查询所有 age 字段大于 20 的文档 |
| 大于等于 | db.collection_name.find({key:{$gte:value}}) | db.myfirstcol.find({"age":{$gte:20}}) | 查询所有 age 字段大于等于 20 的文档 |
| 不等于 | db.collection_name.find({key:{$ne:value}}) | db.myfirstcol.find({"age":{$ne:20}}) | 查询所有 age 字段不等于 20 的文档 |
对示例语句进行运行,结果如下:
2 与或操作
我们还可以对多个查询条件进行与或操作:
| 操作 | 格式 | 示例 | 示例说明 |
|---|---|---|---|
| 与操作 AND | db.collection_name.find({key1:value1, key2:value2, ...}) | db.myfirstcol.find({"name":"Tom", "age":{$lt:20}}) | 查询所有 name 字段为 Tom 且 age 字段小于 20 的文档 |
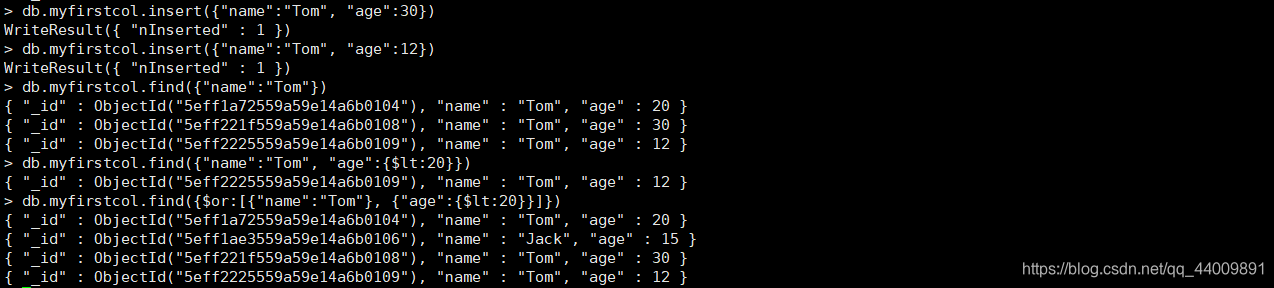
| 或操作 OR | db.collection_name.find({$or:[{key1:value1}, {key2:value2}, ...]}) | db.myfirstcol.find({$or:[{"name":"Tom"}, {"age":{$lt:20}}]}) | 查询所有 name 字段为 Tom 或 age 字段小于 20 的文档 |
对示例语句进行运行,结果如下:
五 更新文档
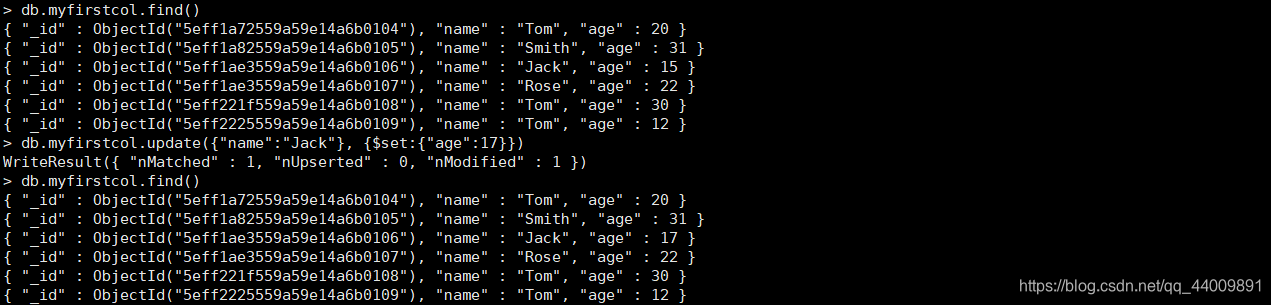
我们可以通过 db.collection_name.update(query,{$set:{key:new_value}}) 命令来更新所有符合查询条件的文档:
六 删除文档
我们可以通过 db.collection.remove(query) 命令来删除所有符合 query 条件的文档:
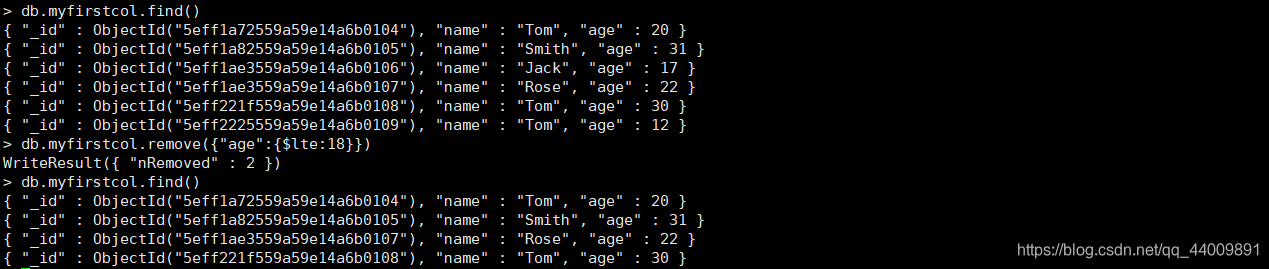
当然,如果 query 缺省的话,就是删除集合当中所有的文档了。
七 切片
我们可以通过 db.collection.find(query).limit(number) 命令从查询结果中提取前 number 个文档,通过 db.collection.find(query).skip(number) 命令跳过查询结果的前 number 个文档,我们也可以同时使用 limit 和 skip 操作来先跳过跳过查询结果的前几个文档,然后从剩下的查询结果中提取前几个文档,这样就可以达到切片的效果:

八 排序
我们可以使用 db.collection.find(query).sort({key:value}) 命令对查询结果进行排序,通过参数 key 来指定要排序的字段,并通过参数 value 来指定排序的方式,value 为 1 表示升序排列,而 value 为 -1 表示降序排列:

参考资料:菜鸟教程

















 1003
1003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









