







TensorFlow游乐场是一个通过网页浏览器就可以训练的简单神经网络并实现了可视化训练过程的工具,网址:http://playground.tensorflow.org,网页截图如下:
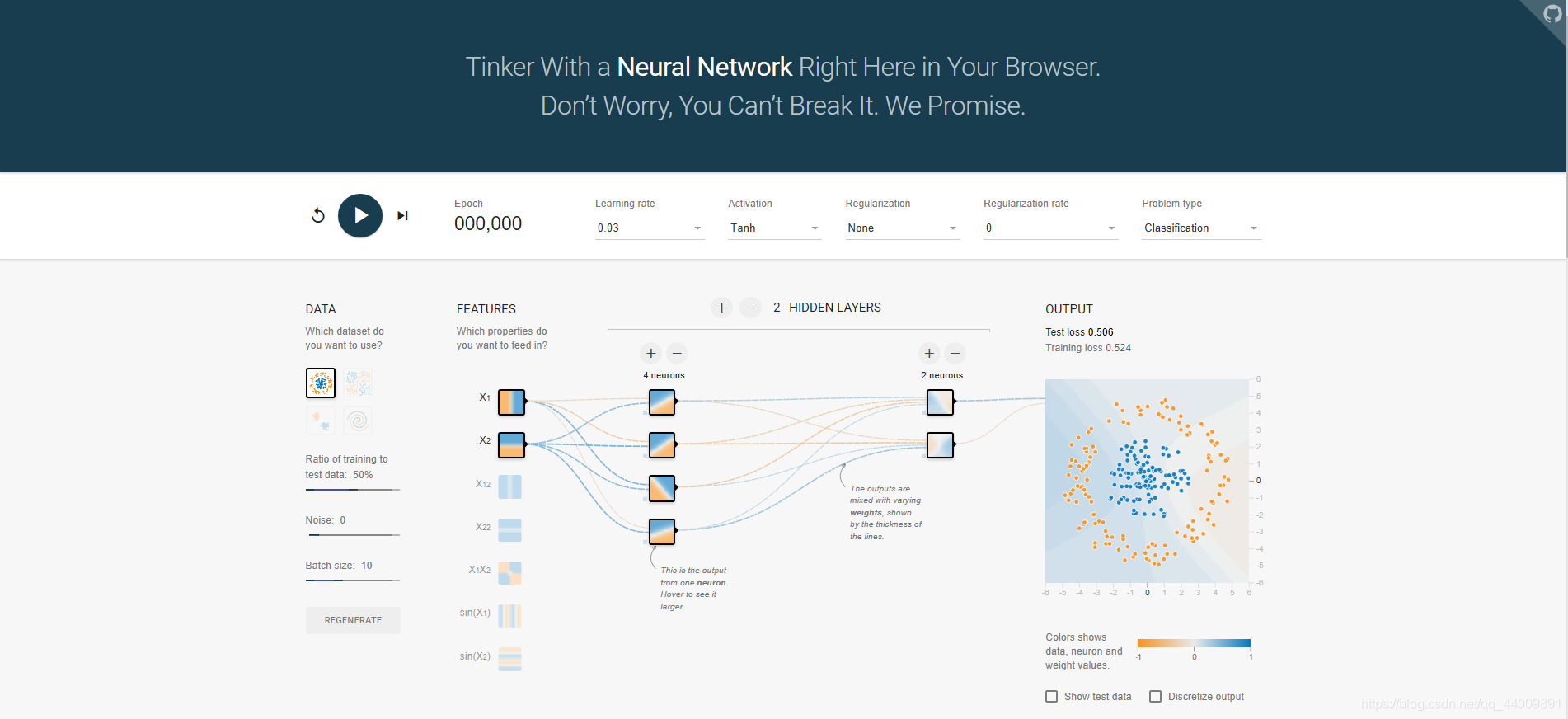
可以看到,TensorFlow游乐场的页面非常简洁清晰,接下来我们来解读一下这个页面:
-
DATA对应的是数据集,在DATA下面是4个不同的数据集的可视化,这些数据集都可以用来训练和测试神经网络;
-
FEATURES对应的是实体的特征向量,特征向量是神经网络的输入,一般神经网络的第一层是输入层,代表特征向量中每一个特征的取值;
-
HIDDEN LAYERS对应的是输入层和输出层之间的隐藏层,我们可以通过页面上的“+”或“-”来设置隐藏层的层数,以及每个隐藏层的节点个数;
-
OUTPUT对应的是输出层,在OUTPUT下面的平面是输出的可视化,平面上或深或浅的颜色表示了神经网络模型做出的判断,颜色越深表示神经网络模型对它的判断越有信心。
我们可以看到,TensorFlow游乐场所展示的是一个全连接神经网络,同一层的节点不会相互连接,而且每一层只和下一层连接,直到最后一层输出层得到输出结果。
在TensorFlow游乐场中,每一个小格子代表神经网络中的一个节点,每一个节点上的颜色代表了这个节点的区分平面,区分平面上的一个点的坐标代表了一种取值,而点的颜色就对应其输出值,输出值的绝对值越大,颜色越深,黄色越深表示负得越大,蓝色越深表示正得越大。
类似地,TensorFlow游乐场中的每一条边代表了神经网络中的一个参数,它可以是任意实数,颜色越深,表示参数值的绝对值越大,黄色越深表示负得越大,蓝色越深表示正得越大,当边的颜色接近白色时,参数取值接近于0。
TensorFlow游乐场简洁明了地展示了使用神经网络解决分类问题的四个步骤:
-
提取问题中实体的特征向量;
-
定义神经网络的结构,定义如何从神经网络的输入到输出,设置隐藏层数和节点个数(前向传播);
-
通过训练数据来调整神经网络中参数的取值,也就是训练神经网络的过程(反向传播);
-
使用训练好的神经网络来预测未知的数据。

















 1200
1200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









