







 该博客讲述了如何利用Selenium和自定义的JavaScript代码来应对网页的反爬机制,主要步骤包括设置Chrome浏览器选项、注入JavaScript以加载动态内容以及手动滚动页面。作者在尝试抓取特定网站的5G相关数据时遇到页面滚动未实现的问题,期望能与有经验的大佬交流解决方案。
该博客讲述了如何利用Selenium和自定义的JavaScript代码来应对网页的反爬机制,主要步骤包括设置Chrome浏览器选项、注入JavaScript以加载动态内容以及手动滚动页面。作者在尝试抓取特定网站的5G相关数据时遇到页面滚动未实现的问题,期望能与有经验的大佬交流解决方案。
话不多说开始
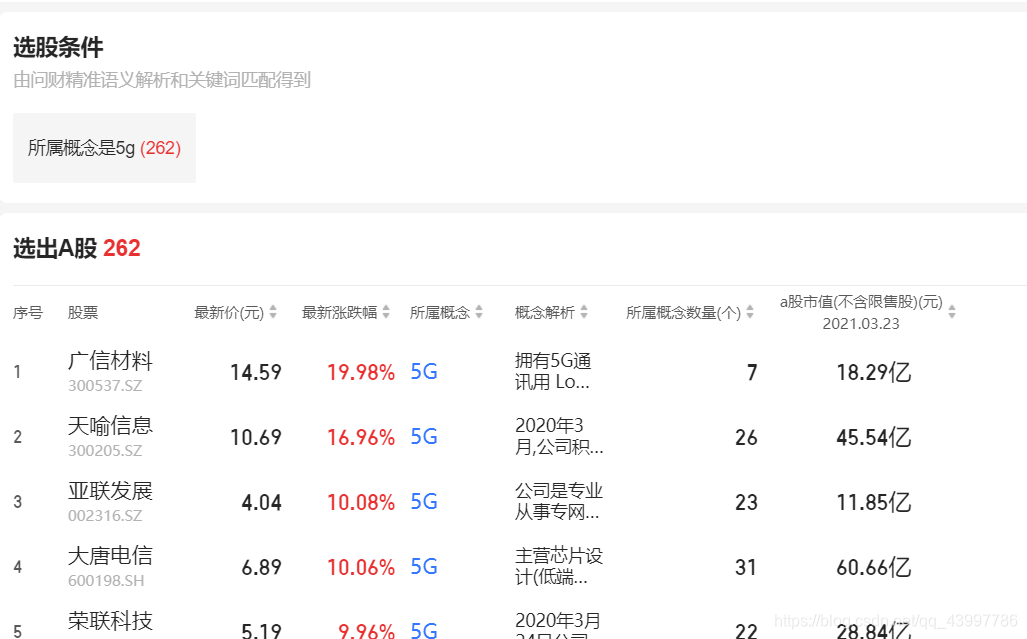
如今用的是js绕行反爬机制,打开页面是这样的
真实页面:
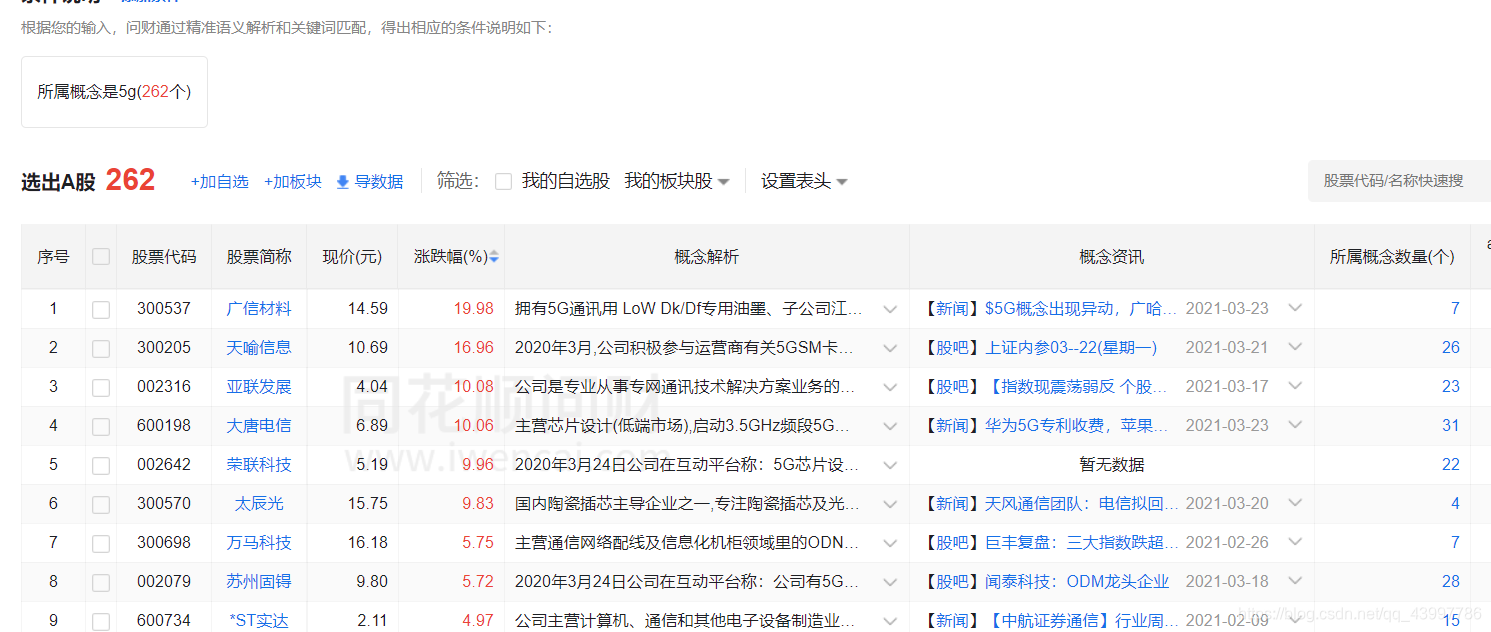
缺点
页面滚动一直没有实现,然后就是需要手动滚动到页面底部
唉
有大佬看到后希望你和我交流一下哟
联系:1440414483@qq.com
代码:
import time
import os
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
import json
import requests
from requests.exceptions import RequestException
import re
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
import pandas as pd
import os
os.getcwd() #获取当前工作路径
chrome_options = webdriver.ChromeOptions()
with open('xxxxx.js') as f:
js = f.read()
time.sleep(2)
chrome_options.add_argument('user-agent="Mozilla/5.0 (iPod; U; CPU iPhone OS 2_1 like Mac OS X; ja-jp) AppleWebKit/525.18.1 (KHTML, like Gecko) Version/3.1.1 Mobile/5F137 Safari/525.20"')
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
browser = webdriver.Chrome(options = chrome_options)
browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
browser.get('http://www.iwencai.com/unifiedwap/result?w=5g&querytype=&issugs')
WebDriverWait(browser,30,0.2).until(lambda x:x.find_element_by_css_selector("#app > div.wrapper > div > div.content.result_content > div.content_container > div > div.xuangu_container > div.xuangu_wrapper > div > div > div > div > div:nth-child(2) > div.jgy_tb_wrap > div > div.xuangu_showMore"))
browser.find_element_by_xpath('/html/body/div[1]/div[1]/div/div[1]/div[1]/div/div[1]/div[2]/div/div/div/div/div[2]/div[2]/div/div[3]').click()
n=input('随便输入一个信号:')#这里是手动滚动页面到底后的操作哭了


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









