




 本文详细介绍了如何使用MNIST数据集训练二元分类器,包括交叉验证、混淆矩阵、精度、召回率和F1分数的计算,以及如何通过精度/召回率权衡和ROC曲线进行模型优化。后续内容涉及多类分类、误差分析、多标签分类和多输出分类的实战应用。
本文详细介绍了如何使用MNIST数据集训练二元分类器,包括交叉验证、混淆矩阵、精度、召回率和F1分数的计算,以及如何通过精度/召回率权衡和ROC曲线进行模型优化。后续内容涉及多类分类、误差分析、多标签分类和多输出分类的实战应用。
文章目录
写在前面
参考书籍:Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow
❤ 本文为机器学习实战学习笔记,主要内容为第三章分类,文中除了书中主要内容,还包含部分博主少量自己修改的部分,如果有什么需要改进的地方,可以在 评论区留言 ❤。
❤更多内容❤
1. 获取数据
本文使用的是 MNIST 数据集,这是一组由美国高中生和人口调查局员工手写的 70000 个数字的图片。每张图片都用其代表的数字标记。它被誉为机器学习领域的 “Hello World” 。我们可以直接通过 Scikit-Learn 来获取 MINST 数据集。
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1, as_frame=False)
# 获取mnist的键值
mnist.keys()
| dict_keys([‘data’, ‘target’, ‘frame’, ‘categories’, ‘feature_names’, ‘target_names’, ‘DESCR’, ‘details’, ‘url’]) |
|---|
Scikit-Learn 加载的数据集通常具有类似的字典结构,包括
DESCR:描述数据集。data:包含一个数组,每个实例为一行,每个特征为一列。target:包含一个带有标记的数组。
# 获取特征与标签
X, y = mnist["data"], mnist["target"]
print(X.shape, y.shape)
| (70000, 784) (70000,) |
|---|
数据集共有 7 万张图片,每张图片有 784 个特征。图片为 28×28 像素,每个特征代表一个像素点的强度,从 0 (白色)—— 255 (黑色)。我们可以先用 Matplotlib 来显示一张图片看一下。
import matplotlib as mpl
import matplotlib.pyplot as plt
from pathlib import Path
current_path = Path.cwd()
some_digit = X[0]
some_digit_image = some_digit.reshape(28, 28)
# 显示灰色图
plt.imshow(some_digit_image, cmap=mpl.cm.binary)
# 显示彩色图
# plt.imshow(some_digit_image)
plt.axis("off")
# 保存灰色图
plt.savefig(Path(current_path, "./images/some_digit_plot.png"), dpi=600)
# 保存彩色图
# plt.savefig(Path(current_path, "./images/some_digit_plot_colour.png"), dpi=600)
plt.show()
 灰色图 灰色图 |
 彩色图 彩色图 |
我们看一下它对应的标签。
y[0]
| ‘5’ |
|---|
标签的结果与图片相符。
此时的标签是字符,需要转为整数。
import numpy as np
y = y.astype(np.uint8)
| 5 |
|---|
在进行之后的步骤之前,需先创建一个测试集,将它与训练集分开。
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
2. 训练二元分类器
我们先尝试训练一个区分两个类别:5 和非 5 的二元分类器,首先创建目标向量。
y_train_5 = (y_train == 5) # [ True False False ... True False False]
y_test_5 = (y_test == 5)
接着挑选一个分类器进行训练。一个好的选择随机梯度下降( SGD )分类器,它的优势在于:能够有效处理非常大型的数据集,这是由于 SGD 独立处理训练实例,一次一个实例(这也使得 SGD 非常适合在线学习)。先创建一个 SGDClassifier 并在整个训练集上进行训练。
from sklearn.linear_model import SGDClassifier
# 构建分类器
sgd_clf = SGDClassifier(max_iter=1000, tol=1e-3, random_state=42)
# 训练分类器
sgd_clf.fit(X_train, y_train_5)
# 预测
sgd_clf.predict([some_digit])
| array([ True]) |
|---|
SGDClassifier 预测整个图像属于 5 ,结果正确,下面评估一下整个模型的性能。
3. 性能测量
3.1 交叉验证测量准确率
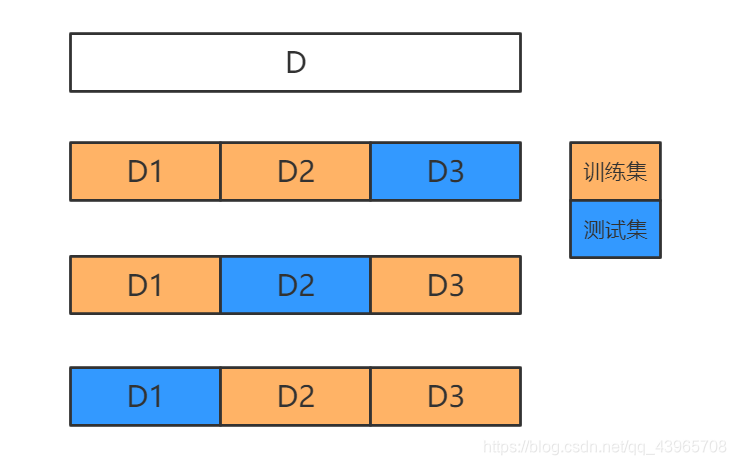
使用 Scikit-Learn 中的 cross_val_score() 函数来评估 SGDClassifier 模型,采用 K 折交叉验证法。这里使用 K=3 ,三个折叠,即将训练集分成 3 个折叠,每次留其中的 1 个折叠进行预测,剩余 2 个折叠用来训练,共重复 3 次。
from sklearn.model_selection import cross_val_score
# 交叉验证获取每次的模型准确率
cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring="accuracy")
| array([0.95035, 0.96035, 0.9604 ]) |
|---|
3 次交叉验证的结果看上去都不错,超过 95%,但事实真的如此?下面构建一个只预测非 5的分类器,我们看一下它交叉验证的评估结果。
from sklearn.base import BaseEstimator
# 构建分类器
class Never5Classifier(BaseEstimator):
def fit(self, X, y=None):
pass
def predict(self, X):
# 返回全1的数组
return np.zeros((len(X), 1), dtype=bool)
never_5_clf = Never5Classifier()
cross_val_score(never_5_clf, X_train, y_train_5, cv=3, scoring="accuracy")
| array([0.91125, 0.90855, 0.90915]) |
|---|
对于只预测非 5 的分类器,交叉验证的结果依旧很好,这说明训练集中大约只有 10% 的图片是数字 5。
我们看一下 y_train_5 中 非5 的比例是否在 90% 左右。
len(y_train_5[y_train_5==False]) / len(y_train_5)
| 0.90965 |
|---|
通过上面的结果,可以说明准确率往往无法成为分类器的首要性能指标,特别是在你处理不平衡的数据集时。
3.2 混淆矩阵
评估分类器性能的更好的方法是混淆矩阵。
混淆矩阵:统计A类别实例被分成B类别的次数
要计算混淆矩阵,需要先有一组预测才能将其与实际目标进行比较。当然可以通过测试集进行预测,但在目前阶段最好不要使用(测试集最好留到最后,在准备启动分类器时再使用)。我们可以使用 cross_val_predict() 函数来替代。
from sklearn.model_selection import cross_val_predict
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3)
print(y_train_pred)
y_train_pred.shape
| 输出 |
|---|
| [ True False False … True False False] |
| (60000,) |
与 cross_val_score() 函数一样, cross_val_predict() 函数同样执行K折交叉验证,但返回的不是评估分数,而是每个折叠的预测。
现在可以使用 confusion_matrix() 函数来获取混淆矩阵,只需要给出 y_train_5 (目标类别)和 y_train_pred(预测类别)即可。
from sklearn.metrics import confusion_matrix
confusion_matrix(y_train_5, y_train_pred)
| 输出 |
|---|
 |
在进行下面内容之前要确保你已经了解以下含义:
TP(True Positive):真 正类,模型预测样本为正类,实际也是正类。FP(False Positive):假 正类, 模型预测样本为正类,实际上是负类。TN(True Negative):真 负类,模型预测样本为负类,实际上也是负类。FN(True Negative):假 负类,模型预测样本为负类,实际上是正类。
我们将上面结果以图的形式展示出来。

混淆矩阵中的行表示实际类别,列表示预测类别。图中我们可以得到以下信息:
- 在第一行表示所有实际类别是
非5的图片中:53892张被正确的分为非5类别(真负类TN)687张被错误的分为5类别(假正类FP)
- 在第一行表示所有实际类别是
5的图片中:1891张被错误的分为非5类别(假负类FN)3530张被正确的分为5类别(真正类TP)
一个完美的分类器只有真正类和真负类,所以它的混淆矩阵只会在其对角线(左上——右下)上有非零值。如下所示:
# 直接以实际标签作为预测结果,来塑造一个完美的分类结果
y_train_perfect_predictions = y_train_5
confusion_matrix(y_train_5, y_train_perfect_predictions)
| 输出 |
|---|
 |
3.3 精度和召回率
混淆矩阵确实能够提供大量的信息,但如果希望指标更简洁一些,分类器的精度可能更加适合。
精度:正类预测的准确率
精 度 = T P T P + F P 精度=\cfrac{TP}{TP + FP} 精度=TP+
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 770
770










 到【灌水乐园】发言
到【灌水乐园】发言









