






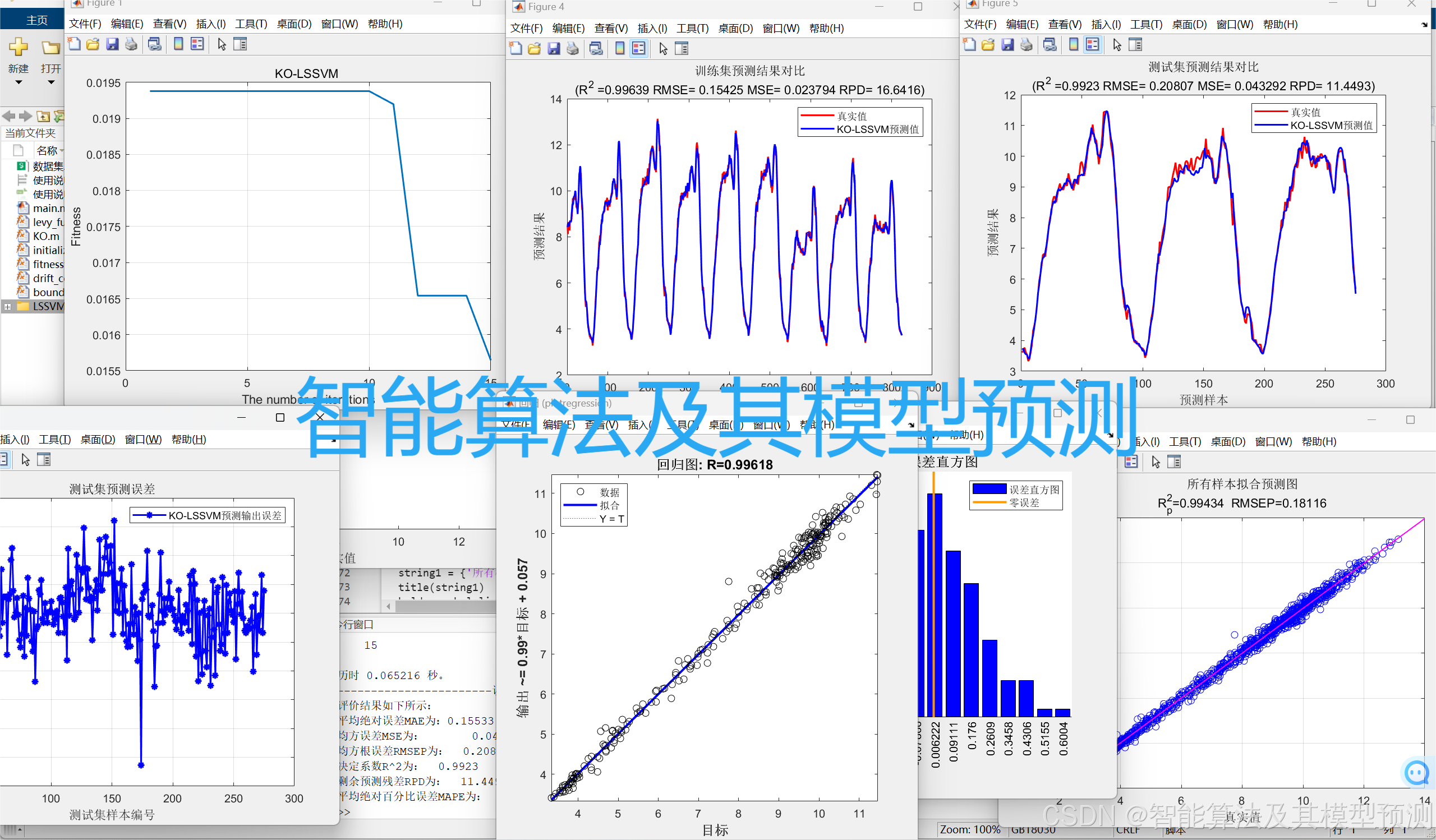
 【24年新算法】KO-LSSVM,K-means优化算法优化最小二乘支持向量机回归预测,KO-LSSVM回归预测,多变量输入模型。
【24年新算法】KO-LSSVM,K-means优化算法优化最小二乘支持向量机回归预测,KO-LSSVM回归预测,多变量输入模型。
K-means优化算法(K-means Optimizer, KO)是一种新型的元启发式算法(智能优化算法),灵感来源于使用K-means算法建立聚类区域的质心向量。不同于以往的动物园算法,该算法原理新颖,在优化算法中巧妙引入聚类算法,该成果由Hoang-Le Minh于2022年9月发表在SCI一区顶刊《Knowledge-Baesd Systems》上!
评价指标包括:R2、MAE、MSE、RMSE和MAPE等,代码质量极高,方便学习和替换数据。
优化EMD/VMD/ICCEMD/SVM/LSSVM/ELM/BP/KELM/RF/DELM/LSTM/BILSTM/GRU/HKELM/XGboost/PNN/CNN/VMD/ICEEMDAN/组合模型CNN-SVM/CNN-LSTM/CNN-GRU/CNN-BiLSTM/LSTM-Attention/GRU-Attention/CNN-LSTM-Attention/TCN/TCN-LSTM/TCN-BILSTM/TCN-GRU/TCN-BIGRU/BITCN/BITCN-LSTM/BITCN-BILSTM/BITCN-GRU/BITCN-BIGRU/Transformer/Transformer-LSTM/Transformer-BILSTM/Transformer-GRU/Transformer-BIGRU等等多种分类/回归/时序/分解/区间预测/多输入多输出/聚类/组合预测模型,具体私信。
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 导入数据
res = xlsread('数据集.xlsx');
%% 数据分析
num_size = 0.75; % 训练集占数据集比例
outdim = 1; % 最后一列为输出
num_samples = size(res, 1); % 样本个数
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
flag_conusion = 1; % 标志位为1,打开混淆矩阵(要求2018版本及以上)
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
%% 划分训练集和测试集
M = size(P_train, 2);
N = size(P_test, 2);
% 获取 https://mbd.pub/o/DDR1
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
t_test = mapminmax('apply', T_test, ps_output);
%% 转置以适应模型
p_train = p_train'; p_test = p_test';
t_train = t_train'; t_test = t_test';
智能算法及其模型预测



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











