







 这篇博客记录了一个基于TensorFlow的深度学习表情识别项目,涵盖了数据预处理(包括随机过采样处理不平衡数据)、自定义神经网络模型的构建与训练,以及结合Haar级联分类器进行人脸检测来实现自然图片中的表情识别。
这篇博客记录了一个基于TensorFlow的深度学习表情识别项目,涵盖了数据预处理(包括随机过采样处理不平衡数据)、自定义神经网络模型的构建与训练,以及结合Haar级联分类器进行人脸检测来实现自然图片中的表情识别。
前言
数据集和一些其他相关文件可以在→这里←下载
数据集是48*48像素的灰度图片,用csv保存。
结合人脸检测的开源模型做到了自然图片中的表情识别
1.导入依赖库
首先加载所有依赖包
import collections # Python标准库,包含了除列表、字典、元组之外的容器数据类型
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 魔法指令,使图形直接在jupyter note
%matplotlib inline
# 机器学习处理工具
from sklearn.model_selection import train_test_split # sklearn的数据切分
from imblearn.over_sampling import RandomOverSampler # 随机上采样
#深度学习框架
from tensorflow import keras # 导入keras作为深度学习框剪tensorflow前端api
from tensorflow.keras.models import Model # 指定输入输出建立模型
#构建神经网络的各层函数
from tensorflow.keras.layers import Input, Add,Dense,Activation,ZeroPadding2D
from tensorflow.keras.layers import BatchNormalization,Flatten,Conv2D
from tensorflow.keras.layers import AveragePooling2D,MaxPooling2D,GlobalMaxPooling2D
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import BatchNormalization # 批量归一化工具
# keras图像数据预处理工具
from tensorflow.keras.preprocessing import image
import warnings
warnings.simplefilter('ignore')
import random
D:\ProgramFilesNotSpace\Anaconda3\envs\Ten_2_6_and_py_3_8\lib\site-packages\numpy\_distributor_init.py:30: UserWarning: loaded more than 1 DLL from .libs:
D:\ProgramFilesNotSpace\Anaconda3\envs\Ten_2_6_and_py_3_8\lib\site-packages\numpy\.libs\libopenblas.FB5AE2TYXYH2IJRDKGDGQ3XBKLKTF43H.gfortran-win_amd64.dll
D:\ProgramFilesNotSpace\Anaconda3\envs\Ten_2_6_and_py_3_8\lib\site-packages\numpy\.libs\libopenblas64__v0.3.21-gcc_10_3_0.dll
warnings.warn("loaded more than 1 DLL from .libs:"
2.数据预处理
2.1加载数据
考虑到实验环境中的内存资源,这里随机抽取20,000张图片进行训练。通过pandas的read_csv函数读取数据,在数据集中包合了原有的训练集和测试集,另外还有一份完整的带标签与像素值的数据train.csv,在本案例中,我们采用train.csv进行模型训练。
import random
filename = "./data/train.csv"
n = sum(1 for line in open(filename)) - 1 # 计算数据集中的总样本数(忽略表头)
s = 20000 # 采样量,采样过大会造成内存溢出而重启 notebook
skip = sorted(random.sample(range(1,n+1),n-s)) # 确保表头不会含在过的样本中
data_set = pd.read_csv(filename, skiprows=skip) # 增加 skiprows 参数,只采用机抽取的15000张图片训练
data_set.head()
| emotion | pixels | |
|---|---|---|
| 0 | 0 | 70 80 82 72 58 58 60 63 54 58 60 48 89 115 121... |
| 1 | 0 | 151 150 147 155 148 133 111 140 170 174 182 15... |
| 2 | 4 | 24 32 36 30 32 23 19 20 30 41 21 22 32 34 21 1... |
| 3 | 4 | 20 17 19 21 25 38 42 42 46 54 56 62 63 66 82 1... |
| 4 | 3 | 77 78 79 79 78 75 60 55 47 48 58 73 77 79 57 5... |
查看data_set的形状,当前数据集共有28109个样本(这里显示的20000是指加载了20000条数据,2代表有两列)
data_set.shape
(20000, 2)
将pixels列设置为特征,将emotion设置为标签
pixel_data = data_set['pixels']
label_data = data_set['emotion']
print(pixel_data.shape)
print(label_data.shape)
(20000,)
(20000,)
2.2 查看表情分布
统计数据集中,各种表情的数量占比,以此检查数据集的均衡性状况
ax = np.array(data_set.emotion)
dict1 = collections.Counter(ax) # 计数送代各类别数量并形成字典
plt.bar(list(dict1.keys()),list(dict1.values())) # 可视化各类别分布情况
<BarContainer object of 7 artists>
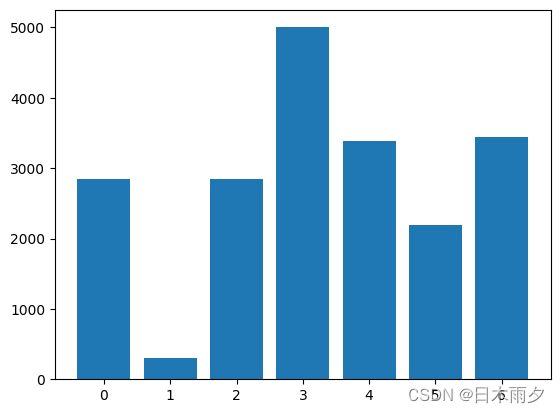
从上图可以看到:标签为1(厌恶)和5(惊讶)的表情样本,较其他几种表情少。由于本案例是一个多分类问题,应该尽可能将各种表情分类的样本数量保持一致或者接近——从而确保模型不会对任何一类表情有任何选择偏好。
2.3 数据均衡化
数据科学中的一个共识,是与其花大量的时间对建好的模型进行各种调优操作,不如在一开始就对源数据进行系统而严谨的处理。数据的质量决定模型的上限。但当我们开始面对真实的、未经加工过的数据时,很快就会发现这些数据要嘈杂且不平衡。真实数据看起来更像是般毫无规律且零散。对于不平衡类的研究通常认为不平衡意味着少数类只占10%~20%。但其实这已经算好的了,在现实中的许多例子会更加的不平衡(1~2%),如规划中的客户信用卡欺诈率,重大疾病感染率等。实际上,数据不平衡是一个非常符合客观事实的情况。因为,我们使用机器学习预测的,往往是在现实生活中罕见、意外的情况。因此,只有真实的数据,才总会存在数据不均衡的问题。
随机欠采样与过采样
- 过采样(也称:上采样):会随机复制少数量类别的样本,以增大它们的规模。
- 欠采样(也称:下采样):会随机减少多数量类别的样本,以减少它们的规模。
2.4 执行数据随机过采样
# 定义随机数据过来样,采样策略为自动
oversampler = RandomOverSampler(sampling_strategy='auto')
目前,pixel_data只是一个一维数组
pixel_data.ndim
1
使用reshape函数,将输入数据转换为模型可以接收的二维数组
pixel_data_2D = pixel_data.values.reshape(-1,1)
print(pixel_data_2D.shape)
(20000, 1)
得到所需的二维数组
pixel_data_2D.ndim
2
执行随机过采样
X_over, y_over = oversampler.fit_resample(pixel_data_2D, label_data)
查看各类表情的样本数据
a = np.array(y_over)
dict2 = collections.Counter(a) # 统计各类别数量形成字典
plt.bar(list(dict2.keys()), list(dict2.values())) # 可视化各类别分布 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









