









 本文详细介绍Hadoop集群的搭建步骤,包括环境变量配置、系统配置文件修改、目录创建、安装包分发、环境变量配置、集群启动及验证方法。
本文详细介绍Hadoop集群的搭建步骤,包括环境变量配置、系统配置文件修改、目录创建、安装包分发、环境变量配置、集群启动及验证方法。
(友情提示以下下面创建的路径跟我写的一样操作起来更便捷,同时主机名设置成node01,node02,node03)
第一步:上传压缩包并解压文件
创建一个文件存放压缩包:mkdir -p /export/soft

创建一个文件夹存放解压包:mkdir -p /export/servers

解压文件到指定文件中
tar -zxvf hadoop-2.6.0-cdh5.14.0.tar.gz -C /export/install

第二步:配置haddop环境变量
创建.sh文件到指定的路径中
vim /etc/profile.d/hadoop.sh
在文件里面添加下面的代码 (export表示文件包,前一个是:变量名=路径)
export HADOOP_HOME=/export/install/hadoop-2.6.0-cdh5.14.0
export PATH=
P
A
T
H
:
PATH:
PATH:HADOOP_HOME/bin

第三步:修改hadoop系统配置文件 (第一台机器执行以下的命令:)
切换路径到下面然后修改文件:cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop

修改文件:vim core-site.xml
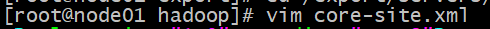
打开这个文件添加下面代码到下面图片指的箭头中(剩下的图片拷贝的代码也是)
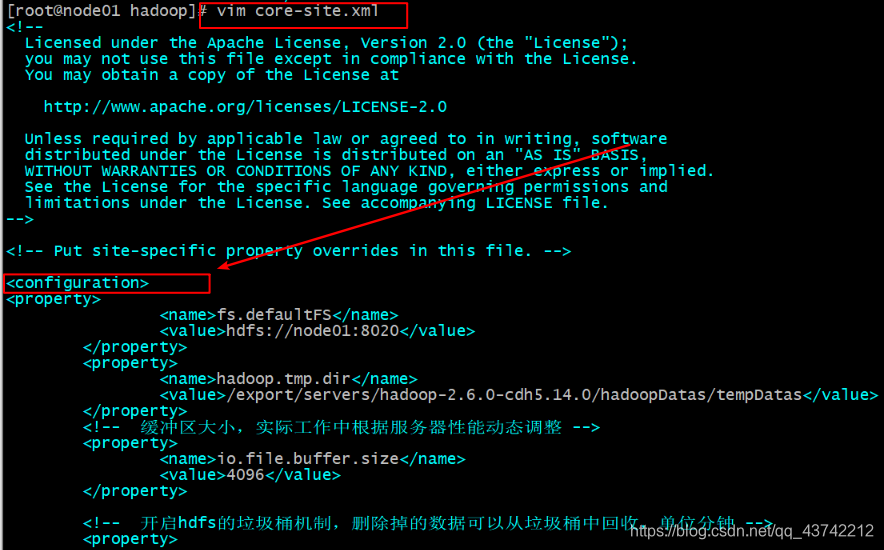
路径:cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
修改文件:vim hdfs-site.xml

路径: cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
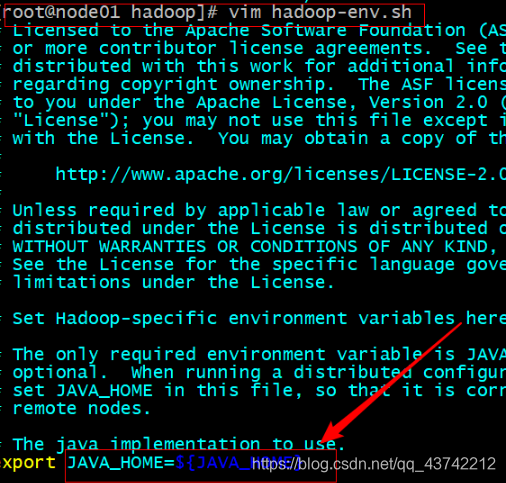
修改文件 : vim hadoop-env.sh
箭头所指的地方进行要保证 JAVA_HOME对应的是jdk的路径
可以测试一下保证路径正确

路径: cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
修改文件: vim mapred-site.xml
路径: cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
修改文件: vim yarn-site.xml
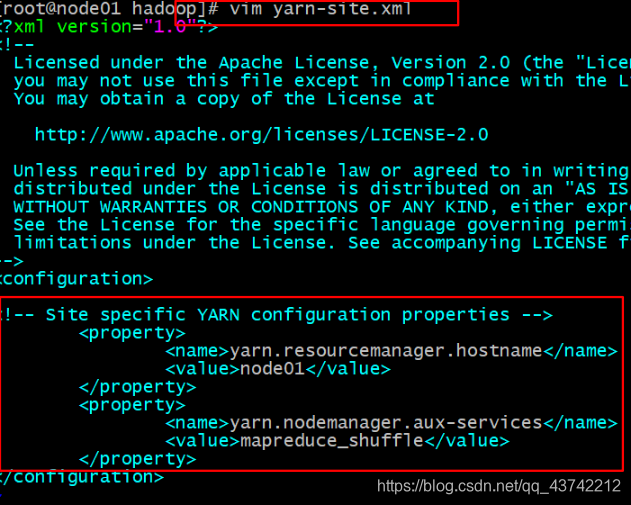
yarn.resourcemanager.hostname
node01
yarn.nodemanager.aux-services
mapreduce_shuffle
路径: cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
修改文件: vim slaves 在里面添加三台服务器的主机名
node01
node02
node03
第四步: 创建文件存放目录
第一台机器执行以下命令
node01机器上面创建以下目录
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/tempDatas
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/namenodeDatas
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/edits
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/snn/name
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/snn/edits
第五步: 安装包的分发
第一台机器把安装包拷贝到其他两台服务器
先切换目录:cd /export/servers/
然后远程拷贝:
scp -r hadoop-2.6.0-cdh5.14.0/ node02:路径
scp -r hadoop-2.6.0-cdh5.14.0/ node03:路径
第六步: 配置Hadoop的环境变量
三台机器都要进行配置Hadoop的环境变量
三台机器执行以下命令
vim /etc/profile.d/hadoop.sh
export HADOOP_HOME=/export/servers/hadoop-2.6.0-cdh5.14.0
export PATH=:
H
A
D
O
O
P
H
O
M
E
/
b
i
n
:
HADOOP_HOME/bin:
HADOOPHOME/bin:HADOOP_HOME/sbin:$PATH
配置完成之后生效
source /etc/profile
第七步: 启动集群
如果配置了 etc/Hadoop/slaves 和 ssh 免密登录,则可以使用程序脚本启动所有Hadoop 两个集群的相关进程,在主节点所设定的机器上执行。
启动集群
node01节点上执行以下命令
第一台机器执行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/
sbin/start-dfs.sh
sbin/start-yarn.sh脚本一键启动所有
一键启动集群
sbin/start-all.sh
停止集群:没事儿不要去停止集群
sbin/stop-dfs.sh
sbin/stop-yarn.sh
一键关闭集群
sbin/stop-all.sh
第八步: 浏览器查看启动页面
hdfs集群访问地址: http://192.168.52.100:50070/dfshealth.html#tab-overview
yarn集群访问地址: http://192.168.52.100:8088/cluster
1.
如何验证集群是否可用?请说出两种以上方式
a.jps查看进程
b.namenode所在节点的IP+50070端口查看HDFS的web界面是否可用
c.在HDFS系统中创建一个文件夹或文件,若可以创建则表示集群可以

















 2371
2371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









