







MySQL
注:本文档内容于Windows下测试、编写,此处均为入门级别语法,sql语法中,#表示注释
图例:
| 文档表示 | 含义 |
|---|---|
| ()中文状态括号 | 需要填数据,必填项 |
| [] | 可以填数据,选填项 |
一、了解mysql
连接数据库三种方式:
-
图形化界面工具(操作简单,略)
-
MySQL自带命令框
-
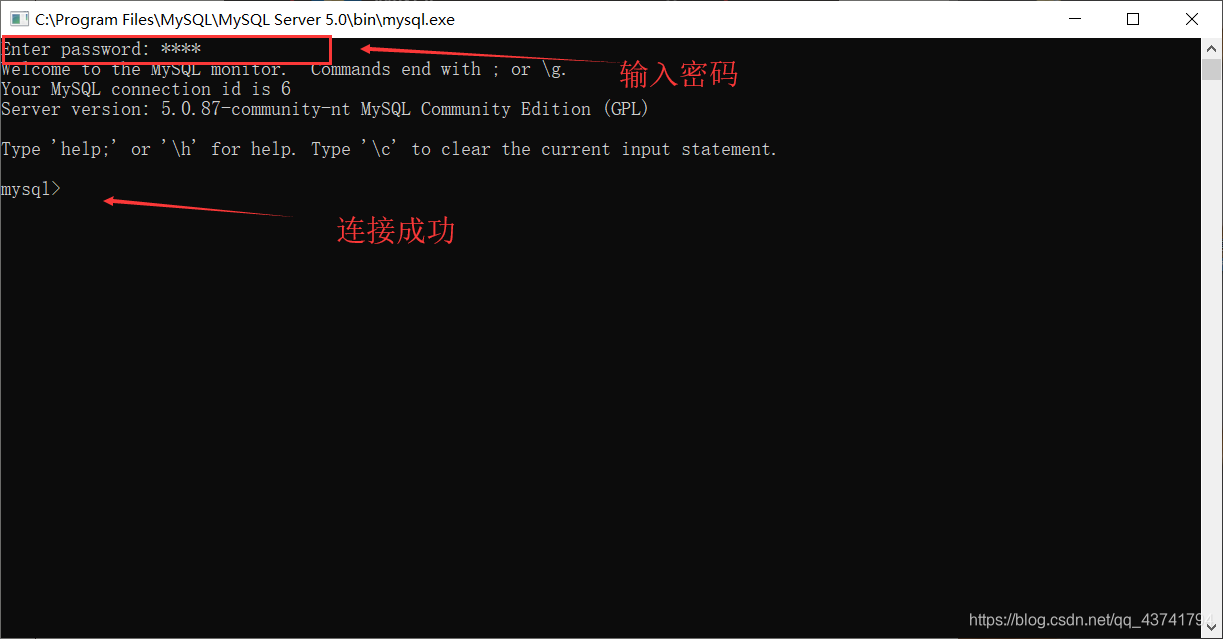
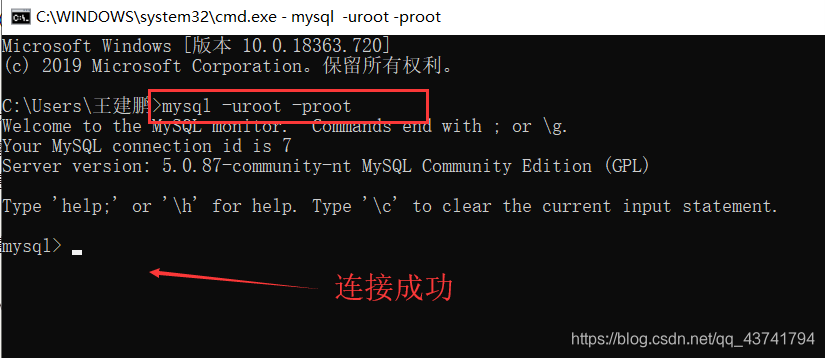
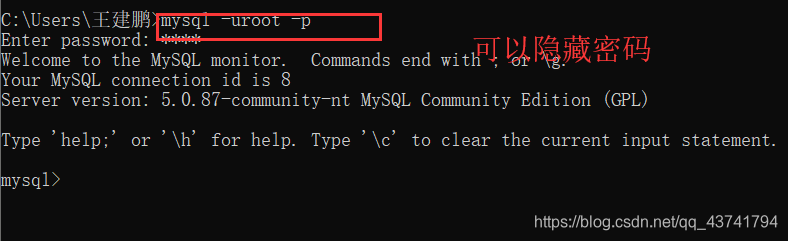
cmd
mysql -u(库名) -p(密码)*
*
退出方式
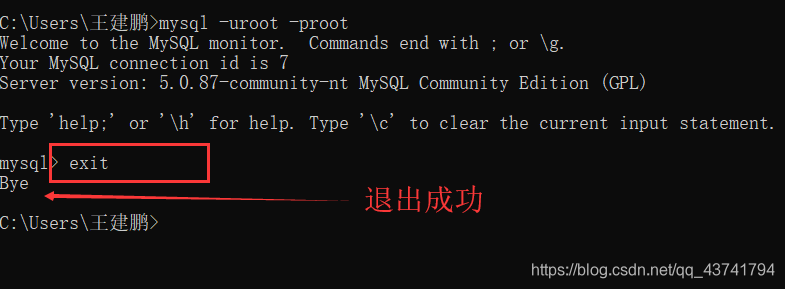
了解专业名词
-
库:存放表
-
表:在数据库中,表(table)类似于Excel,可以用来存放数据
- 字段:类似于Excel中的表头
- 数据类型:字符串(varchar)、整数(tinyint、int、bigint)、小数(float)、日期(Date、datetime)等
-
数据:文本、视频、图片、音频等
-
WHERE关键字:表条件,如果“=”是放在where关键字后,则是“关系运算符”
-
关系运算符:
- 在mysql中常用的关系运算符有:=(等于)、>、>=、<、<=、!=(不等于)
- 在mysql中关系运算符需要放置在where关键字之后
-
逻辑运算符:
- 在mysql中常见的逻辑运算有:与(and)、或(or)、非(not)
-
取模运算:
9 MOD 3 = 0 相当于java中的 9 % 3 == 0
二、创建库
语法:
CREATE DATABASE 库名 [CHARACTER SET 字符集 COLLATE 排序规则];
实践:
CREATE DATABASE lianxi CHARACTER SET utf8 COLLATE utf8_general_ci;
三、删除库
语法:
DROP DATABASE 库名
实践:谨慎使用此命令,此处不实践
四、创建表
语法:
CREATE TABLE 表名(
字段1 数据类型 [自增,主键等],
字段2 数据类型,
.....
)
实践:
# 表示我要使用这个表,接下来的操作是针对这个表的
USE lianxi;
# 开始创建表
CREATE TABLE lx(
id INT NOT NULL AUTO_INCREMENT, # 不为空,自增
stuid INT, # 可以指定长度
stuname VARCHAR(20), # 必须指定长度
score FLOAT,
birthday DATE,
PRIMARY KEY (id) # 设置主键
);
五、删除表
语法:
DROP TABLE 表名;
实践:同删除库,慎用
六、插入数据
语法1:
# 字段可以不全写,要求值必须与已写字段对应
INSERT INTO 表名(字段1,字段2....) VALUES(值1,值2....),(值1,值2....),...
#在插入时,可以省略掉表后面的字段名,但前提是:values关键字后面的字段值数量必须与表字段数量保持一致
INSERT INTO 表名 VALUES(值1,值2....);
实践1:
INSERT INTO lx(stuid, stuname, score, birthday) VALUES(101, 'tom', 99.5, '1999-05-09');
语法2:
INSERT INTO 表名 SET 字段名1=字段值1,字段名2=字段值2...
实践2:
INSERT INTO lx SET stuid=102,stuname='张三',score=98.9,birthday='1999-06-26';
七、删除数据
语法:
DELETE FROM 表名 WHERE 条件;
TRUNCATE TABLE 表名; # 下文DML中详细解释
实践:慎用!
八、查询数据
语法:
SELECT 字段1,字段2... FROM 表名 [WHERE 条件];
#在查询数据的时候,可以通过as来给某一个字段取别名
SELECT 字段1 AS 新名字 FROM 表名 [WHERE 条件];
#可以偷懒写为
SELECT 字段1 新名字 FROM 表名 [WHERE 条件];
#查询所有用*号表示
SELECT * FROM 表名 [WHERE 条件];
实践:
SELECT stuid,stuname,score,birthday FROM lx;
SELECT stuname AS '学生姓名' FROM lx;
SELECT stuname 学生姓名 FROM lx; # 不加引号也行
SELECT * FROM lx;
九、更新数据
语法:
UPDATE 表名 SET 字段名1=值1,字段名2=值2.... WHERE 条件
实践:
UPDATE lx SET stuname='LiMing' WHERE id=1;
十、对sql语句进行分类
1.DQL
数据库查询语言(DQL,database QUERY LANGUAGE):对表的查询语句,select
2.DDL
数据库定义语言(DDL,DATABASE defined LANGUAGE):create database、drop database、修改库、create table、drop table、修改表等
#DDL之操作数据库:
#添加数据库:create database 库名 【character set utf8/gbk】
#删除指定的数据库:drop database 库名;
#查询指定库的详细信息:
(1) show CREATE DATABASE 库名:查看某一个数据库的详细信息
SHOW CREATE DATABASE lianxi;
(2) SHOW DATABASES:查看mysql服务器软件下所有的库
(3) 查看:当前用户连接的是哪个数据库:select DATABASE();
(4) 查看指定的数据库下有哪些表: SHOW TABLES;
#修改指定库的编码:alter database 库名 character set 新编码名;
#DDL之对表的增删改查
#创建一张表:
CREATE TABLE 表名(字段名1 数据类型,字段名2 数据类型....);
#给表中的某一字段添加注释:使用comment属性,comment关键字跟在字段的最后面
#删除表:drop table 表名;
#查询:
(1)、查询某一张表的结构:desc 表名
DESC bank;
(2)、打印某一张表sql创建信息:show CREATE TABLE 表名;
SHOW CREATE TABLE bank;
#修改表:
(1):对已经存在的表进行重命名:rename TABLE 旧表名 TO 新表名;
RENAME TABLE aaa TO bank;
(2):往已经存在的表中添加字段信息:alter TABLE 表名 ADD 字段名 数据类型;
ALTER TABLE bank ADD gender VARCHAR(2);
(3):删除某一张表中的字段:alter TABLE 表名 DROP 被删除的字段名
ALTER TABLE bank DROP gender;
(4):对表中字段进行重命名:ALTER TABLE 表名 CHANGE 旧字段名 新字段名 新字段名数据类型
ALTER TABLE bank CHANGE aaa username VARCHAR(40);
(5):修改某一字段的数据类型长度:ALTER TABLE bank CHANGE bankNo bankNo VARCHAR(25);
#对某一数据库的备份与还原
#第一种通过命令:mysqldump -uroot -p密码 需要备份的数据库名>备份后的sql脚本名;
cmd--->mysqldump -uroot -proot dt55_account>c:\dt55_account_back.sql
还原备份的文件数据: 首先需要进入到mysql环境--->创建一个库---->在库下还原数据
----->source 备份的数据库脚本
#第二种通过图形化用户工具:选中需要备份的数据库---->右键---->备份/导出--->转储到sql
3.DML
数据库操作语言(DML,DATABASE manage LANGUAGE):update、insert、delete
十一、数据类型的属性
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bHxFNzuK-1589078194439)(D:\应用\W3Cschool-win32-x64\storehouse\数据库\MySQL详解视频全套资料_w3cschool.cn\mysql第6-9节上课资料-ok\数据类型属性.gif)]
默认值、自增、非空、主键、唯一键
#----------------------数据类型的属性-------------------
#mysql中常见的数据类型:varchar(n)、float、int(n)、bigint(n)、date、datetime、text
#默认值:DEFAULT ‘默认值’
#非空:NOT NULL,如果某一字段被NOT NULL修饰后,添加数据时,此字段必须填写
#自动增长:auto_increment,尽量作用在int类型字段上
#主键:primary key,不能够重复,一张表中只有一个字段可以作为主键
#唯一键:unique,被unique修饰的数据不能够重复
DROP TABLE students;
CREATE TABLE students(
id BIGINT(20) AUTO_INCREMENT PRIMARY KEY COMMENT '学生编号',
stuName VARCHAR(40) COMMENT '学生姓名',
gender VARCHAR(2) DEFAULT '男' COMMENT '性别',
className VARCHAR(20) NOT NULL COMMENT'班级',
phone VARCHAR(20) UNIQUE COMMENT '手机号码'
)
#此处的delete可以删除整张表,但是删除数据后,自增列不会从1开始
DELETE FROM students WHERE 1=1
#如果要删除一整张表中的数据,使用truncate。使用truncate删除数据后,如果字段时自增的,则重新从1开始
TRUNCATE TABLE students;
十二、排序
#---------------排序(order by 字段 降序/升序)------------------
#排序时字段类型可以是数值类型(int、float),也可以是varchar类型
#如果varchar类型对应的字段存放的是中文,则不能够排序;但是如果字段值都是英文,可以排序
#降序(DESC:)
SELECT * FROM users ORDER BY javaScore DESC;
SELECT * FROM users ORDER BY idcard DESC;
SELECT * FROM users ORDER BY username DESC;
#升序(ASC)
SELECT * FROM users ORDER BY javaScore ASC;
十三、函数
聚合函数:
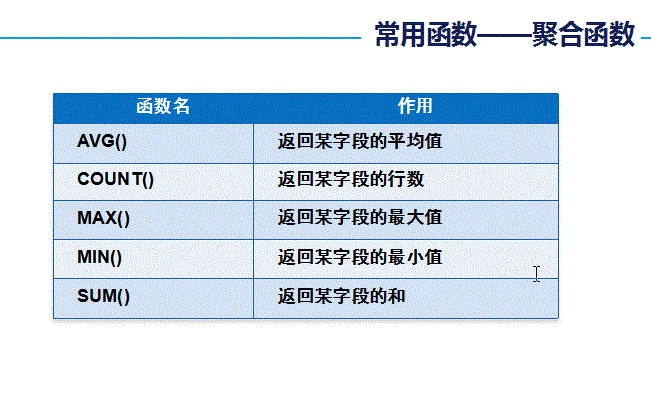
#-------------------------聚合函数-------------------------
#在mysql中函数使用select关键字调用:select 函数名(字段) 【FROM 表名】
#找出最大值:max(字段名)
#找出users表中javaScore的最高分
SELECT MAX(javaScore) AS 最高分 FROM users;
#找出最小值:min(字段名)
#找出users表中javaScore的最低分
SELECT MIN(javaScore) AS 最低分 FROM users;
#求平均数:avg(字段名)
SELECT AVG(javaScore) AS 平均分 FROM users;
#求和:
SELECT SUM(javaScore) AS 总分数 FROM users;
#统计记录:count(字段名)
#count(字段名):如果字段的值为NULL,则此字段对应的数据条数不再统计之内
#为了解决上述问题,在统计某一张表中的所有数据记录时,最好使用count(*)
SELECT COUNT(*) AS 总条数 FROM users;
常用函数:
时间函数
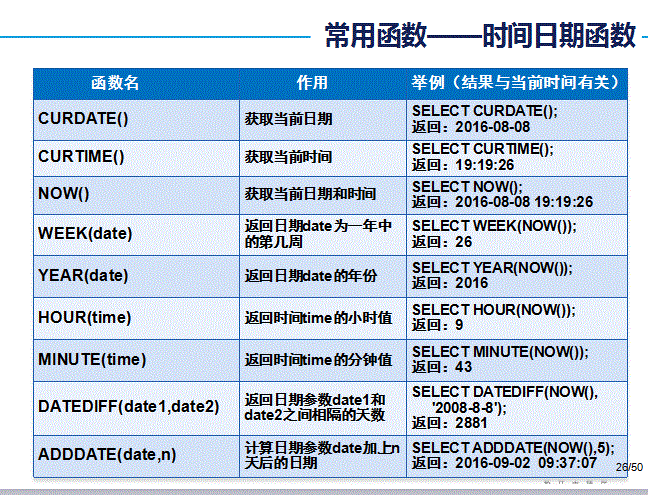
#-------时间函数---------------
#NOW():获取当前系统时间,时间格式包括年月日时分秒
SELECT NOW() AS 当前系统时间;
#CURTIME():只获取系统的时分秒
SELECT CURTIME();
#CURDATE():只获取系统的年月日
SELECT CURDATE();
时间格式化函数
- 占位符详见 : 时间格式转换函数参考文档
#-------------时间格式函数------------------
CREATE TABLE persons(
id BIGINT(20) NOT NULL AUTO_INCREMENT PRIMARY KEY COMMENT '主键',
personName VARCHAR(40) COMMENT '人名',
birthday DATETIME
)
SELECT personName,DATE_FORMAT(birthday,'%Y/%m/%d/ %H:%i:%s') AS birthday
FROM `persons`;#2017年12月25号
数学函数

#----------数学函数-------------------
#向上取舍:
SELECT CEIL(2.3) # 3
#向下取舍:floor(数值)
SELECT FLOOR(2.3) # 2
#随机数:rand():不用接受参数,返回的是0-1之间的小数
SELECT RAND()
#获取一个随机的4位数字,没有小数
SELECT CEIL(RAND()*10000)
十四、查询多条
#--------------------同时查询多条记录----------------------
#获取id=1或者id=2或者id=4
SELECT * FROM users WHERE id=1 OR id=2 OR id=4
#in(数据1,数据2...):判断表中某一个字段是否在in后面的参数列表之中
SELECT * FROM users WHERE id IN(1,2,4)
SELECT * FROM users WHERE id NOT IN(2,3) ORDER BY javaScore ASC;
十五、分组查询
#------------------分组查询(group by 分类字段)--------------
#查询goods表中商品的种类
SELECT goodsType FROM goods GROUP BY goodsType
#查询goods表中是否有种类为衣服的类型
#注意点:如果一个查询语句中使用了group by,则后面的条件需要使用having关键字
SELECT goodsType FROM goods GROUP BY goodsType HAVING goodsType='电脑'
十六、分页查询
#--------------分页(limit 起始下标,每页显示的数据量)-------------
#goods表中有7条数据记录,每页显示3条,总共可以分3页
#获取第一页数据
SELECT * FROM goods LIMIT 0,3;
#获取第二页数据
SELECT *FROM goods LIMIT 3,3;
#获取第三页的数据
SELECT * FROM goods LIMIT 6,3;
SELECT * FROM goods LIMIT (pageNo-1)*pageSize,pageSize;
十七、多表查询
方式一(夹杂union、union all)
#---------------------#多表查询(****)-----------------------
#同时查询多张表
SELECT * FROM 表1,表2...表n WHERE 条件
#查询users表中java最低分学生的名字,成绩和idcard
SELECT
u.username,
u.javaScore,
u.idcard
FROM
users u,
(
SELECT
MIN(javaScore) AS minScore
FROM
users
) temp
WHERE
u.javaScore = temp.minScore;
#(1)查询部门编号=1的部门下的所有员工
SELECT * FROM emp WHERE deptId=1
#(2)查询所有部门中的所有员工
SELECT 字段名1...字段n FROM 表1,表2...表n WHERE 条件
SELECT d.deptName,p.empName FROM dept d,emp p WHERE d.id=p.deptId
#(3)找出"开发部"中的所有员工名、薪水、部门名
SELECT d.deptName,e.empName,e.salary
FROM dept d,emp e
WHERE d.id=e.deptId AND d.deptName='开发部'
#(4)找出"开发部"和"测试部"中的所有员工名、薪水、部门名
#第一种方式
SELECT d.deptName,e.empName,e.salary
FROM dept d,emp e
WHERE d.id=e.deptId AND d.deptName IN ('开发部','测试部')
#第二种方式
SELECT d.deptName,e.empName,e.salary
FROM dept d,emp e
WHERE d.id=e.deptId AND (d.deptName='开发部' OR d.deptName='测试部')
#第三种方式(*)
#union、union all:可以将两个查询语句的结果进行合并,合并的前提是两个查询语句的数据结构是一样的
#union:可以自动去重
#union all:不能够去重
SELECT d.deptName,e.empName,e.salary
FROM dept d,emp e
WHERE d.id=e.deptId AND d.deptName='开发部'
UNION ALL
SELECT d.deptName,e.empName,e.salary
FROM dept d,emp e
WHERE d.id=e.deptId AND d.deptName='测试部'
方式二:连接关键词
内连接:inner join
#内连接: 表1 inner join 表2 on 条件(多个表之间有关联的条件)
#(1)查询所有部门中的所有员工
SELECT * FROM dept d,emp e WHERE d.id=e.deptId
SELECT d.deptName,e.empName,e.salary
FROM
dept d INNER JOIN emp e
ON d.id=e.deptId
#(2)找出"开发部"中的所有员工名、薪水、部门名
SELECT d.deptName,e.empName,e.salary
FROM
dept d INNER JOIN emp e
ON d.id=e.deptId WHERE d.deptName='开发部'
外连接:
左连接:
#左外连接:left join
#左外链接当条件不满足时,以左边的表为主
SELECT p.p_NAME,p.p_LINKMAN,b.`B_NAME`,b.`B_PRICE`,b.`B_AUTHOR`
FROM `publisher` p LEFT JOIN book b ON b.`P_ID`=p.P_ID
右连接:
#右外链接:right join
#右外链接当条件不满足时,以右边的表为主
SELECT p.p_NAME,p.p_LINKMAN,b.`B_NAME`,b.`B_PRICE`,b.`B_AUTHOR`
FROM `publisher` p RIGHT JOIN book b ON p.P_ID=b.`P_ID`
练习:3表查询
#求出teacherId=4的平均得分
#得到总分数
SELECT SUM(score) AS total FROM teacher_question WHERE teacherId=4
SELECT COUNT(*) AS num FROM `teacher_question` WHERE questionId=4 AND teacherId=4
SELECT temp1.total/temp2.num AS 平均分 FROM
(SELECT SUM(score) AS total FROM teacher_question WHERE teacherId=4) temp1,
(SELECT COUNT(*) AS num FROM `teacher_question` WHERE questionId=4 AND teacherId=4) temp2
#需求:想知道王二麻子具体买了哪些商品(商品名,价格,客户名,客户手机号)
SELECT g.goodName,g.price,c.customerName,c.phone
FROM goods g INNER JOIN goods_customer gc INNER JOIN customer c
ON g.id=gc.goodId AND gc.customerId=c.id WHERE c.customerName='王二麻子';
十八、模糊查询
# % 是占位符
#查询book表中b_AUTHOR以"王"开头的所有书籍
SELECT * FROM `book` WHERE B_AUTHOR LIKE '王%'
#查询book表中b_AUTHOR以"a"结尾的所有书籍
SELECT * FROM `book` WHERE B_AUTHOR LIKE '%a'
#查询book表中b_AUTHOR中包含"a"的所有书籍
SELECT * FROM `book` WHERE B_AUTHOR LIKE '%a%'
十九、视图
#视图:在真实表上面构建的一张虚表
#有dept、emp,要求查看所有的员工信息,还包括部门信息
SELECT * FROM dept d INNER JOIN emp e ON d.`id`=e.`deptId`
#创建视图语法:create view 视图名 as 查询语句;
CREATE VIEW view_all
AS SELECT e.id AS empId, e.`empName`,e.`salary`,e.`phone`,d.`deptName`
FROM dept d INNER JOIN emp e ON d.`id`=e.`deptId`
#删除视图:drop view 视图名
DROP VIEW `view_all`;
#查询某一视图中的数据
SELECT * FROM view_all WHERE empId=1;
#删除视图中的某一条数据
CREATE VIEW view_emp AS SELECT * FROM emp;
DELETE FROM view_emp WHERE id=1;
#往视图中添加数据
INSERT INTO view_emp SET empName='王二麻子'
SELECT * FROM view_emp;
#修改视图
UPDATE `view_emp` SET empName='李四' WHERE id=7
#视图的应用场景:在金融行业、保险行业、财务行业等
二十、事务
#事务:
#什么是事务?:多组操作要么全部成功要么全部失败
开启事务:start TRANSACTION;
回滚事务(如果事务提交后,不能够回滚):rollback;
提交事务:commit;
#事务的4大特性:
#原子性(automic):同一个事务中多组操作不能够分割,必须是一个整体
#一致性(consistent):事务操作前与事务操作后总量保持一致
#隔离性(isolation):多个事务之间互不干扰
#在mysql中事务有4种隔离级别:read uncommitted(读取未提交)、read committed(读取提交)、repeatable read(可以重复读)、Serializable
#查看mysql软件的事务隔离级别:select @@tx_isolation;
SELECT @@tx_isolation;
#修改mysql软件默认的隔离级别:set global transaction isolation level 隔离级别
SET GLOBAL TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
#不同的隔离级别会引发不同的问题:
#当mysql事务的隔离级别为read uncommitted时,会引发脏读:一个事务可以读取另一个事务未提交的数据
#如何解决脏读问题:可以将数据库事务的隔离级别改为:read committed
SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED;
#----------------------------
#当mysql软件的事务隔离级别为:read committed的时候,会引发不可重复读:在同一事物中多次读取的结果不一致
#如何解决不可重复读:将事物的隔离级别改为repeatable read
SET GLOBAL TRANSACTION ISOLATION LEVEL REPEATABLE READ;
#当mysql软件的事务隔离级别为:repeatable read时,会引发虚读(幻读)
#持久性(durable):数据一旦进入到库中、表中,就永久存在
二十一、存储过程
基本用法
#------------------存储过程--------------------------
#给员工加薪:加薪的金额(salary),员工编号(id)
#存储过程语法:
DELIMITER //
CREATE PROCEDURE 存储过程名(参数名1 参数类型1,参数名2 参数类型2)
BEGIN
代码块;
END//
DELIMITER ;
#书写一个加薪的存储过程
#存储过程:是一组sql语句的集合
DELIMITER //
CREATE PROCEDURE addSalary(money FLOAT,idd BIGINT)
BEGIN
UPDATE `emp` SET salary=salary+money WHERE id=idd;
END//
DELIMITER ;
#调用存储过程:call 存储过程名()
CALL `addSalary`(-1000,9);
#删除存储过程
DROP PROCEDURE [if exists] 存储过程名;
DROP PROCEDURE `addSalary`;
带返回值的存储过程
#--------------------带返回值的存储过程-----------------------
#test1:传递两个float类型的形参,返回两个数的和
DELIMITER //
CREATE PROCEDURE test1(IN i FLOAT,IN j FLOAT,OUT num FLOAT)
BEGIN
SET num=i+j;
END//
DELIMITER ;
# 调用
CALL `test1`(10,20,@result)
# 取值
SELECT @result
带if的存储过程
#带if语句的存储过程
#加薪的存储过程,传递两个参数:id、m(只能够传递正数,不能够传递负数)
DELIMITER //
CREATE PROCEDURE pro_addSalary(idd BIGINT,m FLOAT)
BEGIN
IF m>0 THEN
UPDATE users SET money=money+m WHERE id=idd;
END IF;
END//
DELIMITER ;
CALL `pro_addSalary`(1,-500); # 执行成功,但不会更新表数据
if…else
#带if..else的存储过程
DROP PROCEDURE IF EXISTS pro_salaryAdd;
DELIMITER //
CREATE PROCEDURE pro_salaryAdd(idd BIGINT,m FLOAT)
BEGIN
IF m>0 THEN
UPDATE users SET money=money+m WHERE id=idd;
ELSE
SELECT '亲,您输入的金额不能够为负数!!!' AS '友情提示';
END IF;
END//
DELIMITER ;
CALL `pro_salaryAdd`(1,-2000); # 输出else下的提示信息
if…else if…
#带if...else if...else语句的存储过程
#存储过程名:pro_buyCar(money float),如果money>500万则买保时捷;否则如果money>300万,买宝马;否则如果money>10万买奥拓;否则骑摩拜
DELIMITER //
CREATE PROCEDURE pro_buyCar(money FLOAT)
BEGIN
IF money>500 THEN
SELECT '买保时捷' AS '买啥';
ELSEIF money>300 THEN
SELECT '宝马' AS '买啥';
ELSEIF money>10 THEN
SELECT '奥拓' AS '买啥';
ELSE
SELECT '骑摩拜' AS '骑啥';
END IF;
END//
DELIMITER ;
CALL `pro_buyCar`(5); # 输出骑摩拜
case
#case选择分支结构
#存储过程名:pro_case(i int),如果i=1则打印星期一,i=2则打印星期二....
DELIMITER //
CREATE PROCEDURE pro_case(i INT)
BEGIN
CASE i
WHEN 1 THEN
SELECT '星期一' AS '日期';
WHEN 2 THEN
SELECT '星期二' AS '日期';
ELSE
SELECT '今天不是周一或者周二,到底周几你猜?' AS '日期';
END CASE;
END//
DELIMITER ;
CALL `pro_case`(2); # 输出“星期二”
while
#存储过程名:pro_while2(i int),如果i=100,则计算1到100之间的所有数之和,返回最终结果
DELIMITER //
CREATE PROCEDURE pro_while2(IN i INT,OUT total INT)
BEGIN
DECLARE a INT DEFAULT 1; # 用DECLARE关键字声明变量,先声明变量名,后写变量类型,DEFAULT设置默认值
SET total=0; #SET进行赋值
WHILE a<=i DO
SET total=total+a;
SET a=a+1;
END WHILE;
END//
DELIMITER ;
CALL `pro_while2`(100,@aaa);
SELECT @aaa;
loop
##loop循环:
CREATE PROCEDURE 存储过程名()
BEGIN
loop循环别名:LOOP
循环体;
LEAVE loop循环别名; # 结束循环
END LOOP;
END;
#通过loop循环往users表中同时添加100条记录
DELIMITER //
CREATE PROCEDURE pro_loop()
BEGIN
DECLARE i INT DEFAULT 0;
loop_test1:LOOP
INSERT INTO `users` SET username='admin',money=200;
SET i = i+1;
IF i=100 THEN
LEAVE loop_test1;
END IF;
END LOOP;
END//
DELIMITER ;
CALL `pro_loop`();
一些不常用写法
#赋值某一张指定的表以及表数据
CREATE TABLE aaa(
SELECT * FROM `publisher`
);
#插入数据
INSERT INTO aaa
SELECT * FROM aaa;
# 直接输出
SELECT '亲,您输入的金额不能够为负数!!!' AS '友情提示';


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









