









单机单卡和单机多卡性能对比
本文针对人脸检测项目内容对单机单卡和单机多卡在性能做简单测评
任务:人脸检测
算法:DamoFD
设备: 1 * A100 * 80G , 4 * A100 * 80G
环境:pytorch1.11
数据集:卡通人脸10000张,项目数据验证机123张
模型:单卡和4卡在DamoFD80个epoch的onnx权重
评测指标:Precision,Recall,F1
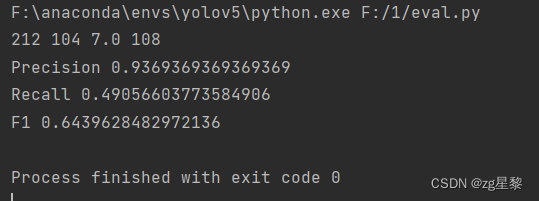
单机单卡在123张数据的指标
单机多卡在123张数据的指标
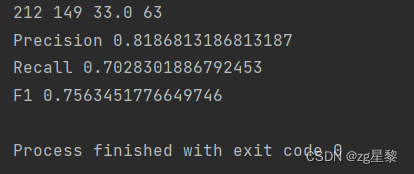
单机单卡在10000张卡通数据的指标
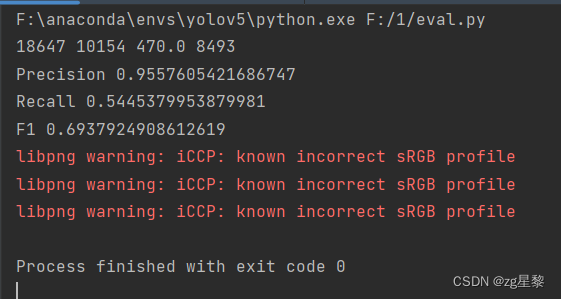
单机多卡在10000张卡通数据的指标
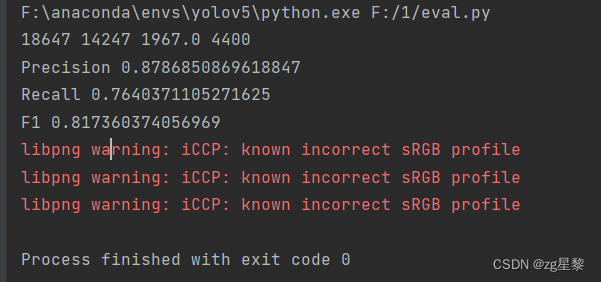
结果
从两批数据上我们不难看出单机多卡的性能是优于单机多卡的,事实上也确实如此。博主在对数据测评后发现,单机单卡的误报比较少,但召回低很多,在小目标上比原论文差,对动漫数据的准确率较高。单机多卡准确率略低一点,但对小目标的召回以及卡通数据的泛化性上都优于单机单卡。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











