







目录
1 NameNode的核心角色与重要性
NameNode是Hadoop分布式文件系统(HDFS)的"大脑",负责管理整个文件系统的命名空间和元数据。作为HDFS的主控节点,它的稳定运行直接关系到整个集群的可用性。
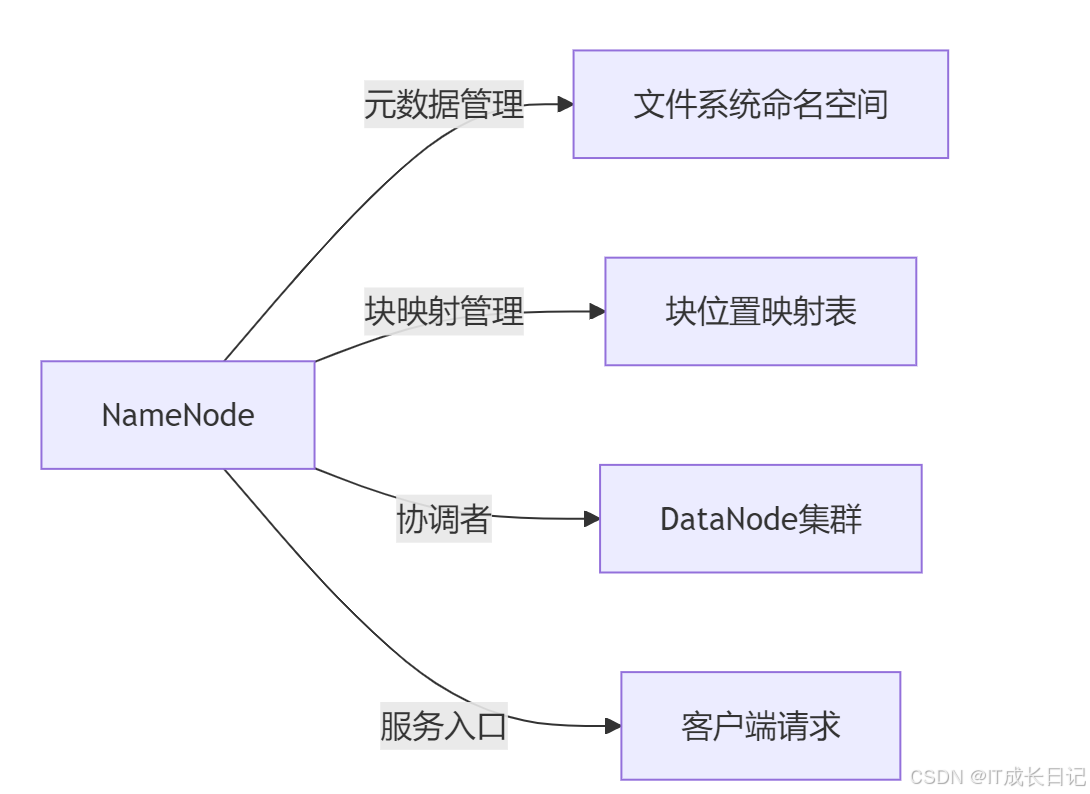
2 NameNode的核心职责
2.1 元数据管理
- 文件系统命名空间:维护文件/目录的层级结构
- 块映射信息:记录每个文件块对应的DataNode位置
- 访问控制:管理文件权限和ACL
2.2 集群协调
- DataNode监控:通过心跳机制检测节点存活状态
- 块副本管理:确保数据块达到指定副本数
- 负载均衡:指导数据均匀分布
2.3 客户端服务
- 文件操作处理:创建/删除/重命名等操作
- 块位置查询:为读取请求提供最佳DataNode位置
3 NameNode运行原理详解
3.1 元数据存储机制
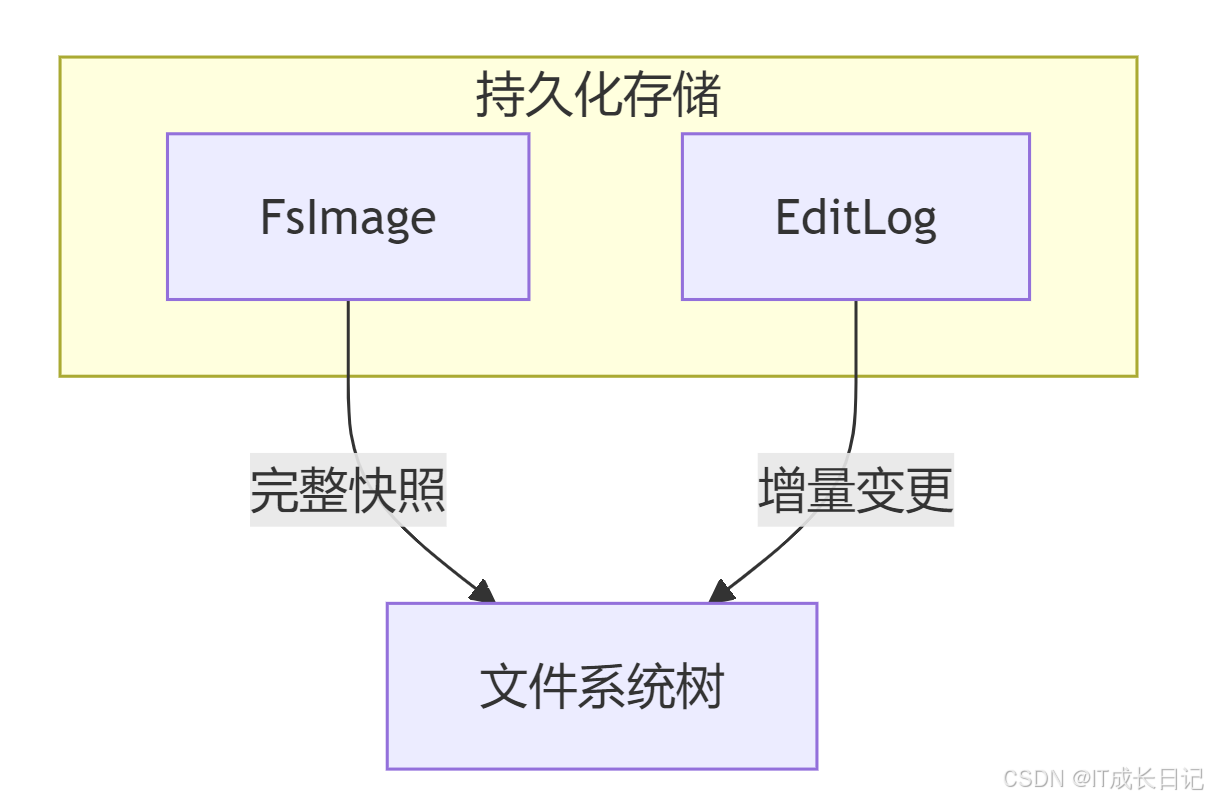
- FsImage:文件系统元数据的完整快照
- EditLog:记录所有对元数据的修改操作
- 合并机制:SecondaryNameNode定期合并EditLog到FsImage
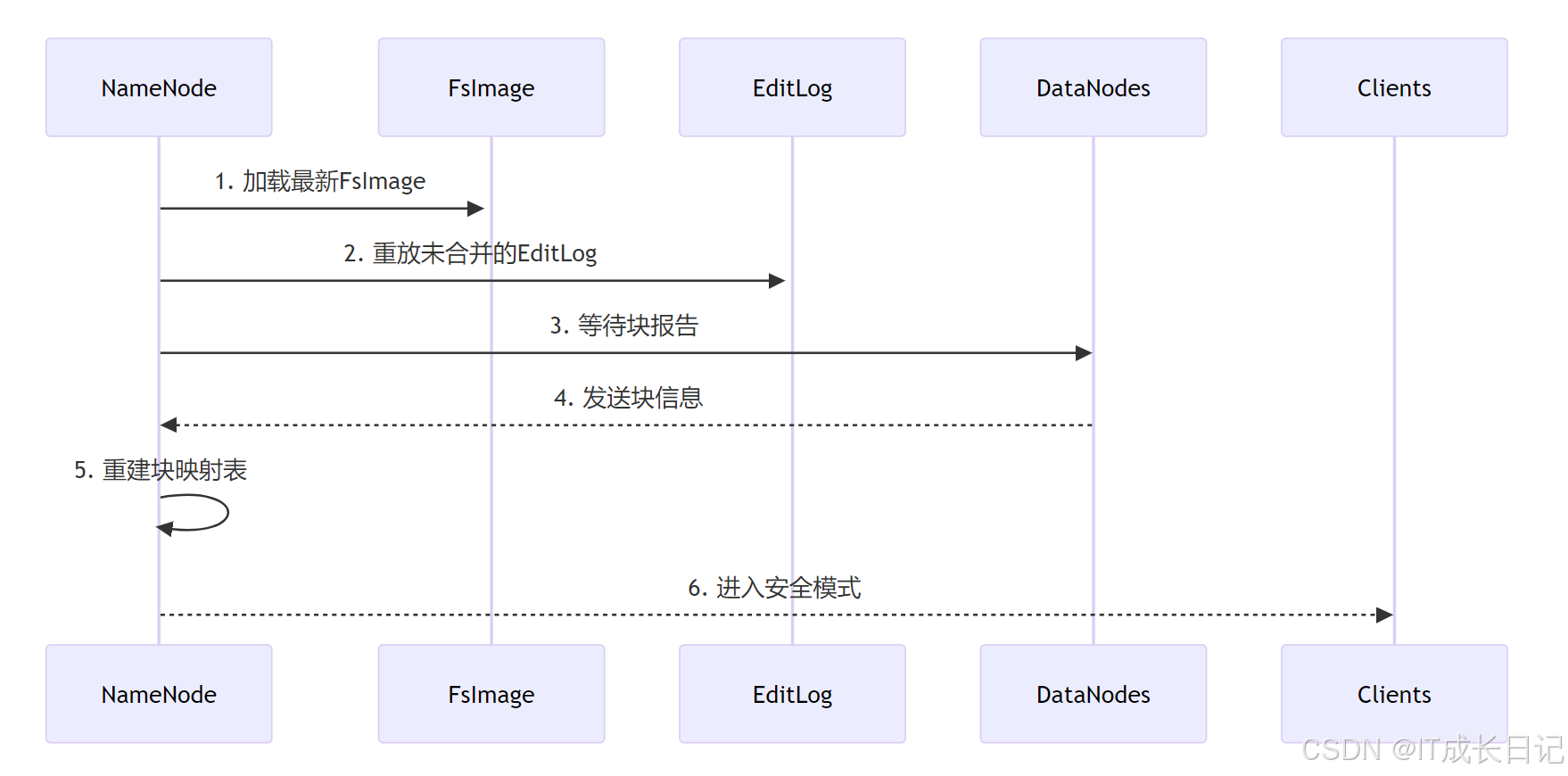
3.2 启动与恢复流程
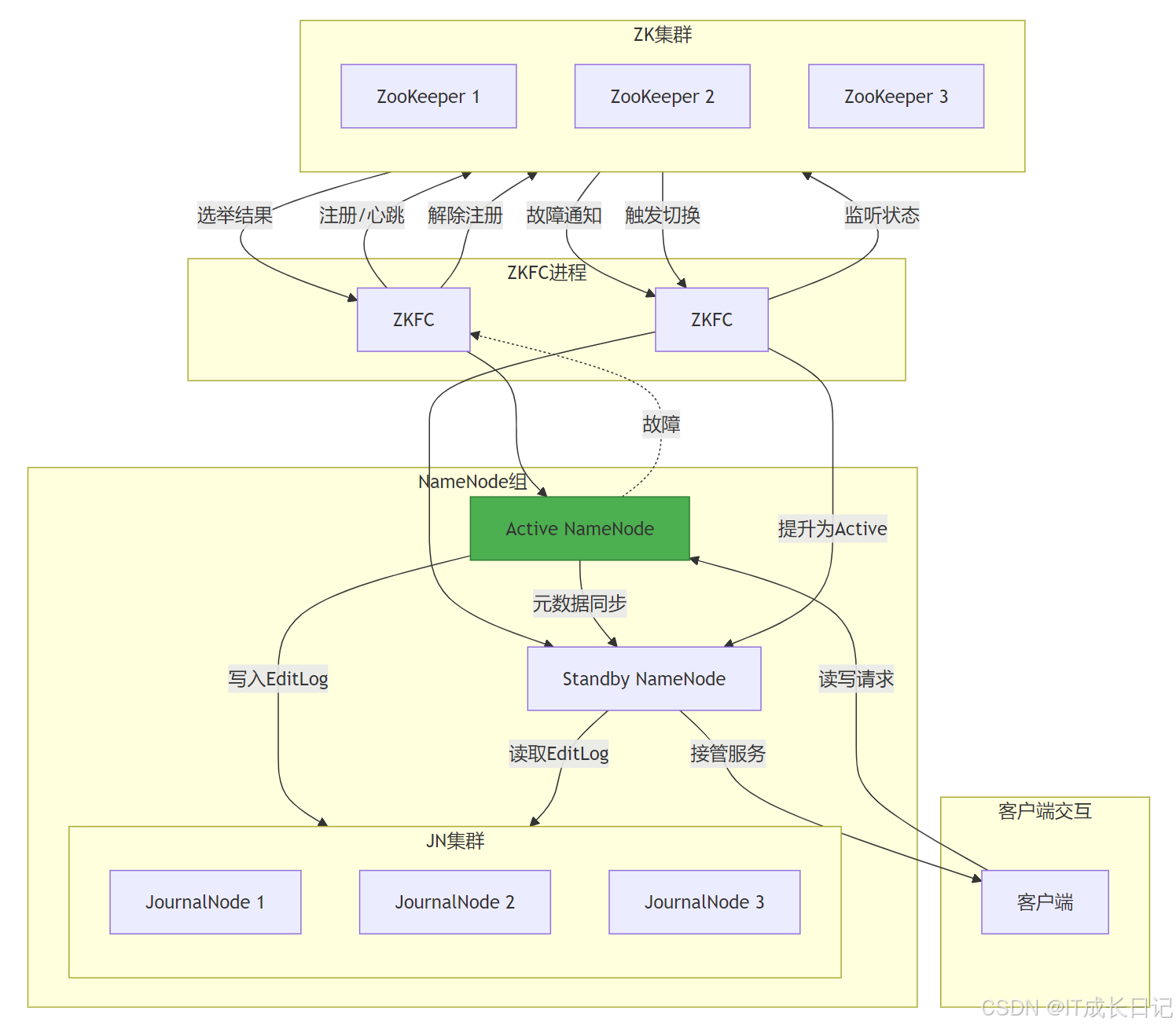
3.3 高可用(HA)机制
4 NameNode关键工作机制
4.1 心跳检测机制
- DataNode每3秒发送心跳
- 超过10分钟无心跳则判定节点失效
- 连续3次失败后触发副本恢复
4.2 安全模式运作

- 安全模式:只读状态,不执行修改操作
- 退出条件:达到dfs.namenode.safemode.threshold-pct(默认99.9%)
4.3 元数据缓存优化
// 典型的内存数据结构
class NameNode {
ConcurrentHashMap<String, INode> fsNamespace; // 文件系统树
BlockManager blockManager; // 块映射管理
LeaseManager leaseManager; // 文件租约控制
}5 NameNode性能优化
5.1 内存配置建议
| 场景 | JVM堆大小 | 元数据缓存 |
| 小集群( | 4-8GB | 默认值 |
| 中等集群 | 8-16GB | 增加dfs.namenode.handler.count |
| 大集群(>5亿文件) | 32GB+ | 使用Off-Heap缓存 |
5.2 关键参数调优
<!-- hdfs-site.xml -->
<property>
<name>dfs.namenode.handler.count</name>
<value>40</value> <!-- 默认30 -->
</property>
<property>
<name>dfs.namenode.avoid.read.stale.datanode</name>
<value>true</value> <!-- 避免读取陈旧节点 -->
</property>6 NameNode故障处理
6.1 常见问题排查指南
- 内存溢出
- 现象:频繁Full GC,响应变慢
- 解决:增加堆内存,检查元数据量
- EditLog损坏
# 恢复最后有效FsImage
hdfs namenode -importCheckpoint- 脑裂问题
- 现象:双Active NameNode
- 解决:配置正确的fencing方法
7 NameNode监控指标
| 指标类别 | 关键指标 | 健康值 |
| 内存使用 | HeapUsed | 小于80% |
| 文件数量 | FilesTotal | 根据内存调整 |
| 请求延迟 | RpcProcessingTime | 小于100ms |
| 块报告 | MissingBlocks | 0 |
8 总结
NameNode作为HDFS的核心枢纽,其设计体现了分布式系统管理的精髓,理解其工作原理对于集群运维和性能优化至关重要。


















 5150
5150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











