







目录
3.3 ZKFailoverController(ZKFC)
1 HDFS核心架构概述
Hadoop 2.0及以后版本的HDFS(Hadoop Distributed File System)采用了主/从(Master/Slave)架构,主要由NameNode、DataNode以及一系列辅助组件构成。HDFS的设计目标是实现高吞吐量、高容错性的数据存储,适用于大规模数据集的分布式处理。
2 高可用设计背景
在Hadoop 1.x版本中,NameNode是单点故障,一旦NameNode出现故障,整个HDFS集群将不可用。为了解决这个问题,Hadoop 2.0引入了NameNode的高可用性(HA)机制,确保在NameNode出现故障时,系统能够迅速恢复,保证数据的持续可用性。
3HDFS核心组件
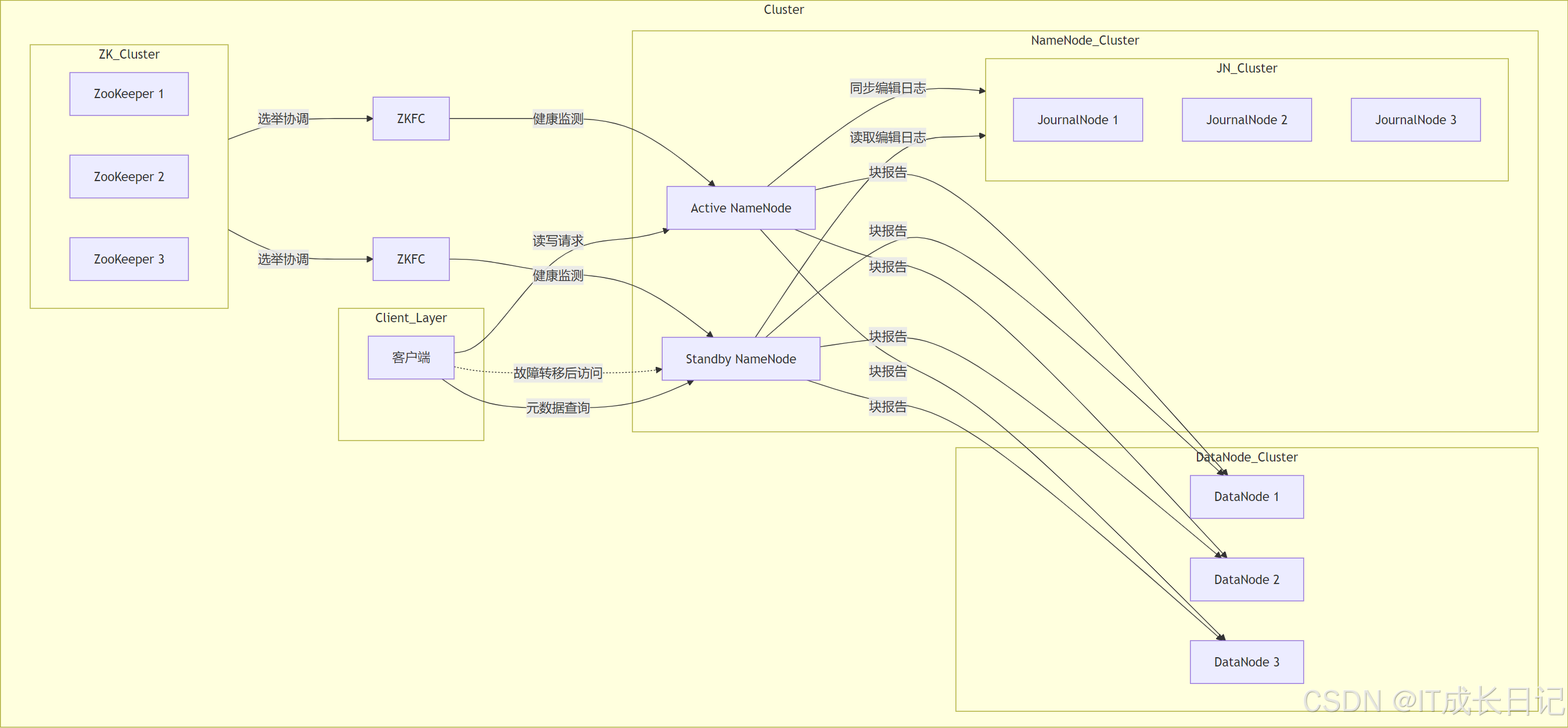
3.1 Active与Standby NameNode
- 功能:
- Active NameNode:处理所有客户端的读写请求,管理文件系统的命名空间
- Standby NameNode:作为热备份,与Active NameNode保持同步,随时准备接管
- 高可用性实现:
- 通过配置两个NameNode(一个Active,一个Standby),确保在Active NameNode出现故障时,Standby NameNode能够迅速接管
- 使用JournalNode实现Active和Standby NameNode之间的元数据同步
3.2 JournalNode
- 功能:
- 在NameNode的高可用性配置中,JournalNode用于实现NameNode之间的编辑日志共享
- Active和Standby NameNode都通过JournalNode来记录编辑日志,确保两者之间的元数据保持一致
- 工作原理:
- Active NameNode将编辑日志写入JournalNode集群
- Standby NameNode从JournalNode集群读取编辑日志,并在本地应用这些日志,以保持与Active NameNode的元数据同步
3.3 ZKFailoverController(ZKFC)
- 功能:
- 基于Zookeeper实现NameNode的故障转移控制
- 监控NameNode的健康状态,并在Active NameNode出现故障时触发故障转移
- 工作原理:
- ZKFC在Zookeeper中创建一个会话,并注册一个临时的Znode来表示Active NameNode的状态
- 当Active NameNode出现故障时,Zookeeper会检测到会话超时,并通知Standby NameNode的ZKFC进行故障转移
- Standby NameNode的ZKFC在确认Active NameNode确实故障后,将Standby NameNode切换为Active状态,并接管所有客户端请求
3.4 DataNode
- 功能:
- 存储实际的数据块,根据NameNode的指示进行数据存储和检索
- 定期向NameNode发送心跳信号和块报告,以确认其状态和存储的数据块信息
- 在高可用设计中的角色:
- DataNode并不直接参与NameNode的故障转移过程,但它们的状态和存储的数据块对于HDFS的整体可用性至关重要
- 在NameNode故障转移后,新的Active NameNode需要能够快速获取DataNode的状态信息,以确保数据的正确性和一致性
4 高可用设计的工作流程
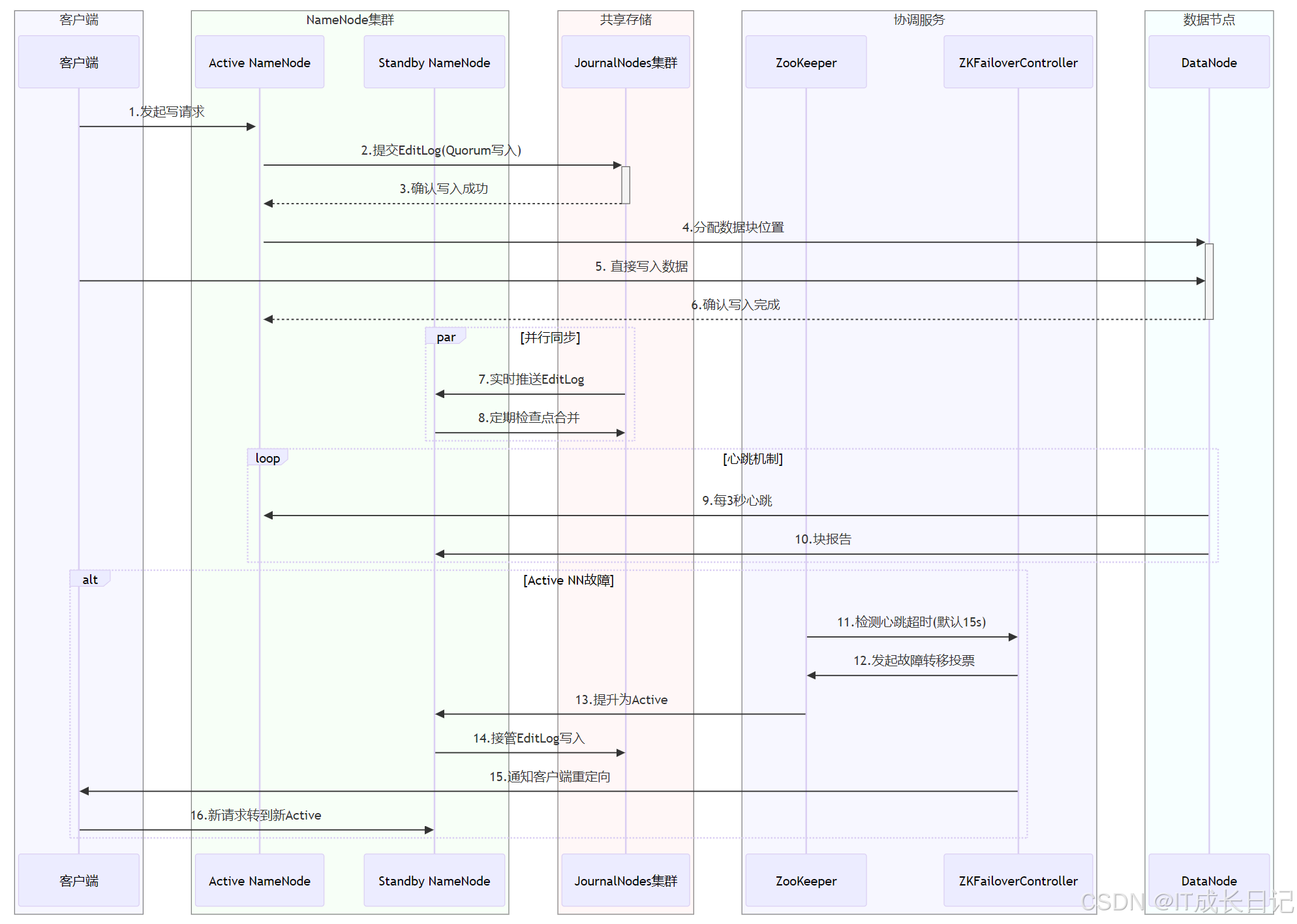
写入阶段:
客户端与Active NN交互:
- 在HDFS的写入阶段,客户端只与Active NameNode(NN)进行交互。Active NameNode负责处理所有客户端的读写请求,并管理文件系统的命名空间
EditLog确认机制:
- 当客户端发起写请求时,Active NameNode会记录相关的操作到EditLog中。为了确保EditLog的可靠性,HDFS采用了多数JournalNodes确认的机制。例如在3个JournalNodes的集群中,至少需要2个JournalNodes成功写入EditLog,才能认为该操作被成功记录
数据直接写入DN:
- 客户端在获得Active NameNode的写入许可后,会直接将数据写入DataNode(DN),这种设计避免了NameNode成为数据写入的瓶颈,提高了系统的整体写入性能
元数据同步:
Standby NN实时追踪EditLog:
- Standby NameNode会实时追踪Active NameNode的EditLog,以确保两者之间的元数据保持一致;当Active NameNode记录新的EditLog时,Standby NameNode会从JournalNodes中读取并应用这些日志
定期执行检查点合并:
- 为了减少NameNode重启时的恢复时间,Standby NameNode会定期执行检查点合并操作。它将EditLog中的操作应用到FsImage(命名空间镜像)中,生成新的FsImage文件;在NameNode重启时,可以直接加载最新的FsImage文件,而无需重放大量的EditLog
健康监测:
DataNode同时向主备NN发送块报告:
- DataNode会同时向Active和Standby NameNode发送块报告,以告知它们自己存储的数据块信息;即使Active NameNode出现故障,Standby NameNode也能迅速获取到最新的数据块信息
心跳超时触发故障检测:
- NameNode会定期向DataNode发送心跳信号,以检测DataNode的健康状态,如果某个DataNode的心跳信号超时,NameNode会认为该DataNode出现故障,并采取相应的措施(如复制数据块到其他DataNode),同样地ZKFailoverController也会通过Zookeeper来监控Active NameNode的健康状态,一旦检测到故障,就会触发故障转移过程
故障转移:
ZKFC通过ZooKeeper实现分布式协调:
- ZKFailoverController(ZKFC)是基于Zookeeper的故障转移控制器,它负责监控NameNode的健康状态,并在Active NameNode出现故障时触发故障转移过程;ZKFC通过Zookeeper来实现分布式协调,确保故障转移过程的可靠性和一致性
典型切换时间30秒内:
- 在Hadoop 2.0及以后版本中,HDFS的故障转移时间被大大缩短,典型情况下,从Active NameNode出现故障到Standby NameNode接管所有客户端请求的时间可以在30秒内完成(具体时间取决于session.timeout配置),这种快速的故障转移能力确保了HDFS的高可用性和数据可靠性
5 高可用设计的优势
- 提高系统可用性:通过配置Active和Standby NameNode,确保在NameNode出现故障时系统能够迅速恢复
- 增强数据可靠性:DataNode的数据冗余和容错机制确保即使某个DataNode出现故障,也不会影响整个文件系统的正常运行
- 简化运维管理:高可用设计减少了单点故障的风险,降低了运维管理的复杂度
6 总结
Hadoop 2.0及以后版本的HDFS通过引入NameNode的高可用性机制,显著提高了系统的可用性和数据可靠性。Active与Standby NameNode、JournalNode、ZKFailoverController以及DataNode等核心组件共同构成了HDFS的高可用架构,确保了HDFS在节点故障、网络分区等异常情况下仍能保持数据的可靠性和系统的可用性。这一设计使得HDFS成为大规模数据存储和处理的首选平台之一。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











