







 该博客通过读取数据、数据预处理、训练集交叉验证,对比了k近邻、随机森林和支持向量机三种分类模型在用户流失预测上的效果。模型评价和混淆矩阵的可视化进一步揭示了模型在不同阈值下的表现。
该博客通过读取数据、数据预处理、训练集交叉验证,对比了k近邻、随机森林和支持向量机三种分类模型在用户流失预测上的效果。模型评价和混淆矩阵的可视化进一步揭示了模型在不同阈值下的表现。
该案例主要目的:根据用户一系列属性,对用户是否流失做出合理判断
1.读取数据
from __future__ import division
import pandas as pd
import numpy as np
#读取数据
churn_df = pd.read_csv('churn.csv')
col_names = churn_df.columns.tolist()
#打印列名
print("Column names:")
print(col_names)
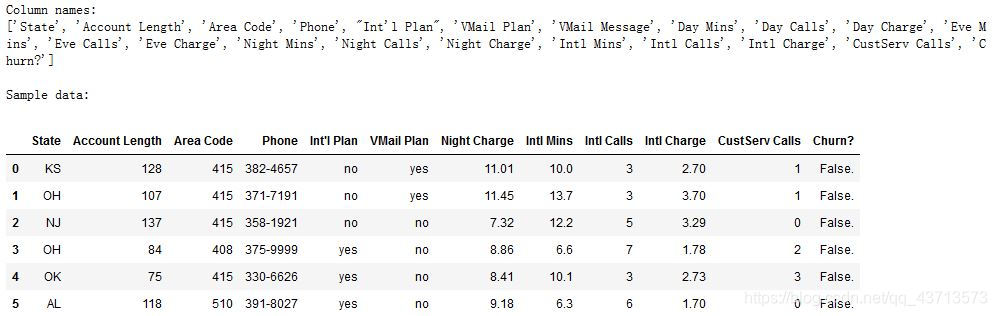
#显示左边五列和右边五列数据
to_show = col_names[:6] + col_names[-6:]
#打印前六行
print("\nSample data:")
churn_df[to_show].head(6)
- 输出结果如下:
2.数据预处理
#将最后一列标签字段(字符型)数据类型转化为数值型
churn_result = churn_df['Churn?']
y = np.where(churn_result == 'True.',1,0)
# 删除无用字段
to_drop = ['State','Area Code','Phone','Churn?']
churn_feat_space = churn_df.drop(to_drop,axis=1)
# 将"Int'l Plan"和"VMail Plan" 两列转化为数值型
yes_no_cols = ["Int'l Plan","VMail Plan"]
churn_feat_space[yes_no_cols] = churn_feat_space[yes_no_cols] == 'yes'
# 所有属性字段名
features = churn_feat_space.columns
X = churn_feat_space.values.astype(np.float)
# 数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X = scaler.fit_transform(X)
#显示记录数量和特征数量值
print('Feature space holds {} observations and {} features'.format( X.shape[0], X.shape[1])) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1222
1222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









