







 超级会员免费看
超级会员免费看
 本文探讨了深度学习模型的泛化性问题,包括模型过拟合的原因和解决方案。重点介绍了正则技术,如Dropout和数据增强,以及模型优化、对抗攻击、迁移学习和集成学习对提升泛化性能的作用。文章还讨论了对抗训练、迁移学习的挑战和方法,以及模型蒸馏等技术,为大模型时代的科研提供了思路。
本文探讨了深度学习模型的泛化性问题,包括模型过拟合的原因和解决方案。重点介绍了正则技术,如Dropout和数据增强,以及模型优化、对抗攻击、迁移学习和集成学习对提升泛化性能的作用。文章还讨论了对抗训练、迁移学习的挑战和方法,以及模型蒸馏等技术,为大模型时代的科研提供了思路。
暂时无法在飞书文档外展示此内容
零、泛化性
-
泛化性指模型经过训练后,应用到新数据并做出准确预测的能力。一个模型在训练数据上经常被训练得太好即过拟合,以致无法泛化。
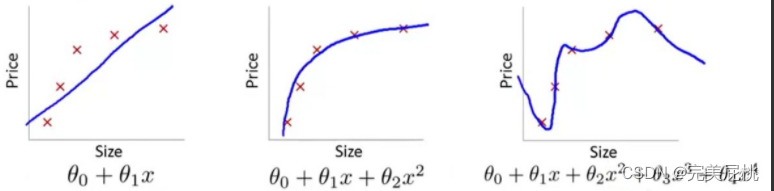
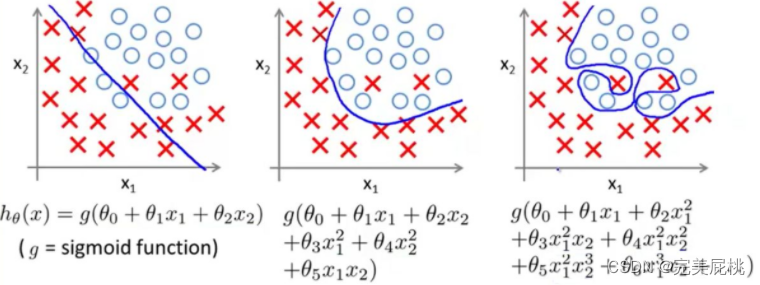
深度学习模型过拟合的原因,不仅仅是数据原因:
-
模型复杂度过高:如果模型具有过多的参数或层次,它可以很容易地记住训练数据的细节,但却不能泛化到新的数据上。这会导致模型在测试数据上表现不佳。
暂时无法在飞书文档外展示此内容
泛化性指模型经过训练后,应用到新数据并做出准确预测的能力。一个模型在训练数据上经常被训练得太好即过拟合,以致无法泛化。
深度学习模型过拟合的原因,不仅仅是数据原因:
模型复杂度过高:如果模型具有过多的参数或层次,它可以很容易地记住训练数据的细节,但却不能泛化到新的数据上。这会导致模型在测试数据上表现不佳。
 1329
1329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文























