







 超级会员免费看
超级会员免费看
 该论文提出了一种名为VFD的深度学习模型,通过匹配音频和人脸的内在相关性来进行Deepfake检测。VFD模型采用预训练-微调范式,减少了对额外数据的需求,能有效泛化到多种Deepfake数据集。通过测量声音和人脸的相似性,VFD在真实和假视频中取得了显著的区别,提高了Deepfake检测的准确性。
该论文提出了一种名为VFD的深度学习模型,通过匹配音频和人脸的内在相关性来进行Deepfake检测。VFD模型采用预训练-微调范式,减少了对额外数据的需求,能有效泛化到多种Deepfake数据集。通过测量声音和人脸的相似性,VFD在真实和假视频中取得了显著的区别,提高了Deepfake检测的准确性。
一、论文信息:
-
题目:Voice-Face Homogeneity Tells Deepfake
-
作者团队:

-
会议:CVPR 2022
二、背景与创新
-
背景:大多数Deepfake检测方法致力于探索虚假视频人脸操作伪影,视觉、频域等方面,但这些方法跨数据集的泛化能力较低,如在FF++上训练的模型迁移到DFDC上时性能显著下降,因为不同算法针对不同数据集关注的区域不同。
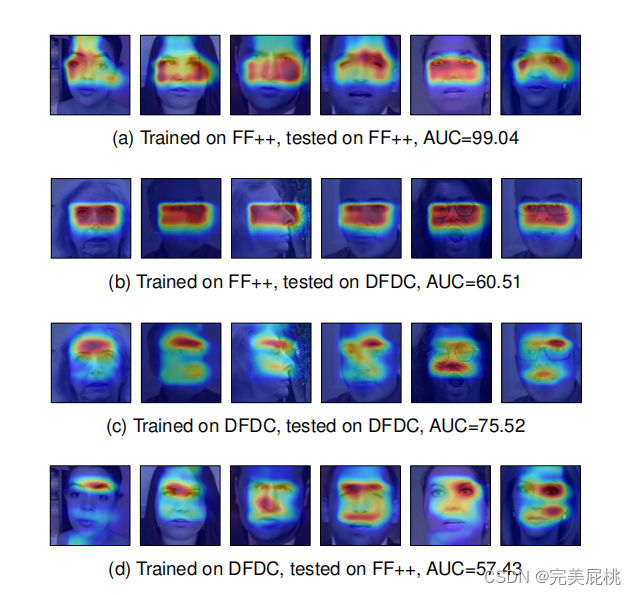
2. 创新:
1)提出语音人脸匹配检测模型&#x
一、论文信息:
题目:Voice-Face Homogeneity Tells Deepfake
作者团队:
会议:CVPR 2022
二、背景与创新
背景:大多数Deepfake检测方法致力于探索虚假视频人脸操作伪影,视觉、频域等方面,但这些方法跨数据集的泛化能力较低,如在FF++上训练的模型迁移到DFDC上时性能显著下降,因为不同算法针对不同数据集关注的区域不同。
2. 创新:
1)提出语音人脸匹配检测模型&#x

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文























